Interconnection Networks
분배되고 공유된 메모리 시스템의 성능에 영향을 끼친다(왜냐하면 병렬적으로 처리하고 나중에 한 곳으로 뭉칠 때, 짧은 시간 안에 서로 통신해야하기 때문이다).
Interconnection Networks는 두 가지로 나뉜다.
-
Shared Memory Interconnects
-
Distributed Memory Interconnects
Shared Memory Interconnects
Bus interconnect
버스처럼, interconnect에 여러 프로세서가 연결되어있고, 한 곳의 공유 메모리에 접근한다.
구현하고 확장하기 쉽지만, 버스에 많은 디바이스가 붙는다면 혼잡도가 증가하여 퍼포먼스가 낮아진다.Switched interconnect
연결된 디바이스 사이 데이터 라우팅을 컨트롤하기 위해 스위칭한다.
-
Crossbar
모든 디바이스가 동시에 연결되는 것을 허용함.
버스들보다 빠르다. 하지만 디바이스끼리 직접적으로 연결하기 때문에 비싸다.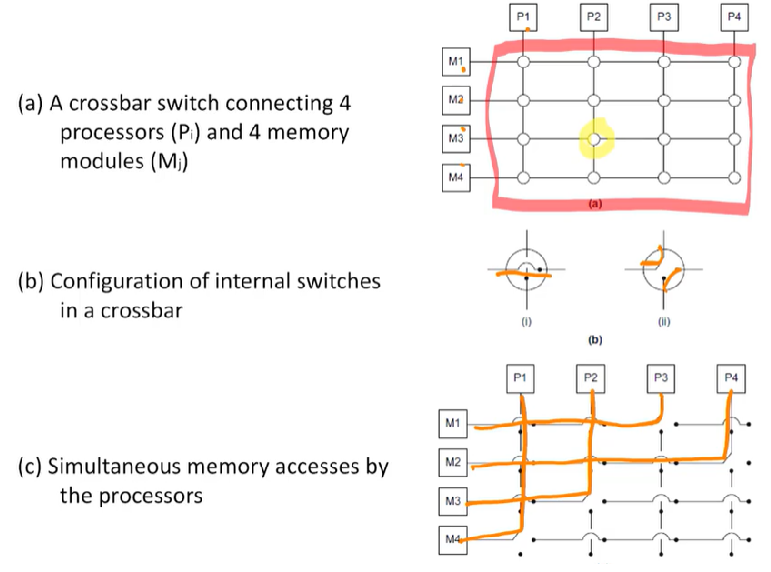
Distrbuted Memory Interconnects
Direct Interconnect
대량의 데이터를 주고 받기 위해 모든 스위치가 프로세서-메모리 쌍이 서로 직접 연결되어있다.
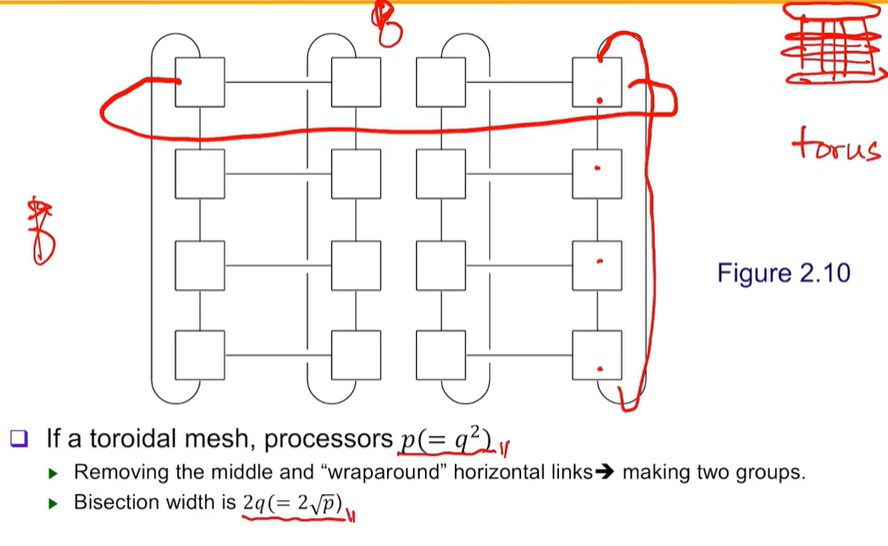
Bisection Width
프로세서 쌍을 반으로 잘라 나눈 동시에 통신이 일어나는 대역폭
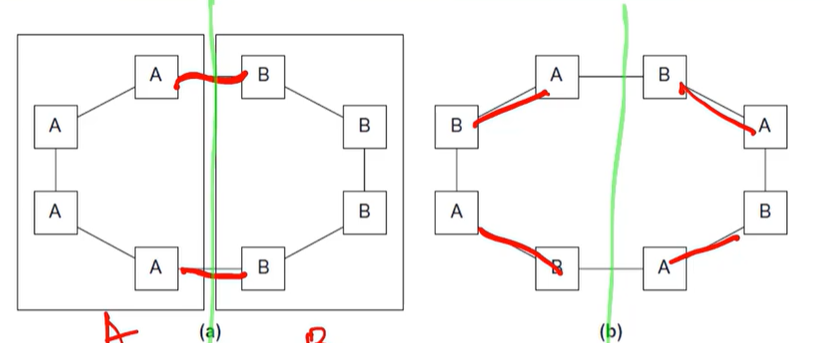
빨간표시가 자른 부분이다. 이 자른 부분이 Bisection Width이다.
Bisection Width는 Worst case를 기준으로 평가한다. 오른쪽같은 경우, 4개의 쌍이 묶어지지만 반으로 나뉜 왼쪽은 2개만 이어지게 된다.
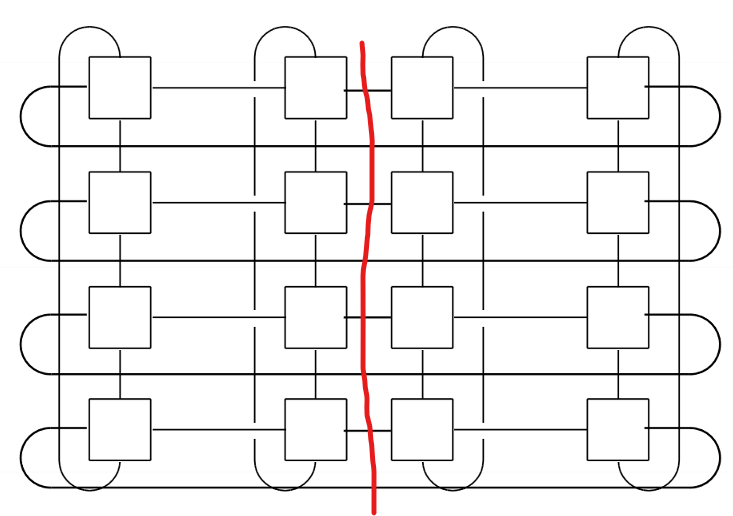
위 같은 경우엔 8개의 링크가 잘라졌다고 볼 수 있다.
-
Bandwidth of a link
하나의 링크를 통해 보낼 수 있는 데이터 rate -
Bisection bandwidth
네트워크의 퀄리티( = bandwidth * bisection) -
Fully Conntected Network
모든 프로세서가 본인 이외의 프로세서와 연결한다.
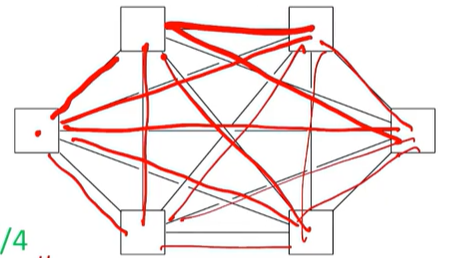
이 때, link의 개수는(n-1)!이므로, 프로세서가 많아지면 그만큼 복잡해지기 때문에 소규모 네트워크에서만 사용된다.
Fully Connected Network의 bisection width를 계산해보자면,
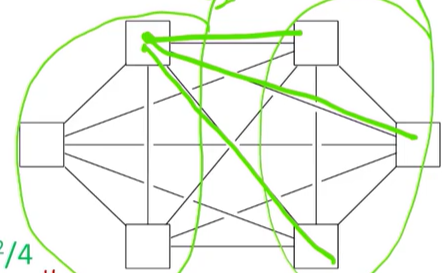
먼저 프로세서를 2개의 그룹으로 나눈 뒤, 하나의 프로세서의 link 개수와 그룹 하나의 프로세서 수를 구한다. 전체 프로세스의 수를p라고 한다면, link 개수는p/2, 프로세서의 개수는p/2가 된다. 두 값을 곱하면 bisection width는(p^2)/4이다.HyperCube
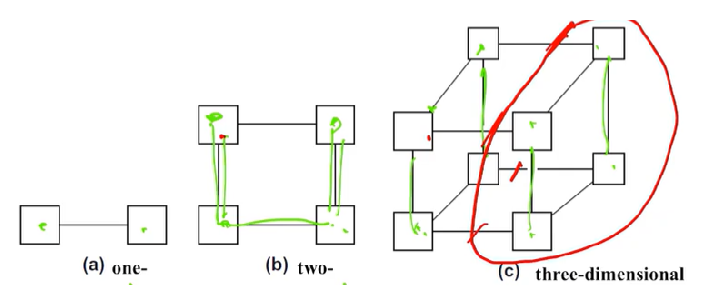
다차원적으로 Connect하는 네트워크이다.
-
1차원의 하이퍼큐브는 두 프로세서 간 서로 Fully conneteced System으로 연결되어있다.
-
2차원의 하이퍼큐브는 2개의 1차원 하이퍼큐브가 연결되어있는 구조다.
-
3차원은 2차원 하이퍼큐브 2개가 연결되어있다.
하이퍼큐브 n차원은
p = 2^n만큼 노드(프로세서)를 갖고 있다.
bisection width는p/2, 스위치 와이어는1 + d = 1 + log2p만큼 있다.PDF 본문에는 스위치 와이어의 계산식이 잘못되어있다. 주의바람
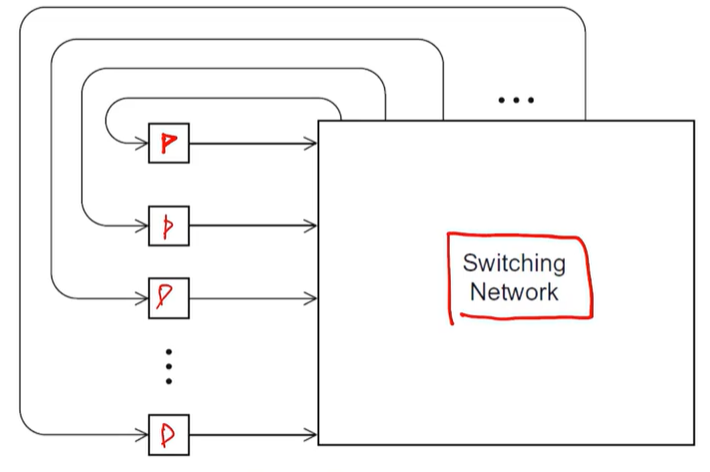
Indirect Interconnect
수신과 발신 링크와 네트워크 스위칭을 갖고 있는 단방향 링크와 프로세서 집단을 형성하고 있다.
ex) Crossbar, omega network
일반적인 Indirect Interconnect
각 프로세서들은 스위칭을 통해 네트워크에 연결되어있다.
Indirect Interconnect with Crossbar
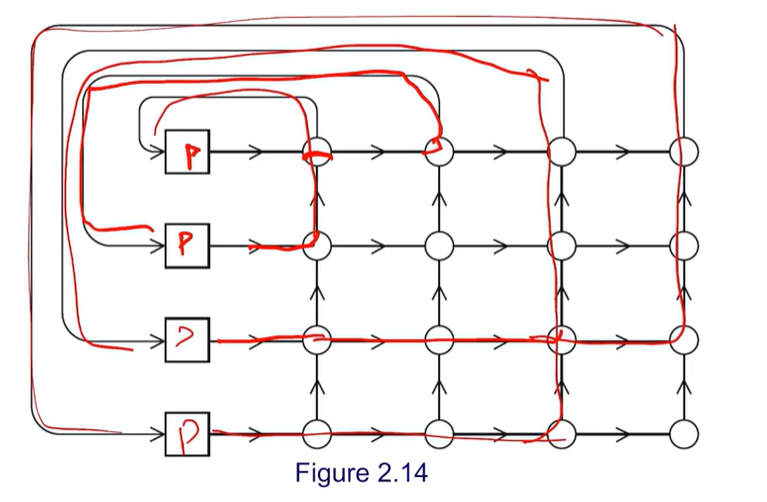
Crossbar가 결합된 Interconnect. 동시에 여러 개의 프로세서에 연결할 수 있다. 단, 연결도중 교차점에 다른 Connection과 충돌이 나면 안된다.
Omega Network
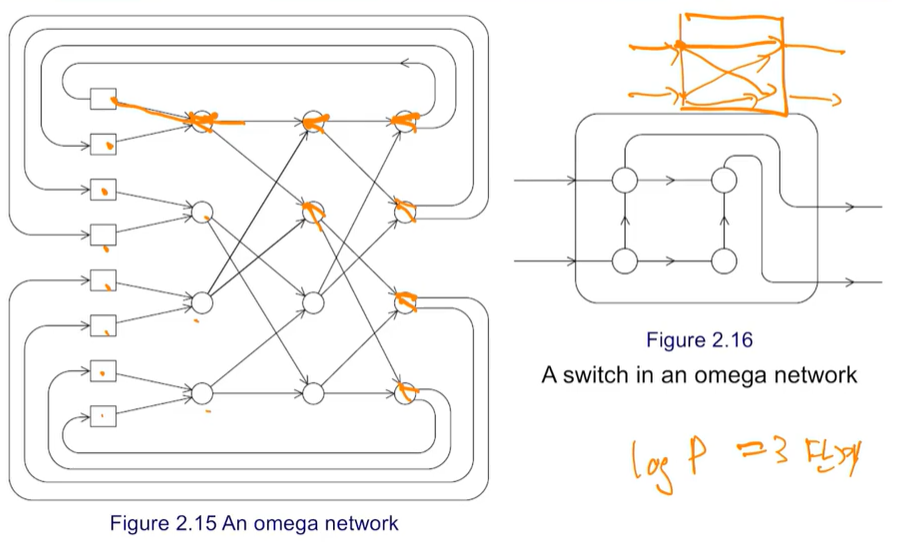
Omega Network는 하나의 프로세서는 모든 프로세서에 접근할 수 있다. 대신, 스위치에서 충돌이 발생하지 않는 조건이 있어야 한다.
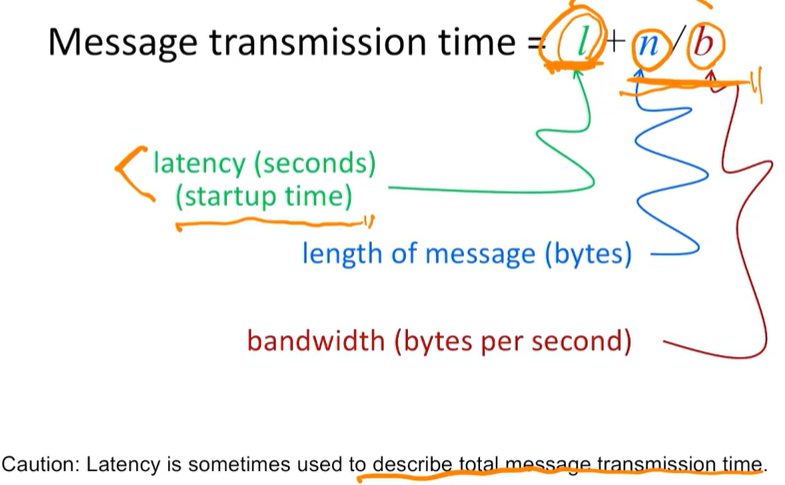
Message Transmission Time
-
Latency(Startup time) : 데이터를 전달하기 시작한 후부터 첫 바이트를 받기까지 걸린 시간 => 데이터를 보내기 시작하고 ~ 데이터를 받기 시작하기까지의 시간.
-
Bandwidth : 받기 시작한 다음부터 바이트(데이터)를 얼마나 빨리 보내는지에 대한 rate(=속도)
메세지 전송 시간은 다음과 같다.