
Performance
우리가 병렬프로그래밍을 하는 이유는 성능을 향상시키기 위해서이다. -> 속도를 빠르게!

병렬프로그램이 빨라진 정도는 (직렬 처리 시간) / (병렬처리 시간) 로 계산할 수 있다.
-
Efficieny

-
Overhead

예를 들어보자.
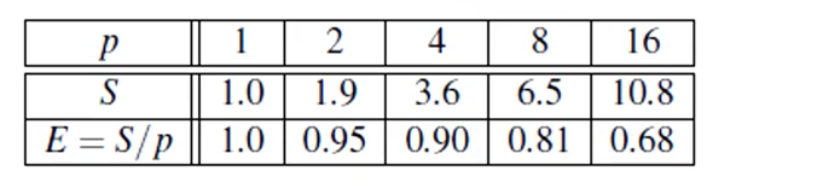
여기, 한 병렬 프로그램의 효율성과 Speedup를 측정한 표가 있다. 프로세서를 증가시키므로써 속도는 빨라지지만, 효율성은 낮아진 모습을 볼 수 있다.
이 때, 동일한 프로그램을 데이터의 사이즈를 변형해서 다시 돌렸을 때 다음과 같은 표가 나왔다.
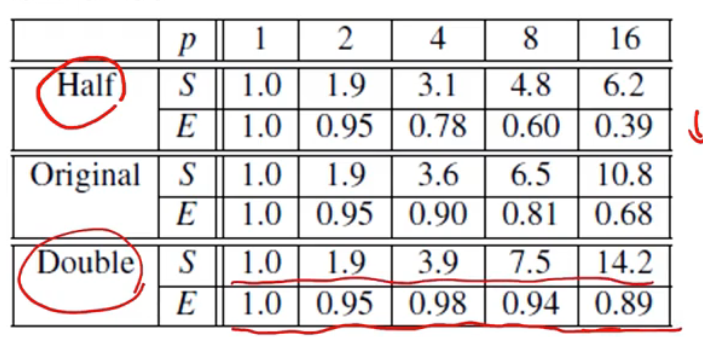
Half는 데이터의 사이즈를 반으로 줄인 것이고 Double은 데이터의 사이즈를 두 배 늘린 것이다. Half의 경우 효율성은 오히려 낮아졌고 Double은 효율성이 증가한 모습이다.
Amdahl's Law
한 직렬 프로그램을 병렬화하려 할 때, 가능한 속도 향상에 한계가 있다는 것을 말한다.
예를 들어, 한 직렬 프로그램의 90%를 병렬화할 수 있고 코어를 완벽하게 모두 사용하며, 직렬 처리 시간이 20초라고 가정했을 때, 병렬 처리 시간은 다음과 같이 나온다.
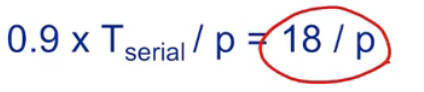
(0.9는 90%를 뜻하며, p는 코어의 개수를 뜻한다)
하지만, 직렬 처리 시간은 이렇게 나온다.

총 처리시간은 18/p + 2 가 나온다. 아무리 프로세서를 늘려도, 결국 2초는 고정이라는 뜻이다. -> 속도를 올리는데 한계가 있다! SpeedUp 역시, 10을 넘을 수 없다.

Amdahl's Law에 의해 속도 향상에 한계가 있지만, 이는 데이터의 크기가 고정되었다는 가정이다. 그렇다면 위에서 다룬 것처럼, 데이터의 크기를 증가시키면 되지 않을까? 데이터의 크기가 커지면 병렬성이 늘어나고 효율이 좋아진다! -> 이를 Gustafson's law라고 한다.
Scalability
문제의 크기를 키웠을 때를 Scalable하다고 한다. 문제의 크기를 증가시키지 않은 채 프로세스나 스레드의 수를 증가시키고 효율성을 똑같이 유지할 수 있을 때, 이를 Strongly scalable이라고 한다. 문제의 크기도 증가시키고 프로세스나 스레드의 수를 증가시키고 효율성을 똑같이 유지할 수 있을 때, 이를 Weakly scalable이라고 한다.
Time measurement
시간을 측정할 때 무엇을 기준으로 측정할까? 대게 프로그램의 처리시간을 계산할 때 CPU Time으로 계산한다(Standard C Function, "Clock"). 하지만, IDLE 상태일 때 포함시키지 않으므로 이건 문제가 된다.
그래서 우린 시간을 측정할 때, Wall Clock Time이라는 것을 사용할 것이다. 이것은 처리를 시작하는 시간과 처리가 끝난 시간을 구한 뒤, 이 구간만큼 생긴 차이(Wall)을 계산한다. 장벽을 두 개 세워놓고 계산한다고 해서 Wall Clock Time이라고 불린다.
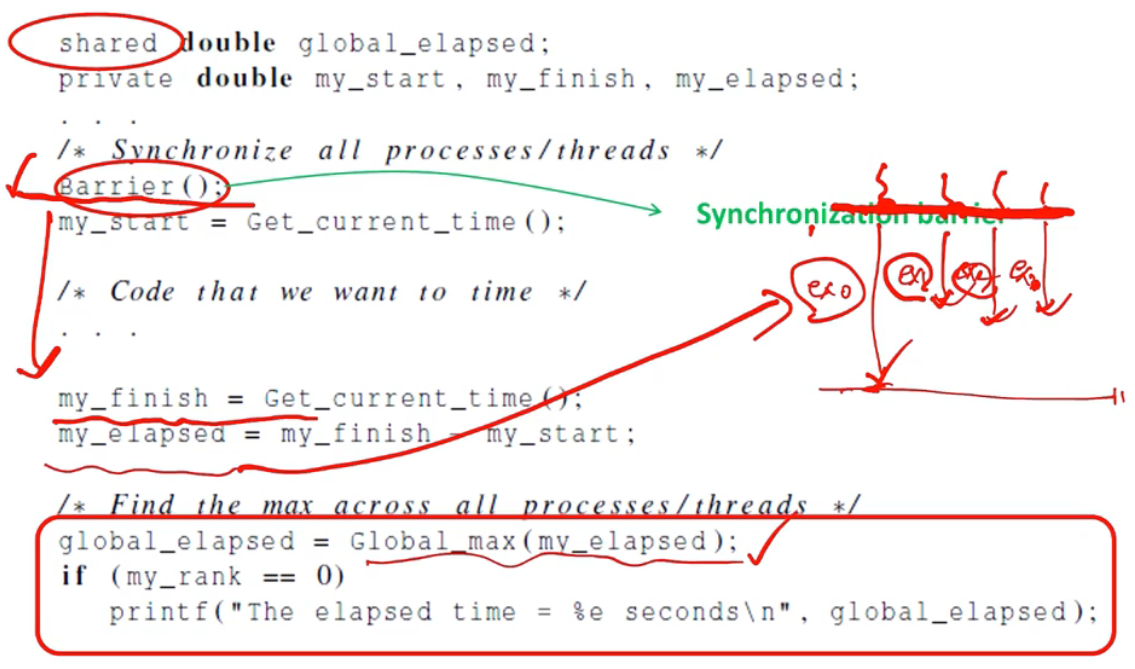
시간을 측정하는 예제 중 하나이다. 스레드가 여러 개일 경우, 모든 스레드의 처리가 끝날 때까지 기다린다. 다 끝난 뒤 처리시간이 가장 긴 시간이 총 처리시간이 될 것이다(이 외 예제는 교재를 보자!).
Paraell Program Design
Foster's methodology
- Partitioning : 처리하고자하는 컴퓨터테이션 업무를 작은 단위의 데이터나 작업으로 나눠준다.
- Communication : 데이터를 나눌 때 통신이 필요하다.
- Agglomeration or aggregation : 결과를 모으고 통신한다. 예를 들어 B라는 작업을 하기 전에 A작업이 실행되야할 때, A작업이 끝날 때까지 기다리고 이를 모아 B작업을 시작한다. 이 과정에서 통신을 하는 것이다.
- Mapping : 작업들을 스레드와 프로세스에 할당해줘야 한다. 이 과정에서 통신을 최소화하고 비슷한 작업량을 할당해줘야 한다.
Example
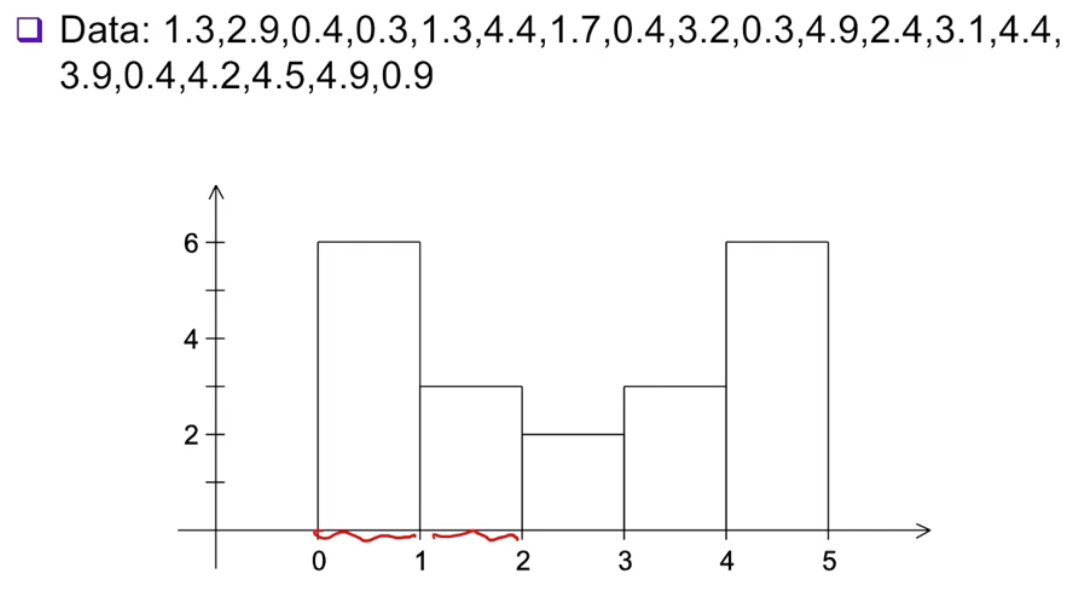
히스토그램을 띄우는 프로그램이 있다고 가정한다.
- Serial Input
- 데이터의 개수
- 데이터 배열
- 데이터 배열 속 최댓값
- 데이터 배열 속 최솟값
- 최솟값과 최댓값 사이의 개수(bin count)
- Serial Input
- bin count 배열의 최댓값(bin maxes)
- bin counts
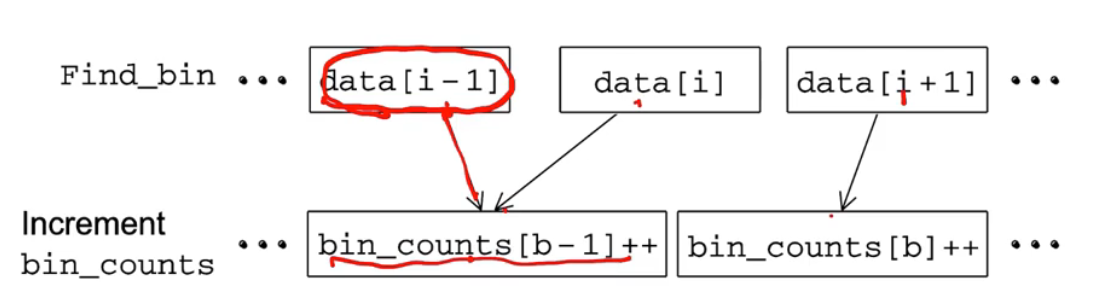
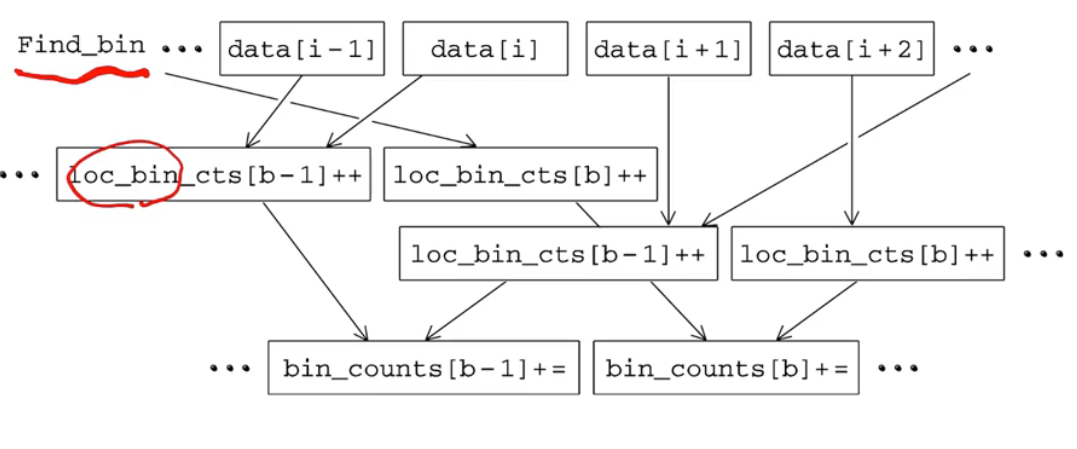
이런 식으로 bin 값을 하나씩 넣어준다.
