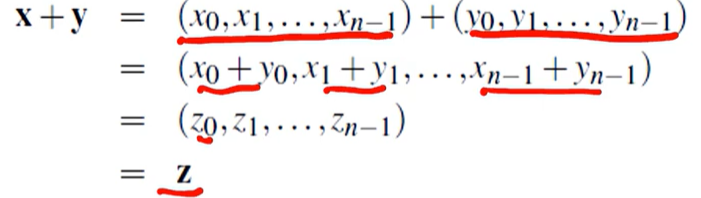
위와 같은 연산식이 있다고 치자. 시리얼하게 실행하면 단순히 for문을 돌려서 계산할 것이다. 하지만 이를, 분산 컴퓨팅으로 계산하려면 어떻게 해야될까?
Data distributions
12개의 컴포턴트 벡터를 3개의 프로세스로 파티션을 나눈다.
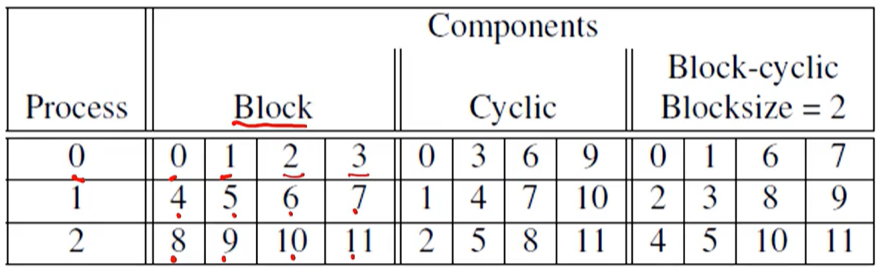
데이터를 분산시키는데에 3가지 방법이 있다.
-
Block
전체를 3개의 블록을 나눈다. -
Cyclic
라운드로빈처럼 프로세스 순서로 돌아게끔 분배함. -
Block-cyclic (Blocksize = 2)
Block과 Cyclic을 섞은 방법이다. 블록 사이즈를 2개로 하면, 01 ->23 -> 45 -> 67 -> 89 -> 10 11 순으로 순회한다.
Scatter
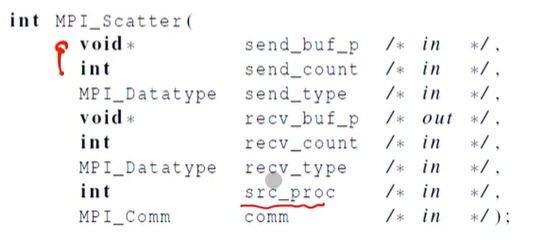
MPI_Scatter는 0번 프로세스의 전체 벡터를 읽고, 이것을 필요로한 프로세스들에게 나눠줌.
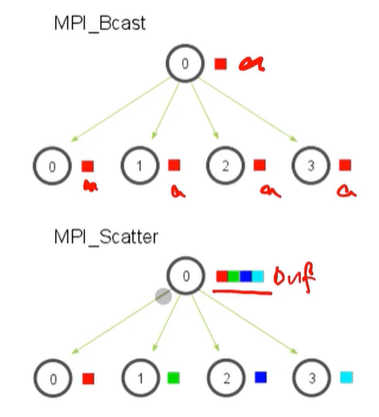
Bcast는 하나의 값만 알려줄 수 있지만, Scatter는 버퍼를 읽고 이를 각 프로세스들에게 나눠줄 수 있다.
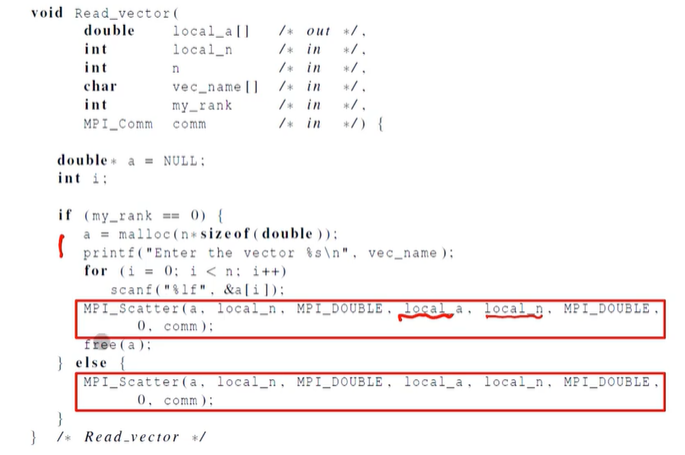
이런 식으로 버퍼를 여러 프로세스에게 나눠줄 수 있다.
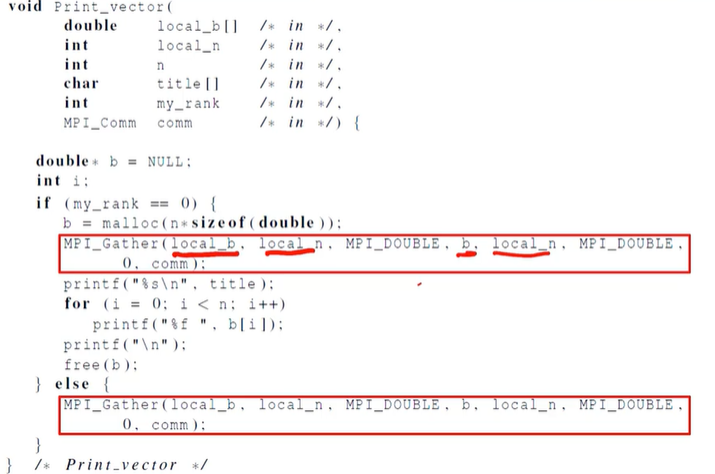
Getter
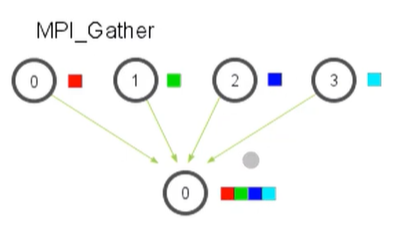
Scatter의 반대로, 여러 프로세스에게 나눠준 값들을 한 곳으로 모아준다.
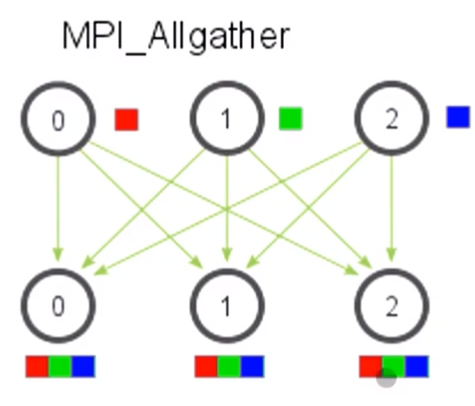
Allgather

각각의 프로세스의 콘텐츠가 send_buf를 만들고 recv_buf를 각 프로세스에서 저장한다. Reduce가 결과를 공유했던 것처럼, Allgather도 결과를 공유한다.
Matrix-vector multiplication
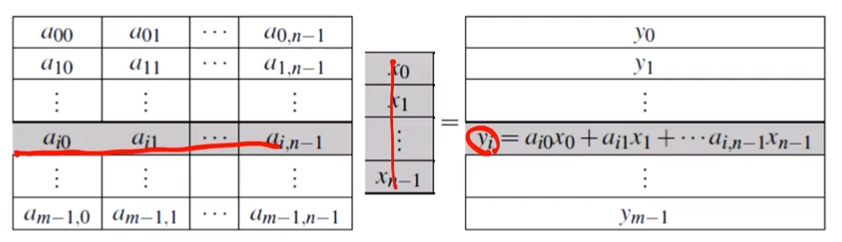
두 행렬의 각 행과 열을 곱하여 이를 행으로 결과를 나열한다. 시리얼 코드로 나타내면 다음과 같이 나온다.

이러한 행렬 계산을 저장할 때, c style arrays로 저장된다.
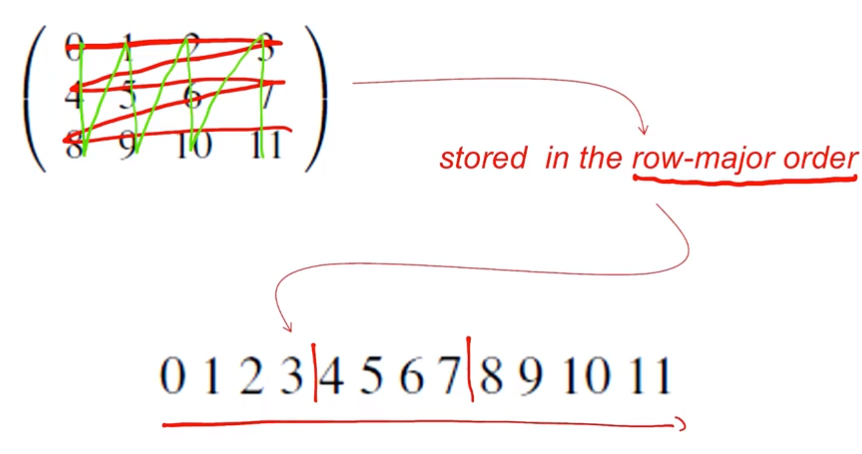
row-major-order 방식으로 저장되었을 때 모습이다. 이와 반대로, column-major-order 방식도 있는데, 초록색으로 색칠한 순서대로 저장된다.

이를 Allgather 함수를 사용하여 행렬곱을 계산할 수 있다. 각 행을 곱할 때 이를 스레드별로 나눈다음 MPI에서 각 결과를 합치는 것이다.
MPI Derived dataype
아이템들의 특정 컬렉션을 보여주기 위해 어떤 타입의 데이터를 저장하는지, 메모리 안의 상대적 위치를 저장하는지 알려줘야 한다. 따라서, 데이터를 전송할 때, 아이템리스트의 컬렉션에게 데이터에 대한 정보를 전달해줄 필요가 있다.
데이터를 받았을 때 메모리에서 데이터를 합칠 때 분산정보(->Data Structure)에 대해 알고 있어야 메모리에 저장할 수 있다.
MPI 데이터 타입이 묶여져있는지,각각의 타입이 얼마나 떨어진채 저장되어있는지 이를 명확하게 알려준다.
예시: Trapezoidal Rule
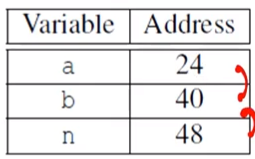
프로세스 0에 저장된 변수가 3개가 있다. 변수명과 주소가 위와 같을 경우, MPI Dervied Datatype은 다음과 같다.
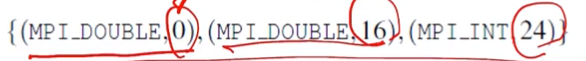
A변수로부터 B변수는 16만큼 떨어져있고, C변수는 24만큼 떨어져있다는 것을 표시한다. 그리고 첫번째 인자에 데이터 타입을 명시해준다. 당연하게도, 기준점이 되는 A는 0이다.


각 데이터타입을 build해주는 함수와 참조하는 메모리의 위치를 반환해주는 함수이다(그 외 commit, free 함수도 있지만 생략하겠다. 자세한건 pdf에서 보기로.)
