성능 평가
시간 측정
일반적으로 elasped time으로 병렬처리 시간을 계산한다. 병렬처리가 되기 전의 시간을 구하고 병렬 처리가 끝난 뒤의 시간을 구한 뒤 이 두 시간의 차이를 계산한다.
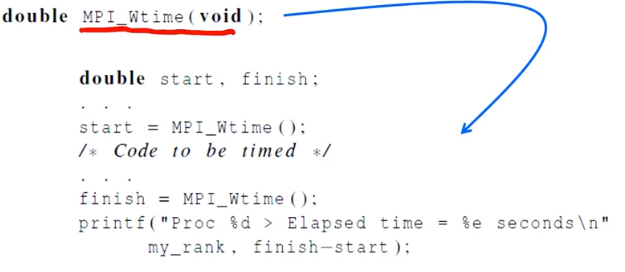
이 경우엔 MPI를 사용할 필요는 없다. timer.h에서 제공하는 함수는 microseconds로 제공하여 elapsed time을 구할 수 있다.
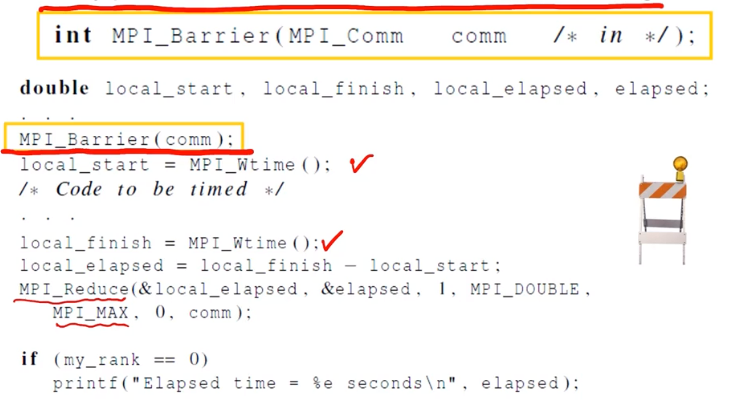
각각의 프로세스의 시작부터 끝까지의 시간이 다르기 때문에, 모든 프로세스가 끝날 때까지 기다려야한다. 이걸 MPI_Barrier를 사용하여 elapsed time을 측정할 수 있다.
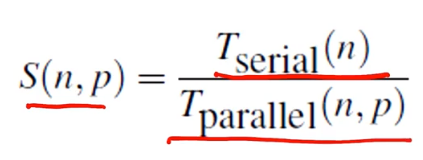
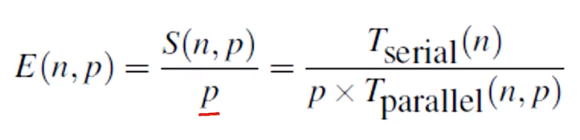
전에 배웠던 SpeedUp과 Efficiency의 계산식이다. 각 프로세스 개수에 따른 elapsed time을 구하고 S와 E를 구할 수 있다.
Scalability
해결하고자 하는 문제의 사이즈를 증가되었을 때, 프로세스의 개수를 증가시켜 Efficiency가 감소하지 않으면 Sacable한 프로그램이라고 볼 수 있다.
문제의 사이즈를 증가시키지 않고 efficiency를 유지시키는 프로그램을 "Strongly Scalable" 이라고 부른다.
또한 문제의 사이즈가 커질 때, efficiency가 유지되면 "Weakly Scalable"이라고 부른다.
Parallel Sorting Algorithm
- n개의 키를 정렬할 때, p(=comm_sz)개의 프로세스를 사용한다.
- 각 프로세스는 n/p개의 키가 할당될 것이다.
- 각 키의 할당은 제한 없이 프로세스에 될 것이다.
- 알고리즘이 종료가 되기 위해선
- 프로세스에 할당된 키는 오름차순으로 정렬되어야 하고- 0 <= q < r < p 일 때, 각 프로세스의 모든 키는 정렬되어있을 것이다.
버블 정렬을 예로 들어보자. 버블 정렬은 배열을 순회하면서 다른 값보다 클 경우, 서로의 값을 swap해준다. 이를 짝수/홀수로 나누어 작업할 수 있다. 이 방법을 Odd-even transposition sort라고 한다.


5, 9, 4, 3이 시작된다.- 5와 9, 4와 3을 비교한다. 4 > 3이므로, 이 둘을 swap하여
5 9 3 4가 된다. - 9와 3을 비교한다. 9 > 3이므로 서로 바꿔
5 3 9 4가 된다. - 다시 5와 3, 9와 4를 비교한다. 양쪽 모두 왼쪽이 크므로
3 5 4 9가 된다. - 다시 중간의 5와 4를 비교한다. 마찬가지로 swap하여
3 4 5 9가 된다.
이를 직렬코드로 나타내면 다음과 같다.

Odd even Sort에서의 작업 간 통신
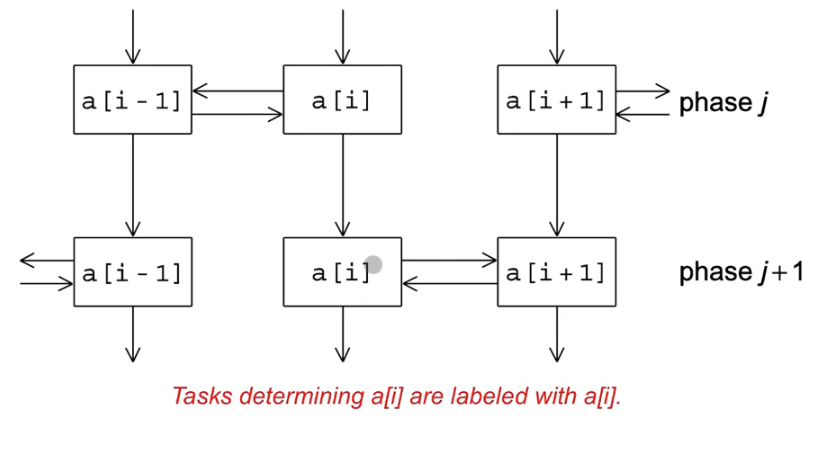
이웃하는 프로세서 끼리 자신의 밸류들을 서로 주고받아 비교를 하고 swap한다.
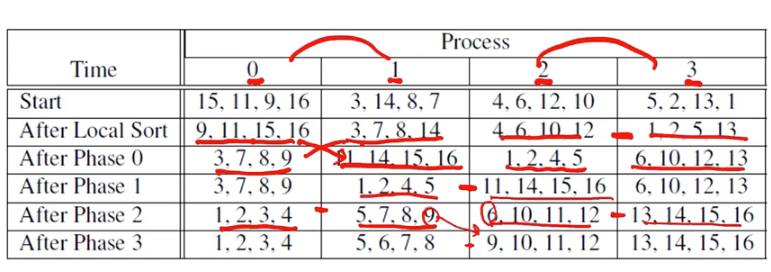
예시로 이렇게 프로세서 간 교환하면서 sort한다.

나의 키를 파트너에게 전송하고, 나는 파트너의 키를 받게 될 것이다. 본인 프로세서의 순서가 파트너보다 작을 경우, 작은 키들을 갖고 있어야 한다. 반대로 순서가 파트너보다 큰 경우 큰 키 값들을 갖고 있는다.
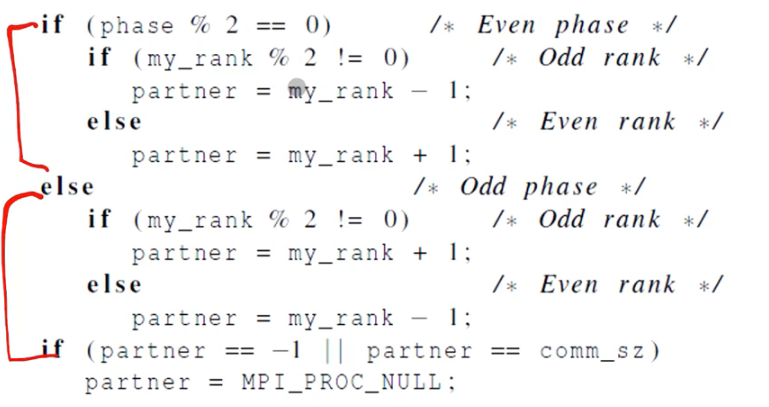
파트너를 구하는 의사코드이다. 짝수 페이즈일 경우, 본인의 랭크가 짝수라면 1만큼 감소시킨 랭크가 파트너가 될 것이다. 본인의 랭크가 홀수라면 1만큼 증가된 랭크가 파트너가 된다. 홀수 페이즈일 경우 반대로 생각하면 된다. 그 외에는 양쪽에서 통신이 일어나지 않는 경우이다.
Safety in MPI programs
-
MPI 스탠다드는 두 가지 방식으로 MPI_Send를 허용한다.
MPI가 메세지를 버퍼에 복사만 하고 리턴되는 경우가 발생할 수 있다. 혹은 MPI_Recv의 시작될 때까지 MPI 스탠다드가 멈춰있을 가능성도 있다. -
대부분의 MPI implementations들은 버퍼링을 해둔다.
상대적으로 작은 메세지들은 MPI_Send에 의해 버퍼링이 된다.
만약 큰 메세지일 경우, 블록을 일으킬 수도 있다. -
만약 MPI_Send를 각 프로세스 블록에서 할 경우(서로에게 Send), MPI_Recv를 호출할 수 없을 것이고 프로그램이 hang이나 deadlock에 걸릴 것이다.
각 프로세스는 절대 발생하지 않는 이벤트들을 기다리기 때문에 블록될 것이다. -
버퍼링이 제공되는 MPI에 의존하는 프로그램은 안전하지 않다.
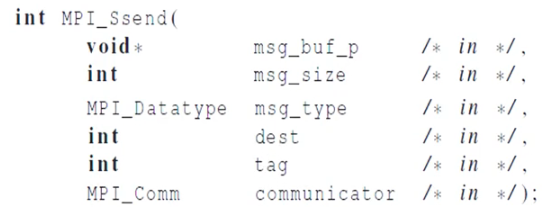
MPI_Ssend는 MPI_Send 대신에 사용할 수 있는 함수이다. s가 붙은 것은 synchronous(동기)를 뜻한다. receive 시작이 매칭될 때까지 블록을 보장해주는 함수이다.
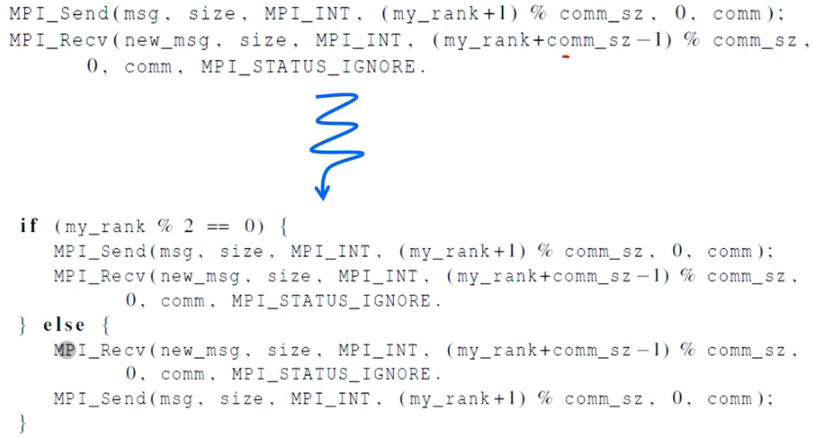
다시 커뮤니케이터를 재구성하면 다음과 같이 나온다. 짝수는 send하고 recv를 하고, 홀수는 recv를 하고 send한다.
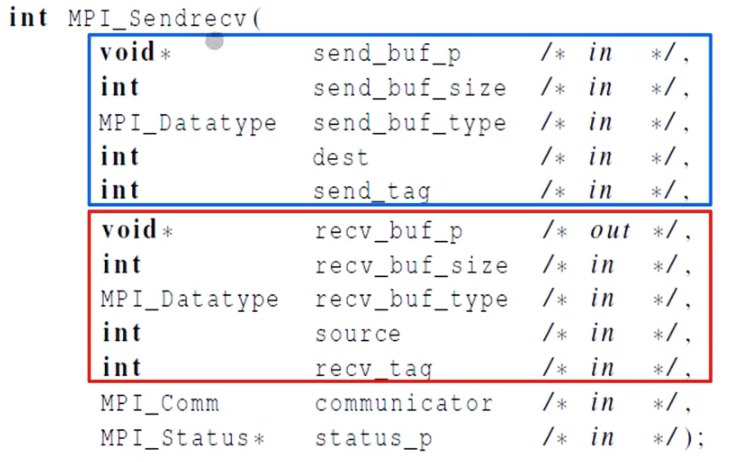
위 과정을 하나의 콜로 처리하는데, MPI_Sendrecv가 있다. 블록이 되는 Send와 recv가 하나의 싱글 스레드로 처리된다.
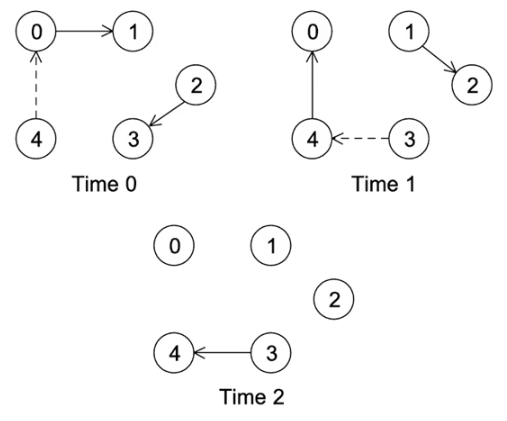
이렇게 5개의 프로스들이 안전하게 통신하는 것을 볼 수 있다.

parallel하게 처리한 odd even transposition sort 코드이다.
