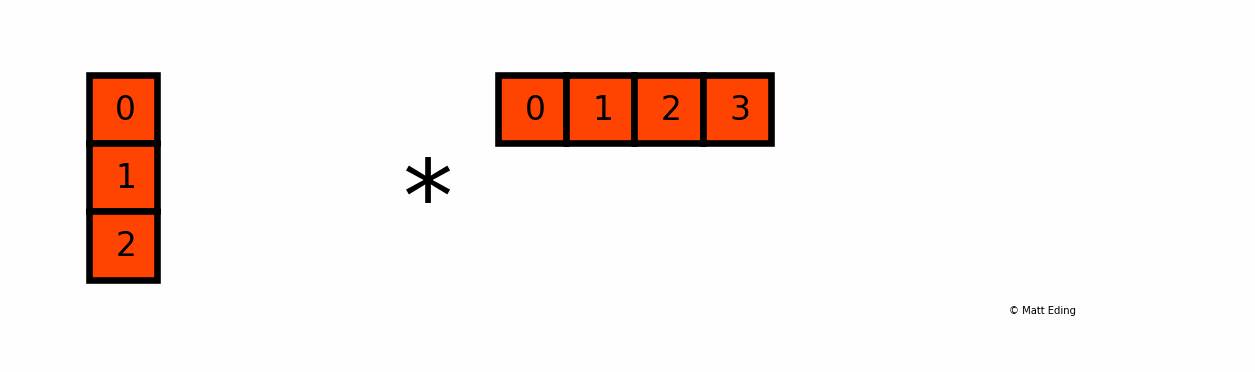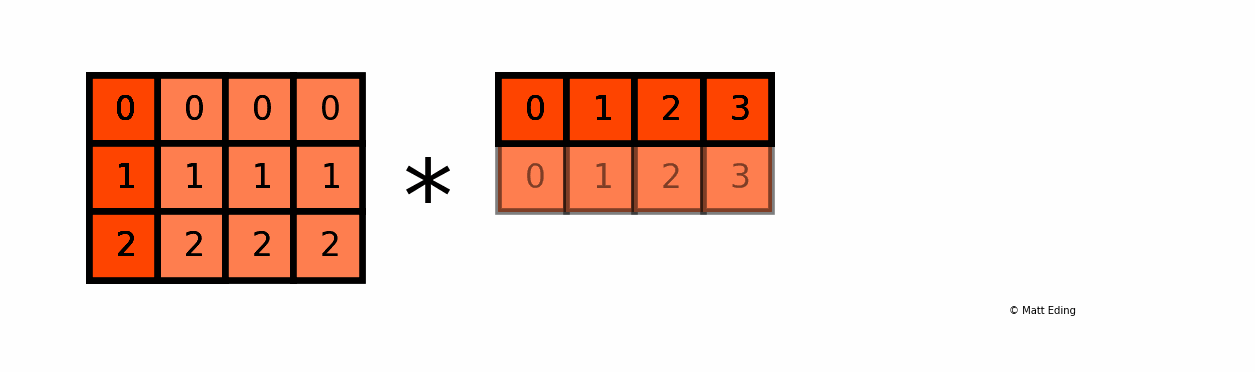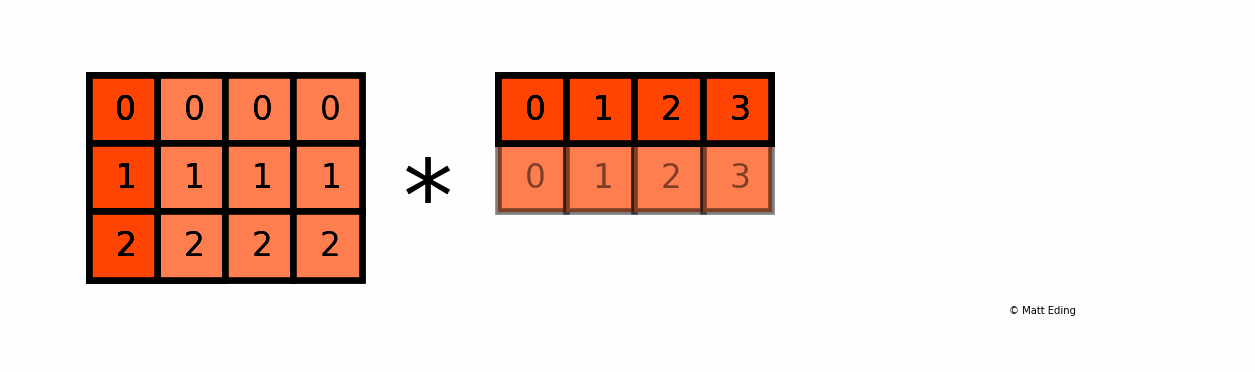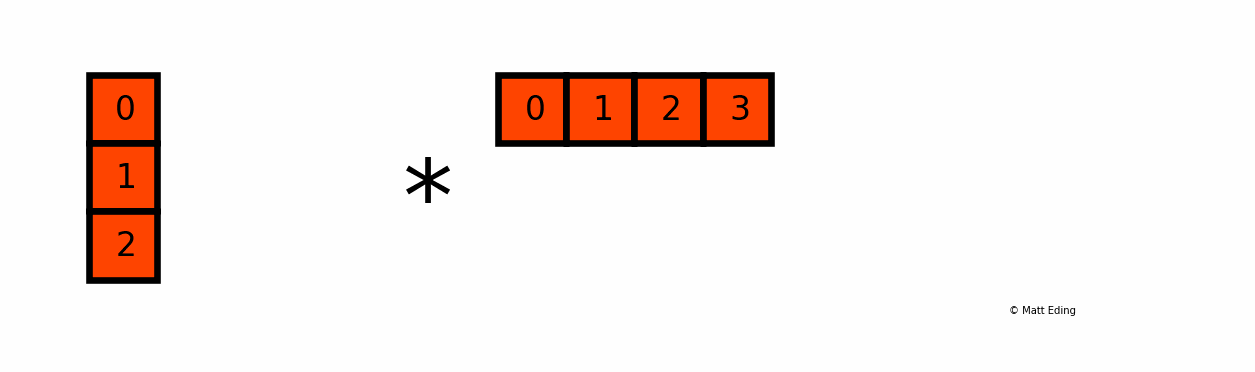
Abstract
빅데이터, 머신러닝, 딥러닝 등... 개발 분야에서 굉장히 핫 한 키워드들이다.
위 키워드들에 대해 자세히 배울때, Python으로 직접 구현해 보고 싶을 때, 절대 필수적으로 알아야 하는 두 가지가 Numpy, Pandas이다.
다른 블로거 분들도 굉장히 자세하게 정확한 정보들을 주고 계시지만, 나 같이 난독증 있고 물음표 살인마인 사람들에게 더 도움이 될 정보들을 담아보려 한다.
또한, Numpy를 사용하지 않았을 때 직접 작성해야하는 코드의 효율성을 직접 비교하며 알아보려 한다.
Numpy를 왜 쓰는가?
벡터와행렬연산을 지원해서 더 빨리 계산된다는 건 알겠고,
그래서 뭐 때문에 성능이 더 좋아서 사용하는데?
시간복잡도(Big-O)
Big-O 표기법을 잘 모르는 사람을 위해 아래에 표를 기재 해두겠다.
(아래로 갈 수록 오래 걸린다고 생각하면 된다.)
| 표기법 | 형태 | 예시 |
|---|---|---|
| O(1) | 상수 | data[i] = 인덱스로 값 찾기 |
| O(log n) | 로그 | 이진 탐색 |
| O(n) | 선형 | for문 |
| O(n log n) | 선형로그 | data.sort() = 파이썬 기본 정렬 |
| O(n^2) | 이차 | 이중 for문 |
| O(n^3) | 삼차 | 삼중 for문 |
간단한 예시로 리스트 각각에 3을 더한 요소를 반환하는 프로그램을 작성 해 보자.
score = [12, 34, 56]
# 일반적인 방법
score_origin = [3+i for i in score]
print(score_origin)결과: [15, 37, 59]
# Numpy 사용
score_numpy = np.array(score)+3
print(score_numpy)결과: [15 37 59]
결과를 보면 다른점은 ,가 있는지 없는지 하나밖에 안보인다.
이것만 봐서는 뭐가 나은지, 왜 좋은지를 모르겠으니 실험을 하나 해보자.
Numpy VS List
1억개의 데이터를 생성을 하고, 시간을 측정해보자.
# 일반적인 방법
import time
start = time.time()
arr = [i for i in range(100000000)]
end = time.time()
print('list 1억개 생성 소요시간은 ', end-start, '초입니다.')결과: list 1억개 생성 소요시간은 6.2452921867370605 초입니다.
# Numpy 사용
import time
import numpy as np
start = time.time()
arr = np.arange(100000000)
end = time.time()
print('numpy array 1억개 생성 소요시간은 ', end-start, '초입니다.')결과: numpy array 1억개 생성 소요시간은 0.9000861644744873 초입니다.
1억개의 데이터인데도 시간 차이가 상당한 것을 알 수 있다.
이 데이터들이 10억, 100억개가 넘어가면 더욱 더 많은 차이를 보일 것이다.
왜냐면 Numpy의 시간복잡도는 O(1), 기본 for문을 거친 데이터 생성은 O(n)이기 때문이다.
둘 다 데이터를 생성하는 것 뿐인데 Numpy는 무슨 원리로 이렇게 빨리 되는건가?
예제 하나를 보면 바로 이해가 가능 할 것이다.
Python List
# Python
python_list = ['100', 200, True, 3.14]
print(python_list)결과: ['100', 200, True, 3.14]
# Python
python_list = ['100', 200, True, 3.14]
for e in python_list:
print(type(e))결과:
<class 'str'>
<class 'int'>
<class 'bool'>
<class 'float'>
Python List로 생성한 원소들은 각자 모두 Type을 개별로 저장 된다는 것을 알 수 있다.
그럼, Numpy List는?
# Numpy
python_list = np.array(['100', 200, True, 3.14])
print(python_list)결과: ['100' '200' 'True' '3.14']
# Numpy
python_list = np.array(['100', 200, True, 3.14])
for e in python_list:
print(type(e))결과:
<class 'numpy.str_'>
<class 'numpy.str_'>
<class 'numpy.str_'>
<class 'numpy.str_'>
모든 값이 str Type으로 바뀐것을 알 수 있다.
이렇듯, Numpy는 한 가지 Type으로만 데이터를 담기 때문에 더 빠르다는 것을 알 수 있다.
그럼 Numpy는 여러 Type의 데이터를 못 담나?
그건 아니다.
# Numpy
python_list = np.array(['100', 200, True, 3.14], dtype=object)
for e in python_list:
print(type(e))결과:
<class 'str'>
<class 'int'>
<class 'bool'>
<class 'float'>
위 코드처럼, 배열에 저장할 때 dtype=object를 넣어주면 각각 데이터 타입을 유지하여 저장할 수 있다.
근데 이렇게 쓸거면 그냥 Numpy 쓰지않는게 좋다.
같은 데이터 빨리 행렬연산 하려고 Numpy쓰는거지, 여러 데이터 타입을 담으려고 쓰는건 아니니까..
BroadCasting
Numpy는 BroadCasting이라는 것이 있다.
BroadCasting이란, 다른 차원을 가지고 있는 두 개의 피연산자를 산술 연산하는 도중 산술 연산이 가능하도록 차원을 맞춰주는 것이다.
이 덕에 Numpy를 사용하면 방대한 양의 데이터도 순식간에 처리할 수 있는 속도가 나오는 것이다.
BroadCasting도 무조건 되는건 아니고, 크게 2가지의 조건이 있다.
조건1: 연산 할 데이터가 1개의 사이즈
- 조건이 충족되는 예시:
[1, 2, 3, 4]*3
- 조건이 충족되지 않는 예시:
[1, 2, 3, 4]*[5, 6, 7]
조건2: 연산 할 데이터의 사이즈가 같을 때
[1, 2, 3, 4]*[5, 6, 7, 8]
이정도만 알아도 될 것 같다.
Numpy 활용
실제로 Numpy가 어떻게 많이 사용되는지 보자.
shape
dim1 = [1, 2, 3] # 1차원 데이터
dim2 = [[1, 2, 3, 4], [6, 7, 8, 9]] # 2차원 데이터
dim3 = [[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]] # 3차원 데이터score_numpy = np.array(dim1)
score_numpy.shape결과: (3,)
score_numpy = np.array(dim2)
score_numpy.shape결과: (2, 4)
score_numpy = np.array(dim3)
score_numpy.shape결과: (2, 2, 3)
위 데이터들이 출력되는게 어떤것을 뜻하는지 이해가 가는가?
순서대로 1차원, 2차원, 3차원의 데이터이다.
쉽게 얘기하면
1차원의 경우 (3, )으로 끊어져있는 모습을 볼 수 있는데, 이는 type이 tuple이라 그런 것이고, 데이터의 개수를 표시해준다.
2차원의 경우 (2, 4)로 나누어진 이유는 4개의 데이터가 2묶음 있다는 뜻이다.
3차원 데이터의 경우도 마찬가지. (2, 2, 3)로 출력된 이유는 3개의 데이터가 2묶음씩 2개 있다는 뜻이다.
더 쉽게 얘기하면
4차원 이상의 다차원에서도 뒤에 있는 값부터 순서대로 보면 된다.
더 더 쉽게 얘기하면
(2, 2, 3)
(3차원, 2차원, 1차원)
dtype
arr = np.array([1.21, 2, 3, 4.4])
print(arr.dtype)
print(arr)결과:
float64
[1.21 2. 3. 4.4 ]
dtype은 특정 변수, 객체 등의 type이 뭔지 알 수 있게 해준다.
astype
arr = np.array([1.21, 2, 3, 4.4])
arr = arr.astype('int64')
print(arr)결과:
[1 2 3 4]
astype은 elements의 type을 한번에 변환 시켜준다.
Boolean Indexing
이거 굉장히 좋다..
x = np.array([1, 4, 2, 3, 9])
x > 2결과:
array([False, True, False, True, True])
근데 이게 뭐가좋아요?
result = x > 2
result.sum()결과:
3
기본적으로 True == 1, False == 0이다.
그래서 위와 같이 sum()을 사용해서 수많은 데이터 중 조건보다 큰 값, 작은 값등이 총 몇개있는지 빠르게 구할 수 있다.
실제로 머신러닝, 딥러닝에서 데이터 전 처리 과정 중, 결측치를 구할때 많이 사용하는 방법이기도 하다.
concatenate & stack
이건 정말 확실히 알고가는게 좋다.
여러 차원의 데이터를 한번에 합치고 싶은데, 행 방향으로 합치거나, 열 방향으로 합칠 수 있다.
arr1 = np.array([[1, 2, 3, 4],[11, 12, 13, 14]])
arr2 = np.array([[5, 6, 7, 8],[15, 16, 17, 18]])- 이런 데이터가 있다고 가정해보자.
concatenate(axis=0) == vstack
# concatenate(axis=0)
np.concatenate((arr1, arr2), axis=0)# vstack
np.vstack((arr1, arr2))결과:
array([[ 1, 2, 3, 4],
[11, 12, 13, 14],
[ 5, 6, 7, 8],
[15, 16, 17, 18]])위 두가지 기능 모두 데이터를 행으로 합쳐준다.
concatenate(axis=1) == hstack
# concatenate(axis=1)
np.concatenate((arr1, arr2), axis=1)# hstack
np.hstack((arr1, arr2))결과:
array([[ 1, 2, 3, 4, 5, 6, 7, 8],
[11, 12, 13, 14, 15, 16, 17, 18]])마찬가지로, 위 두가지 기능 모두 데이터를 열로 합쳐준다.
사실 Numpy는 단일로 사용하는 경우는 아직 못봤다.
보통 빅데이터에서 많이 사용되니 pandas나 ML, DL과 연계되어 많이 사용되기 때문에 기본적인 문법은 이정도만 알아도 충분할 것 같다.
그래서 다음 게시글은 Pandas에 대해서 설명하려고 한다.

자세하게 알려주셔서 정말 감사합니다. 도움 많이 되었습니다.