CS개념의 중요성을 느꼈다.... 요즘 직무 면접에서 워낙 많이 나오는 개념들이라 과목을 들을때 시험을 위해서 공부한 내용들이 머리에서 다 잊혀져갔다... 지금부터라도 정리해보자는 마음에 시작하는 나의 첫 BLOG! 많이 부족하니 너무 뭐라고 하지마시길..
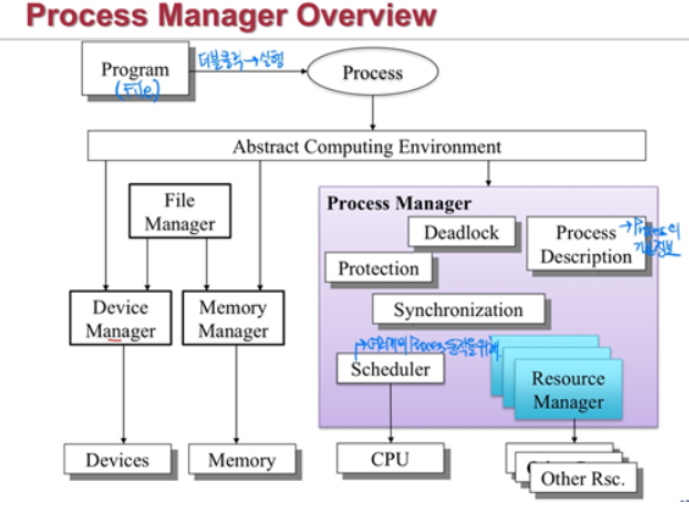
프로세스와 스레드의 차이
프로세스(Process)
- 프로세스는 ‘메인 메모리에 할당되어 실행중인 상태’ 의 프로그램을 말한다. 쉽게 말하면 우리가 어떤 프로그램을 마우스로 더블클릭하여 실행하면 그 순간 그 프로그램은 하나의 process가 되는 셈이다. 프로그램(Program)은 일반적으로 하드디스크에 저장되어 아무 일도 하지 않지만, 프로세스는 실행하면서 stack pointer, data, text, register등 끊임없이 변한다. 운영체제로부터 주소 공간, 파일, 메모리 등을 할당받기 때문에 운영체제가 관리해야 한다는 의미에서 job또는 task로 불리기도 한다.
Process의 생성과정
프로세스의 생성과 종료
-
프로세스는 또다른 프로세스에 의해 만들어지며, fork() 라는 시스템 콜에 의해 생성된다. 만들어진 프로세스에서 어떤 파일을 실행하려면 exec() 시스템 콜을 사용한다.
-
프로세스를 종료하는 시스템 콜은exit() 이다. 한 프로세스가 종료되면 해당 프로세스가 사용한 모든 자원을 회수해야하며, 이 자원들에 관한 권한은 모두 운영체제로 되돌아간다.
프로세스 제어 블록(Process Control Block, PCB)
PCB는 특정 프로세스에 대한 각종 요소들을 담고있는 운영체제의 자료구조이다. OS에 의해 생성되고 관리된다.
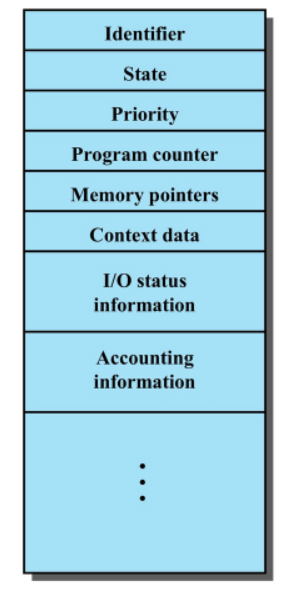
PCB에 저장되는 정보
- 프로세스 식별자(Process ID , PID) : 프로세스 식별번호 (int형으로 저장됨)
- 프로세스 상태 : new, ready, running, waiting, terminated 등의 상태를 저장
- 프로그램 카운터 (Program Counter, PC) : 프로세스가 다음에 실행할 명령어의 주소
- CPU 레지스터
- CPU 스케줄링 정보 : 프로세스의 실행순서에 관한 정보
- 메모리 관리 정보
- 입출력 상태 정보
- Accounting 정보 : 사용된 CPU시간, 시간제한, 계정 번호 등
프로세스의 일반적 구조
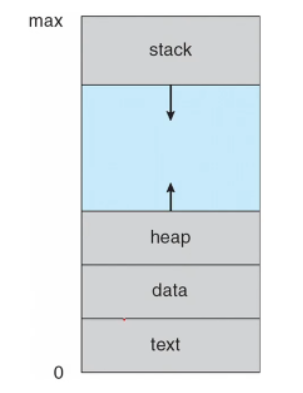
프로세스의 일반적인 구는 위의 그림과 같다.
● text(CODE) : 컴파일된 소스 코드가 저장되는 영역
● data : 전역 변수/초기화된 데이터가 저장되는 영역
● stack : 임시 데이터(함수 호출, 로컬 변수 등)가 저장되는 영역
● heap : 코드에서 동적으로 생성되는 데이터가 저장되는 영역
함수를 실행하게 되면 함수의 return address가 스택에 저장되고, 함수의 지역 변수들이 차례로 스택에 쌓이게 된다. 함수가 다 실행되고 나면 스택에 있던 데이터들이 차례로 삭제되고, 스택에 저장되어 있던 return address또한 사라지면서 그 주소로 이동한다.
이렇게 스택을 이용하여 만든 함수 실행 구조를 ‘스택프레임’ 이라고 한다.
스레드(Thread)
스레드는 프로세스의 실행 단위이다. 프로세스 내의 주소 공간이나 자원을 공유할 수 있다.
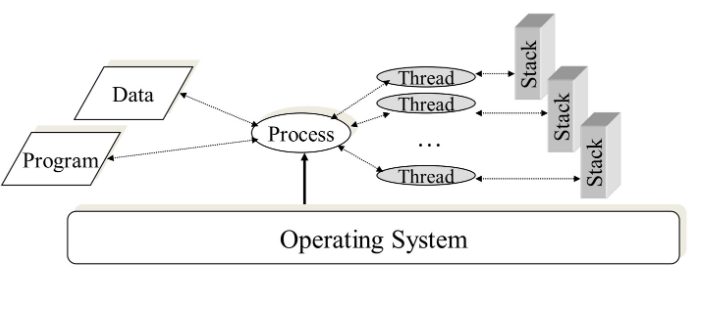
스레드는 동작하는 Process안에 각자의 stack을 가진다.
Process VS Thread
-
새로운 프로세스를 fork() 를 이용하여 생성하는 것은 비용이 많이 든다. 시간과 메모리 측면에서 비효율 적이라는 말이다.
-
스레드(종종, lightweight process라고 불림.)는 메모리와 생성시간을 많이 요구하지 않기때문에 Process에 비해 효율적이라고 할 수 있다.
Thread의 장점
- 응답성
- 자원 공유
- 메모리 절약
- 확장성
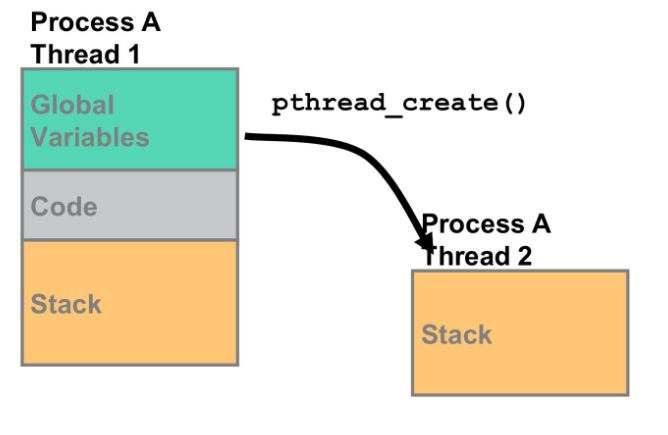
위의 그림처럼 thread는 전역변수와 코드를 Process와 공유하기 때문에 stack만 존재하면 된다.
Thread마다 독립적으로 가지고 있는 것들.
- Program Counter
- Register Set
- Stack Space
Thread가 Process와 공유하는 것들
- Code Section
- Data Section
- Operating-System Resource
- Collectively know as a task
※그렇다면, stack을 스레드마다 독립적으로 할당하는 이유는 무엇일까?
- 스택은 함수 호출 시 전달되는 인자, 되돌아갈 주소값 및 함수 내에서 선언하는 변수 등을 저장하기 위해 사용되는 메모리 공간이므로 스택 메모리 공간이 독립적이라는 것은 독립적인 함수 호출이 가능하다는 것!
→ 따라서, 스레드의 정의에 따라 독립적인 실행 흐름을 추가하기 위한 최소 조건인 셈이다.
※Stack을 스레드마다 독립적으로 할당하는 이유는 무엇일까?
- PC는 스레드가 명령어의 어디까지 수행하였는지를 나타낸다. 스레드는 CPU를 할당 받았다가 스케줄러에 의해 다시 선점당한다. 그렇게 때문에 명령어가 연속적으로 수행되지 못하고 어느 부분까지 수행됐는지 기억될 필요가 있다.
→ 따라서, PC를 독립적으로 할당한다.
