첫번째 포스팅에서, 스레드에 관한 이야기를 짧게 했었다. 스레드는 프로그램 내부의 흐름이며, 일반적으로 하나의 프로그램은 하나의 쓰레드를 갖는다.
멀티스레드(MultiThread)
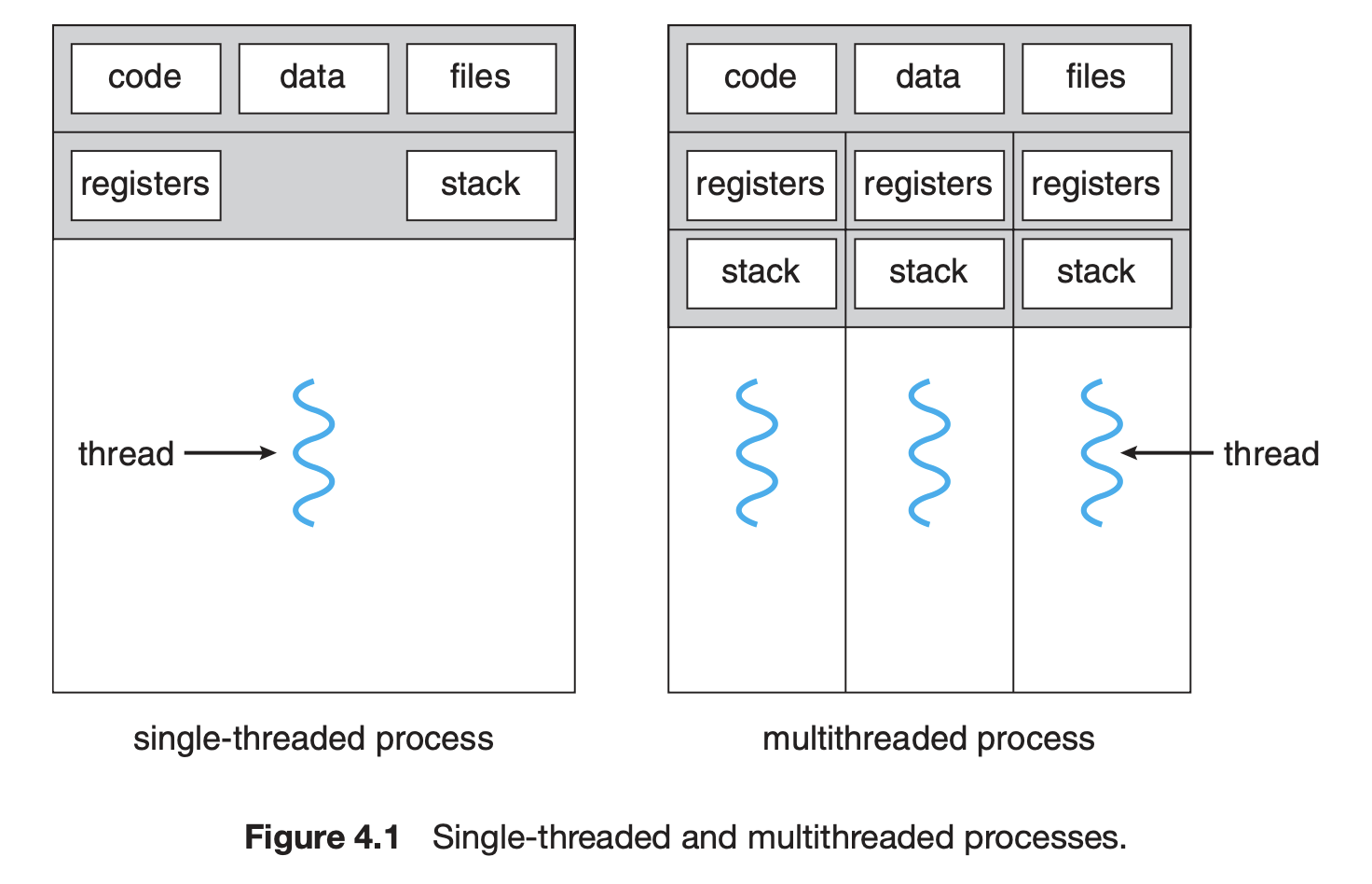
- 하나의 프로그램에 스레드가 2개 이상 존재하는 것을 멀티 스레드라고 한다. 이렇게 한 프로그램에 여러 개의 스레드 즉, 여러개의 흐름이 있을 수 있는 이유는 스레드가 빠른 시간 간격으로 스위칭되기 때문이다. 이러한 동작으로인해 사용자는 여러 스레드가 동시에 실행되는 것처럼 보인다.
각각의 스레드가 가지는 것들.
1. execution state : Running, Ready 등 스레드의 실행 상태에 관한 정보를 가진다.
2. thread context : 스레드가 실행중이지 않을 때, 어디까지 진행되고 있었는지에 관한 정보를 가진다.
3. execution stack
4. some static storage : 또 다른 함수 호출 시, local variable을 저장하기위한 공간이다.
각각의
process는 여러개의 스레드를 가질 수 있다는 것을 기억하자.
멀티 스레드의 사용 예시
-
비동기 처리 (Asynchronous processing) : background에서 계속 돌아가야 하는 것들에 대한 처리이다 예를 들면, MS-word의 자동저장 기능이 있다.(주기적으로 backup을 함.)
-
Server Architecture : 클라이언트의 요청이 있을 때마다 thread를 생성하여 맡기고 다른 클라이언트의 요청을 또 받는다.
멀티 스레드의 문제점
- 멀티 스레딩을 기반으로 프로그래밍을 할 경우, 공유하는 자원에 대하여 동시에 접근하는 경우가 생길 수 있다. 서로 다른 스레드가 process의 데이터와 힙 영역을 공유하기 때문에 만약 어떤 스레드가 다른 스레드에서 사용 중인 변수나 자료구조에 접근하여 엉뚱한 값을 읽어올 수 있다.
-> 그렇기 때문에 멀티스레딩 환경에서는 스레드 간의 동기화 작업이 매우 필요하다. 동기화를 통해 작업 처리 순서를 컨트롤 하고, 공유 자원에 대한 접근을 컨트롤 하기 위함이다.
현대 운영체제의 Switching단위
현재 운영체제에서는 대부분 멀티 스레드를 지원하기 때문에 하나의 프로세스 안에서 여러 스레드를 수행하다가 다른 프로세스로 넘어가서 그 프로세스의 스레드는 수행한다. 그러므로 현대의 운영체제의 context switching단위는 스레드 단위이다.
멀티스레드 프로세스 내에서 스레드간의 Context Switching을 하는 것이 Stack영역만 교체하면 되기 때문에 비용이 감소하여 성능이 증가하기 때문!!
- 이전 포스팅에서 스레드가 독립적인 요소를 가져야 하는 이유도 바로 위와 같은 이유 때문이다.
멀티 스레드와 멀티 프로세스의 차이점
- 우선, 프로세스는 다른 프로세스와 완전히 독립적이다. 프로세스가 가지는 구조로는 Code, Data, Heap, Stack이 있는데 이 때 스레드는 자기가 속한 프로세스의 일부 메모리를 공유한다.
- 이러한 관점에서 두
operation의 차이점을 분석해보면, 멀티 스레드는 멀티 프로세스보다 적은 메모리 공간을 차지하고context switching이 빠르다는 장점이 있다. 그렇지만, 오류로 인하여 하나의 스레드가Block상태가 되면 proess 전체가 Block이 된다는 문제가 있다. - 반면에, 멀티 프로세스는 하나의 프로세스가 Block되더라도 다른 프로세스에는 영향을 끼치지 않고 정상적으로 수행된다는 장점이 있다. 그렇지만 멀티 스레드보다 많은 메모리 공간과 CPU 시간을 차지한다는 단점이 존재한다.
멀테 스레드와 멀티 프로세스는 동시에 여러 작업을 수행한다는 점에서 같지만, 적용해야 하는 시스템에 따라 적합/부적합이 구분된다. 따라서 적합한 동작 방식을 선택하고 적용해야한다!
다음 포스팅에서는 CPU의 스케줄링에 대해서 정리를 해보자!
