개요
- Stable Diffusion 모델은 Large-Scale Model이므로, 서비스를 위해선 고성능 GPU와 높은 Latency가 발생함
- 효율적인 Stable Diffusion 서비스를 위해, 모델의 Latency를 줄이고 안정적인 Server 구성이 필요함
이전 상황
모델 Inference 속도 이슈
- Diffusers를 활용하는 경우, A100 GPU에서 1개의 요청에 대해 5초 이상의 처리 시간이 소요하게 됨
GPU 메모리 이슈
- Diffusers를 활용하여 그대로 서빙하는 경우, GPU 메모리 점유율이 높아 1개의 서버에서 여러 모델을 동시에 서비스하는데 어려움이 발생
목표
- Stable Diffusion 모델구조(pipeline)에서 BottleNeck이 되는 부분을 파악하고, 이를 최적화 해보자
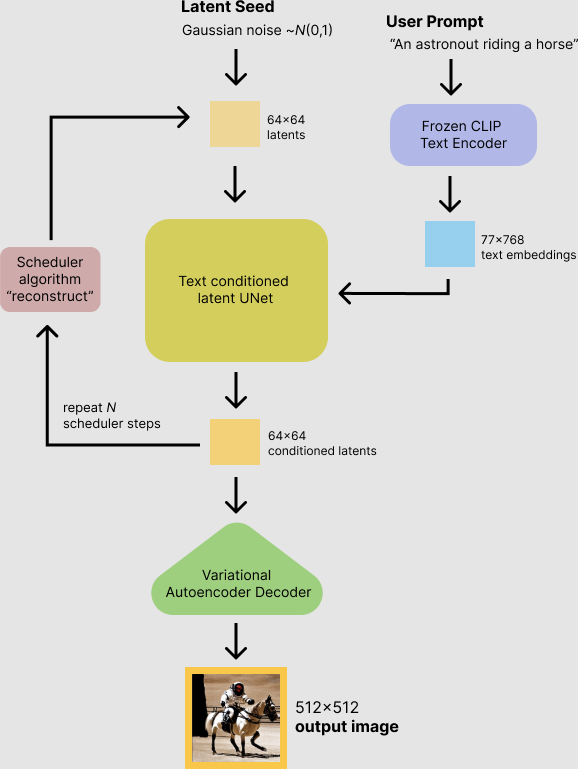
모델 구조
- Stable Diffusion은 단일 모델이 아닌, Text Encoder, U-Net, VAE와 같은 여러 모델이 합쳐져 있는 구조
- 특히 Diffusing 과정에서 U-Net이 여러 for loop을 도는 구조인데, 해당 과정에서 latency가 높게 발생함
가장 기본적인 txt2img pipeline 구조
- Diffusing 과정에서 UNet에 어떤 condition을 주냐에 따라 img2img, ControlNet등등 다양한 pipeline이 존재하지만 대략적인 구조는 비슷하다
TensorRT를 활용한 Nvidia GPU에서의 Inference 최적화
(Pytorch -> TensorRT 최적화 과정은 스킵하도록 하겠습니다.)
| GPU(A100-40G) | Pytorch | TensorRT |
|---|---|---|
| CLIP Text Encoder | 1.25s | 0.0025s |
| Text conditioned latent UNet | 5s | 0.85s |
| VAE-Decoder | 0.0284s | 0.018s |
타 기술과 최적화 성능 비교
- Diffusers에서도 다양한 최적화 기술들은 제공해주므로, 이를 비교 해보았다.
| GPU/Precision | Image per Prompt | Vanilla Attention | xFormers | Pytorch2.0 + SDPA | SDPA + torch.compile | TensorRT |
|---|---|---|---|---|---|---|
| A100/FP16 | 4 | 8.23s | 6.21s | 6.1s | 5.92s | 2.74s |
| T4/FP16 | 4 | 38.81s | 30.09s | 29.74s | 27.55s | OOM |
- T4는 TensorRT 변환 실패(Out of Memory)
- diffusion Scheduler : DDIM, 50 step 기준, 512x512, 4 images
참고 : A100에서도 TensorRT 변환할 때 가끔 out of memory가 뜬다...

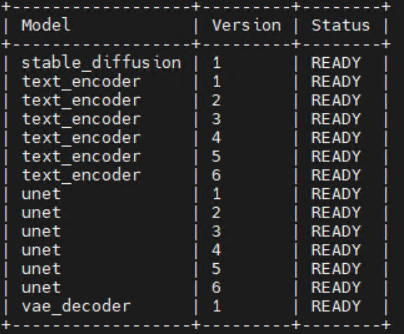
Triton Inference Server를 활용하여 서비스 서버를 구성해 봅니다.
Triton을 사용한 이유?
- 서버개발 경험이 없는, 저 같은 사람도 모델과 inference 코드만 구성하면 서버 구성하기 쉽고 용이함...
- NVIDIA의 GPU A100에서, NVIDIA의 AI 모델 최적화 라이브러리인 TensorRT와, NVIDIA의 ML Serving을 위한 Triton을 쓰면 좋지 않을까 싶어서...
- 구성 과정은 생략하겠습니다.
다음과 같이 TensorRT backend로 구성된 Triton Inference Server가 구성되게 된다.
Server inference 성능은 A100-40G 기준 다음과 같다.
512x512 해상도의 이미지 4장 요청할 때
Avg latency : 3323452usec
p50 latency : 3322060 usec
p99 latency : 3347962 usec
상위 1퍼의 latency도 3.4초 이하의 안정적인 inference 속도를 보여준다.
요약
- TensorRT를 활용하여 Stable Diffusion Pipeline latency를 5배 이상 최적화 하였다
- 여러 최적화 기법들이 있지만, 아직 TensorRT가 최고다.
Appendix
- Stable Diffusion Fine-Tuning 기법중, LoRA를 사용하면 UNet 구조 사이사이에 fc layer가 중간중간 들어가게되어, TensorRT 최적화의 효율이 매우 떨어진다.
- DreamBooth 최고

ML 잡부
진짜 궁금한 pytorch -> tensorrt 부분이 생략되었네요 ㅠㅠ