Triton Inference Server에서 제공해주는 것중에 Perfomance Analyzer가 있다
ML 모델을 잘 말아서 TIS(Triton Inference Server)를 생성했을때, TIS의 throughput과 latency를 분석해주는 툴이다.
1. 사용법
docker run -it --ipc=host --net=host nvcr.io/nvidia/tritonserver:22.06-py3-sdk /bin/bash
#example
./install/bin/perf_analyzer -m yolov7_visdrone -u 127.0.0.1:8001 -i grpc --shared-memory system --concurrency-range 1:50 -f yolov7_visdrone_perf.csv
TIS 성능평가를 위한 docker를 실행하고, 아래 명령어를 통해 분석을 시작합니다.
-m : 테스트할 모델(yolov7_visdrone)
-u, -i : url 주소 및 통신옵션 (grpc이므로, local에 8001 port)
-concurrency-range : 동시에 몇개까지 테스트할지 설정 1~100 concurrency
-f : performace 결과를 csv로 저장
2. 실험 환경 및 성능 분석
실험 환경
- 모델 종류 : Yolov7-TensorRT
- GPU : V100 x 2
- Maximum batch size 8
성능분석
- concurrency : 동시성
- inference/Second : 1초당 inference 처리량
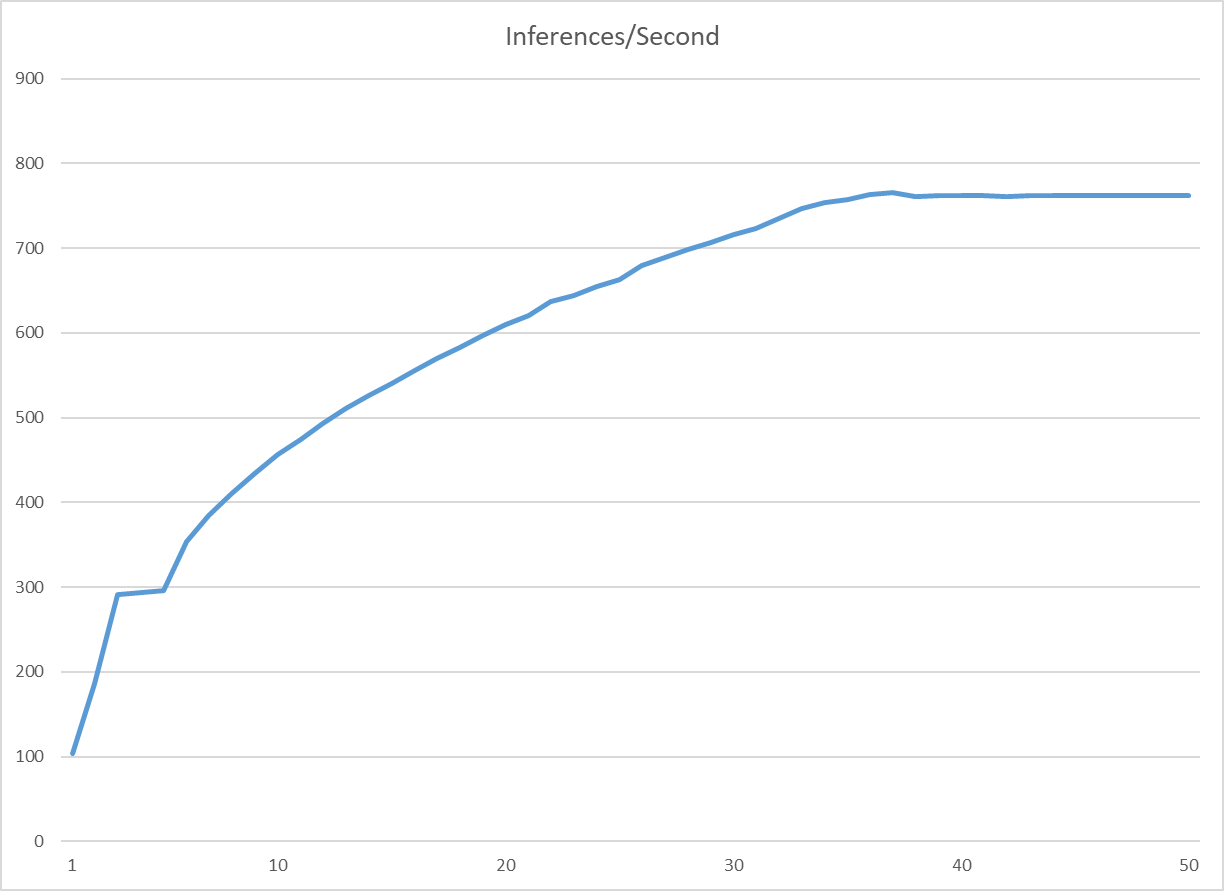
- concurrecy가 36일때 가장 높은 효율(765 inference/sec)을 보임
- 1초당 765개 이미지의 inference 요청 처리가 가능하다.
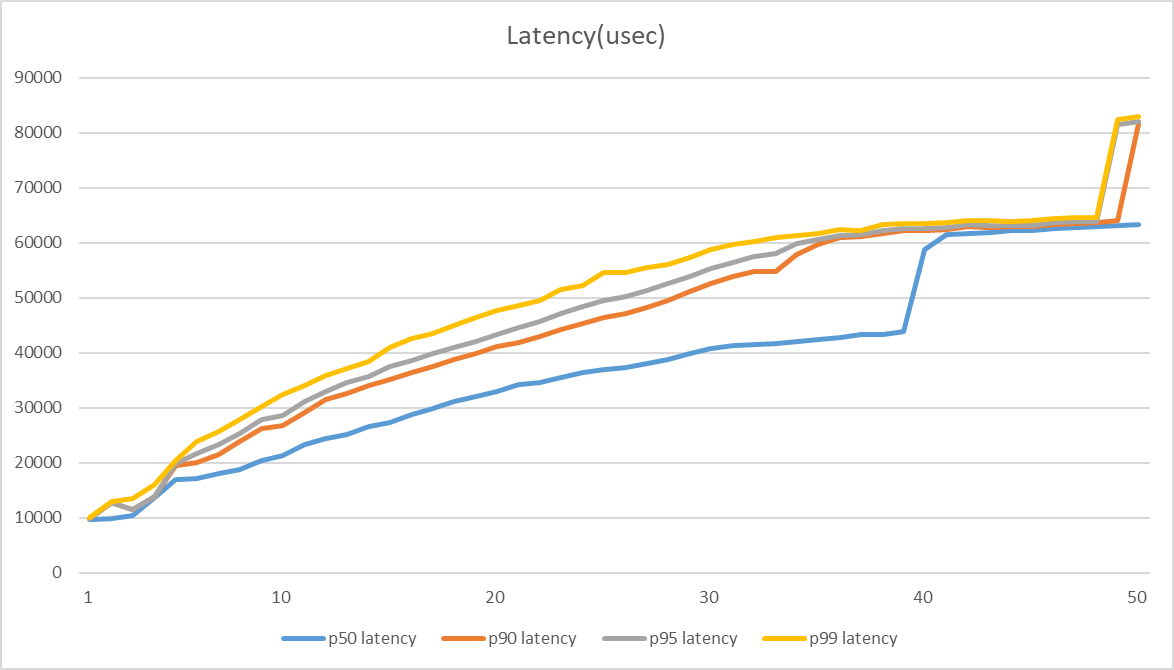
- p50, p90, p95, p99 latency : 하위 50%,90%,95%,99%의 평균 latency
- concurrency 30후반쯤부터, latenct가 급격하게 늘기 시작
- 처리량의 한계가 오니 당연한 현상

- Network + Server send/Recv : Send/Recv latency(gPRC로 image 받고, 모델 output 보내기)
- Server queue : TIS의 스케줄링 latency
- concurrency 30중후반부터, 처리 가능한 트래픽이 초과하기 시작하여, queue latency 급등하기 시작
- Server Compute Input : Image → Tensor 변환 및 필요에 따라 Batch 구성
- concurrency가 늘어남에 따라 계속 증가하다가, 최대치가 됨과 동시에 일정해졌음 → max batch size인 8개로 계속 처리하게 되었기 때문
- Server compute infer : TensorRT Inference 속도
- concurrency가 늘어남에 따라 계속 증가하다가, 최대치가 됨과 동시에 일정해졌음 → max batch size인 8개로 계속 처리하게 되었기 때문
- 1 concurrency일때 p50 latency가 9.666ms

(성능 평가를 돌려놓고, GPU가 괴로워 하는거 보면 기분이 좋아집니다.)
추가 실험 ONNX vs TensorRT
- 같은 모델을 onnx로 서빙했을때와 TensorRT로 서빙했을때 TIS의 Performance 비교
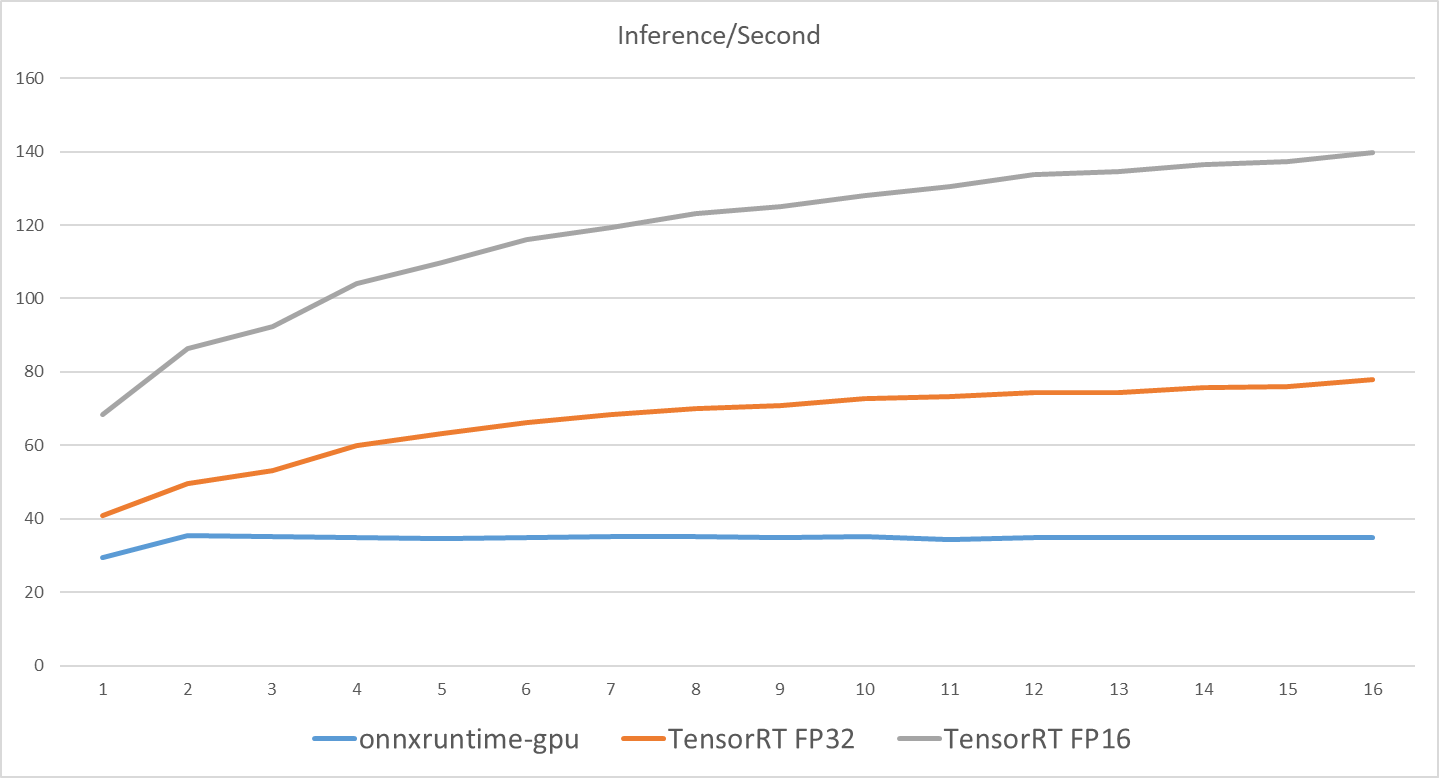
- onnxruntime-gpu 대비 TensorRT(FP16)의 성능이 약 4배(34.934 -> 139.687) 좋아진다.
- (이건 GPU :P100에서 테스트)
결론1 : TIS를 실제 서빙하기 전에, Perfomance Analyzer를 통해 수용 가능한 트래픽을 미리 estimate 할 수 있다.
결론2 : backend의 옵션에 따라 같은 GPU server라도 Performance가 크게 차이 날 수 있다. (앵간하면 TensorRT에 다이나믹 배치 처리 하자)

ML 잡부