Triton Inference Server 부수기
1.Triton Inference Server 부수기 1
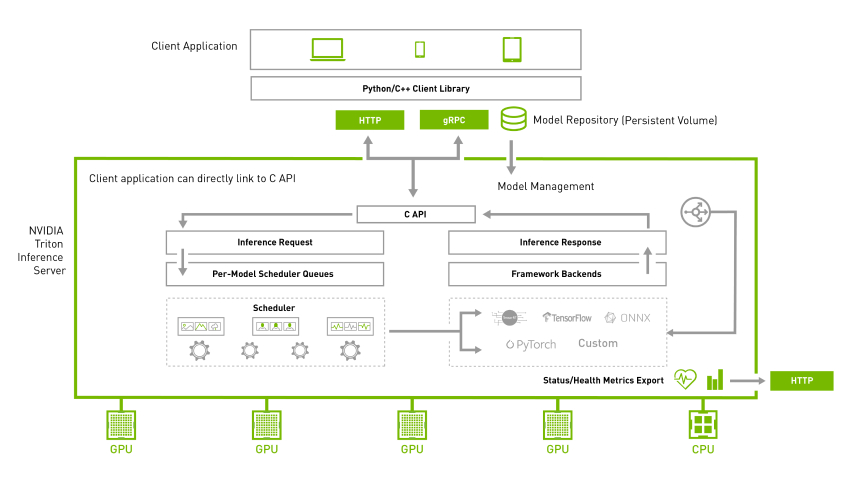
Why Triton Inference Server?
2022년 9월 23일
2.Triton Inference Server 부수기 2
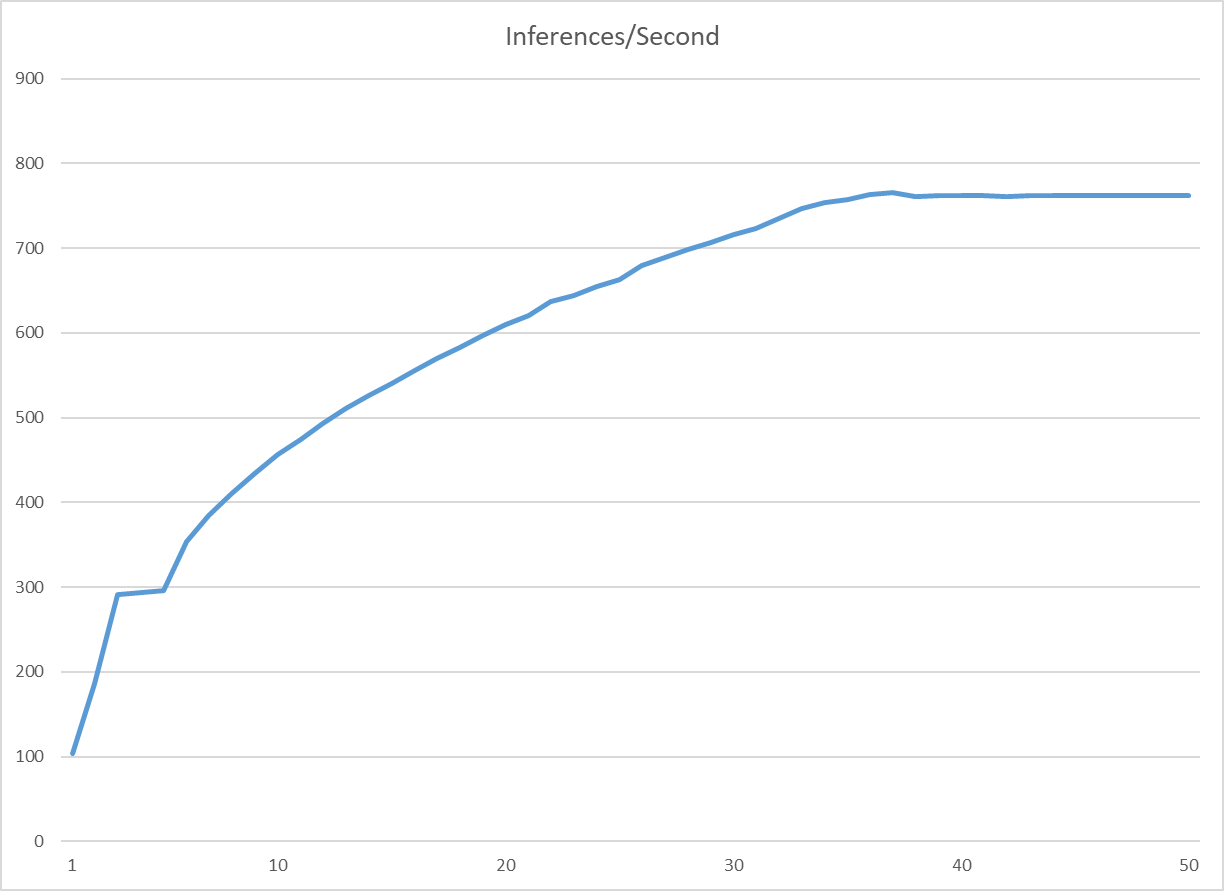
모델 종류 : Yolov7-TensorRTGPU : V100 x 2Maximum batch size 8concurrency : 동시성inference/Second : 1초당 inference 처리량concurrecy가 36일때 가장 높은 효율(765 inference/
2022년 9월 30일
3.Stable Diffusion Inference 최적화 및 서버 구성
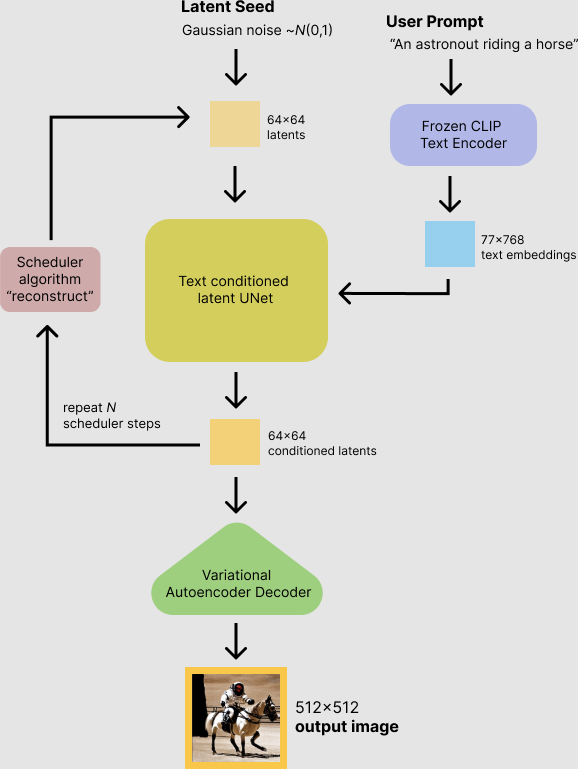
Stable Diffusion 모델은 Large-Scale Model이므로, 서비스를 위해선 고성능 GPU와 높은 Latency가 발생함효율적인 Stable Diffusion 서비스를 위해, 모델의 Latency를 줄이고 안정적인 Server 구성이 필요함Diffuse
2023년 3월 23일