Why Triton Inference Server?
- 다양한 inference Framework 지원(Pytorch, Tensorflow, ONNX, TensorRT)
- 내부 로직이 C++로 구현되어 있어, Python기반 Inference server 보다 빠름(Nivida가 그렇게 자랑함)
- Multi-GPU에도 용이하게끔 GPU 스케쥴링 제공해줌
- Model만 잘 말아서 넣어주면 Server Inference SDK가 뚝딱
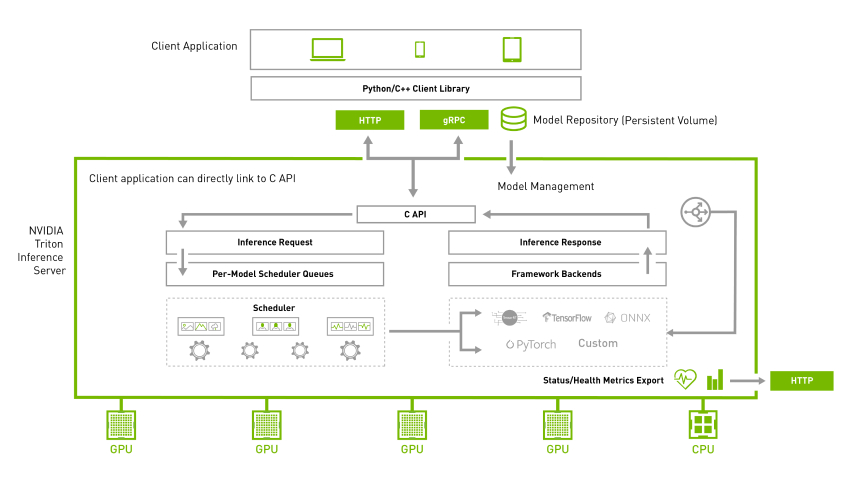

환경설정
사전 준비
- TensorRT 변환 완료된 모델
저는 YOLOv7을 Visdrone Dataset으로 개인적으로 학습한 모델을 사용 - docker, Nivida-docker
Model Repository for Triton Inference Server
#TensorRT model repository
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.plan
#ONNX Model repository
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.onnx
#TorchScript repository
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.pt
#Tensorflow GraphDef Model repository
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.graphdef
#Tensorflow GraphDef Model repository
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.savedmodel/
<saved-model files>
#####USE Case TensorRT###########
$ tree triton-deploy/
triton-deploy/
└── models
└── yolov7_visdrone
├── 1
│ └── model.plan
└── config.pbtxtbackend를 TensorRT로 사용할것이기 때문에 다음과 같이 구성.
#디렉토리 규격에 맞게 생성
mkdir -p triton-deploy/models/yolov7_visdrone/1/
#config file 생성
touch triton-deploy/models/yolov7_visdrone/config.pbtxt
#TensorRT 모델 규격에 맞게 옮겨주기(model.plan으로 이름 재지정)
mv yolov7-fp16-visdrone.engine ./triton-deploy/models/yolov7_visdrone/1/model.plan생성된 config.pbtxt에 TensorRT옵션 주기.
- name: Model directory name
- platform: TensorRT
- max_batch_size: dynamic_batch inference에서 최대값 설정
name: "yolov7_visdrone"
platform: "tensorrt_plan"
max_batch_size: 8
dynamic_batching { }Triton Inference Server 실행
docker run --gpus all --rm --ipc=host --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -p8000:8000 -p8001:8001 -p8002:8002 -v$(pwd)/triton-deploy/models:/models nvcr.io/nvidia/tritonserver:22.06-py3 tritonserver --model-repository=/models --strict-model-config=false --log-verbose 1-v$(pwd)/triton-deploy/models:/models : 로컬에 위치한 서빙을 하고자 하는 모델을 도커 컨테이너 target 디렉토리에 맵핑
8000포트(통신용,grpc) 8001포트(통신용, http), 8002포트(모델 상태 체크용, http)
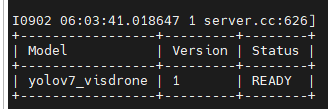
다음과 같은 상태창이 떳다면, Triton Inference Server 셋팅 완료
Triton Client 설정
!pip3 install tritonclient[all] #tritonclient 설치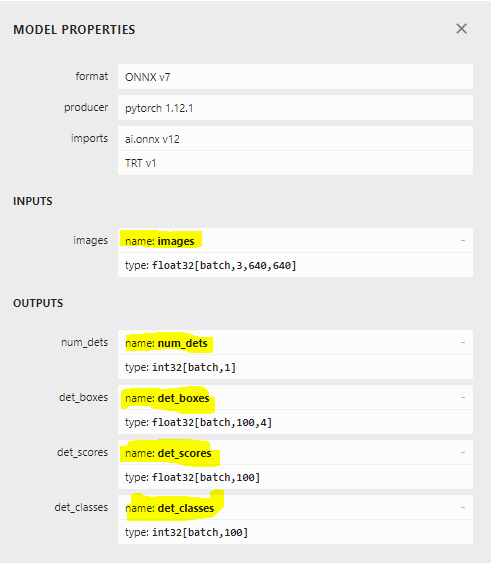
import tritonclient.grpc as grpcclient
#tritonServer 설정 및 연결
triton_client = grpcclient.InferenceServerClient(
url=FLAGS.url, #localhost:8001,
###RestAPI:8000, gRPC:8001,
ssl=FLAGS.ssl, #None
root_certificates=FLAGS.root_certificates,#None
private_key=FLAGS.private_key, #None
certificate_chain=FLAGS.certificate_chain) #none
########### onnx export 당시 input output Name 참조 ###############
INPUT_NAMES = ["images"]
OUTPUT_NAMES = ["num_dets", "det_boxes", "det_scores", "det_classes"]
#####################################################################
#Server <-> Client Input/Ouput 이름 맵핑
inputs = []
outputs = []
inputs.append(grpcclient.InferInput(INPUT_NAMES[0], [1, 3, FLAGS.width, FLAGS.height], "FP32"))
inputs[0].set_data_from_numpy(np.ones(shape=(1, 3, FLAGS.width, FLAGS.height), dtype=np.float32))
outputs.append(grpcclient.InferRequestedOutput(OUTPUT_NAMES[0]))
outputs.append(grpcclient.InferRequestedOutput(OUTPUT_NAMES[1]))
outputs.append(grpcclient.InferRequestedOutput(OUTPUT_NAMES[2]))
outputs.append(grpcclient.InferRequestedOutput(OUTPUT_NAMES[3]))
#Do triton server inferece
results = triton_client.infer(model_name=FLAGS.model, #yolov7_visdrone
inputs=inputs,
outputs=outputs,
client_timeout=FLAGS.client_timeout) #Nonegrpc로 연결하는 간단한 예제입니다.(grpc이므로, 포트 8000으로 연결)
주의해야할 사안으로, model config쪽에 Input/output name을 연결을 안해줬으므로, client단에서 연결해주어야 함.
onnx 모델에서 Input output name을 기억해뒀다가 연결(위 그림 참고)
Triton Inference Server를 통한 Inference 결과 확인
전체 Latency(이미지 전송 + TensorRT Inference + 결과 받기) < 30ms 이하
사용한 모델 : yolov7-w6(103.3GFLOPs)


위(Pytorch Inference, Local GPU), 아래(TensorRT Inference, Triton Inference Server)

ML 잡부