[zerobase_데이터취업스쿨] 머신러닝_~CH7-11 (credit card fraud데이터, SMOTE 오버샘플링, 서포트벡터머신(SVM), borderlineSMOTE)
머신러닝
목록 보기
8/11
12. SVMSMOTE로 결정경계 주변의 미묘한 패턴을 잡아내어 소수클래스의 오버샘플링을 해주고 성능평가하기
오버샘플링 비율
- 오버샘플링을 할 때, 정확한 비율은 데이터의 특성, 모델의 종류, 그리고 특정 문제의 요구사항에 따라 달라질 수 있습니다. 일반적인 규칙은 없지만, 목표는 모델이 두 클래스 모두에서 충분히 학습할 수 있도록 하는 것입니다. 너무 과도하게 오버샘플링을 하면, 모델이 소수 클래스의 합성 샘플에 과적합되어 실제 성능이 저하될 수 있습니다.
비율 선택
- 일부 연구나 실제 적용 사례에서는 1:1 비율로 오버샘플링하는 것이 좋다고 제안하지만, 이는 항상 최적의 선택은 아닙니다. 대신, 다양한 비율로 실험하여 검증 세트에서의 성능을 기준으로 최적의 비율을 찾는 것이 좋습니다.
결정 경계에서의 오버샘플링
- 신용 카드 사기와 같은 민감한 문제에서는 결정 경계 근처에서 오버샘플링하는 것이 특히 유용할 수 있습니다. BorderlineSMOTE나 SVMSMOTE와 같은 방법이 이를 위해 설계되었습니다. 이들 방법은 모델이 사기 거래와 정상 거래를 구분하는 결정 경계를 더 잘 이해하고 학습하도록 도와줍니다
결정 경계 오버샘플링의 장점
- 이러한 접근 방식은 모델이 더 복잡하고 미묘한 패턴을 학습할 수 있도록 도와, 실제 사기 거래를 더 정확히 감지하는 데 도움이 될 수 있습니다
실제 적용
- 교차 검증: 모델의 성능을 평가할 때는 오버샘플링된 데이터셋에 대해 교차 검증을 적용하여, 모델이 새로운 데이터에 대해 얼마나 잘 일반화되는지 확인하는 것이 중요합니다
성능 지표 선택
- 불균형 데이터셋에서는 정확도(accuracy)만으로 모델의 성능을 평가하는 것이 적절하지 않습니다. 대신, 정밀도(precision), 재현율(recall), F1 점수, AUC-ROC 곡선과 같은 지표를 사용하는 것이 더 유용합니다


from imblearn.over_sampling import SVMSMOTEX = raw_df.drop(['Class','Time'],axis=1)
y = raw_df['Class']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)svmsmote = SVMSMOTE(sampling_strategy = 0.55, random_state=42,m_neighbors = 5, n_jobs = -1)X_re_train, y_re_train = svmsmote.fit_resample(X_train,y_train)y_re_train.value_counts()Class
0 227451
1 125098
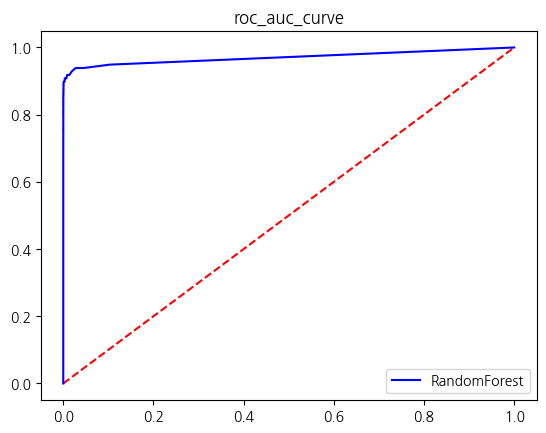
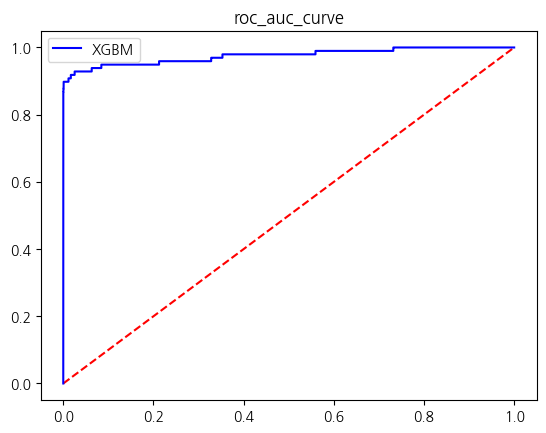
Name: count, dtype: int64res = get_score_df(models,X_re_train,y_re_train,X_test,y_test)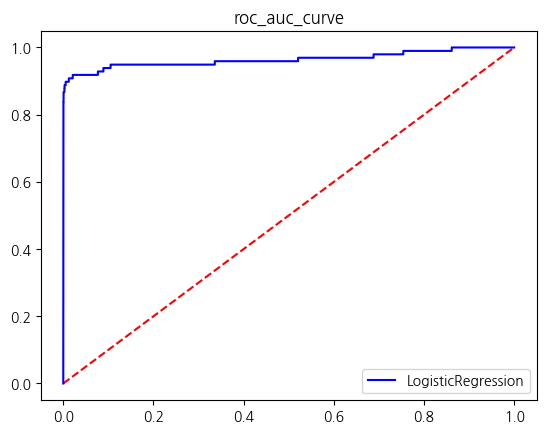
[LightGBM] [Info] Number of positive: 125098, number of negative: 227451
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.012191 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 7395
[LightGBM] [Info] Number of data points in the train set: 352549, number of used features: 29
[LightGBM] [Warning] No further splits with positive gain, best gain: -inf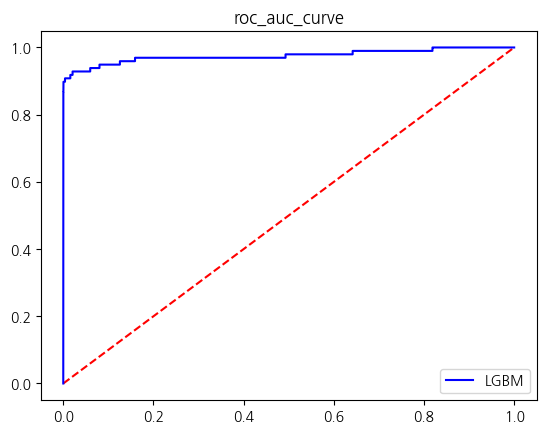
결론: SVMSMOTE를 사용하여 소수클래스: 다수클래스를 0.55 : 1의 비율로 오버샘플링한 성능평가 결과
- V20,V21,V23칼럼의 Class0인 것의 Outlier 제거한 모델
- 스케일이 혼자 많이 달랐던 Amount열을 standardscaling한 모델
- Amount열의 분포를 고르게하는 동시에 스케일링도 한 log1p적용 모델
- V20, V21, V23칼럼의 Class0인 것의 Outlier 제거한 후 Amount열을 로그변환한 모델
- 그 전 모델 중 모든 지표에서 가장 성능이 높았던
- V20,V21,V23칼럼 Outlier제거 모델과 비교하면 SVMSMOTE로 소수클래스를 오버샘플링한 모델의 auc score는 가장 높았으나
- 로지스틱 회귀에서의 precision이 굉장히 낮아져 f1_score도 굉장히 낮았으며
- RamdomForest의 경우 precision이 1.2정도 하락하고 recall이 0.1정도 올랐으나 f1은 떨어졌다 auc score는 0.05 증가
- XGBM의 경우 f1은 0.7정도 하락했고 auc score은 0.1 증가
- LGBM의 경우 f1은 0.27정도 하락했고 auc score은 0.1 증가함
SVMSMOTE를 사용하여 오버샘플링한 모델의 성능평가 결과
res| accuracy | precision | recall | f1_score | roc_auc_score | |
|---|---|---|---|---|---|
| LogisticRegression | 0.994997 | 0.240997 | 0.887755 | 0.379085 | 0.941468 |
| RandomForest | 0.999491 | 0.848485 | 0.857143 | 0.852792 | 0.928440 |
| XGBM | 0.999438 | 0.817308 | 0.867347 | 0.841584 | 0.933506 |
| LGBM | 0.999596 | 0.912088 | 0.846939 | 0.878307 | 0.923399 |
