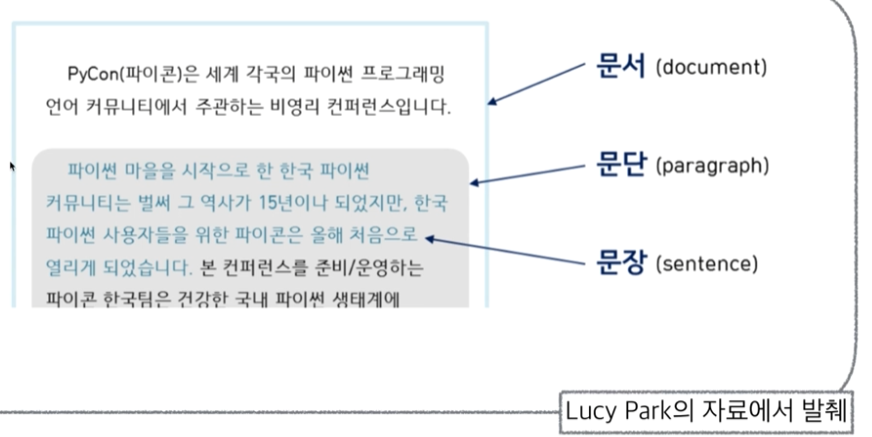
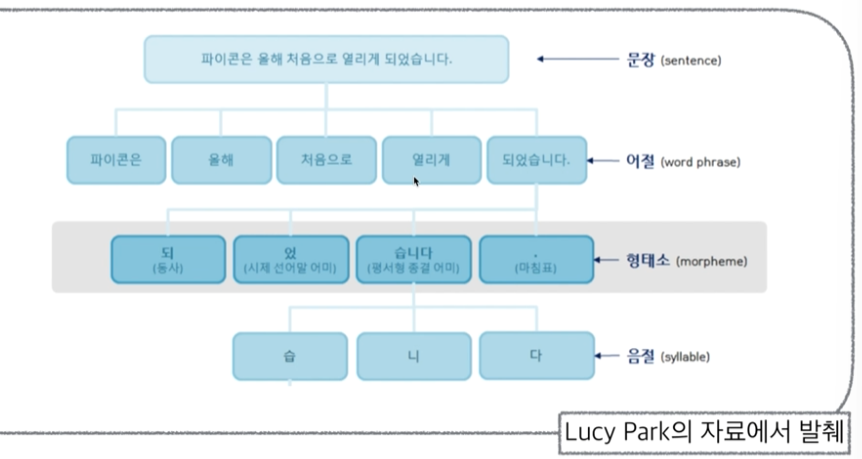
CH8-03. 자연어 처리(형태소 분석)
1. Kkma(꼬꼬마) 엔진 사용 분석
from konlpy.tag import Kkma
kkma = Kkma()
kkma.sentences('한국어 분석을 시작합니다 재미있어요~~')
['한국어 분석을 시작합니다', '재미있어요~~']
kkma.nouns('한국어 분석을 시작합니다 재미있어요~~')
['한국어', '분석']
kkma.pos('한국어 분석을 시작합니다 재미있어요~~')
[('한국어', 'NNG'),
('분석', 'NNG'),
('을', 'JKO'),
('시작하', 'VV'),
('ㅂ니다', 'EFN'),
('재미있', 'VA'),
('어요', 'EFN'),
('~~', 'SW')]
2. Hannanum 엔진으로 분석
from konlpy.tag import Hannanum
hannanum = Hannanum()
hannanum.morphs('한국어 분석을 시작합니다 재미있어요~~')
['한국어', '분석', '을', '시작', '하', 'ㅂ니다', '재미있', '어요', '~~']
hannanum.pos('한국어 분석을 시작합니다 재미있어요~~')
[('한국어', 'N'),
('분석', 'N'),
('을', 'J'),
('시작', 'N'),
('하', 'X'),
('ㅂ니다', 'E'),
('재미있', 'P'),
('어요', 'E'),
('~~', 'S')]
hannanum.nouns('한국어 분석을 시작합니다 재미있어요~~')
['한국어', '분석', '시작']
3. Okt 엔진 사용하여 분석
from konlpy.tag import Okt
t = Okt()
t.nouns('한국어 분석을 시작합니다 재미있어요~~')
['한국어', '분석', '시작']
t.morphs('한국어 분석을 시작합니다 재미있어요~~')
['한국어', '분석', '을', '시작', '합니다', '재미있어요', '~~']
t.pos('한국어 분석을 시작합니다 재미있어요~~')
[('한국어', 'Noun'),
('분석', 'Noun'),
('을', 'Josa'),
('시작', 'Noun'),
('합니다', 'Verb'),
('재미있어요', 'Adjective'),
('~~', 'Punctuation')]
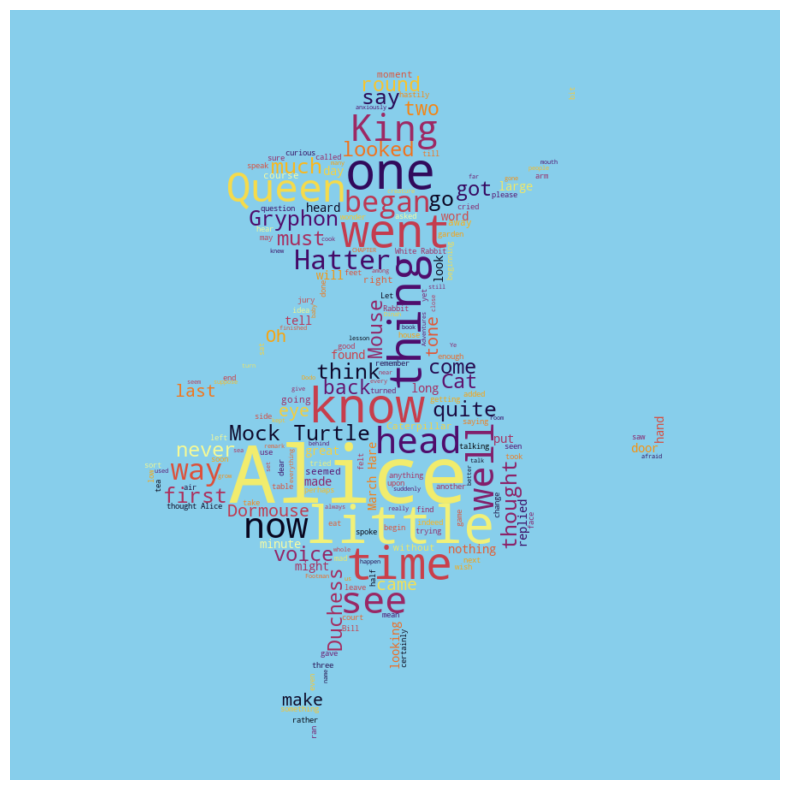
CH8-04 워드클라우드 만들기(이상한 나라의 앨리스 활용)
from wordcloud import WordCloud, STOPWORDS
import numpy as np
from PIL import Image
with open('../datas/06_alice.txt', mode = 'r') as file:
text = file.read()
print(text)
Project Gutenberg's Alice's Adventures in Wonderland, by Lewis Carroll
This eBook is for the use of anyone anywhere at no cost and with
almost no restrictions whatsoever. You may copy it, give it away or
re-use it under the terms of the Project Gutenberg License included
with this eBook or online at www.gutenberg.org
Title: Alice's Adventures in Wonderland
Author: Lewis Carroll
Posting Date: June 25, 2008 [EBook #11]
Release Date: March, 1994
[Last updated: December 20, 2011]
Language: English
*** START OF THIS PROJECT GUTENBERG EBOOK ALICE'S ADVENTURES IN WONDERLAND ***
ALICE'S ADVENTURES IN WONDERLAND
Lewis Carroll
THE MILLENNIUM FULCRUM EDITION 3.0
CHAPTER I. Down the Rabbit-Hole
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?' [후략...]
1. STOPWORDS를 활용하여 워드클라우드에 said를 고려하지 않도록 한다
- np.array(Image.open))을 통하여 넘파이 배열에 픽셀값을 저장한다
여러가지 cmap 옵션들
matplotlib에는 많은 내장 colormap이 있으며, 일부 일반적인 cmap 옵션은 다음과 같습니다:
'viridis': 연속적인 데이터에 적합한 기본 colormap으로, 밝은 노란색에서 어두운 파란색으로 변화합니다.
'plasma': 'viridis'와 비슷하지만, 색상 범위가 더 밝습니다.
'inferno': 밝은 노란색에서 어두운 붉은색으로 변화하는 또 다른 연속적인 colormap입니다.
'magma': 'inferno'와 비슷하지만, 보라색이 강조됩니다.
'cividis': 색맹 사용자를 위해 최적화된 버전의 'viridis'입니다.
'Greys': 다양한 그레이스케일 톤을 표현합니다.
'Purples': 다양한 보라색 톤을 표현합니다.
'Blues': 다양한 파란색 톤을 표현합니다.
'Greens': 다양한 녹색 톤을 표현합니다.
'Oranges': 다양한 주황색 톤을 표현합니다.
'Reds': 다양한 빨간색 톤을 표현합니다.
'YlOrBr': 노란색에서 주황색, 그리고 갈색으로 변화하는 colormap입니다.
'YlOrRd': 노란색에서 주황색, 그리고 빨간색으로 변화하는 colormap입니다.
'OrRd': 주황색에서 빨간색으로 변화하는 colormap입니다.
'PuRd': 보라색에서 빨간색으로 변화하는 colormap입니다.
'RdPu': 빨간색에서 보라색으로 변화하는 colormap입니다.
'BuPu': 파란색에서 보라색으로 변화하는 colormap입니다.
'GnBu': 녹색에서 파란색으로 변화하는 colormap입니다.
'PuBu': 보라색에서 파란색으로 변화하는 colormap입니다.
'YlGnBu': 노란색에서 녹색, 그리고 파란색으로 변화하는 colormap입니다.
'PuBuGn': 보라색에서 파란색, 그리고 녹색으로 변화하는 colormap입니다.
'BuGn': 파란색에서 녹색으로 변화하는 colormap입니다.
'YlGn': 노란색에서``` 녹색으로 변화하는 colormap입니다.
```python
alice_mask = np.array(Image.open('../datas/06_alice_mask.png'))
stopwords = set(STOPWORDS)
stopwords.add('said')
np.unique(alice_mask)
array([ 0, 255], dtype=uint8)
print(alice_mask.shape)
(900, 900)
import koreanize_matplotlib
import matplotlib.pyplot as plt
plt.figure(figsize=(7,7))
plt.imshow(alice_mask, cmap='YlOrRd')
plt.show()
wc = WordCloud(
background_color = 'skyblue', colormap = 'inferno', mask = alice_mask, stopwords = stopwords
)
wc.generate(text)
plt.figure(figsize=(10,10))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
CH8-05.스타워즈 워드클라우드 만들기
with open('../datas/06_a_new_hope.txt', mode = 'r') as file:
starwars = file.read()
print(starwars)
STAR WARS
Episode IV
A NEW HOPE
From the
JOURNAL OF THE WHILLS
by
George Lucas
Revised Fourth Draft
January 15, 1976
LUCASFILM LTD.
A long time ago, in a galaxy far, far, away...
A vast sea of stars serves as the backdrop for the main title.
War drums echo through the heavens as a rollup slowly crawls
into infinity.
[후략...]
starwars.replace("LUKE'S", 'Luke')
starwars.replace('HAN', 'Han')
stopwords = set(STOPWORDS)
stopwords.add('int')
stopwords.add('ext')
starwars_mask = np.array(Image.open('../datas/starwarswars.png'))
starwars_mask = np.where(starwars_mask > 0, 255, 0)
plt.figure(figsize=(7,7))
plt.imshow(starwars_mask, cmap = 'RdPu')
plt.show()
wc = WordCloud(
background_color = 'black', colormap = 'PuBuGn', mask = starwars_mask, stopwords = stopwords, max_words = 1000
)
wc.generate(starwars)
<wordcloud.wordcloud.WordCloud at 0x2b9ab6b9390>
plt.figure(figsize=(10,10))
plt.imshow(wc)
plt.axis('off')
plt.show()

CH8-06. 육아휴직관련 법안 분석
import nltk
from konlpy.corpus import kobill
files_ko = kobill.fileids()
doc_ko = kobill.open('1809890.txt').read()
from konlpy.tag import Okt
t = Okt()
tokens_ko = t.nouns(doc_ko)
kor = nltk.Text(tokens_ko, name = '육아휴직법안')
kor
<Text: 육아휴직법안>
1. 사용된 총 단어의 수
len(kor.tokens)
735
2. 사용된 단어의 고유값
len(set(kor.tokens))
250
3. 사용된 단어의 빈도수 분석
kor.vocab()
FreqDist({'육아휴직': 38, '발생': 19, '만': 18, '이하': 18, '비용': 17, '액': 17, '경우': 16, '세': 16, '자녀': 14, '고용': 14, ...})
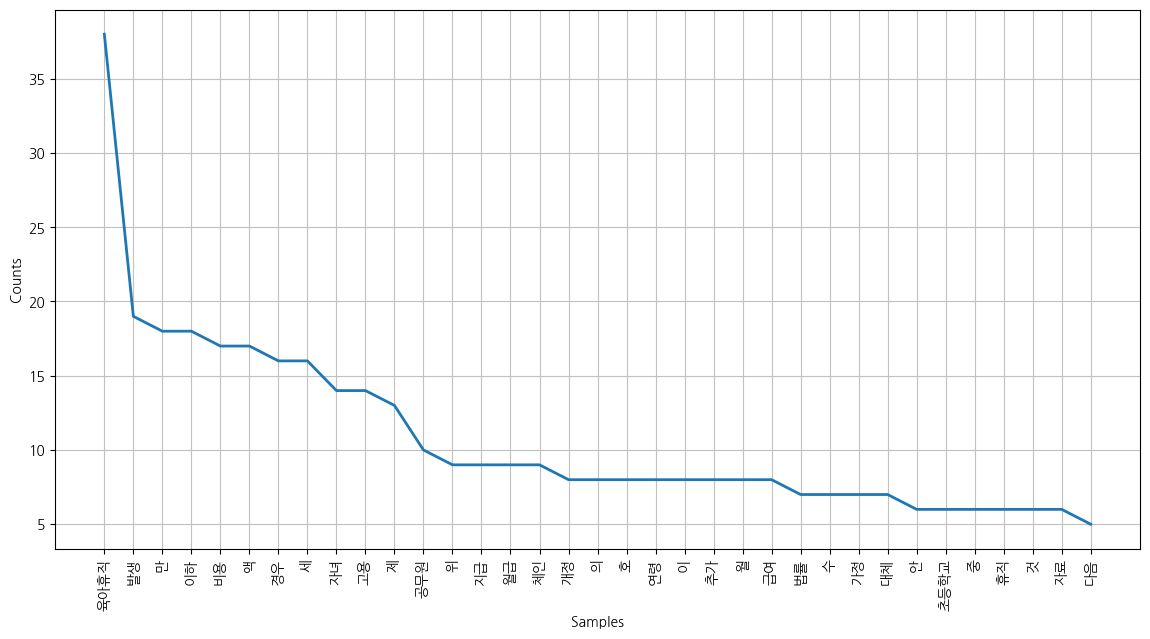
4. 빈도수가 높은 단어 35위까지 그래프 시각화
plt.figure(figsize=(14,7))
kor.plot(35)
plt.show()
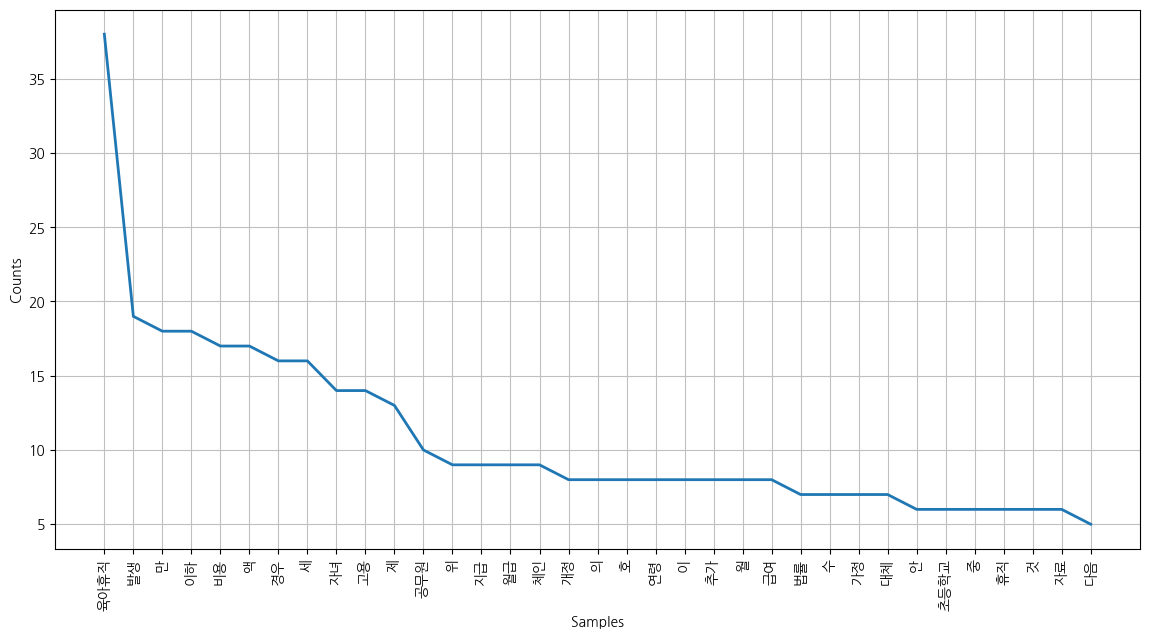
5. 의미있는 단어만 추출하기 위해 STOPWORDS 지정하고 다시 시각화
stopwords = set(STOPWORDS)
stopwords = [
'만','의','호','이','수','안','중','것','위','제','세','액','로','가','를','은','는','나',
'월','표','명','및','법','생','략',
'.',')','(',"'",'-',').'
]
from nltk import FreqDist
kor_dist = [words for words in kor if words not in stopwords]
kor_freqdist = FreqDist(kor_dist)
plt.figure(figsize=(14,7))
kor.plot(35)
plt.show()
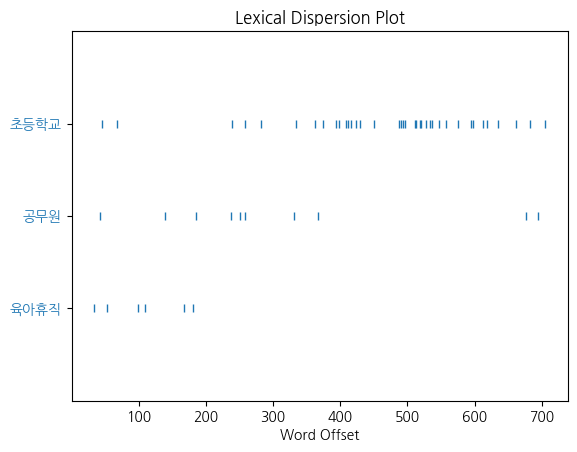
6. nltk의 count(), concordance(), collocation(), dispersion_plot()
kor.count('육아휴직')
38
concordance() 단어 좌우에 있는 단어를 표시해줌
kor.concordance('휴직')
Displaying 6 of 6 matches:
칙 이 법 공포 날 시행 신 구조 문대비 표 현 행 개 정 안 제 휴직 생 략 제 휴직 현행 공무원 다음 각 호의 느 하나 해당 사유 직
날 시행 신 구조 문대비 표 현 행 개 정 안 제 휴직 생 략 제 휴직 현행 공무원 다음 각 호의 느 하나 해당 사유 직 임용 휴직 명 수
략 제 휴직 현행 공무원 다음 각 호의 느 하나 해당 사유 직 임용 휴직 명 수 다만 제 호 의 경우 대통령령 정 사정 직 명 생 략 현행
유 재정 요인 개정안 국가공무원 법 제 항제 호 중 국가공무원 육아 휴직 가능 자녀 연령 만 세 이하 만 세 이하 방공 무 법 제 항제 호
대비 육아휴직 지급 임금 더 이상 발생 따라서 실제 발생 비용 육 휴직 지급 월 급여 액 연령 확대 발생 비용 인 육아휴직 월급 액 체인
용 발생 행정안전부 통계 자료 행정안전부 통계 연감 지방 공무원 육 휴직 현황 자료 여기 육아휴직 발생 경우 체인 주로 임용 기자 일용직 활
plt.figure(figsize=(14,7))
kor.dispersion_plot(['육아휴직','공무원','초등학교'])
plt.show()
<Figure size 1400x700 with 0 Axes>
kor.collocations()
초등학교 저학년; 근로자 육아휴직; 육아휴직 대상자; 공무원 육아휴직
7. wordcloud 그려보기
data = kor.vocab().most_common(100)
wc = WordCloud(
font_path = 'C:/Windows/Fonts/NanumSquareR.ttf',
relative_scaling = 0.2,
colormap = 'magma',
background_color = 'white',
).generate_from_frequencies(dict(data))
plt.figure(figsize=(7,7))
plt.imshow(wc)
plt.axis('off')
plt.show()

CH8-07. Naive Bayes를 이용한 영어 감성 분석
from nltk.tokenize import word_tokenize
import nltk
train = [
('i like you', 'pos'),
('i hate you', 'neg'),
('you like me', 'neg'),
('i like her', 'pos')
]
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0])
)
all_words
{'hate', 'her', 'i', 'like', 'me', 'you'}
1. Naive Bayes 트레인하기 위한 훈련세트 생성하기
t = [({word: (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]
t
[({'like': True,
'i': True,
'you': True,
'her': False,
'hate': False,
'me': False},
'pos'),
({'like': False,
'i': True,
'you': True,
'her': False,
'hate': True,
'me': False},
'neg'),
({'like': True,
'i': False,
'you': True,
'her': False,
'hate': False,
'me': True},
'neg'),
({'like': True,
'i': True,
'you': False,
'her': True,
'hate': False,
'me': False},
'pos')]
clf = nltk.NaiveBayesClassifier.train(t)
clf.show_most_informative_features()
Most Informative Features
hate = False pos : neg = 1.7 : 1.0
her = False neg : pos = 1.7 : 1.0
i = True pos : neg = 1.7 : 1.0
like = True pos : neg = 1.7 : 1.0
me = False pos : neg = 1.7 : 1.0
you = True neg : pos = 1.7 : 1.0
2. 훈련된 NaiveBayes분류기를 통해 새로운 문장으로 test해보기
test_sentence = 'i like me like her'
test_sent_features = {
word.lower(): (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sent_features
{'like': True, 'i': True, 'you': False, 'her': True, 'hate': False, 'me': True}
clf.classify(test_sent_features)
'pos'
CH8-08: NaiveBayes를 통해 한글 자연어 감성분석
train = [
('나는 강아지가 좋아','pos'),
('난 집가서 강아지랑 놀거야', 'pos'),
('난 수업이 지루해','neg'),
('고양이도 좋아', 'pos'),
('강아지는 예뻐서 좋아', 'pos')
]
all_words = set(
word for sentence in train for word in word_tokenize(sentence[0])
)
all_words
{'강아지가',
'강아지는',
'강아지랑',
'고양이도',
'나는',
'난',
'놀거야',
'수업이',
'예뻐서',
'좋아',
'지루해',
'집가서'}
t = [({word: (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]
t
[({'강아지가': True,
'좋아': True,
'강아지는': False,
'나는': True,
'고양이도': False,
'예뻐서': False,
'지루해': False,
'난': False,
'놀거야': False,
'집가서': False,
'수업이': False,
'강아지랑': False},
'pos'),
({'강아지가': False,
'좋아': False,
'강아지는': False,
'나는': False,
'고양이도': False,
'예뻐서': False,
'지루해': False,
'난': True,
'놀거야': True,
'집가서': True,
'수업이': False,
'강아지랑': True},
'pos'),
({'강아지가': False,
'좋아': False,
'강아지는': False,
'나는': False,
'고양이도': False,
'예뻐서': False,
'지루해': True,
'난': True,
'놀거야': False,
'집가서': False,
'수업이': True,
'강아지랑': False},
'neg'),
({'강아지가': False,
'좋아': True,
'강아지는': False,
'나는': False,
'고양이도': True,
'예뻐서': False,
'지루해': False,
'난': False,
'놀거야': False,
'집가서': False,
'수업이': False,
'강아지랑': False},
'pos'),
({'강아지가': False,
'좋아': True,
'강아지는': True,
'나는': False,
'고양이도': False,
'예뻐서': True,
'지루해': False,
'난': False,
'놀거야': False,
'집가서': False,
'수업이': False,
'강아지랑': False},
'pos')]
clf = nltk.NaiveBayesClassifier.train(t)
clf.show_most_informative_features()
Most Informative Features
난 = True neg : pos = 2.5 : 1.0
좋아 = False neg : pos = 2.5 : 1.0
강아지가 = False neg : pos = 1.1 : 1.0
강아지는 = False neg : pos = 1.1 : 1.0
강아지랑 = False neg : pos = 1.1 : 1.0
고양이도 = False neg : pos = 1.1 : 1.0
나는 = False neg : pos = 1.1 : 1.0
놀거야 = False neg : pos = 1.1 : 1.0
예뻐서 = False neg : pos = 1.1 : 1.0
집가서 = False neg : pos = 1.1 : 1.0
test_sentence = '나는 크림이라는 강아지가 좋아서 집에 빨리 갈거야'
test_sent_features = {
word.lower(): (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sent_features
{'강아지가': True,
'좋아': False,
'강아지는': False,
'나는': True,
'고양이도': False,
'예뻐서': False,
'지루해': False,
'난': False,
'놀거야': False,
'집가서': False,
'수업이': False,
'강아지랑': False}
clf.classify(test_sent_features)
'pos'
1. 형태소 분석을 위해 조사를 태그로 붙여보자
from konlpy.tag import Okt
pos_tagger = Okt()
def tokenize(doc):
return pos_tagger.pos(doc,norm=True,join=True,stem=True)
train_docs = [(tokenize(row[0]),row[1]) for row in train]
train_docs
[(['나/Noun', '는/Josa', '강아지/Noun', '가/Josa', '좋다/Adjective'], 'pos'),
(['난/Noun', '지다/Verb', '강아지/Noun', '랑/Josa', '놀다/Verb'], 'pos'),
(['난/Noun', '수업/Noun', '이/Josa', '지루하다/Adjective'], 'neg'),
(['고양이/Noun', '도/Josa', '좋다/Adjective'], 'pos'),
(['강아지/Noun', '는/Josa', '예쁘다/Adjective', '좋다/Adjective'], 'pos')]
tokens = [t for d in train_docs for t in d[0]]
tokens
['나/Noun',
'는/Josa',
'강아지/Noun',
'가/Josa',
'좋다/Adjective',
'난/Noun',
'지다/Verb',
'강아지/Noun',
'랑/Josa',
'놀다/Verb',
'난/Noun',
'수업/Noun',
'이/Josa',
'지루하다/Adjective',
'고양이/Noun',
'도/Josa',
'좋다/Adjective',
'강아지/Noun',
'는/Josa',
'예쁘다/Adjective',
'좋다/Adjective']
def term_exists(doc):
return {word: (word in set(doc)) for word in tokens}
train_xy = [(term_exists(d),c) for d,c in train_docs]
train_xy
[({'나/Noun': True,
'는/Josa': True,
'강아지/Noun': True,
'가/Josa': True,
'좋다/Adjective': True,
'난/Noun': False,
'지다/Verb': False,
'랑/Josa': False,
'놀다/Verb': False,
'수업/Noun': False,
'이/Josa': False,
'지루하다/Adjective': False,
'고양이/Noun': False,
'도/Josa': False,
'예쁘다/Adjective': False},
'pos'),
({'나/Noun': False,
'는/Josa': False,
'강아지/Noun': True,
'가/Josa': False,
'좋다/Adjective': False,
'난/Noun': True,
'지다/Verb': True,
'랑/Josa': True,
'놀다/Verb': True,
'수업/Noun': False,
'이/Josa': False,
'지루하다/Adjective': False,
'고양이/Noun': False,
'도/Josa': False,
'예쁘다/Adjective': False},
'pos'),
({'나/Noun': False,
'는/Josa': False,
'강아지/Noun': False,
'가/Josa': False,
'좋다/Adjective': False,
'난/Noun': True,
'지다/Verb': False,
'랑/Josa': False,
'놀다/Verb': False,
'수업/Noun': True,
'이/Josa': True,
'지루하다/Adjective': True,
'고양이/Noun': False,
'도/Josa': False,
'예쁘다/Adjective': False},
'neg'),
({'나/Noun': False,
'는/Josa': False,
'강아지/Noun': False,
'가/Josa': False,
'좋다/Adjective': True,
'난/Noun': False,
'지다/Verb': False,
'랑/Josa': False,
'놀다/Verb': False,
'수업/Noun': False,
'이/Josa': False,
'지루하다/Adjective': False,
'고양이/Noun': True,
'도/Josa': True,
'예쁘다/Adjective': False},
'pos'),
({'나/Noun': False,
'는/Josa': True,
'강아지/Noun': True,
'가/Josa': False,
'좋다/Adjective': True,
'난/Noun': False,
'지다/Verb': False,
'랑/Josa': False,
'놀다/Verb': False,
'수업/Noun': False,
'이/Josa': False,
'지루하다/Adjective': False,
'고양이/Noun': False,
'도/Josa': False,
'예쁘다/Adjective': True},
'pos')]
clf = nltk.NaiveBayesClassifier.train(train_xy)
clf.show_most_informative_features()
Most Informative Features
강아지/Noun = False neg : pos = 2.5 : 1.0
난/Noun = True neg : pos = 2.5 : 1.0
좋다/Adjective = False neg : pos = 2.5 : 1.0
는/Josa = False neg : pos = 1.5 : 1.0
가/Josa = False neg : pos = 1.1 : 1.0
고양이/Noun = False neg : pos = 1.1 : 1.0
나/Noun = False neg : pos = 1.1 : 1.0
놀다/Verb = False neg : pos = 1.1 : 1.0
도/Josa = False neg : pos = 1.1 : 1.0
랑/Josa = False neg : pos = 1.1 : 1.0
test_sentence = '난 수업 마치면 강아지 크림이와 놀거야'
test_docs = pos_tagger.pos(test_sentence)
test_docs
[('난', 'Noun'),
('수업', 'Noun'),
('마치', 'Noun'),
('면', 'Josa'),
('강아지', 'Noun'),
('크림', 'Noun'),
('이', 'Suffix'),
('와', 'Josa'),
('놀거야', 'Verb')]
test_sent_features = {
word: (word in tokens) for word in test_docs
}
test_sent_features
{('난', 'Noun'): False,
('수업', 'Noun'): False,
('마치', 'Noun'): False,
('면', 'Josa'): False,
('강아지', 'Noun'): False,
('크림', 'Noun'): False,
('이', 'Suffix'): False,
('와', 'Josa'): False,
('놀거야', 'Verb'): False}
clf.classify(test_sent_features)
'pos'
CH8-09 문장을 벡터화해서 유사도 측정하기
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1)
1. 형태소로 나눠주기
from konlpy.tag import Okt
t = Okt()
contents = [
'내일은 오늘보다 더 나을 거야',
'희망이 있기에 우리는 꿈꾼다',
'어둠 뒤에 빛이 온다',
'꿈은 실현될 희망의 신호다'
]
contents_morphs = [t.morphs(word) for word in contents]
contents_morphs
[['내일', '은', '오늘', '보다', '더', '나을', '거야'],
['희망이', '있기에', '우리', '는', '꿈꾼다'],
['어둠', '뒤', '에', '빛', '이', '온다'],
['꿈', '은', '실현', '될', '희망', '의', '신호', '다']]
2. 형태소로 분석된 문장들을 띄어쓰기 기준으로 합쳐보자
contents_for_vectorize = []
for content in contents_morphs:
sentence = ''
for word in content:
sentence += ' '+ word
contents_for_vectorize.append(sentence)
contents_for_vectorize
[' 내일 은 오늘 보다 더 나을 거야',
' 희망이 있기에 우리 는 꿈꾼다',
' 어둠 뒤 에 빛 이 온다',
' 꿈 은 실현 될 희망 의 신호 다']
X = vectorizer.fit_transform(contents_for_vectorize)
X
<4x14 sparse matrix of type '<class 'numpy.int64'>'
with 14 stored elements in Compressed Sparse Row format>
num_samples, num_features = X.shape
num_samples, num_features
(4, 14)
print(len(vectorizer.get_feature_names_out()), vectorizer.get_feature_names_out())
14 ['거야' '꿈꾼다' '나을' '내일' '보다' '신호' '실현' '어둠' '오늘' '온다' '우리' '있기에' '희망' '희망이']
3. 전치행렬로 각 feature들이 4개 문장에 포함되는지 알 수 있다.
- 밑의 array에서 각 행은 하나의 feature에 대한 값이고
- 각 열은 한 문장임
- X의 각 형태소들이 4 문장 중 어디에 속하는지를 표시해주는 array임
X.toarray().transpose()
array([[1, 0, 0, 0],
[0, 1, 0, 0],
[1, 0, 0, 0],
[1, 0, 0, 0],
[1, 0, 0, 0],
[0, 0, 0, 1],
[0, 0, 0, 1],
[0, 0, 1, 0],
[1, 0, 0, 0],
[0, 0, 1, 0],
[0, 1, 0, 0],
[0, 1, 0, 0],
[0, 0, 0, 1],
[0, 1, 0, 0]], dtype=int64)
4. 유사도를 측정할 문장을 설정하자
new_contents = '나는 내일의 희망을 실현한다'
new_contents_morph = t.morphs(new_contents)
new_contents_vectorize = []
sentence = ''
for word in new_contents_morph:
sentence += ' ' + word
new_contents_vectorize.append(sentence)
new_contents_vectorize
[' 나 는 내일 의 희망 을 실현 한다']
new_contents_morph
['나', '는', '내일', '의', '희망', '을', '실현', '한다']
new_contents_vec = vectorizer.transform(new_contents_vectorize)
new_contents_vec
<1x14 sparse matrix of type '<class 'numpy.int64'>'
with 3 stored elements in Compressed Sparse Row format>
new_contents_vec.toarray()
array([[0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0]], dtype=int64)
5. 테스트할 문장과 처음에 지정해준 contents의 4문장과의 거리(유사도)측정하기
import scipy
def dist_raw(v1, v2):
delta = v1 - v2
return scipy.linalg.norm(delta.toarray())
dist = [dist_raw(each, new_contents_vec) for each in X]
dist
[2.449489742783178, 2.6457513110645907, 2.23606797749979, 1.4142135623730951]
print('Best post is:', contents[dist.index(min(dist))], ', dist:', min(dist))
print('Test post is:', new_contents)
Best post is: 꿈은 실현될 희망의 신호다 , dist: 1.4142135623730951
Test post is: 나는 내일의 희망을 실현한다
CH8-10 TF-IDF vectorizer를 사용하여 문서내의 유사도 측정하기
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
contents
['내일은 오늘보다 더 나을 거야', '희망이 있기에 우리는 꿈꾼다', '어둠 뒤에 빛이 온다', '꿈은 실현될 희망의 신호다']
new_contents
'나는 내일의 희망을 실현한다'
contents_for_vectorize
[' 내일 은 오늘 보다 더 나을 거야',
' 희망이 있기에 우리 는 꿈꾼다',
' 어둠 뒤 에 빛 이 온다',
' 꿈 은 실현 될 희망 의 신호 다']
new_contents_vectorize
[' 나 는 내일 의 희망 을 실현 한다']
X = vectorizer.fit_transform(contents_for_vectorize)
X
<4x14 sparse matrix of type '<class 'numpy.float64'>'
with 14 stored elements in Compressed Sparse Row format>
X.toarray().transpose()
array([[0.4472136 , 0. , 0. , 0. ],
[0. , 0.5 , 0. , 0. ],
[0.4472136 , 0. , 0. , 0. ],
[0.4472136 , 0. , 0. , 0. ],
[0.4472136 , 0. , 0. , 0. ],
[0. , 0. , 0. , 0.57735027],
[0. , 0. , 0. , 0.57735027],
[0. , 0. , 0.70710678, 0. ],
[0.4472136 , 0. , 0. , 0. ],
[0. , 0. , 0.70710678, 0. ],
[0. , 0.5 , 0. , 0. ],
[0. , 0.5 , 0. , 0. ],
[0. , 0. , 0. , 0.57735027],
[0. , 0.5 , 0. , 0. ]])
y = vectorizer.transform(new_contents_vectorize)
y
<1x14 sparse matrix of type '<class 'numpy.float64'>'
with 3 stored elements in Compressed Sparse Row format>
y.toarray()
array([[0. , 0. , 0. , 0.57735027, 0. ,
0. , 0.57735027, 0. , 0. , 0. ,
0. , 0. , 0.57735027, 0. ]])
def normalized_dist(v1, v2):
v1_normalized = v1/scipy.linalg.norm(v1.toarray())
v2_normalized = v2/scipy.linalg.norm(v2.toarray())
delta = v1_normalized - v2_normalized
return scipy.linalg.norm(delta.toarray())
dist = [normalized_dist(each, y) for each in X]
dist
[1.2180321098007547, 1.414213562373095, 1.4142135623730951, 0.816496580927726]
print('Best post is: ', contents[dist.index(min(dist))], 'dist: ', min(dist))
print('Test post is: ', new_contents)
Best post is: 꿈은 실현될 희망의 신호다 dist: 0.816496580927726
Test post is: 나는 내일의 희망을 실현한다
TF-IDF를 사용하지 않고 그냥 벡터간의 거리를 잰 결과와 같은 문장과 유사도가 가장 높게 나왔다.
