from konlpy.tag import Okt
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import urllib
import urllib.request
import json
import nltk
import datetime
import sys
import osCH8-11 네이버 API 활용하여 유사문장 찾기
1. Naver API로 검색결과 가져온 후 전처리
def gen_search_url(api_node, search_text, start_num, disp_num):
base = 'https://openapi.naver.com/v1/search'
node = '/' + api_node +'.json'
param_query = '?query=' + urllib.parse.quote(search_text)
param_start = '&start=' + str(start_num)
param_disp = '&display=' + str(disp_num)
return base + node + param_query + param_disp + param_startclient_id =
client_secret = def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header('X-Naver-Client-Id', client_id)
request.add_header('X-Naver-Client-Secret', client_secret)
response = urllib.request.urlopen(request)
print('[%s] url Request Success' % datetime.datetime.now())
return json.loads(response.read().decode('utf-8'))url = gen_search_url('blog', '머신러닝 공부하기', 1, 30)search_res = get_result_onpage(url)[2024-02-27 18:32:26.669361] url Request Successprint(search_res['items'][2]){'title': '[<b>머신러닝</b>] 메타코드 <b>머신러닝</b> 기초 강의 <b>공부</b> 후기 (1)', 'link': 'https://blog.naver.com/parkbendiary/223329386490', 'description': '사실 <b>머신러닝</b> 강의 <b>공부</b> 일지는 완강을 하고 쓰려고 했는데, 중간중간에 모르는 것들 찾아보고 하다 생각보다 완강이 늦어지고 있어서 먼저 일부분이라도 <b>공부</b> 후기를 올리게 되었습니다. 내용이 워낙... ', 'bloggername': '나의 일기장', 'bloggerlink': 'blog.naver.com/parkbendiary', 'postdate': '20240121'}def delete_tag(res):
temp = []
for val in res:
value = val['description'].replace('<b>','').replace('</b>','').\
replace('"','').replace('<','').replace('>','')
temp.append(value)
return tempdatas = delete_tag(search_res['items'])datas['대해서도 공부를 해보고. 경사하강법 내용을 배울 수 있었습니다. 분류는 어떤 로지스틱 회귀와 소프트맥스라는 어떤 함수의 형태인데, 해당 함수들에 대해서도 배울 수 있었습니다. 머신러닝 강의에서... ',
'머신러닝 공부하게 된 이유 저희 학과에는 졸업하려면 필수로 들어야하는 전공필수 과목 중에 머신러닝 및 실습 과목이 있어요! 그런데 1, 2로 나뉘어 있고 둘 다 들어야하는데 제가 편입학하자마자 후다닥... ',
'사실 머신러닝 강의 공부 일지는 완강을 하고 쓰려고 했는데, 중간중간에 모르는 것들 찾아보고 하다 생각보다 완강이 늦어지고 있어서 먼저 일부분이라도 공부 후기를 올리게 되었습니다. 내용이 워낙... ',
'이 책은 2021년에 머신러닝, 딥러닝을 공부하면서 읽어보고 공부하고 싶었던 책이었는데 텐서플로우 코드 위주라고 해서 다른 교재를 봤었어요. 이번에 파이토치 버전으로 나왔다고 해서 딱이다... ',
'Python을 활용해 머신러닝 공부하기 최근 머신러닝 관련 데이터는 급속도로 커지고 있습니다. 모든... 통해 머신러닝 공부를 하는 방법에 대해 소개합니다. Python 언어를 사용하는 이유는 명확합니다.... ',
"요즘 핫한 인공지능, 머신러닝에 관해 공부를 시작하고 싶은 사람, 맛보기 하고 싶은 사람에게 '머신러닝 기본기' 토픽 아주 추천한다 출처 : 코드잇 인공지능, 머신러닝, 딥러닝, 빅데이터 이것들이 대체... ",
'머신러닝을 공부하기 전에... 인공지능, 머신러닝, 딥러닝이 발전하면서 우리들의 일자리가 위협받는 말을 많이 들었다. 포크레인이 있다고 삽이 필요없어지는 것이 아니다. 자동차가 있다고 자전거가... ',
'본격적으로 머신러닝을 공부하기 전에, 인공지능/머신러닝/딥러닝 등 개념 및 용어를 정리하고 넘어가겠습니다. 인공지능, 머신러닝 & 딥러닝 이제는 인공지능, 딥러닝 같은 용어들이 일상적으로 매우... ',
'머신러닝 알고리즘의 종류, 샘플의 입력과 타깃(정답)을 알고 있을 때 사용할 수 있는 학습방법은? 지도학습 비지도학습 차원축소 강화학습 Ans. 1.지도학습 지도학습과... ',
'요즘 머신러닝은 데이터 구해서 적당한 모형 돌려서 결과 확인하는 식으로 많이 가르친다. 하지만 깊게 들어갈 수록 공부해야하는 내용과 범위는 지수로 증가하는 것 같다. https... ',
"1차 차분을 한번 해보자 (차분에 대해 궁금하신 분들은 '머신러닝 공부 5일차' 글을 읽어보시는 것을 추천드립니다) 유의수준이 0으로 나왔으므로 차분은 1차까지만 하면 된다. 이제 계절성이... ",
'합격의기운이에요 혼공머신 1주차 혼자 공부하는 머신러닝 딥러닝 안녕하세요, IT 관련 책도 많이 읽고 데이터과학을 공부하고 있는 합격의기운이랍니다. 이번 방학기간동안에 뭔가 의미있는... ',
'마지막으로 저자가 생각하는 머신러닝 공부의 왕도로 끝맺고자 한다. 사실, 머신러닝이 아니더라도 컴퓨터 분야의 모든 부분에서 왕도일 것입니다. 필자가 여러분께 전하고 싶은 조언은 연습하고 또... ',
'초보자부터 머신러닝을 전공한 사람들까지 커버 가능한 책이다. 앞으로 머신러닝을 계속 공부하면서 꾸준히 참고할 수 있는 책인 것 같다! * 이 게시글은 길벗 리뷰어 활동으로 작성된 글입니다',
' 태그 #파이썬 #python #딥러닝 #머신러닝 #사이키런 #sklearn #train_test_split #StandardScaler #LogisticRegression #fit #info #head #describe #coef #intercept 엘리스에서 무료로 공부하고 있습니다. 매일 공부 하기... ',
'머신러닝 미술사 공부 Machine Learning Studying Art History - 심철웅展 Sim, Cheol-Woong Solo Exhibition :: Media Art ▲ , 머신러닝 미술사 공부_01 Machine Learning Studying Art History_01 Single Channel Video, 5min.... ',
'스스로 공부하는 힘을 키워주는 EBSMath입니다. 그동안 친구들과 함께 다양한 직업을 가지신 분들의 이야기를 들어보는 시간을 가져보았는데요~ 당시 포스팅을 보며 머신러닝, 딥러닝에 대한 용어는 매우... ',
'머신 러닝과 딥러닝을 공부하고 그걸 기록하려고 한다. 이 분야를 공부하는데 중요한 것은 세 가지라고 생각한다. 하나는 기본 개념, 두번째는 코딩으로 구현하는 능력, 세 번째는 최근 논문을 통해 그... ',
'머신러닝 공부하면서 제일 중요한게 아마 전처리이지 않을까 싶습니다 전처리 안되면 시작도 못하니까요*^^* 그리고 모델 사용법은 다 비슷비슷하나 모델이 어떤 데이터에 사용하면 좋을지 그리고 가장... ',
"오늘부터 머신러닝 공부를 조금 더 심도있게 해보고자 '머신러닝의 바이블' 이라고 불리는 이 책을 구매하였다 공부하면서 요약한 내용들 혹은 중요한 내용들을 이 블로그에 1차적으로 작성하고 내 본계... ",
'가서 공부하다가 약속 갈 예정! 머신러닝 캡스톤 프로젝트 끝내보자구 ~~ 진짜 사람 느끼는 거 다 똑같구나 느끼는 중 ㅎ 나 이제 병원가면 로봇들 보는 거냐며 ㅎ 넘 설렌닷 영국아 지겹다 ㅋ 친구 약속... ',
'머신러닝 공부를 해보려고 윈도우에는 docker desktop을 설치하고, wsl2에는 cuda를 설치했다. (cuda는 nvidia 그래픽카드를 연산에 사용할 수 있게 해주는 프로그램이라고 생각하면 된다. 설치 방법은... ',
"여기서 우리의 업무는, 알코올 도수와 당도, PH를 가지고 화이트와인인지 레드와인인지 구별하는 머신러닝 알고리즘을 만드는 것입니다. 해당 문제를 푸는 가장 간단한 방법은 'Logistics Regression', 즉... ",
'혼자 공부하는 머신러닝+딥러닝으로 직접 손코딩으로 인공지능을 공부하고 싶다면 한빛미디어 혼공단 시리즈로 하자. 한빛미디어의 혼공단에 3번(SQL, Python, 컴퓨터구조와 운영체제)을 참여하면서 알게된... ',
'그럴만한 이유는 나중에 되면 다 이해가 될 것이다. 그렇지 않으면 머신 러닝 살아 남기 힘들다. 통계도 수학도 ... ^^ #혼공학습단, #혼공, #혼공단, #혼공머신, #혼자공부하는머신러닝딥러닝',
'인공지능 공부 인공지능 공부 머신러닝과 인공지능은 이제 막 현실에 접목되고 있어요. 그것도 제한적으로 말이죠. 혼자 공부하는 머신러닝 딥러닝을 읽으며 매주 내용을 정리하다보니 글도 제법... ',
'처리기술 머신러닝과 딥러닝에 대해 알아보았는데요 이렇게 얕게 훑고 가기엔 복잡한 개념이라 아직 헷갈리는 분들이 있을 수 있습니다! 빅데이터 처리 기술에 대해 좀 더 자세하게 공부하고 싶은 분들은... ',
'태그 #파이썬 #python #딥러닝 #머신러닝 #사이키런 #sklearn #교차검증 #cross_validate #fit_time #score_time, #test_score #StratifiedKFold #KFold #n_splits 엘리스에서 무료로 공부하고 있습니다. 매일 공부... ',
'시스템을 이용한 정량적 수요예측을 공부할 때마다 꼭 해보고 싶었던 머신러닝을 이용한 수요예측. 연휴 마지막 날에 어디 가서 배운 건 아니고, 그냥 책 보고, 인터넷 보고, 동영상 보고 하면서 독학해서 해... ',
'먼저 핸즈온 머신러닝 3판 은 머신러닝, 신경망, 딥러닝, 인공지능을 공부할때 꼭 읽어봐야 할 책 입니다. 전세계 1위 베스터셀러이며 이제까지 3판이 나올정도로 머신러닝, 신경망, 딥러닝에 대한 이론, 그림... ']2. 벡터공간에 매핑하기
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df = 1)from konlpy.tag import Okt
t = Okt()datas_morphs = [t.morphs(sentence) for sentence in datas]
datas_morphs3. 형태소 단위로 한칸씩 띄어쓰기하고 한 문장씩 반환하기
datas_to_be_vectorized = []
for row in datas_morphs:
sentence = ''
for word in row:
sentence += ' ' + word
datas_to_be_vectorized.append(sentence)
datas_to_be_vectorized[' 대해 서도 공부 를 해보고 . 경 사 하강 법 내용 을 배울 수 있었습니다 . 분류 는 어떤 로지 스틱 회귀 와 소프트맥스 라는 어떤 함수 의 형태 인데 , 해당 함수 들 에 대해 서도 배울 수 있었습니다 . 머신 러닝 강의 에서 ...',
' 머신 러닝 공부 하게 된 이유 저희 학과 에는 졸업 하려면 필수 로 들어 야하는 전공 필수 과목 중 에 머신 러닝 및 실습 과목 이 있어요 ! 그런데 1 , 2 로 나뉘어 있고 둘 다 들어야하는데 제 가 편입학 하 자마자 후다닥 ...',
' 사실 머신 러닝 강의 공부 일지 는 완강 을 하고 쓰려고 했는데 , 중간 중간 에 모르는 것 들 찾아보고 하다 생각 보다 완강 이 늦어지고 있어서 먼저 일부분 이라도 공부 후기 를 올리게 되었습니다 . 내용 이 워낙 ...',
' 이 책 은 2021년 에 머신 러닝 , 딥 러닝 을 공부 하면서 읽어 보고 공부 하고 싶었던 책 이었는데 텐서 플로우 코드 위주 라고 해서 다른 교재 를 봤었어요 . 이번 에 파 이토 치 버전 으로 나왔다고 해서 딱이다 ...',
' Python 을 활용 해 머신 러닝 공부 하기 최근 머신 러닝 관련 데이터 는 급속도 로 커지고 있습니다 . 모든 ... 통해 머신 러닝 공부 를 하는 방법 에 대해 소개 합니다 . Python 언어 를 사용 하는 이유 는 명확합니다 ....',
" 요즘 핫 한 인공 지능 , 머신 러닝 에 관해 공부 를 시작 하고 싶은 사람 , 맛보기 하고 싶은 사람 에게 ' 머신 러닝 기 본기 ' 토픽 아주 추천 한다 출처 : 코드 잇 인공 지능 , 머신 러닝 , 딥 러닝 , 빅데이터 이 것 들 이 대체 ...",
' 머신 러닝 을 공부 하기 전 에 ... 인공 지능 , 머신 러닝 , 딥 러닝 이 발전 하면서 우리 들 의 일자리 가 위협 받는 말 을 많이 들었다 . 포크레인 이 있다고 삽 이 필요없어지는 것 이 아니다 . 자동차 가 있다고 자전거 가 ...',
' 본격 적 으로 머신 러닝 을 공부 하기 전 에 , 인공 지능 / 머신 러닝 / 딥 러닝 등 개념 및 용어 를 정리 하고 넘어가겠습니다 . 인공 지능 , 머신 러닝 & amp ; 딥 러닝 이제 는 인공 지능 , 딥 러닝 같은 용어 들 이 일상 적 으로 매우 ...',
' 머신 러닝 알고리즘 의 종류 , 샘플 의 입력 과 타깃 ( 정답 ) 을 알 고 있을 때 사용 할 수 있는 학습 방법 은 ? 지도 학습 비지 도 학습 차원 축소 강화 학습 Ans . 1 . 지도 학습 지도 학습 과 ...',
' 요즘 머신 러닝 은 데이터 구해 서 적당한 모형 돌려서 결과 확인 하는 식 으로 많이 가르친다 . 하지만 깊게 들어갈 수록 공부 해야하는 내용 과 범위 는 지수 로 증가 하는 것 같다 . https ...',
" 1 차 차 분 을 한번 해보자 ( 차 분 에 대해 궁금하신 분 들 은 ' 머신 러닝 공부 5일 차 ' 글 을 읽어 보시 는 것 을 추천 드립니다 ) 유의수준 이 0 으로 나왔으므로 차 분 은 1 차 까지만 하면 된다 . 이제 계절 성 이 ...",
' 합격 의 기운 이에요 혼 공 머신 1 주차 혼자 공부 하는 머신 러닝 딥 러닝 안녕하세요 , IT 관련 책 도 많이 읽고 데이터 과학 을 공부 하고 있는 합격 의 기운이랍니다 . 이번 방학기 간 동안 에 뭔가 의미 있는 ...',
' 마지막 으로 저자 가 생각 하는 머신 러닝 공부 의 왕도 로 끝 맺고자 한다 . 사실 , 머신 러닝 이 아니더라도 컴퓨터 분야 의 모든 부분 에서 왕 도일 것 입니다 . 필자 가 여러분 께 전하 고 싶은 조언 은 연습 하고 또 ...',
' 초보자 부터 머신 러닝 을 전공 한 사람 들 까지 커버 가능한 책 이다 . 앞 으로 머신 러닝 을 계속 공부 하면서 꾸준히 참고 할 수 있는 책 인 것 같다 ! * 이 게시 글 은 길벗 리뷰 어 활동 으로 작성 된 글 입니다',
' 태그 #파이썬 #python #딥러닝 #머신러닝 #사이키런 #sklearn #train_test_split #StandardScaler #LogisticRegression #fit #info #head #describe #coef #intercept 엘리스 에서 무료 로 공부 하고 있습니다 . 매일 공부 하기 ...',
' 머신 러닝 미술사 공부 Machine Learning Studying Art History - 심철웅 展 Sim , Cheol - Woong Solo Exhibition :: Media Art ▲ , 머신 러닝 미술사 공부 _ 01 Machine Learning Studying Art History _ 01 Single Channel Video , 5 min ....',
' 스스로 공부 하는 힘 을 키워주는 EBSMath 입니다 . 그동안 친구 들 과 함께 다양한 직업 을 가지신 분 들 의 이야기 를 들어 보는 시간 을 가져 보았는데요 ~ 당시 포스팅 을 보며 머신 러닝 , 딥 러닝 에 대한 용어 는 매우 ...',
' 머신 러닝 과 딥 러닝 을 공부 하고 그걸 기록 하려고 한다 . 이 분야 를 공부 하는데 중요한 것 은 세 가지 라고 생각 한다 . 하나 는 기본 개념 , 두번째 는 코딩 으로 구현 하는 능력 , 세 번 째 는 최근 논문 을 통해 그 ...',
' 머신 러닝 공부 하면서 제일 중요한게 아마 전 처리 이지 않을까 싶습니다 전 처리 안되면 시작 도 못 하니까 요 *^^* 그리고 모델 사 용법 은 다 비슷 비슷하나 모델 이 어떤 데이터 에 사용 하면 좋을지 그리고 가장 ...',
" 오늘 부터 머신 러닝 공부 를 조금 더 심도있게 해보고자 ' 머신 러닝 의 바이블 ' 이라고 불리는 이 책 을 구매 하였다 공부 하면서 요약 한 내용 들 혹은 중요한 내용 들 을 이 블로그 에 1 차 적 으로 작성 하고 내 본계 ...",
' 가서 공부 하다가 약속 갈 예정 ! 머신 러닝 캡 스톤 프로젝트 끝내 보자구 ~~ 진짜 사람 느끼는 거 다 똑같구나 느끼는 중 ㅎ 나 이제 병원 가면 로봇 들 보는 거 냐 며 ㅎ 넘 설렌 닷 영국 아 지겹다 ㅋ 친구 약속 ...',
' 머신 러닝 공부 를 해보려고 윈도우 에는 docker desktop 을 설치 하고 , wsl 2 에는 cuda 를 설치 했다 . ( cuda 는 nvidia 그래픽카드 를 연산 에 사용 할 수 있게 해주는 프로그램 이라고 생각 하면 된다 . 설치 방법 은 ...',
" 여기 서 우리 의 업무 는 , 알코올 도수 와 당 도 , PH 를 가지 고 화이트와인 인지 레드와인 인지 구별 하는 머신 러닝 알고리즘 을 만드는 것 입니다 . 해당 문제 를 푸는 가장 간단한 방법 은 ' Logistics Regression ', 즉 ...",
' 혼자 공부 하는 머신 러닝 + 딥 러닝 으로 직접 손 코딩 으로 인공 지능 을 공부 하고 싶다면 한빛 미디어 혼 공단 시리즈 로 하자 . 한빛 미디어 의 혼 공단 에 3 번 ( SQL , Python , 컴퓨터 구조 와 운영체제 ) 을 참여 하면서 알 게 된 ...',
' 그럴만 한 이유 는 나중 에 되면 다 이해 가 될 것 이다 . 그렇지 않으면 머신 러닝 살 아 남기 힘들다 . 통계 도 수학 도 ... ^^ #혼공학습단 , #혼공 , #혼공단 , #혼공머신 , #혼자공부하는머신러닝딥러닝',
' 인공 지능 공부 인공 지능 공부 머신 러닝 과 인공 지능 은 이제 막 현실 에 접목 되고 있어요 . 그것 도 제한 적 으로 말 이 죠 . 혼자 공부 하는 머신 러닝 딥 러닝 을 읽으며 매주 내용 을 정리 하다 보니 글 도 제법 ...',
' 처리 기술 머신 러닝 과 딥 러닝 에 대해 알아보았는데요 이렇게 얕게 훑고 가기 엔 복잡한 개념 이라 아직 헷갈리는 분 들 이 있을 수 있습니다 ! 빅데이터 처리 기술 에 대해 좀 더 자세하게 공부 하고 싶은 분 들 은 ...',
' 태그 #파이썬 #python #딥러닝 #머신러닝 #사이키런 #sklearn #교차검증 #cross_validate #fit_time #score_time , #test_score #StratifiedKFold #KFold #n_splits 엘리스 에서 무료 로 공부 하고 있습니다 . 매일 공부 ...',
' 시스템 을 이용 한 정량 적 수 요 예측 을 공부 할 때 마다 꼭 해보고 싶었던 머신 러닝 을 이용 한 수요 예측 . 연휴 마지막 날 에 어디 가서 배운 건 아니고 , 그냥 책 보고 , 인터넷 보고 , 동영상 보고 하면서 독학 해서 해 ...',
' 먼저 핸즈온 머신 러닝 3 판 은 머신 러닝 , 신경망 , 딥 러닝 , 인공 지능 을 공부 할 때 꼭 읽어 봐야 할 책 입니다 . 전세계 1 위 베스 터 셀러 이며 이제 까지 3 판이 나올 정도 로 머신 러닝 , 신경망 , 딥 러닝 에 대한 이론 , 그림 ...']X = vectorizer.fit_transform(datas_to_be_vectorized)
X.toarray()array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 1, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=int64)X<30x453 sparse matrix of type '<class 'numpy.int64'>'
with 696 stored elements in Compressed Sparse Row format>4. test할 sentence 형태소단위로 띄어쓰기
test_sentence = '머신러닝과 AI를 체계적으로 공부하는 방법을 알려주세요'
test_morph = [' '.join(t.morphs(test_sentence))]
test_morph['머신 러닝 과 AI 를 체계 적 으로 공부 하는 방법 을 알려주세요']y = vectorizer.transform(test_morph)
y.toarray()import scipy
def dist_norm(v1, v2):
dist = v1 - v2
return np.linalg.norm(dist.toarray())dist = [dist_norm(each, y) for each in X]len(dist)30dist[6.4031242374328485,
5.656854249492381,
5.744562646538029,
5.291502622129181,
5.656854249492381,
7.0710678118654755,
5.291502622129181,
8.06225774829855,
7.874007874011811,
4.795831523312719,
4.242640687119285,
5.5677643628300215,
5.0,
5.0,
5.385164807134504,
7.0710678118654755,
5.0,
5.196152422706632,
5.830951894845301,
5.196152422706632,
5.477225575051661,
6.082762530298219,
5.0990195135927845,
5.656854249492381,
4.58257569495584,
6.557438524302,
5.656854249492381,
5.196152422706632,
6.164414002968976,
6.782329983125268]print('Best post is: ', datas[dist.index(min(dist))])Best post is: 1차 차분을 한번 해보자 (차분에 대해 궁금하신 분들은 '머신러닝 공부 5일차' 글을 읽어보시는 것을 추천드립니다) 유의수준이 0으로 나왔으므로 차분은 1차까지만 하면 된다. 이제 계절성이... print('Test sentence is: ', test_sentence)Test sentence is: 머신러닝과 AI를 체계적으로 공부하는 방법을 알려주세요5. tfidf로 분석해보기
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()X = vectorizer.fit_transform(datas_to_be_vectorized)
X<30x453 sparse matrix of type '<class 'numpy.float64'>'
with 696 stored elements in Compressed Sparse Row format>test_sentence = '머신러닝과 딥러닝을 빠르게 공부하는 방법과 좋은 책이 있나요'
test_morphs = [' '.join(t.morphs(test_sentence))]
test_morphs['머신 러닝 과 딥 러닝 을 빠르게 공부 하는 방법 과 좋은 책 이 있나요']y = vectorizer.transform(test_morphs)
y<1x453 sparse matrix of type '<class 'numpy.float64'>'
with 5 stored elements in Compressed Sparse Row format>
def dist_norm(v1, v2):
v1_norm = v1/np.linalg.norm(v1.toarray())
v2_norm = v2/np.linalg.norm(v2.toarray())
norm = v1_norm - v2_norm
print(norm)
return np.linalg.norm(norm.toarray())이 표현은 흔히 희소 행렬(sparse matrix)에서 사용되는 좌표 형식(coordinate format)이나 다른 희소 행렬 형식을 나타낼 때 볼 수 있습니다. 여기서 제공된 정보를 분석해보면:
(0, 175)는 행렬의 위치를 나타냅니다. 이는 0번째 행과 175번째 열을 의미합니다.
-0.6408840666776808는 해당 위치에 있는 행렬의 값입니다.
간단히 말해서, 이것은 특정 희소 행렬에서 (0, 175) 위치에 있는 값이 -0.6408840666776808임을 나타냅니다. 희소 행렬은 대부분의 값이 0인 행렬로, 메모리를 효율적으로 사용하기 위해 비-0 값의 위치와 값을 저장하는 특별한 형식으로 표현됩니다.
희소 행렬을 일반 벡터(또는 밀집 행렬)로 바꾸는 원리는 희소 행렬에 저장된 비-0 데이터를 포함하는 전체 행렬 구조를 복원하는 것에 기반합니다. 희소 행렬은 대부분의 원소가 0인 행렬로, 메모리를 절약하기 위해 비-0 원소와 그 위치 정보만 저장합니다. 이러한 희소성을 활용하는 여러 저장 형식이 있으며, 희소 행렬을 일반 벡터로 변환할 때는 이러한 형식에서 전체 데이터 구조를 재구성해야 합니다. 다음은 이 과정의 기본 원리입니다:
데이터 저장 방식
희소 행렬은 주로 다음과 같은 형식으로 데이터를 저장합니다:
좌표 리스트(COO): 각 비-0 원소의 행, 열 위치와 값을 별도의 배열로 저장합니다.
압축 행 저장(CSR): 행 인덱스를 압축하여 저장하고, 열 인덱스와 값은 별도의 배열로 저장합니다. 이 방식은 행 기반 연산에 유리합니다.
압축 열 저장(CSC): CSR과 유사하지만 열 기반으로 데이터를 압축하여 저장합니다.
일반 벡터로의 변환 원리
희소 행렬에서 일반 벡터(밀집 행렬)로의 변환은 희소 행렬에 저장된 위치 정보와 값을 사용하여 전체 행렬의 원본 구조를 재구성하는 과정입니다. 이 과정은 대략적으로 다음과 같습니다:
행렬의 크기 결정: 희소 행렬의 전체 크기를 기반으로 하는 0으로 채워진 밀집 행렬을 초기화합니다. 이 크기는 희소 행렬의 최대 행 인덱스와 열 인덱스에 의해 결정됩니다.
비-0 원소의 할당: 희소 행렬에 저장된 비-0 원소의 위치 정보(행, 열 인덱스)와 값을 사용하여 밀집 행렬의 해당 위치에 값을 할당합니다. 이 과정에서 모든 비-0 원소가 밀집 행렬에 올바르게 배치됩니다.
밀집 행렬의 완성: 모든 비-0 원소가 할당된 후, 나머지 위치는 이미 0으로 초기화되어 있으므로, 이제 변환된 밀집 행렬은 희소 행렬의 전체 데이터를 포함하게 됩니다.
dist = [dist_norm(each, y) for each in X]dist[1.379840909034111,
1.3456611957328932,
1.3651375488765984,
1.3370176137796972,
1.0892345503991316,
1.2898431675074638,
1.3071605926069196,
1.2462379046372956,
1.3488560885507594,
1.2800089294884185,
1.3611562267097912,
1.2869143191517955,
1.2863028929360658,
1.3325600340720178,
1.3901276123507376,
1.353748339296911,
1.3029311054161208,
1.2904789540560988,
1.3762059658050851,
1.3202584513587885,
1.3745831080339983,
1.3161599148099097,
1.2655115903921448,
1.3046915795779785,
1.37783597563262,
1.2518408123950702,
1.3519925004025373,
1.389057288504945,
1.3785560469131193,
1.2622256941593837]datas[4]'Python을 활용해 머신러닝 공부하기 최근 머신러닝 관련 데이터는 급속도로 커지고 있습니다. 모든... 통해 머신러닝 공부를 하는 방법에 대해 소개합니다. Python 언어를 사용하는 이유는 명확합니다.... 'print('Most similar sentence is: ', datas[dist.index(min(dist))], '\n',\
'distance :', min(dist))Most similar sentence is: Python을 활용해 머신러닝 공부하기 최근 머신러닝 관련 데이터는 급속도로 커지고 있습니다. 모든... 통해 머신러닝 공부를 하는 방법에 대해 소개합니다. Python 언어를 사용하는 이유는 명확합니다....
distance : 1.0892345503991316print('Test sentence is: ', test_sentence)Test sentence is: 머신러닝과 딥러닝을 빠르게 공부하는 방법과 좋은 책이 있나요CH9-01. PCA(차원축소, 주성분분석)
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns1. np.random.rand: 0 이상 1 미만의 균등 분포에서 난수를 생성.
np.random.randn: 평균 0, 표준편차 1의 표준 정규 분포에서 난수를 생.
따라서, 사용 용도에 따라 균등 분포에서 난수가 필요한 경우 np.random.rand를 사용하고, 표준 정규 분포에서 난수가 필요한 경우 np.random.randn을 사용하면 됩니다.
np.random.rand() 함수를 사용하여 생성된 난수는 0 이상 1 미만의 범위에서 균등하게 분포되어 있습니다. 이는 0.1, 0.5, 0.9와 같은 값이 나올 확률이 모두 같다는 것을 의미합니다.
균등 분포는 두 종류가 있습니다:
연속 균등 분포(Continuous Uniform Distribution): 연속적인 범위 내에서 모든 값이 발생할 확률이 동일합니다. 예를 들어, 0에서 1 사이의 모든 수는 연속 균등 분포를 따릅니다.
이산 균등 분포(Discrete Uniform Distribution): 이산적인 범위 내의 값이 발생할 확률이 동일합니다. 예를 들어, 주사위를 던졌을 때 나오는 1부터 6까지의 숫자는 이산 균등 분포를 따릅니다.
NumPy의 np.random.rand 함수에 의해 생성된 난수는 연속 균등 분포를 따르며, 이 분포의 특성상 지정된 범위 내의 어떤 값이 선택될 확률도 동일합니다.
rng = np.random.RandomState(42)
X = np.dot(rng.rand(2,2), rng.randn(2,200)).T
X.shape(200, 2)plt.figure(figsize=(7,7))
plt.scatter(X[:,0], X[:,1], color = 'blue')
plt.axis('equal')
plt.grid('white')
plt.show()
2. 주성분 2개로 주성분분석하기
from sklearn.decomposition import PCApca = PCA(n_components = 2, random_state = 42)
X_pca = pca.fit_transform(X)pca.explained_variance_array([1.82927343, 0.10246373])3. 주성분으로 설명되는 variance(분산)의 비율
pca.explained_variance_ratio_array([0.94695773, 0.05304227])4. 원레 데이터의 각 독립변수(열)들의 평균(새로 구성된 차원의 원점으로 생각하면 됨(pca.mean_)
이렇게 계산된 각 특성의 평균 값들은 PCA 변환 과정에서 데이터의 각 특성에서 해당 평균 값을 빼주어 데이터를 중심화하는 데 사용됩니다.
pca.mean_array([0.04264695, 0.00793155])5. 주성분 분석 후 나온 주성분 벡터들(pca.components_)
pca.components_array([[ 0.74306799, 0.66921593],
[-0.66921593, 0.74306799]])이 Python 함수 draw_vector는 Matplotlib 라이브러리를 사용하여 벡터를 그리는 데 사용됩니다. 함수의 목적은 시작점 v0에서 끝점 v1으로 향하는 화살표를 그리는 것입니다. 이 화살표는 벡터를 시각적으로 표현합니다. 함수의 작동 방식을 자세히 살펴보겠습니다.
함수 매개변수
v0: 벡터의 시작점입니다. (x, y) 형태의 튜플로 표현됩니다.
v1: 벡터의 끝점입니다. 역시 (x, y) 형태의 튜플로 표현됩니다.
ax: 화살표(벡터)를 그릴 Matplotlib의 축(Axes) 인스턴스입니다. 기본값이 None으로 설정되어 있고, None일 경우 현재 활성화된 축(plt.gca())을 사용합니다.
화살표 스타일 설정
arrows라는 딕셔너리를 통해 화살표의 시각적 스타일을 설정합니다.
arrowstyle: 화살표의 스타일을 정의합니다. '->'는 화살표 끝이 뾰족한 형태를 나타냅니다.
linewidth: 화살표 선의 두께를 설정합니다.
color: 화살표의 색상을 정의합니다. 여기서는 'red'로 설정되어 있습니다.
shrinkA: 시작점에서 화살표가 축소되는 비율을 정의합니다. 0은 축소하지 않음을 의미합니다.
shrinkB: 끝점에서 화살표가 축소되는 비율을 정의합니다. 마찬가지로 0은 축소하지 않음을 의미합니다.
화살표 그리기
ax.annotate('':, v1, v0, arrowprops=arrows): annotate 함수는 주로 텍스트 주석을 추가할 때 사용되지만, 여기서는 텍스트 없이 화살표만을 그리기 위해 사용됩니다. 첫 번째 인자는 표시할 텍스트로, 여기서는 비어 있습니다(''). v1은 주석이 위치할 좌표, v0은 주석 텍스트의 시작점으로 사용됩니다. 하지만 여기서는 화살표의 시작점과 끝점으로 기능합니다. arrowprops에 arrows 딕셔너리를 전달하여 화살표의 스타일을 지정합니다.
PCA(Principal Component Analysis, 주성분 분석)에서 pca.mean_은 입력 데이터 세트에 대한 각 특성(변수)의 평균 값을 나타냅니다. PCA를 수행하기 전에 데이터를 중심화(또는 정규화)하는 과정이 필요한데, 이 때 각 특성의 평균 값이 계산됩니다. 중심화는 각 특성에서 해당 특성의 평균 값을 빼주는 과정으로, 데이터를 원점(0)을 중심으로 재배치하는 것을 의미합니다. 이는 데이터의 분산을 최대로 하는 방향을 찾을 때, 평균을 기준으로 분산을 계산하기 위함입니다.

6. 주성분들의 시각화
def draw_vector(v0, v1, ax=None):
ax = ax or plt.gca()
arrows = dict(
arrowstyle = '->',
linewidth = 3,
color = 'red',
shrinkA = 0,
shrinkB = 0,
alpha = 0.5
)
ax.annotate('',v1,v0, arrowprops = arrows)
pca.mean_array([0.04264695, 0.00793155])plt.scatter(X[:,0], X[:,1], alpha = 0.2)
for length, vector in zip(pca.explained_variance_, pca.components_):
v = vector * 2 * np.sqrt(length)
draw_vector(pca.mean_, pca.mean_ + v)
plt.axis('equal')
plt.grid('blue')
plt.show()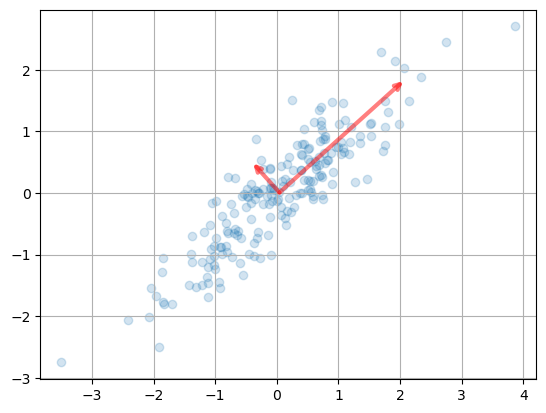

주성분으로 차원축소를 하게되면 원래 데이터의 특성이 사라지므로
각 특성은 pc1, pc2라고 임의로 정해줌
7. 주성분을 1개로 하여 차원축소해보기
from sklearn.decomposition import PCA
pca = PCA(n_components = 1, random_state = 42)
X_pca = pca.fit_transform(X)
X_pcapca.mean_array([0.04264695, 0.00793155])pca.components_array([[0.74306799, 0.66921593]])pca.explained_variance_array([1.82927343])pca.explained_variance_ratio_array([0.94695773])8. pca를 통해 차원축소된 X_pca를 다시 2차원으로 inverse_transform()해주기
하지만 원래 데이터가 되는게 아니라 pca로 주성분분석된 결과를 단순히 2차원에 매핑함
원 데이터의 특성은 이미 주성분의 특징으로 바뀐 상태임

print(X_pca.shape)(200, 1)X_new = pca.inverse_transform(X_pca)
print(X_new.shape)(200, 2)plt.figure(figsize=(7,7))
plt.scatter(X[:,0], X[:,1], alpha = 0.5, color = 'blue')
plt.scatter(X_new[:,0], X_new[:,1], alpha = 0.8, color = 'red')
plt.axis('equal')
plt.grid('black')
plt.show()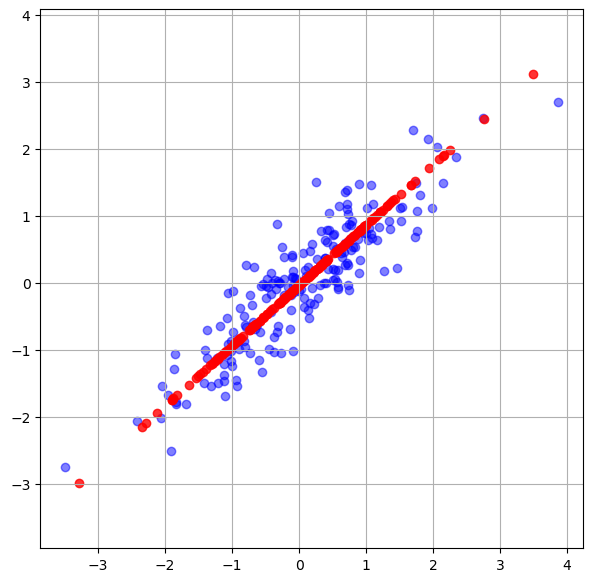
CH9-03~9-04. PCA를 이용한 IRIS 데이터 분석
from sklearn.datasets import load_irisdata = load_iris()X = pd.DataFrame(data['data'], columns = data['feature_names'])
y = pd.DataFrame(data['target'], columns = ['Species'])
df = pd.concat([X,y], axis = 1)df| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | Species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | 2 |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | 2 |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | 2 |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | 2 |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | 2 |
150 rows × 5 columns
1. pairplot으로 특성 탐색하기
sns.pairplot(df, hue = 'Species', height = 3,
x_vars = ['sepal length (cm)', 'petal width (cm)'],
y_vars = ['petal length (cm)', 'sepal width (cm)'])<seaborn.axisgrid.PairGrid at 0x247a2081950>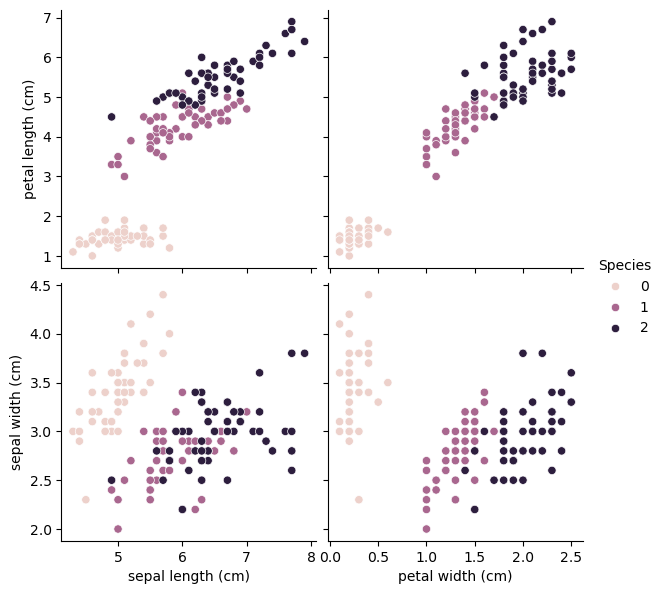
2. 보통 PCA(주성분분석 및 차원축소)는 스케일링에 민감하다고 알려져 있다
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_sc = scaler.fit_transform(X)
X_sc3. pca결과를 반환하는 함수 및 데이터프레임 만들어 주는 함수 정의하기
from sklearn.decomposition import PCA
def transform_pca(data, n_components=2):
pca = PCA(n_components = n_components, random_state = 24)
decomposed = pca.fit_transform(data)
return decomposed, pcadef framing_results(data, cols=['PC1','PC2']):
temp = pd.DataFrame(data, columns=cols)
return tempresult_pca = transform_pca(X_sc, 2)X_pca = result_pca[0]pca = result_pca[1]pca.mean_array([-1.69031455e-15, -1.84297022e-15, -1.69864123e-15, -1.40924309e-15])pca.explained_variance_array([2.93808505, 0.9201649 ])pca.explained_variance_ratio_array([0.72962445, 0.22850762])pca.components_array([[ 0.52106591, -0.26934744, 0.5804131 , 0.56485654],
[ 0.37741762, 0.92329566, 0.02449161, 0.06694199]])df_pca = pd.concat([framing_results(X_pca,),y],axis=1)df_pca| PC1 | PC2 | Species | |
|---|---|---|---|
| 0 | -2.264703 | 0.480027 | 0 |
| 1 | -2.080961 | -0.674134 | 0 |
| 2 | -2.364229 | -0.341908 | 0 |
| 3 | -2.299384 | -0.597395 | 0 |
| 4 | -2.389842 | 0.646835 | 0 |
| ... | ... | ... | ... |
| 145 | 1.870503 | 0.386966 | 2 |
| 146 | 1.564580 | -0.896687 | 2 |
| 147 | 1.521170 | 0.269069 | 2 |
| 148 | 1.372788 | 1.011254 | 2 |
| 149 | 0.960656 | -0.024332 | 2 |
150 rows × 3 columns
4. PCA로 4가지 독립변수(특성)이 2가지 특성으로 차원축소된 결과를 시각화해보기
sns.scatterplot(data = df_pca, x = 'PC1', y = 'PC2', hue = 'Species',
alpha = 1.0)
plt.axvline(x=0, color = 'red', linewidth = 2, ls = '--')
plt.axhline(y=0, color = 'red', linewidth = 2, ls = '--')
plt.grid(True)
plt.show()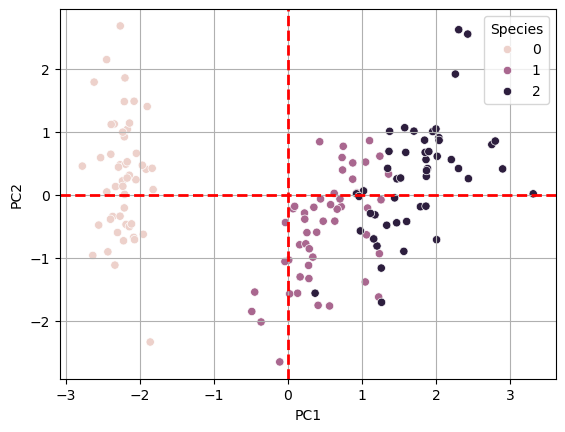
5. RandomForest로 X_scaled로 성능 평가하기
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import KFold, cross_val_score
rf = RandomForestClassifier(n_estimators = 500, random_state = 42, n_jobs = -1)def get_rf_scores(X, y, kfold):
rf.fit(X, y)
res = cross_val_score(rf,X, y, scoring = 'accuracy', cv=kfold, verbose=2,n_jobs=-1)
print(f'CV Scores: {np.mean(res)}')kfold = KFold(n_splits = 5, random_state = 42, shuffle = True)get_rf_scores(X_sc, np.array(y).reshape(-1), kfold)[Parallel(n_jobs=-1)]: Using backend LokyBackend with 16 concurrent workers.
CV Scores: 0.9600000000000002
[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 1.2s finished6. RandomForest로 PC1, PC2 2개의 차원으로 축소된 특성 활용하여 성능 평가하기
get_rf_scores(X_pca, np.array(y).reshape(-1), kfold)[Parallel(n_jobs=-1)]: Using backend LokyBackend with 16 concurrent workers.
CV Scores: 0.9
[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 1.1s finished7. 최종결과
res_df = pd.DataFrame({'models':['StandardScaling만 한 모델', 'pc1,pc2로 차원축소한 모델'],
'cv_scores':[0.9600000000000002, 0.9]})res_df| models | cv_scores | |
|---|---|---|
| 0 | StandardScaling만 한 모델 | 0.96 |
| 1 | pc1,pc2로 차원축소한 모델 | 0.90 |
CH9-05. wine data PCA로 분석, 예측
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/wine.csv'
df = pd.read_csv(url, header = 0, index_col = 0).reset_index()df = df.drop('index',axis=1)1. 2개 차원으로 특성을 축소하고 성능평가
X = df.drop(['color'], axis = 1)
y = df['color']y0 1
1 1
2 1
3 1
4 1
..
6492 0
6493 0
6494 0
6495 0
6496 0
Name: color, Length: 6497, dtype: int64from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_sc = scaler.fit_transform(X)from sklearn.decomposition import PCAdef get_pca_scores(data, n_components):
pca = PCA(n_components = n_components, random_state = 42)
X_pca = pca.fit_transform(data)
print('pca_mean_: \n', pca.mean_,'\n')
print('설명된 분산: \t', pca.explained_variance_)
print('설명된 분산의 비율(점수): ', pca.explained_variance_ratio_)
print('설명된 분산의 비율(점수)의 합 : ', np.sum(pca.explained_variance_ratio_))
return pca, X_pcapca, X_pca = get_pca_scores(X_sc, 2)pca_mean_:
[-3.84963896e-16 1.04990153e-16 2.18729486e-17 3.49967178e-17
1.39986871e-16 -8.74917945e-17 -6.99934356e-17 -3.55216686e-15
2.72974399e-15 -5.42449126e-16 9.97406457e-16 -3.10595870e-16]
설명된 분산: [3.04201535 2.65026192]
설명된 분산의 비율(점수): [0.25346226 0.22082117]
설명된 분산의 비율(점수)의 합 : 0.474283427432362X_pcaarray([[-3.34843817, 0.56892617],
[-3.22859545, 1.19733465],
[-3.23746833, 0.95258001],
...,
[ 0.62692235, -0.62214478],
[ 0.49193416, -3.75592792],
[ 0.76155534, -2.7678397 ]])pca.mean_array([-3.84963896e-16, 1.04990153e-16, 2.18729486e-17, 3.49967178e-17,
1.39986871e-16, -8.74917945e-17, -6.99934356e-17, -3.55216686e-15,
2.72974399e-15, -5.42449126e-16, 9.97406457e-16, -3.10595870e-16])pca.explained_variance_array([3.04201535, 2.65026192])pca.explained_variance_ratio_array([0.25346226, 0.22082117])from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs = -1, n_estimators = 500, random_state = 42)def get_cv_scores(X, y, estimator, kfold):
estimator.fit(X,y)
scores = cross_val_score(estimator, X, y, scoring = 'accuracy',
n_jobs = -1, verbose = 2, cv = kfold)
return np.mean(scores)kfold = KFold(n_splits = 10, shuffle = True, random_state = 42)2. 일단 원래 모델의 특성을 모두 이용하여 rf 교차검증 점수
get_cv_scores(X, y, rf, kfold)[Parallel(n_jobs=-1)]: Using backend LokyBackend with 16 concurrent workers.
[Parallel(n_jobs=-1)]: Done 3 out of 10 | elapsed: 4.7s remaining: 11.0s
[Parallel(n_jobs=-1)]: Done 10 out of 10 | elapsed: 5.4s finished
0.99507478961716263. 2개의 차원으로 축소된 특성을 이용한 rf 교차검증 점수
get_cv_scores(X_pca, y, rf, kfold)[Parallel(n_jobs=-1)]: Using backend LokyBackend with 16 concurrent workers.
[Parallel(n_jobs=-1)]: Done 3 out of 10 | elapsed: 1.6s remaining: 4.0s
[Parallel(n_jobs=-1)]: Done 10 out of 10 | elapsed: 5.1s finished
0.98399170321204224. 2개 차원으로 예측한 성능 분류의 시각화
pca_df = pd.DataFrame(X_pca, columns = ['PC1','PC2'])y_df = pd.DataFrame(y)y_df| color | |
|---|---|
| 0 | 1 |
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 1 |
| ... | ... |
| 6492 | 0 |
| 6493 | 0 |
| 6494 | 0 |
| 6495 | 0 |
| 6496 | 0 |
6497 rows × 1 columns
pca_df| PC1 | PC2 | |
|---|---|---|
| 0 | -3.348438 | 0.568926 |
| 1 | -3.228595 | 1.197335 |
| 2 | -3.237468 | 0.952580 |
| 3 | -1.672561 | 1.600583 |
| 4 | -3.348438 | 0.568926 |
| ... | ... | ... |
| 6492 | 0.112718 | -1.912247 |
| 6493 | 1.720296 | 1.009571 |
| 6494 | 0.626922 | -0.622145 |
| 6495 | 0.491934 | -3.755928 |
| 6496 | 0.761555 | -2.767840 |
6497 rows × 2 columns
pca_all = pd.concat([pca_df, y_df], axis = 1)pca_all| PC1 | PC2 | color | |
|---|---|---|---|
| 0 | -3.348438 | 0.568926 | 1 |
| 1 | -3.228595 | 1.197335 | 1 |
| 2 | -3.237468 | 0.952580 | 1 |
| 3 | -1.672561 | 1.600583 | 1 |
| 4 | -3.348438 | 0.568926 | 1 |
| ... | ... | ... | ... |
| 6492 | 0.112718 | -1.912247 | 0 |
| 6493 | 1.720296 | 1.009571 | 0 |
| 6494 | 0.626922 | -0.622145 | 0 |
| 6495 | 0.491934 | -3.755928 | 0 |
| 6496 | 0.761555 | -2.767840 | 0 |
6497 rows × 3 columns
plt.figure(figsize=(7,7))
sns.scatterplot(data = pca_all, x = 'PC1', y = 'PC2', hue = 'color', alpha = 0.3)
plt.grid('black')
plt.axis('equal')
plt.show()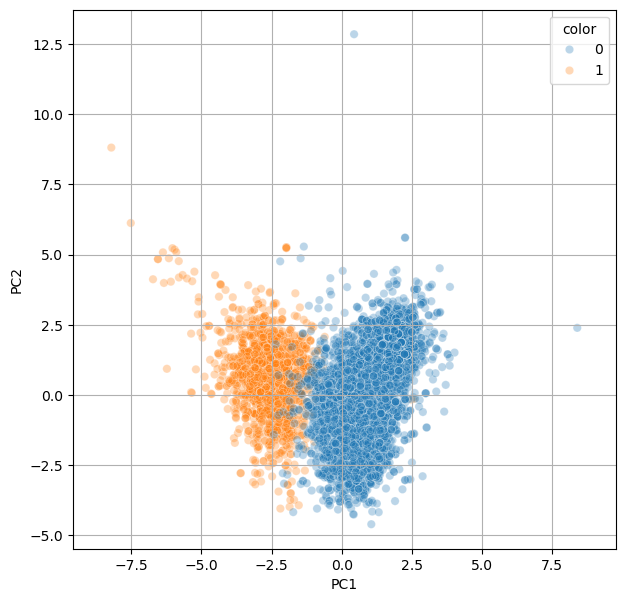
5. 3개의 차원(특성)으로 차원축소하고 성능 평가 및 시각화(3d)해보기
from sklearn.decomposition import PCApca, X_pca = get_pca_scores(X_sc, 3)pca_mean_:
[-3.84963896e-16 1.04990153e-16 2.18729486e-17 3.49967178e-17
1.39986871e-16 -8.74917945e-17 -6.99934356e-17 -3.55216686e-15
2.72974399e-15 -5.42449126e-16 9.97406457e-16 -3.10595870e-16]
설명된 분산: [3.04201535 2.65026192 1.64175951]
설명된 분산의 비율(점수): [0.25346226 0.22082117 0.13679223]
설명된 분산의 비율(점수)의 합 : 0.61107566218387from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import KFold, cross_val_score
rf = RandomForestClassifier(n_estimators = 1000, n_jobs = -1, random_state = 42)
kfold = KFold(n_splits = 20, shuffle = True, random_state = 42)get_cv_scores(X_pca, y, rf, kfold)[Parallel(n_jobs=-1)]: Using backend LokyBackend with 16 concurrent workers.
[Parallel(n_jobs=-1)]: Done 11 out of 20 | elapsed: 17.0s remaining: 13.9s
[Parallel(n_jobs=-1)]: Done 20 out of 20 | elapsed: 20.7s finished
0.9850702754036087pca_df = pd.DataFrame(X_pca, columns = ['PC1','PC2','PC3'])
pca_all = pd.concat([pca_df, y], axis = 1)
pca_all| PC1 | PC2 | PC3 | color | |
|---|---|---|---|---|
| 0 | -3.348438 | 0.568926 | -2.727386 | 1 |
| 1 | -3.228595 | 1.197335 | -1.998904 | 1 |
| 2 | -3.237468 | 0.952580 | -1.746578 | 1 |
| 3 | -1.672561 | 1.600583 | 2.856552 | 1 |
| 4 | -3.348438 | 0.568926 | -2.727386 | 1 |
| ... | ... | ... | ... | ... |
| 6492 | 0.112718 | -1.912247 | -0.061138 | 0 |
| 6493 | 1.720296 | 1.009571 | -0.662488 | 0 |
| 6494 | 0.626922 | -0.622145 | -0.149483 | 0 |
| 6495 | 0.491934 | -3.755928 | -0.080284 | 0 |
| 6496 | 0.761555 | -2.767840 | 0.176820 | 0 |
6497 rows × 4 columns
6. 3차원공간에 PCA로 차원축소된 특성과 target을 시각화하기
import plotly.express as pxfig = px.scatter_3d(pca_all, x = 'PC1', y = 'PC2', z = 'PC3',
color = 'color', symbol = 'color', opacity = 0.3)
fig.update_layout(margin=dict(l=0,r=0,b=0,t=0))
fig.show() 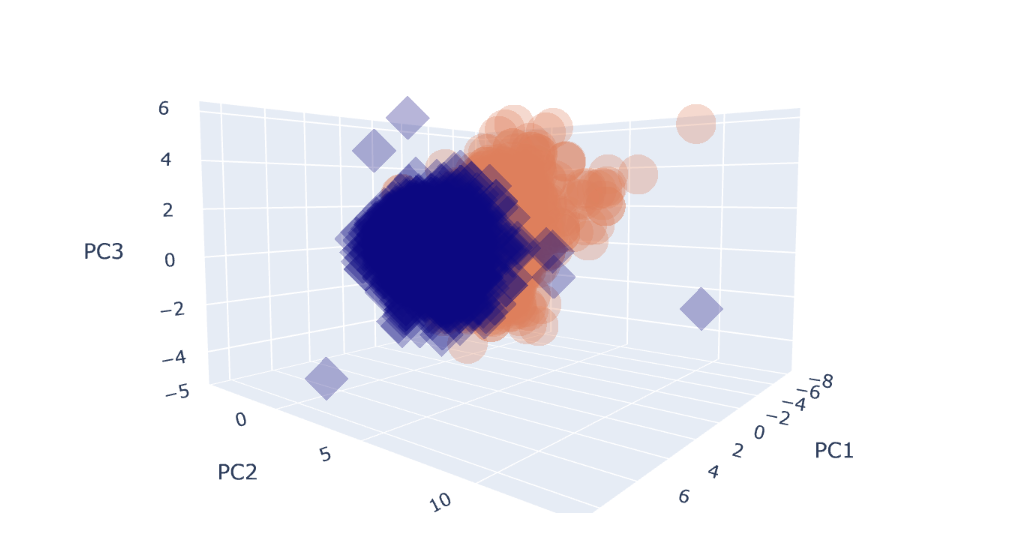
CH9-06: eigenface PCA로 차원축소하기(1)
from sklearn.datasets import fetch_olivetti_faces
data = fetch_olivetti_faces()downloading Olivetti faces from https://ndownloader.figshare.com/files/5976027 to C:\Users\kd010\scikit_learn_dataprint(data['DESCR']).. _olivetti_faces_dataset:
The Olivetti faces dataset
--------------------------
`This dataset contains a set of face images`_ taken between April 1992 and
April 1994 at AT&T Laboratories Cambridge. The
:func:`sklearn.datasets.fetch_olivetti_faces` function is the data
fetching / caching function that downloads the data
archive from AT&T.
.. _This dataset contains a set of face images: https://cam-orl.co.uk/facedatabase.html
As described on the original website:
There are ten different images of each of 40 distinct subjects. For some
subjects, the images were taken at different times, varying the lighting,
facial expressions (open / closed eyes, smiling / not smiling) and facial
details (glasses / no glasses). All the images were taken against a dark
homogeneous background with the subjects in an upright, frontal position
(with tolerance for some side movement).
**Data Set Characteristics:**
================= =====================
Classes 40
Samples total 400
Dimensionality 4096
Features real, between 0 and 1
================= =====================
The image is quantized to 256 grey levels and stored as unsigned 8-bit
integers; the loader will convert these to floating point values on the
interval [0, 1], which are easier to work with for many algorithms.
The "target" for this database is an integer from 0 to 39 indicating the
identity of the person pictured; however, with only 10 examples per class, this
relatively small dataset is more interesting from an unsupervised or
semi-supervised perspective.
The original dataset consisted of 92 x 112, while the version available here
consists of 64x64 images.
When using these images, please give credit to AT&T Laboratories Cambridge.print(data['target'])[ 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 2
2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4
4 4 5 5 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 6 6 7 7
7 7 7 7 7 7 7 7 8 8 8 8 8 8 8 8 8 8 9 9 9 9 9 9
9 9 9 9 10 10 10 10 10 10 10 10 10 10 11 11 11 11 11 11 11 11 11 11
12 12 12 12 12 12 12 12 12 12 13 13 13 13 13 13 13 13 13 13 14 14 14 14
14 14 14 14 14 14 15 15 15 15 15 15 15 15 15 15 16 16 16 16 16 16 16 16
16 16 17 17 17 17 17 17 17 17 17 17 18 18 18 18 18 18 18 18 18 18 19 19
19 19 19 19 19 19 19 19 20 20 20 20 20 20 20 20 20 20 21 21 21 21 21 21
21 21 21 21 22 22 22 22 22 22 22 22 22 22 23 23 23 23 23 23 23 23 23 23
24 24 24 24 24 24 24 24 24 24 25 25 25 25 25 25 25 25 25 25 26 26 26 26
26 26 26 26 26 26 27 27 27 27 27 27 27 27 27 27 28 28 28 28 28 28 28 28
28 28 29 29 29 29 29 29 29 29 29 29 30 30 30 30 30 30 30 30 30 30 31 31
31 31 31 31 31 31 31 31 32 32 32 32 32 32 32 32 32 32 33 33 33 33 33 33
33 33 33 33 34 34 34 34 34 34 34 34 34 34 35 35 35 35 35 35 35 35 35 35
36 36 36 36 36 36 36 36 36 36 37 37 37 37 37 37 37 37 37 37 38 38 38 38
38 38 38 38 38 38 39 39 39 39 39 39 39 39 39 39]data['images'][data['target'] == 7][0]array([[0.18595041, 0.19421488, 0.32231405, ..., 0.19421488, 0.19008264,
0.17768595],
[0.17355372, 0.21487603, 0.36363637, ..., 0.22727273, 0.21900827,
0.20661157],
[0.17768595, 0.24380165, 0.43801653, ..., 0.23140496, 0.24793388,
0.2231405 ],
...,
[0.11157025, 0.1322314 , 0.15289256, ..., 0.1983471 , 0.18595041,
0.16528925],
[0.11983471, 0.12396694, 0.15289256, ..., 0.19008264, 0.19008264,
0.18595041],
[0.13636364, 0.11570248, 0.1446281 , ..., 0.19008264, 0.19421488,
0.20247933]], dtype=float32)k = 7
faces = data['images'][data['target'] == 7]fig = plt.figure(figsize=(18,9))
r = 2
c = 5
for i in range(r*c):
ax = fig.add_subplot(r, c, i + 1)
ax.imshow(faces[i], cmap = plt.cm.bone)
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.show()
1.PCA 차원축소로 2개 차원으로 줄이고 다시 사진 시각화해보기
from sklearn.decomposition import PCA
pca = PCA(n_components = 2, random_state= 42)faces.shape(10, 64, 64)faces_shaped = faces.reshape(10,-1)faces_shaped.shape(10, 4096)faces_shapedarray([[0.18595041, 0.19421488, 0.32231405, ..., 0.19008264, 0.19421488,
0.20247933],
[0.19421488, 0.2231405 , 0.3140496 , ..., 0.13636364, 0.1694215 ,
0.16528925],
[0.39256197, 0.5247934 , 0.6198347 , ..., 0.32231405, 0.32231405,
0.35950413],
...,
[0.20247933, 0.25619835, 0.32231405, ..., 0.2107438 , 0.23140496,
0.35123968],
[0.2231405 , 0.23966943, 0.23140496, ..., 0.5289256 , 0.55785125,
0.5661157 ],
[0.74380165, 0.77272725, 0.8016529 , ..., 0.30165288, 0.28099173,
0.1570248 ]], dtype=float32)faces_pca = pca.fit_transform(faces_shaped)faces_pca
print('pca_mean_: ', pca.mean_)
print('설명된 분산: ', pca.explained_variance_)
print('설명된 분산의 비율: ', pca.explained_variance_ratio_)pca_mean_: [0.41115704 0.46115702 0.5256198 ... 0.2376033 0.2533058 0.2607438 ]
설명된 분산: [40.2715 13.403047]
설명된 분산의 비율: [0.5306011 0.17659314]faces_pca_2d = pca.inverse_transform(faces_pca)faces_pca_2d.shape(10, 4096)faces_pcas = faces_pca_2d.reshape(10, 64, 64)2. 2차원으로 차원축소된 이미지 시각화
- 그래도 약간 흔들린 사진처럼 화질이 조금 나빠지긴 했으나 꽤 잘 표현된것 같음
r = 2
c = 5
fig = plt.figure(figsize=(14,7))
for i in range(r*c):
ax = fig.add_subplot(r,c,i + 1)
ax.imshow(faces_pcas[i],plt.cm.bone)
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.show()
CH9-07: Eigenface의 PCA로 차원축소된 이미지의 pca.mean_, pc1, pc2 그려보기
face_mean = pca.mean_face_p1, face_p2 = pca.components_[0], pca.components_[1]print('face_mean: ', face_mean)
print('face_p1: ', face_p1)
print('face_p2: ', face_p2)face_mean: [0.41115704 0.46115702 0.5256198 ... 0.2376033 0.2533058 0.2607438 ]
face_p1: [-0.03158905 -0.03053354 -0.02972886 ... 0.01399273 0.01664253
0.01870738]
face_p2: [ 0.01500489 0.0060261 -0.00151618 ... 0.00718603 0.00473257
0.00203715]1. 시각화를 위해 원래 사진의 픽셀크기였던 (64*64) 행렬로 만들어주기
face_mean = face_mean.reshape(64,64)
face_p1 = face_p1.reshape(64,64)
face_p2 = face_p2.reshape(64,64)
plt.figure(figsize=(15,5))
plt.subplot(131)
plt.imshow(face_mean, plt.cm.bone)
plt.grid(False); plt.axis('off'); plt.title('mean')
plt.subplot(132)
plt.imshow(face_p1, plt.cm.bone)
plt.grid(False); plt.axis('off'); plt.title('pc1')
plt.subplot(133)
plt.imshow(face_p2, plt.cm.bone)
plt.grid(False); plt.axis('off'); plt.title('pc2')
plt.show()
2. pc1 사진에 가중치를 임의로 주어 mean과 더한 픽셀값을 시각화해보자
import numpy as np
r = 2
c = 5
w = np.linspace(-10,10, r*c)
warray([-10. , -7.77777778, -5.55555556, -3.33333333,
-1.11111111, 1.11111111, 3.33333333, 5.55555556,
7.77777778, 10. ])fig = plt.figure(figsize = (14,7))
for i in range(r*c):
ax = fig.add_subplot(r,c,i+1)
tmp = face_mean + w[i]*face_p1
ax.imshow(tmp, plt.cm.bone)
ax.set_title(f'pc1 \n weight = {round(w[i],2)}')
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.show()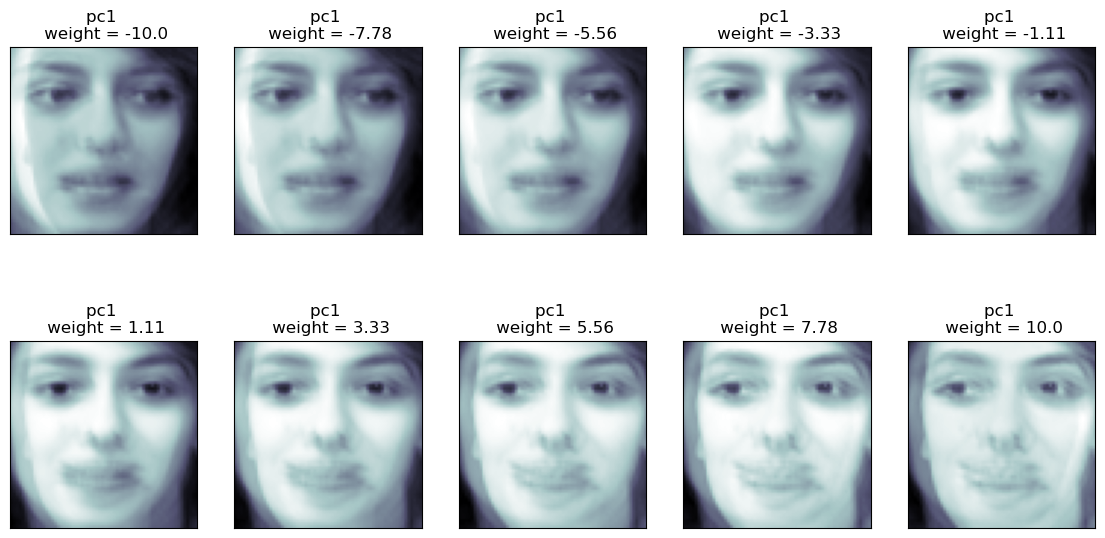
3. pc2 사진에 임의의 가중치를 face_mean에 더하여 시각화해보자
r = 2
c = 5
w = np.linspace(-10,10,r*c)
warray([-10. , -7.77777778, -5.55555556, -3.33333333,
-1.11111111, 1.11111111, 3.33333333, 5.55555556,
7.77777778, 10. ])fig = plt.figure(figsize=(14,7))
for i in range(r*c):
ax = fig.add_subplot(r,c,i+1)
tmp = face_mean + w[i]*face_p2
ax.imshow(tmp, plt.cm.bone)
ax.set_title(f'pc2 \n weight = {round(w[i],2)}')
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.show()
4. pc1과 pc2에 모두 가중치를 곱하여 face_mean과 더하여 시각화해보기
x = np.linspace(-10, 10, 5)
y = np.linspace(-10, 10, 5)xarray([-10., -5., 0., 5., 10.])yarray([-10., -5., 0., 5., 10.])w1, w2 = np.meshgrid(x, y)w1.reshape(-1,)array([-10., -5., 0., 5., 10., -10., -5., 0., 5., 10., -10.,
-5., 0., 5., 10., -10., -5., 0., 5., 10., -10., -5.,
0., 5., 10.])w2.reshape(-1,)array([-10., -10., -10., -10., -10., -5., -5., -5., -5., -5., 0.,
0., 0., 0., 0., 5., 5., 5., 5., 5., 10., 10.,
10., 10., 10.])w1 = w1.reshape(-1,)
w2 = w2.reshape(-1,)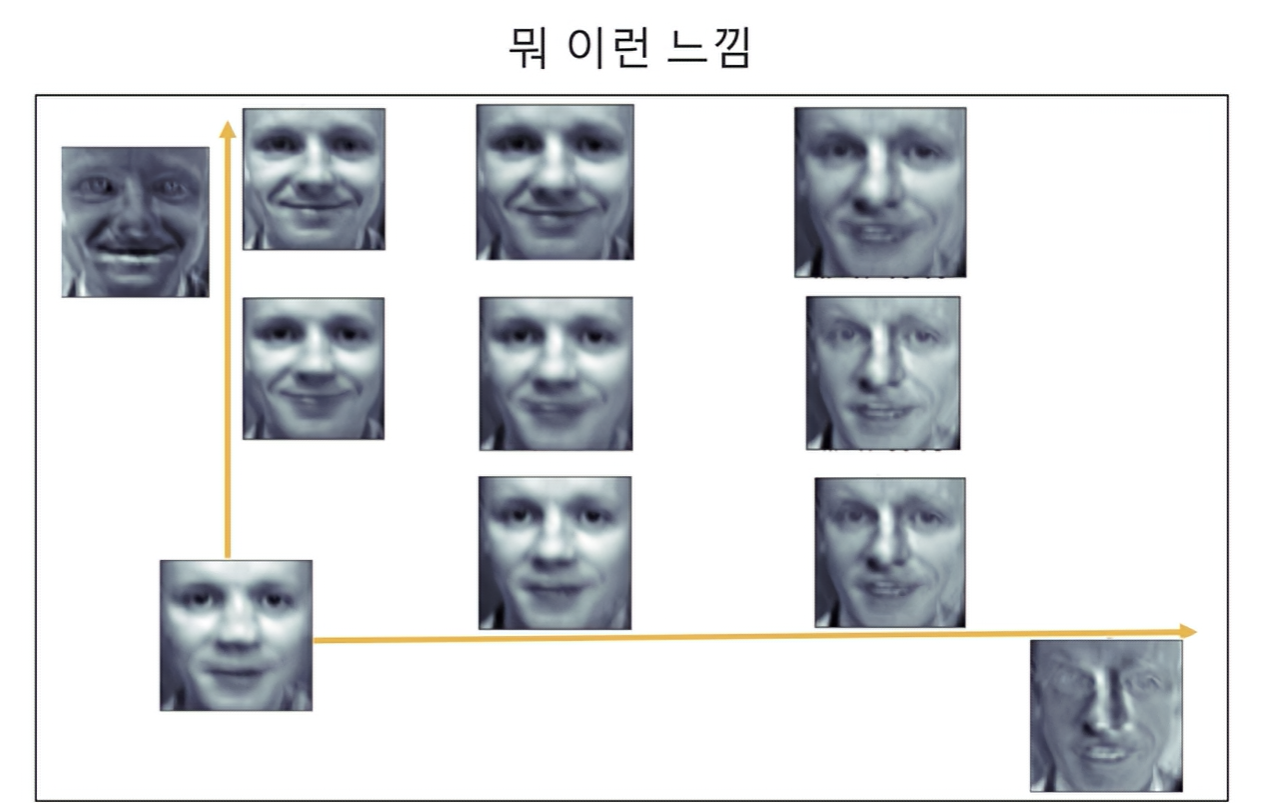
결론: 여기서 제일 가운데 있는 face_mean(pca.mean_)이 pc1, pc2 차원의 원점이라고 생각해도 좋다. pc1, pc2축이 교차하는 원점임
fig = plt.figure(figsize=(40,20))
r = 5
c = 5
for i in range(r*c):
ax = fig.add_subplot(r,c,i+1)
tmp = face_mean + w1[i]*face_p1 + w2[i]*face_p2
ax.imshow(tmp, cmap = plt.cm.bone)
ax.set_title(f'w1: {round(w1[i],2)} w2: {round(w2[i],2)}')
ax.xaxis.set_ticks([])
ax.yaxis.set_ticks([])
plt.tight_layout()
plt.show() 
