머신러닝_1 (Iris)
머신러닝의 교과서적 정의

-
명시적인 프로그램에 의해서가 아니라, 주어진 데이터를 통해 규칙을 찾는 것
-
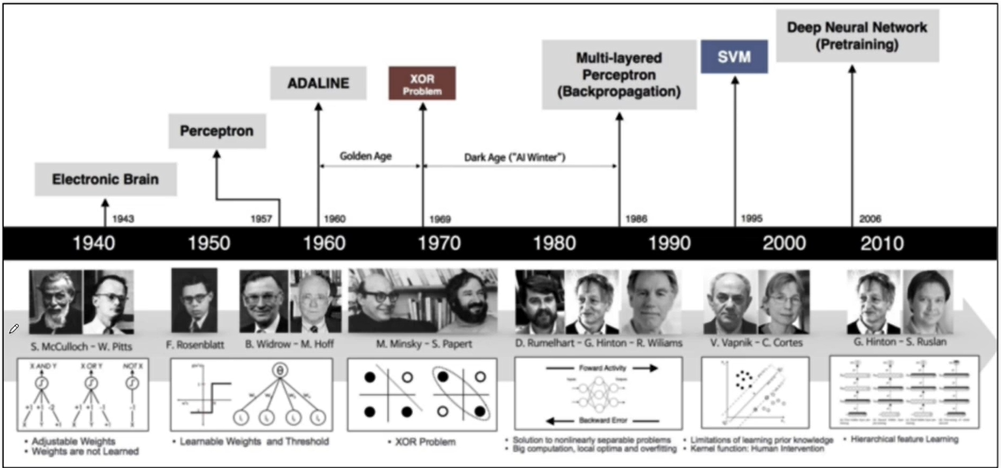
머신러닝(딥러닝)의 역사 1

-
머신러닝(딥러닝)의 역사 2

-
머신러닝(딥러닝)의 역사 3
Iris Classification
- IRIS

- 프랑스의 국화
- 아이리스 iris라는 이름은 그리스 신화의 무지개의 여신인 iris에서 따온 것
헤라 여신이 iris에세 내린 축복의 숨결이 땅으로 떨어져 핀 꽃 - 꽃말은 좋은 소식, 잘 전해 주세요, 사랑의 메시지
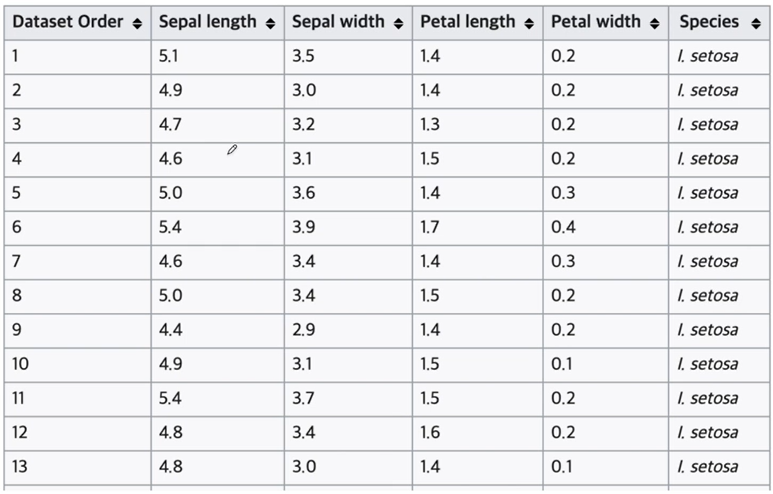
Iris의 품종 분류
- 꽃잎(petal), 꽃받침(sepal)의 길이/너비 정보를 이용해서 이3종의 품종을 구분할 수 있을까?


-
1930년대에 통계학자이자 유전학자였던 로널드 피셔가 iris 데이터를 수집 정리해 두었다.
-
로널드의 iris 데이터
데이터 관찰(python)
- Iris 데이터 불러오기
코드를 입력하세요
from sklearn.datasets import load_iris
iris = load_iris()- iris 데이터 확인
코드를 입력하세요
iris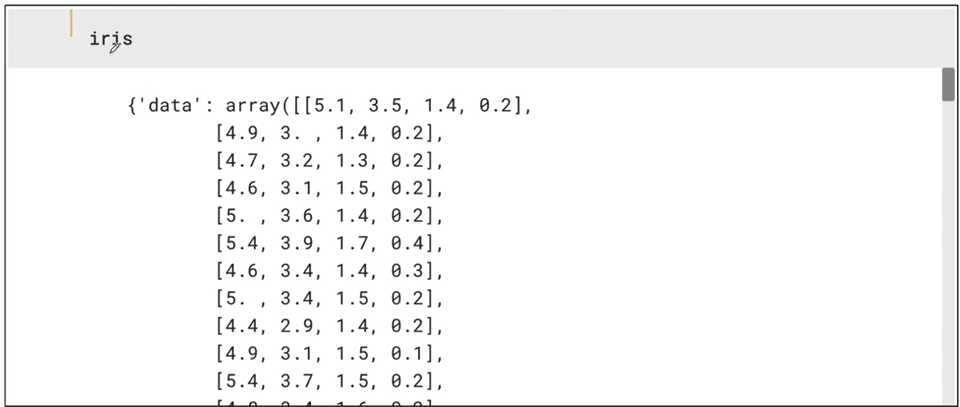
- sklearn의 datasets은 Python의 dict 형과
iris.keys()
- target 데이터 호출하기
iris.target
- iris.data 데이터 호출하기
iris.data
-
iris의 petal, sepal의 length, width로 품종을 구분할 수 있는지 확인해보자.
-
먼저 iris 3개의 품종인 versicolor, virginica, setosa를 구분하기 위해 각각의 특성을 공부하기
- petal, sepal의 length, width에 대해서 파악하기
Pandas
import pandas as pd-
데이터를 바로 딥러닝에 적용하거나 sklearn을 이용한 머신러닝에 적용할 때 꼭 필요한 것은 아니지만, 데이터를 정리해서 관찰할 때는 아주 유용한 도구가 pandas 이다.
-
DataFrame으로 만들어보기
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_name)
iris_pd.head()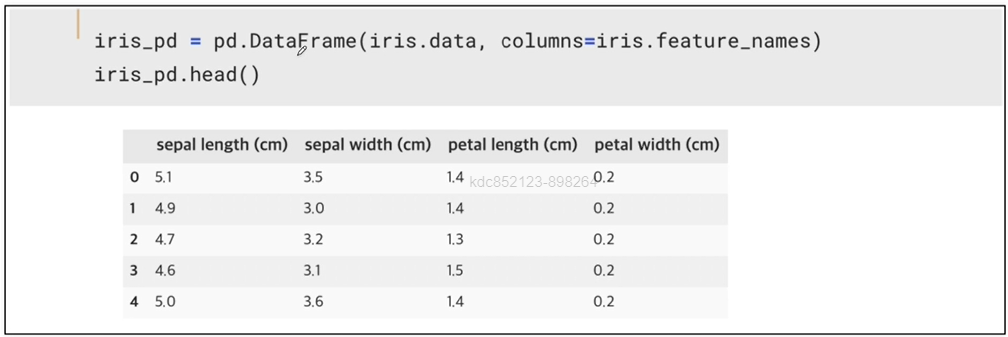
- 품종 정보 추가하기
iris_pd['species'] = iris.target
iris_pd.head()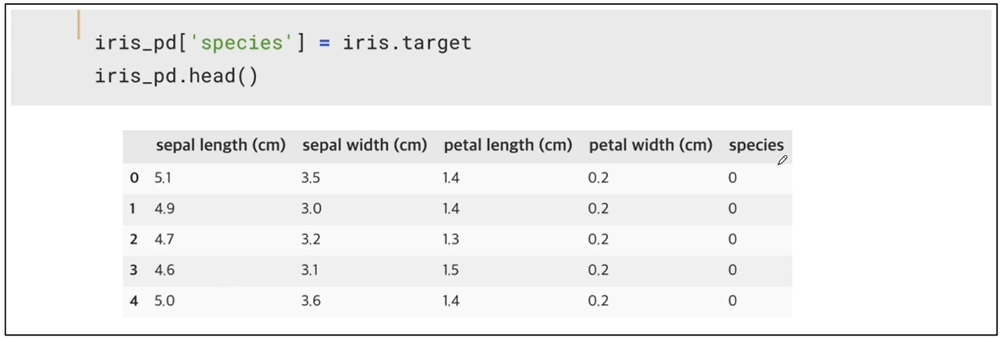
-
species에는 iris의 3가지 품종을 의미하는 0, 1, 2의 값이 들어있다.
-
그래프도 그리기 위해 seaborn, matplotlib import 하기
import seaborn as sns
import matplotlib.pyplot as plt-
boxplot(x='sepal length (cm)')
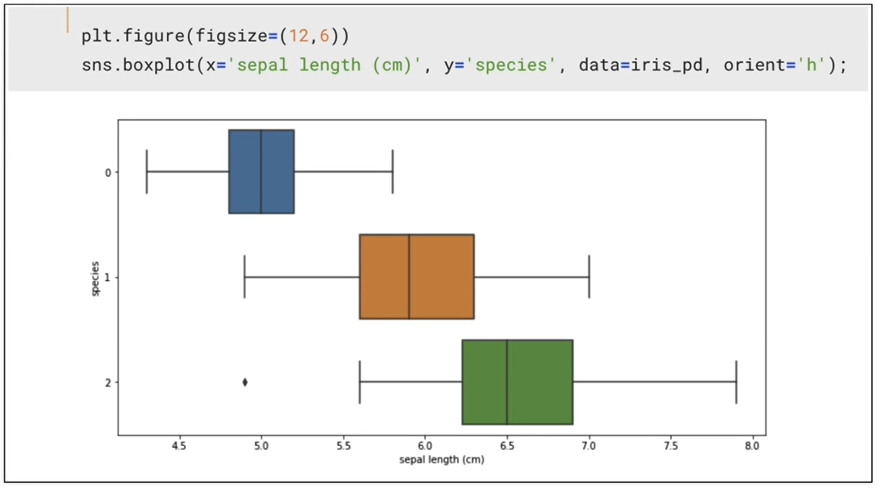
-
boxplot(x='sepal width (cm)')
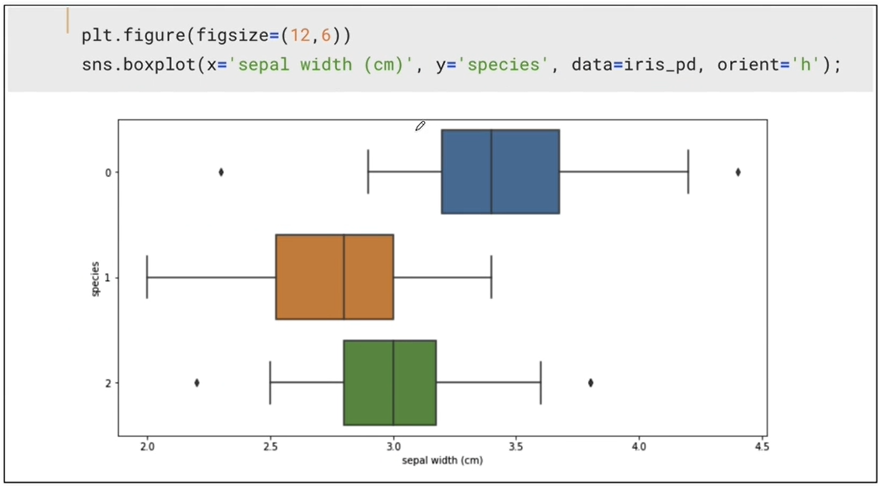
-
boxplot(x='petal length (cm)')
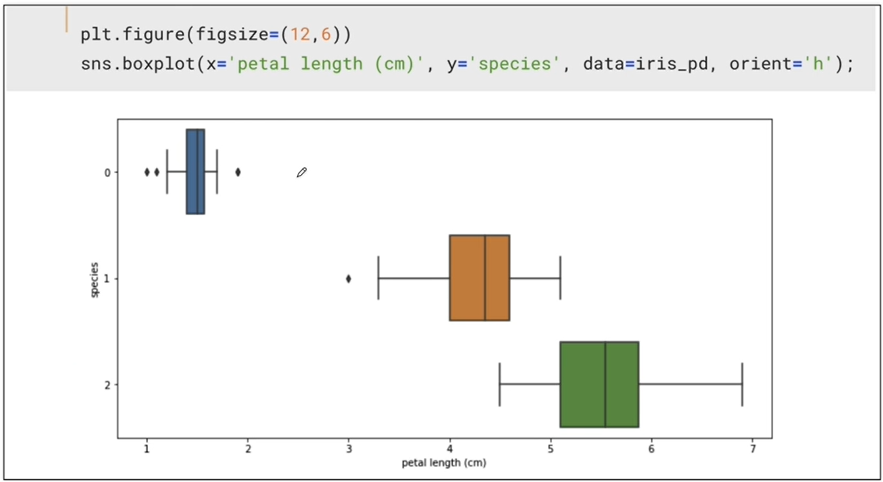
-
boxplot(x='petal width (cm)')
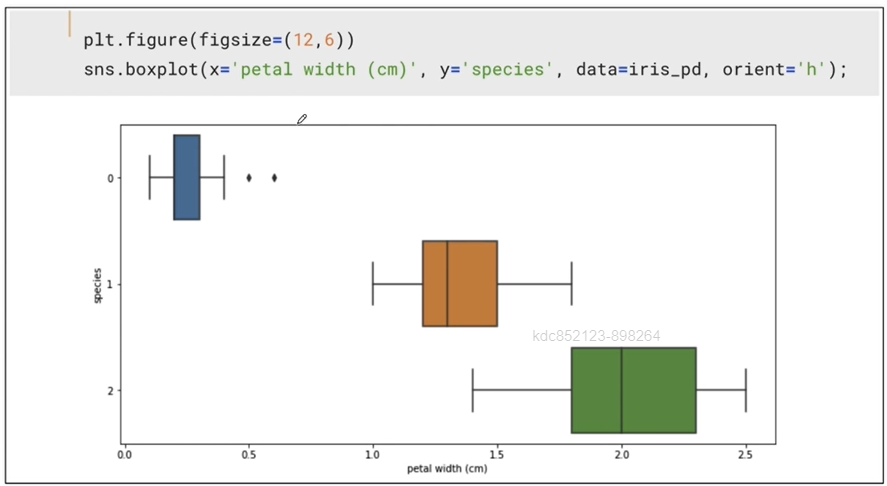
-
pairplot
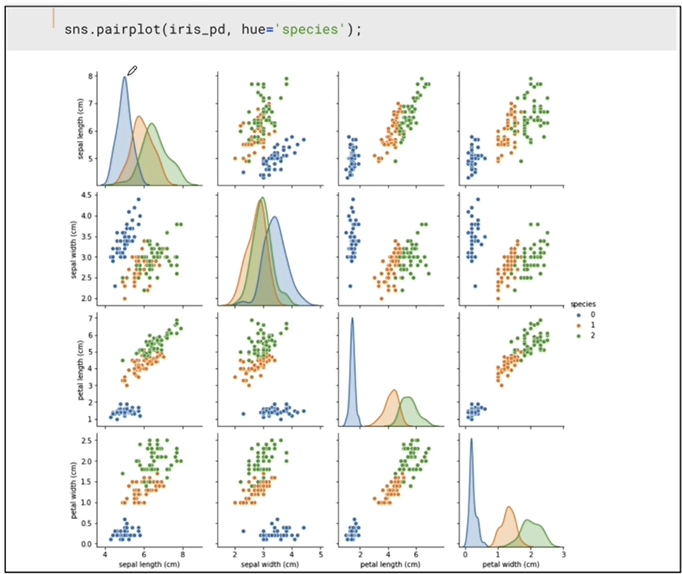
-
좀더 세세한 비교를 하기위한 가짓수 줄이기

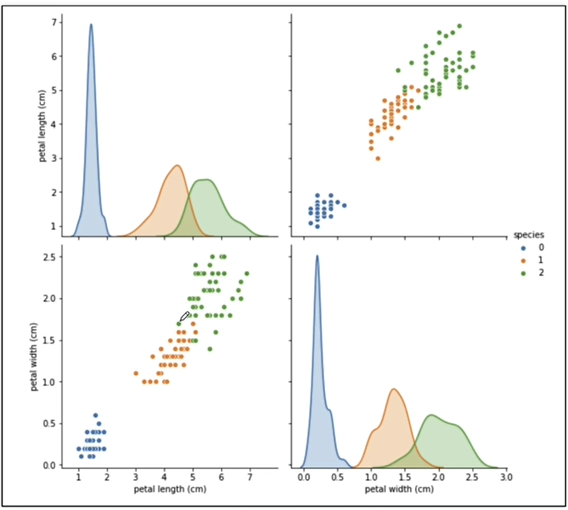
-
3개의 품종 중 setosa는 쉽게 구분 가능
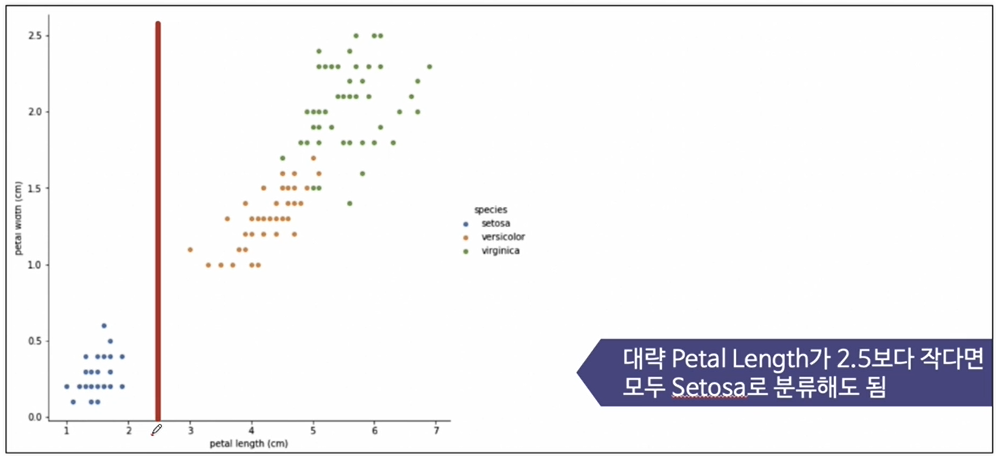
-
나머지 두개의 품종은?
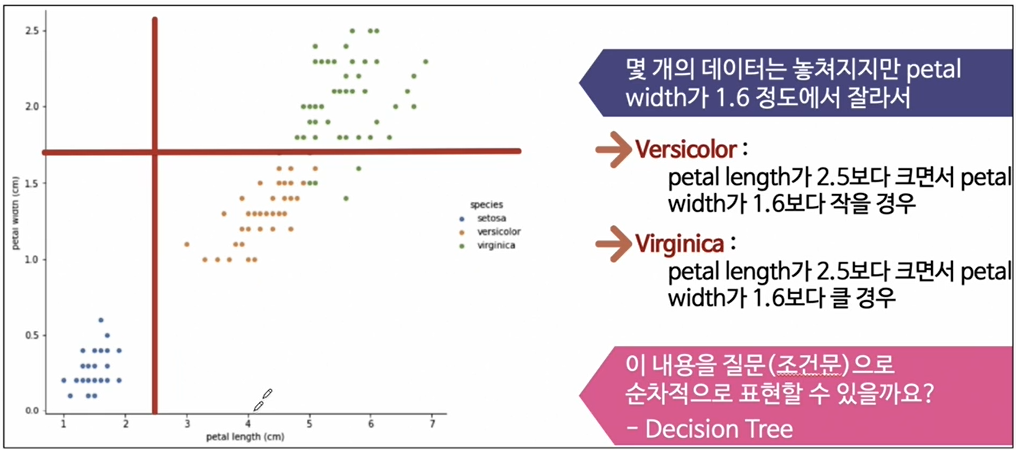
-
아이리스의 3개 품종을 구분하는 규칙
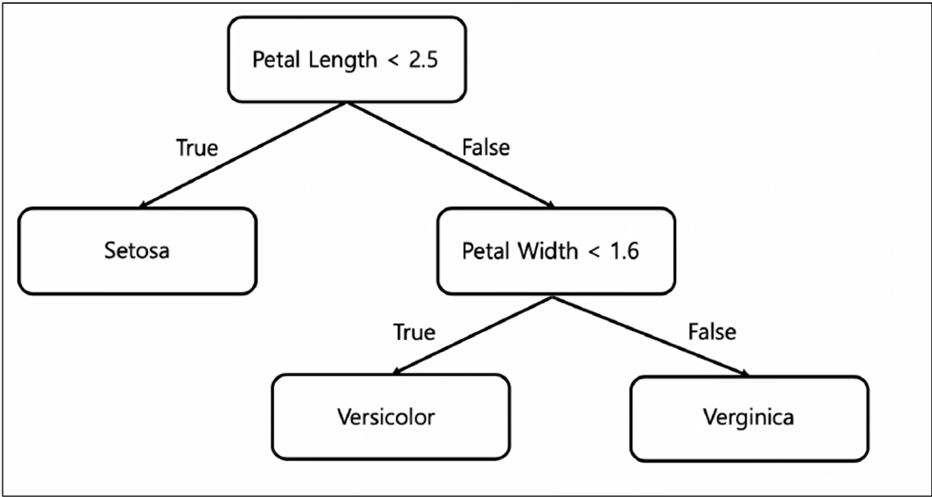
-
이것이 최적의 해답인가? 라는 질문에서 알고리즘이 등장.
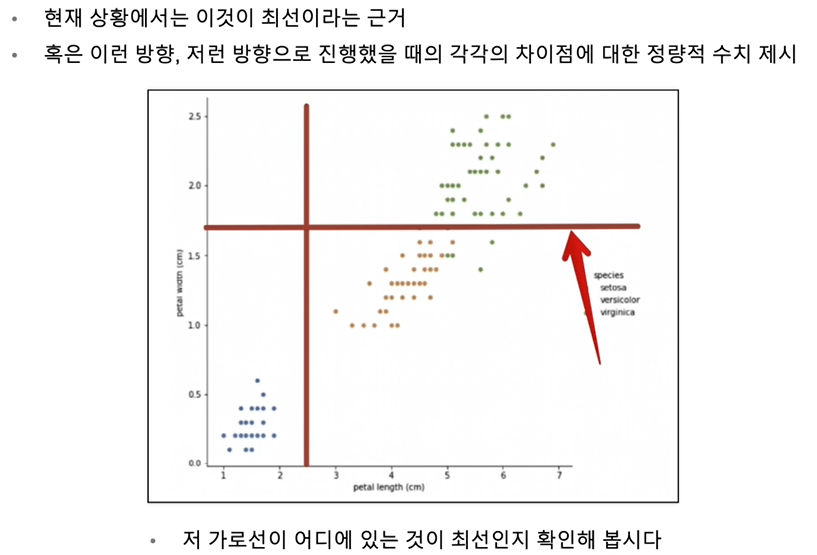
Decision Tree
-
사람들이 직관적으로 알기 쉽다.
-
설정
plt.figure(figsize=(12,6))
sns.scatterplot(x="petal length (cm)", y="petal width (cm)",
data=iris_pd, hue="species", palette="Set2")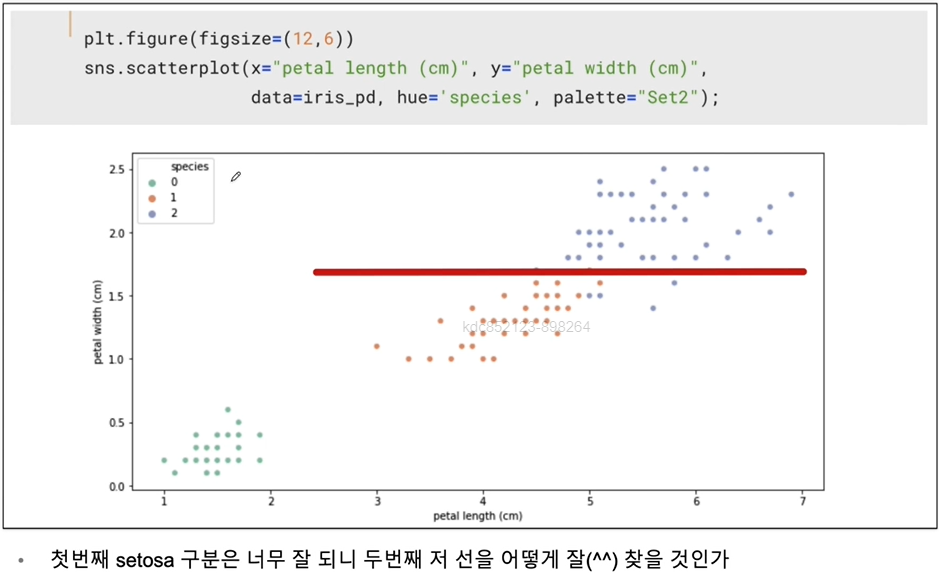
-
데이터 변경
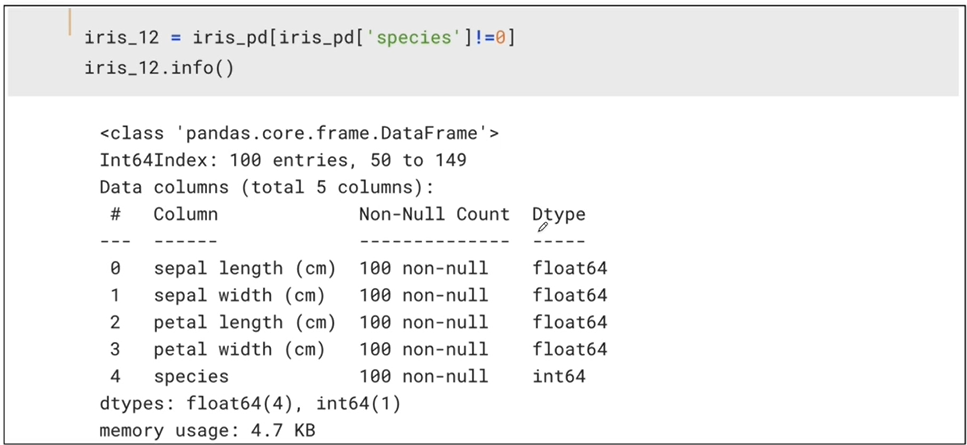
-
학습을 위해 두개의 데이터에 집중
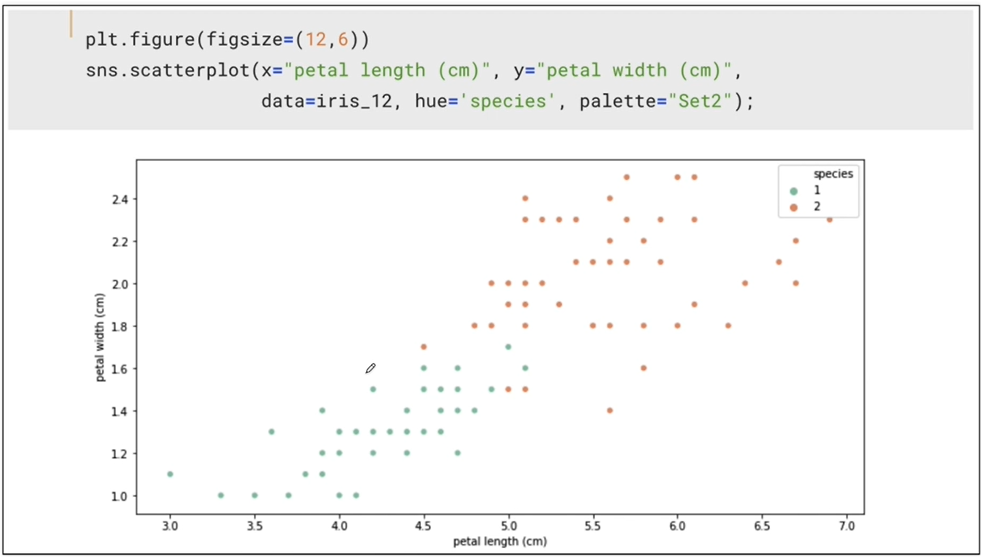
Decision Tree의 분할 기준(Split Criterion)
- 정보획득 Information Gain
- 정보의 가치를 반환하는 데 발생하는 사전의 확률이 작을수록 정보의 가치는 커진다
- 정보 이득이란 어떤속성을 선택함으로 인해서 데이터를 더 잘 구분하게 되는 것
엔프로피 개념
- 열역학의 용어로 물질의 열적 상태를 나타내는 물리 량의 단위 중 하나, 무질서의 정보를 타나냄
- 1948년 엔트로피 개념에서 힌트를 얻어 확률 분포의 무질서도나 불확실성 혹은 정보부담 정도를 나타내는 정보 엔트포리 개념을 클로드 새넌이 고안함

- entropy : 얼마만큼의 정보를 담고 있는가? 또한, 무질서도(disorder)를 의미, 불확실성(uncertainty)를 나타내기도 함
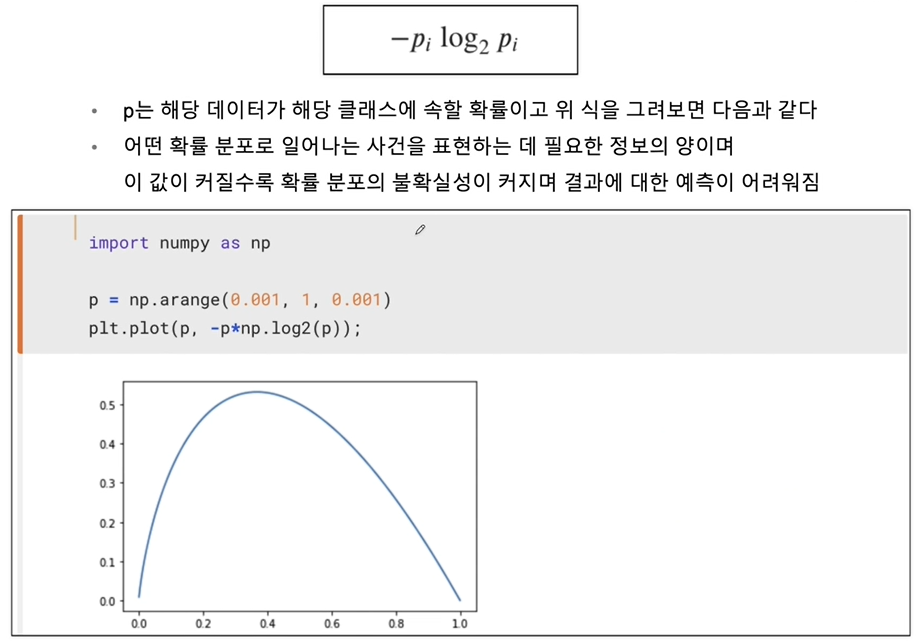
-
엔트로피는 이 확률들의 합이다
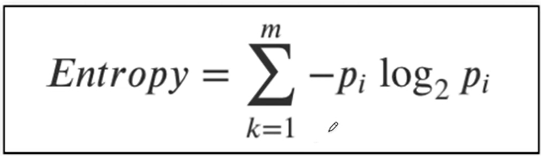
-
엔트로피 연습
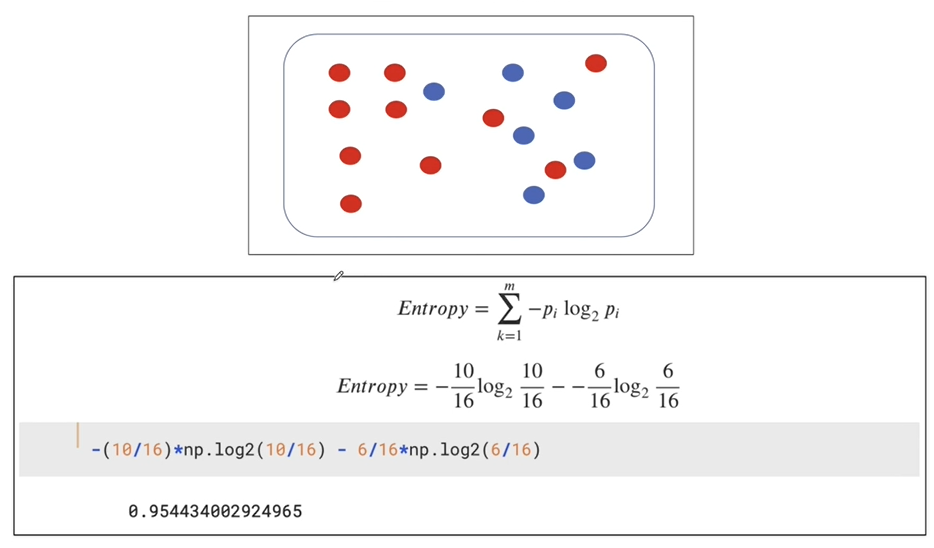
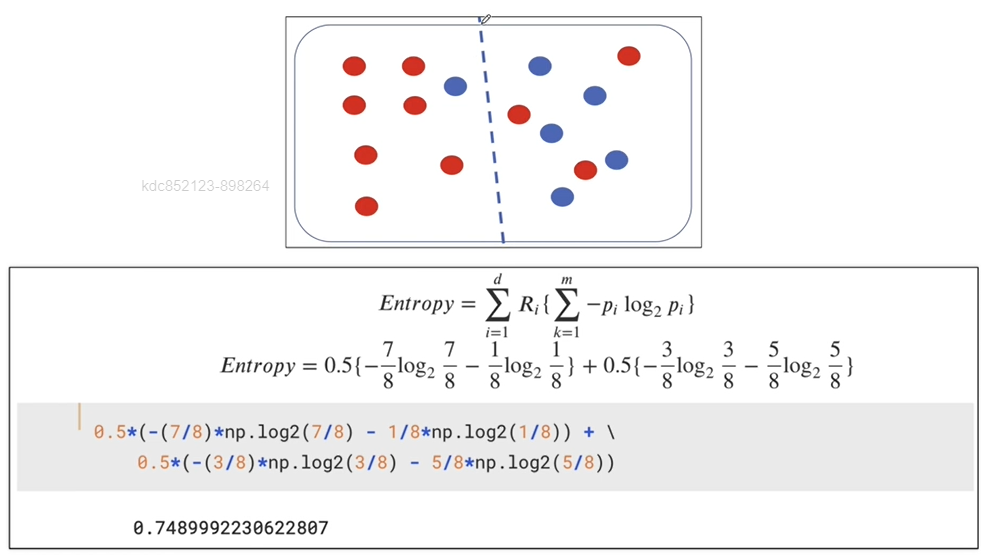
- 엔트로피가 내려갔다면 분할 하는 것이 좋음
지니계수

- Gini index 혹은 불순도율
- 엔트로피의 계산량이 많아서 비슷한 개념이면서 계산량이 적은 지니계수를 사용하는 경우가 많다

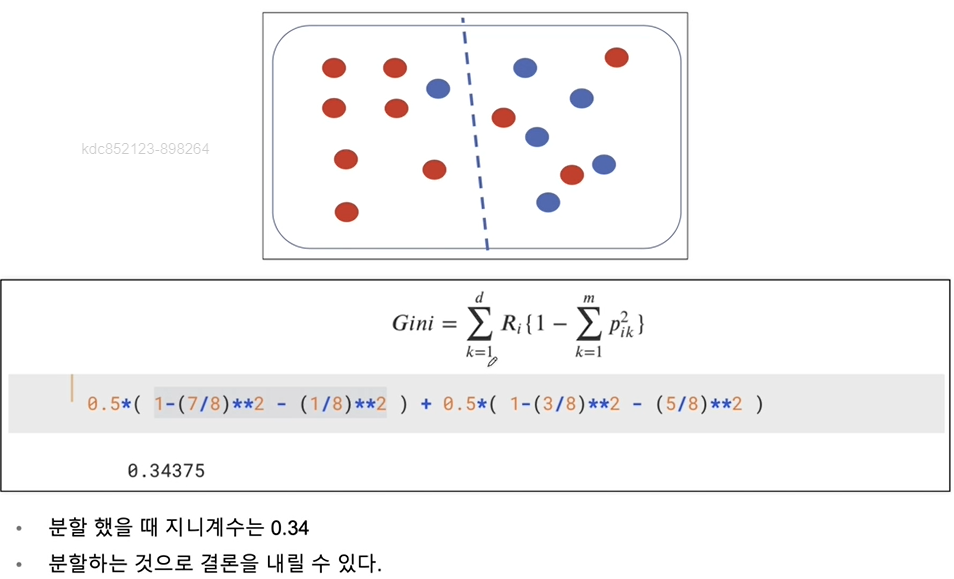
-
그럼 어떻게 분할 하면 좋을까?
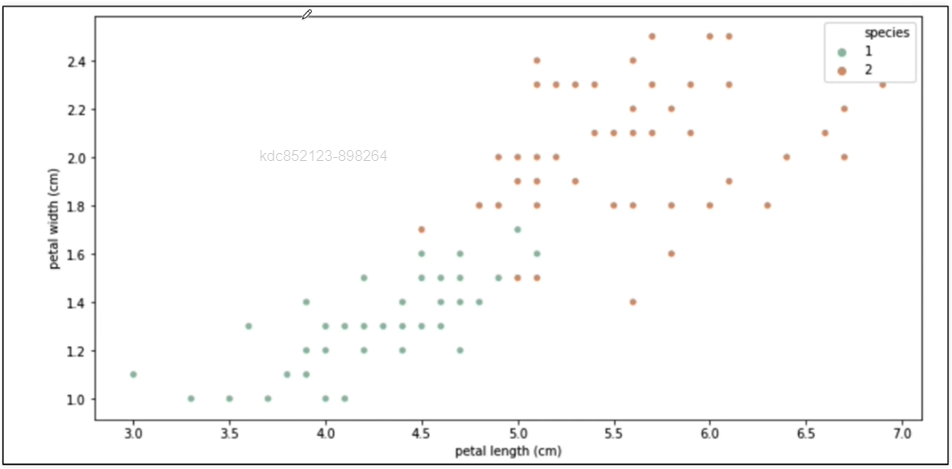
-
일단 쉽게 분할할 수 있는 선을 그어본다.
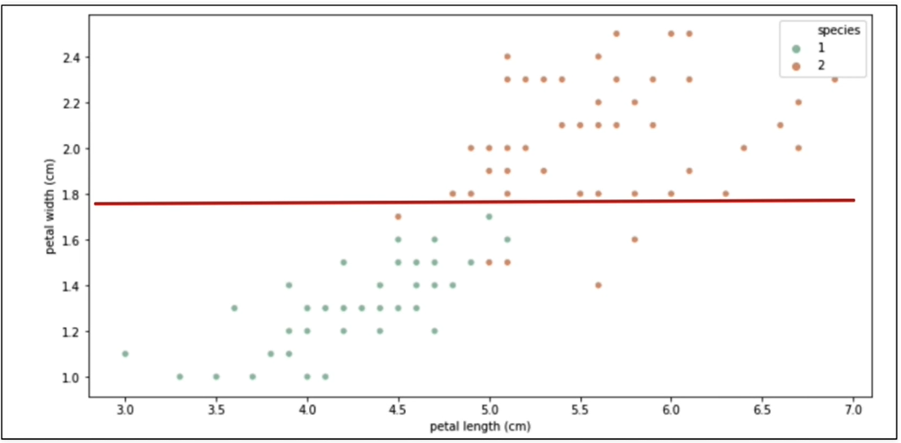
Scikit Learn
-
Scikit Learn 소개

-
Scikit을 이용한 결정나무의 구현
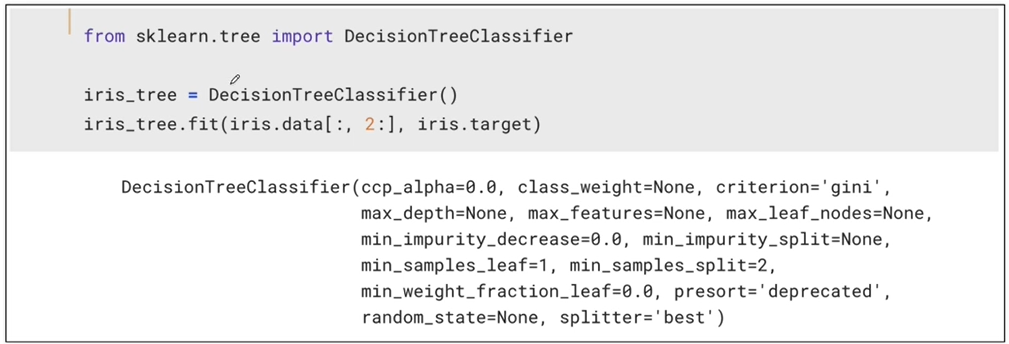
-
Accuracy 확인
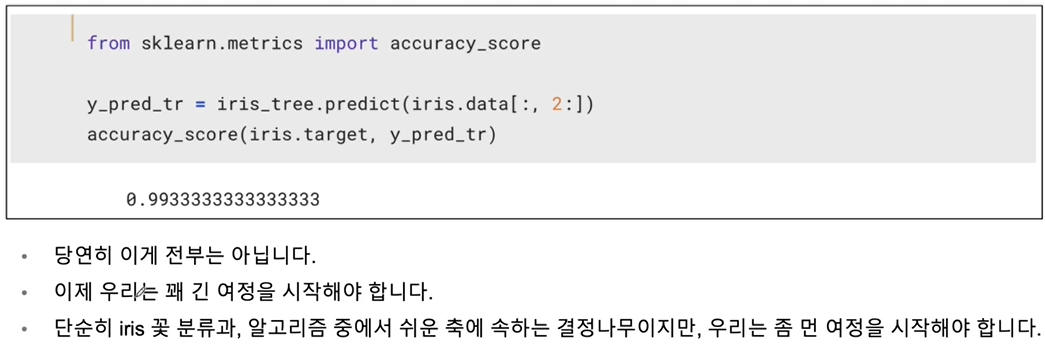
데이터 나누기
Decision Tree를 이용한 Iris 분류
과적합(overfitting)
-
과적합
- 머신 러닝 (machine learning)에서 overfitting은 학습데이터를 과하게 잘 학습하는 것을 뜻한다. 일반적으로 학습 데이터는 실제 데이터의 부분집합인 경우가 대부분이다. 따라서, 아래의 그래프처럼 학습 데이터에 대해서는 오차가 감소하지만, 실제 데이터에 대해서는 오차가 증가하는 지점이 존재할 수 있다.
- 출처 : https://untitledtblog.tistory.com/68
-
머신러닝의 일반적인 절차
- 지도학습
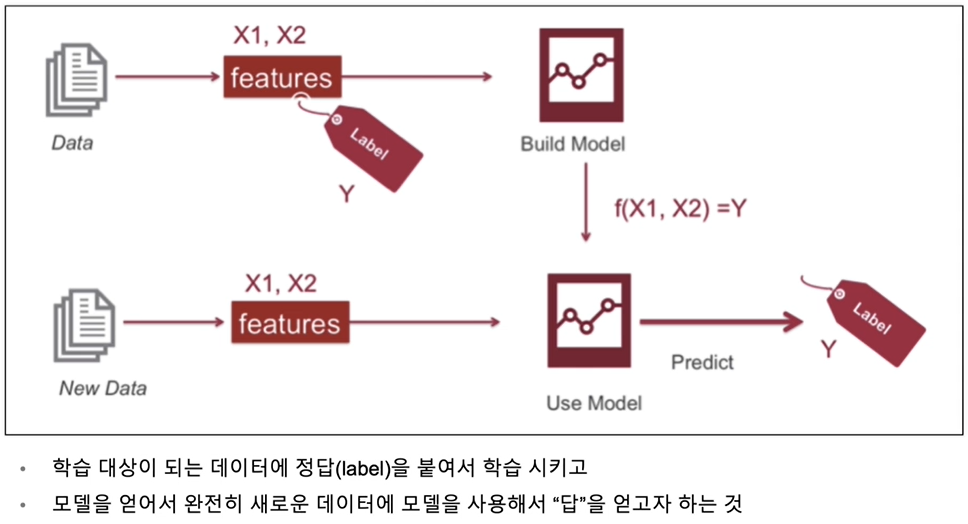
- 지도학습
-
sklearn에 없는 몇몇 유용한 기능을 가진 mlxtend 모듈 설치하기

-
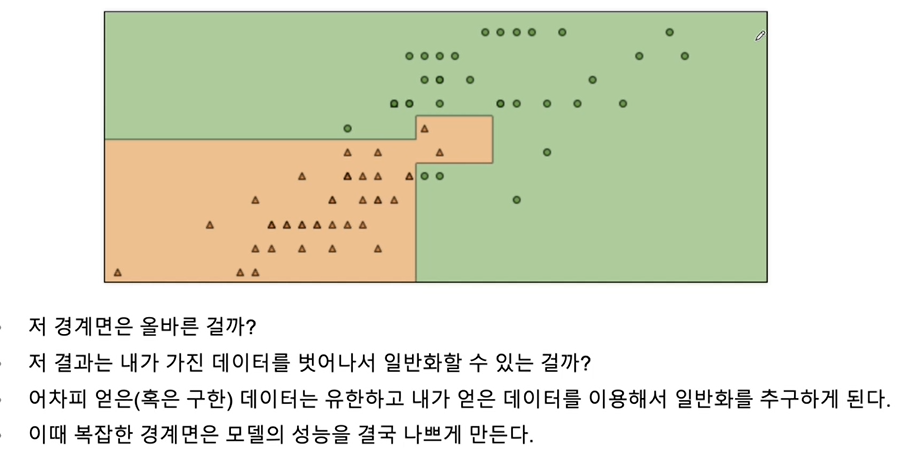
iris의 품종을 분류하는 결정나무 모델이 어떻게 데이터를 분류했는지 확인해보자

-
Accuracy(정확도)가 높다고 믿을 수 있을까?

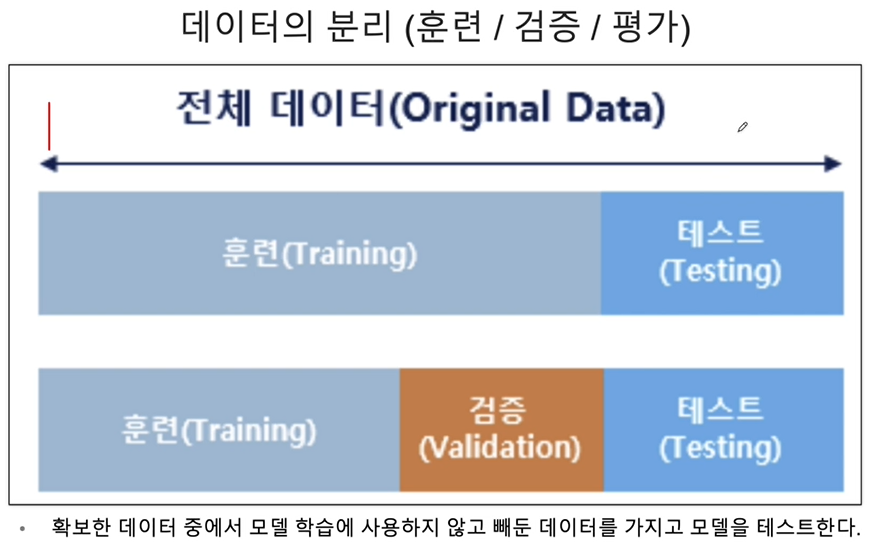
데이터 분리
-
전체 데이터셋에서 훈련용 데이터와 테스트용 데이터로 분리하여 진행하기 위함
-
Iris 데이터 불러오기

-
데이터를 훈련 / 테스트로 분리

-
훈련용 / 테스트용으로 분리가 잘됬는지 확인
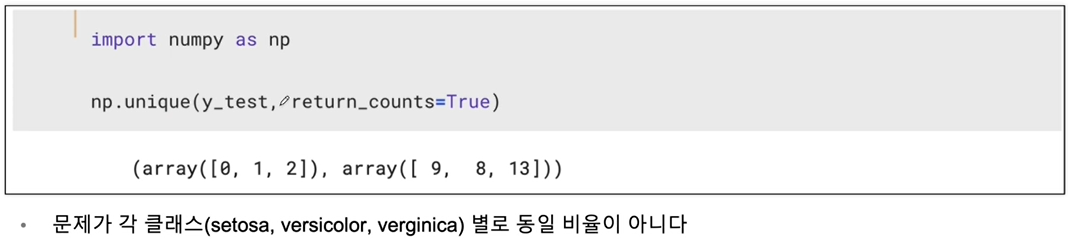
-
종류별로 일정하네 분리하기위해 stratify 옵션을 사용
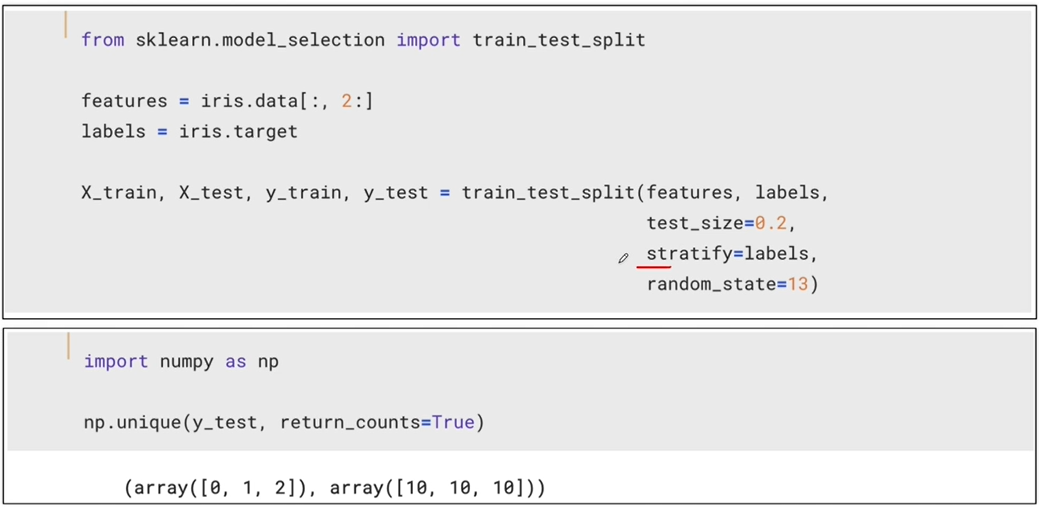
-
train 데이터만 대상으로 결정나무 모델을 만들어보자
- max_depth로 과적합을 방지하기위해 성능을 제한시킬수 있다.
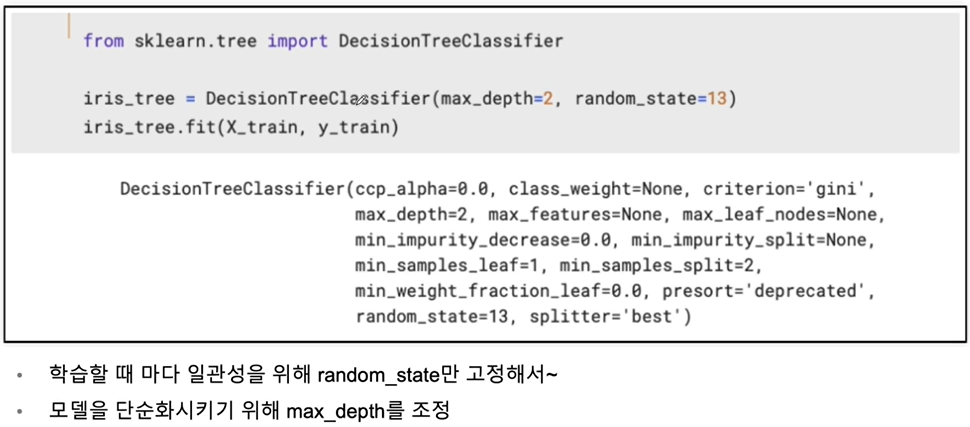
- max_depth로 과적합을 방지하기위해 성능을 제한시킬수 있다.
-
train 데이터에 대한 accuracy 확인

-
모델 확인
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(12, 8))
plot_tree(iris_tree);
-
iris 꽃을 분류하는 결정나무 모델
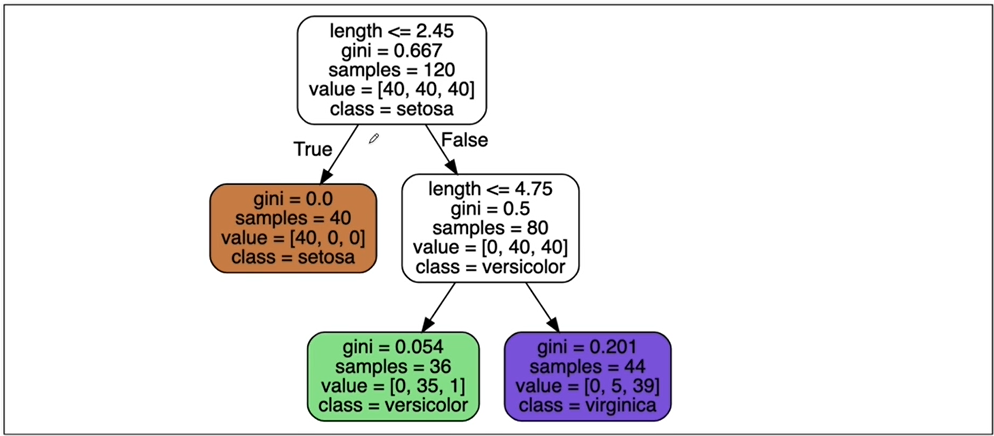
-
훈련 데이터에 대한 결정경계를 확인

-
훈련용 데이터에 대한 결정경계
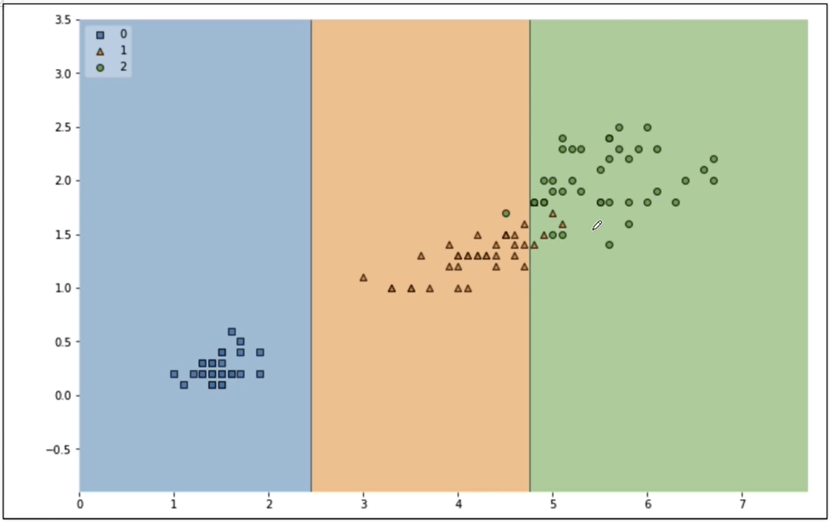
-
test 데이터에 대한 accuracy

-
결과
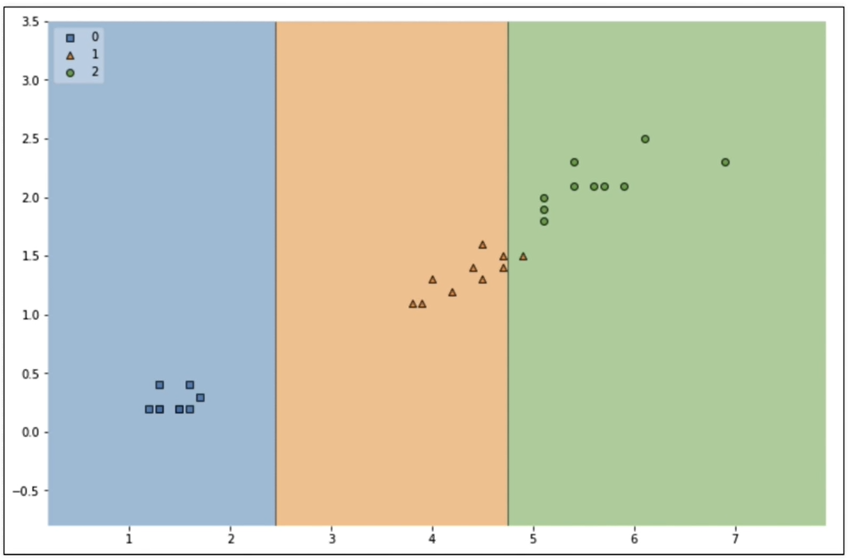
-
주요 특성 확인하기
- maxdepth를 2로 한정했을 경우 feature_importances 확인가능

- maxdepth를 2로 한정했을 경우 feature_importances 확인가능
간단한 zip과 언패킹
-
리스트를 튜플로 zip

-
튜플을 dict으로

-
한번에 리스트 -> 튜플 -> dict

-
unpacking 인자를 이용한 역변환

