EDA(Exploratory Data Analysis) : 탐색적 데이터 분석
데이터를 분석하고 결과를 내는 과정에 있어서 지속적으로 해당 데이터에 대한 ‘탐색과 이해’를 기본으로 가져야 한다는 것을 의미한다.
EDA를 잘하려면?
-
raw data 의 description, dictionary 를 통해 데이터의 각 column들과 row의 의미를 이해하는 기술.
-
결측치 처리 및 데이터필터링 기술.
-
누구나 이해하기 쉬운 시각화를 하는 기술.
예제 : 보스턴 부동산
Feature Description
TOWN : 지역 이름
LON, LAT : 위도, 경도 정보
CMEDV : 해당 지역의 집값(중간값) #target feature
CRIM : 근방 범죄율
ZN : 주택지 비율
INDUS : 상업적 비즈니스에 활용되지 않는 농지 면적
CHAS : 경계선에 강에 있는지 여부
NOX : 산화 질소 농도
RM : 자택당 평균 방 갯수
AGE : 1940 년 이전에 건설된 비율
DIS : 5 개의 보스턴 고용 센터와의 거리에 다른 가중치 부여
RAD : radial 고속도로와의 접근성 지수
TAX : 10000달러당 재산세
PTRATIO : 지역별 학생-교사 비율
B : 지역의 흑인 지수 (1000(B - 0.63)^2), B는 흑인의 비율.
LSTAT : 빈곤층의 비율
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("https://raw.githubusercontent.com/yoonkt200/FastCampusDataset/master/BostonHousing2.csv")
#데이터셋 기본 정보 탐색
df.shape
df.isnull().sum()
df.info()
#target feature 확인
df['CMEDV'].describe()
df['CMEDV'].hist(bins=50) #히스토그램으로 시각화 bins는 가로축 개수
df.boxplot(column=['CMEDV']) #boxplot으로 시각화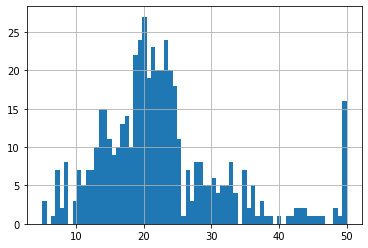
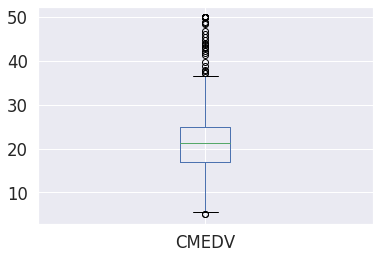
35이상의 값은 outlier라고 고려할만 함
numerical_columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX',
'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO',
'B', 'LSTAT']
fig = plt.figure(figsize = (16, 20)) #figure를 생성하고 사이즈 설정함 일반적으로 16, 20이 보기에 간편함
ax = fig.gca() #axis를 설정
df[numerical_columns].hist(ax=ax)
plt.show()feauture간의 상관관계 분석
cols = ['CMEDV', 'CRIM', 'ZN', 'INDUS',
'CHAS', 'NOX', 'RM', 'AGE', 'DIS',
'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
corr = df[cols].corr(method = 'pearson') #피어슨 상관계수를 구하는 것
fig = plt.figure(figsize = (16, 12)) #시각화
ax = fig.gca()
sns.set(font_scale=1.5) # seaborn library font 설정
hm = sns.heatmap(corr.values,#heatmap 사용
annot=True,
fmt='.2f', #소수점 2번째 자리
annot_kws={'size': 15},
yticklabels=cols,
xticklabels=cols,
ax=ax)
plt.tight_layout() #창에 딱 맞게 설정
plt.show()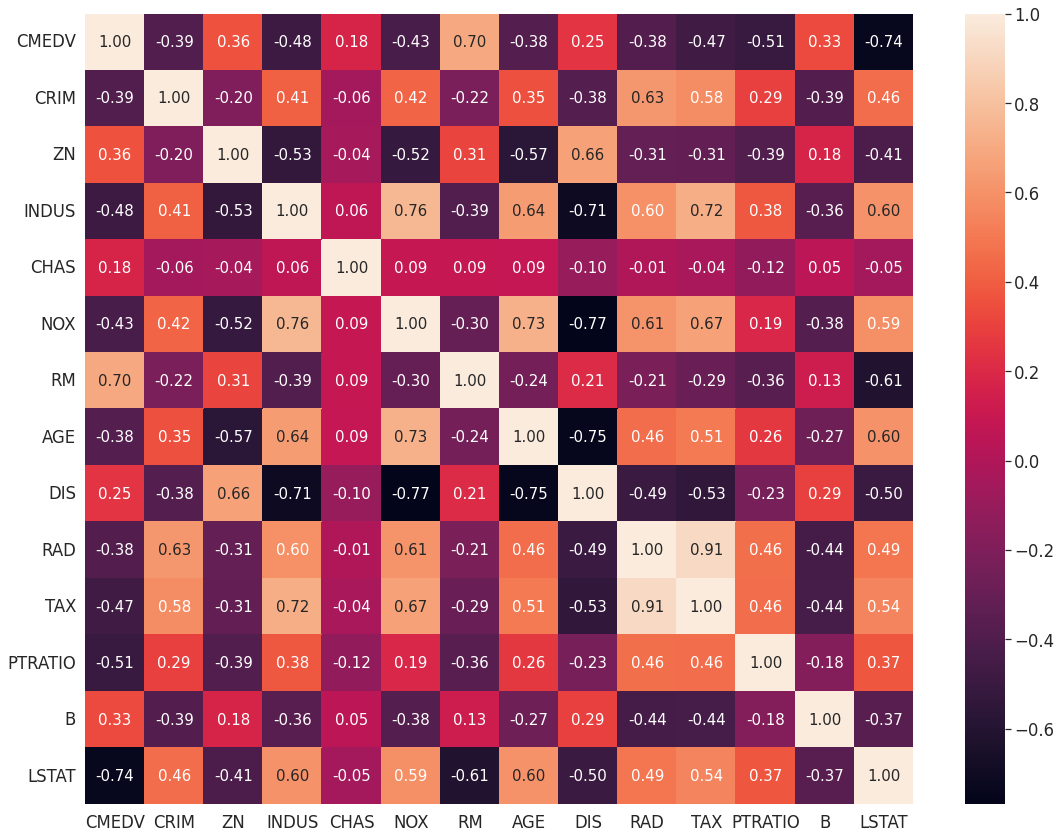
우리가 target으로 가지는 CMEDV와 상관관계를 가지는 변수는 RM과 LSTAT. 각각 양과 음의 상관관계를 가지고 있음
이를 확인하기 위해 CMEDV와 RM의 관계 plot
RM은 방의 개수인데 방의 개수와 밀접한 연관이 있음을 직관적으로 이해할 수 있음
plt.plot('RM', 'CMEDV',
data=df,
linestyle='none',
marker='o',
markersize=5,
color='blue',
alpha=0.5)
plt.title('Scatter Plot')
plt.xlabel('RM')
plt.ylabel('CMEDV')
plt.show()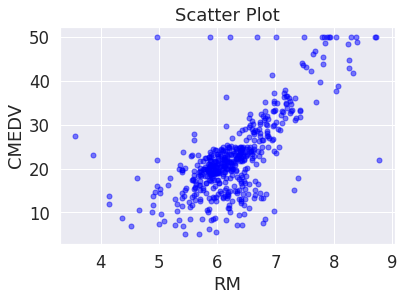
양의 상관관계를 가는 것을 알 수 있음
LSTAT의 경우에는 빈곤층 비율로 집값이 떨어질 가능성이 높음
plt.plot('LSTAT', 'CMEDV',
data=df,
linestyle='none',
marker='o',
markersize=5,
color='blue',
alpha=0.5)
plt.title('Scatter Plot')
plt.xlabel('LSTAT')
plt.ylabel('CMEDV')
plt.show()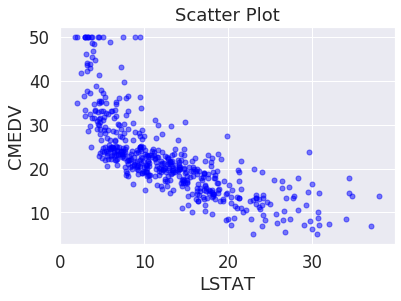
직관적으로 음의 상관관계를 가지는 것을 이해할 수 있음
지역에 따른 부동산 가격 분석
df['TOWN'].value_counts()
df['TOWN'].value_counts().hist(bins=50)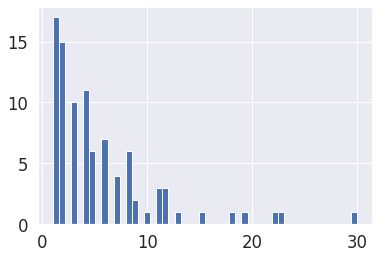
지역별로 대략 10개 정도의 데이터가 존재
지역별 부동산 가격 분포 분석
fig = plt.figure(figsize = (12, 20))
ax = fig.gca()
sns.boxplot(x='CMEDV', y='TOWN', data=df, ax=ax)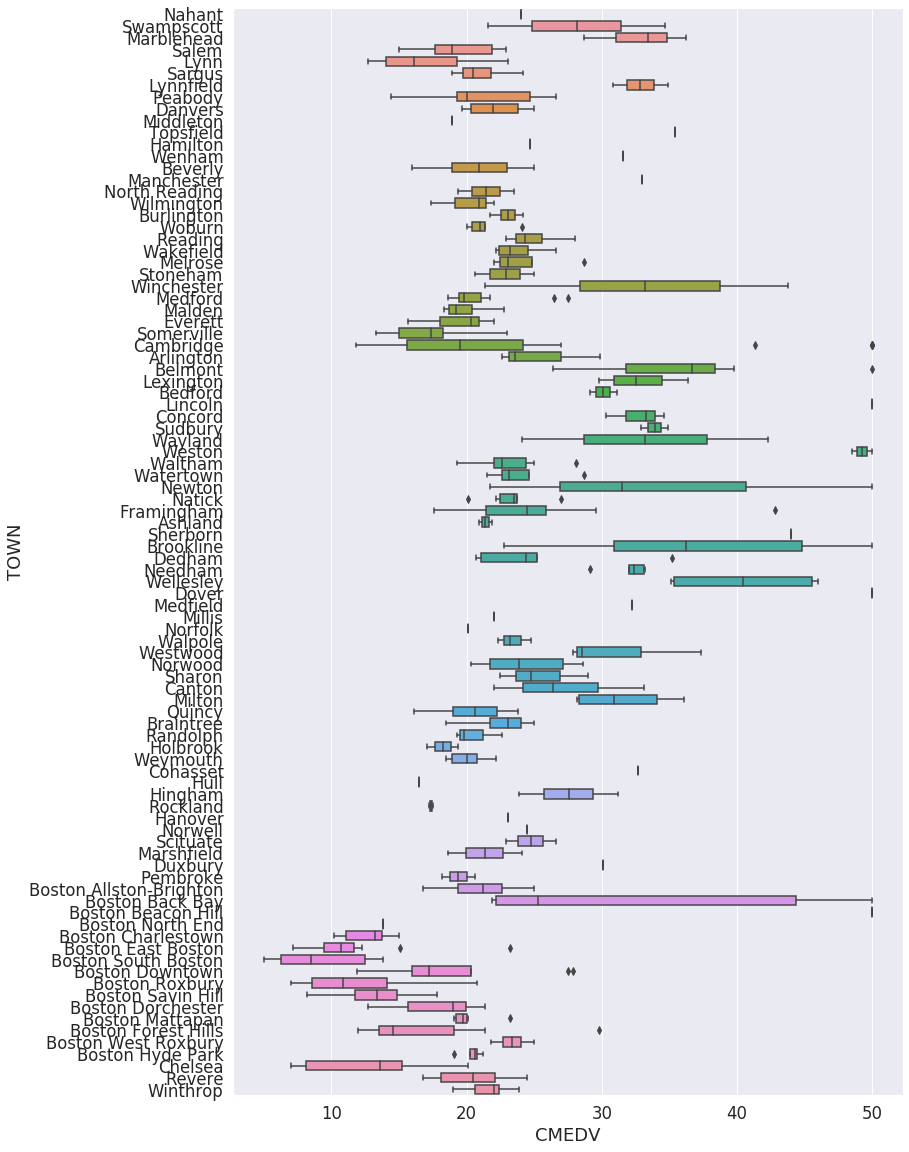
이를 통해 지역별로 집값에 대한 insight를 얻을 수 있다.
지역별 범죄률은 어떨까?
fig = plt.figure(figsize = (12, 20))
ax = fig.gca()
sns.boxplot(x='CRIM', y='TOWN', data=df, ax=ax)
특정지역에 범죄율이 높은 것을 알 수 있다.\
위의 box plot과 비교해 보았을 때 집값과 상관관계가 있는것을 확인 할 수 있다.
함수를 데이터에 맞추는 과정 (모델 학습 과정)
OLS(결정론적-더 일반적인 방법), MLE(확률론적)
OLS(Ordinary Least Square)
오차의 제곱을 최소화하는 방법
대표적인 cost function이 MSE
MSE가 2차 방적식이 떄문에 최솟값이 존재 이를 찾는 것이 gradient descent
모델 평가 방법
R-squared (결정 계수)
1에 가까울 수록 더 정확하다.
t-test
OLS의 단점은 w가 0이 될 수 있으며
다중 공선성
변수간의 강한 상관관계
예제
데이터 전처리
feature_standardization
from sklearn.preprocessing import StandardScaler #sklearn api 사용
# feature standardization
scaler = StandardScaler()
scale_columns = ['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
df[scale_columns] = scaler.fit_transform(df[scale_columns])데이터 셋 분리
from sklearn import linear_model
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from math import sqrt
# dataset split to train/test
X = df[scale_columns]
y = df['CMEDV']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=33) # 8:2로 dataset을 나눔회귀분석 model 학습
# train regression model
from sklearn import linear_model
from sklearn.metrics import mean_squared_error
from math import scale_columns
lr = linear_model.LinearRegression()
model = lr.fit(X_train, y_train)
# print coef
print(lr.coef_) # 학습된 계수를 확인할 수 있음
# data 시각화
# figure size
plt.rcParams['figure.figsize'] = [12, 16] #rcparams를 이용한 그래프 설정 변환
# graph values
coefs = lr.coef_.tolist() #list로 변환
coefs_series = pd.Series(coefs) #pandas로 변환하기 위해 series로 변환
# graph info
x_labels = scale_columns #위에서 정의된 feature
ax = coefs_series.plot.barh() # 바 그래프
ax.set_title('feature_coef_graph')
ax.set_xlabel('coef')
ax.set_ylabel('x_features')
ax.set_yticklabels(x_labels)
plt.show()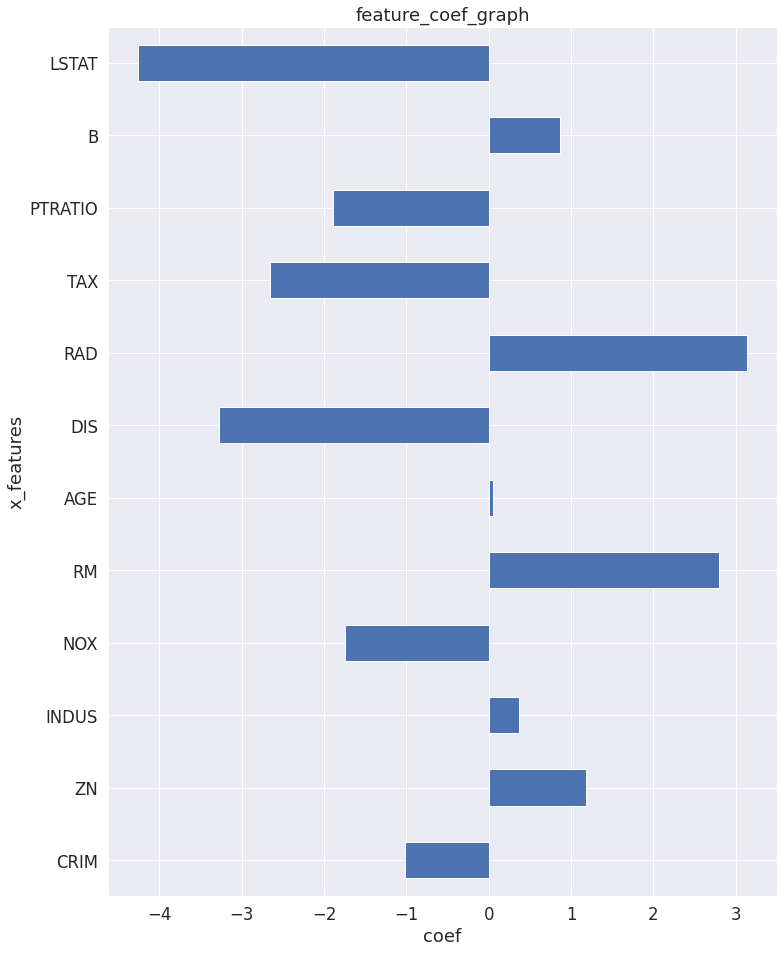
trained weight를 bar 그래프로 시각화 한것
R2 score, RMSE score 계산, 대표적인 선형회귀 모델에 대한 평가 지표
# print r2 score
print(model.score(X_train, y_train))
print(model.score(X_test, y_test))
# 1에 가까울 수록 좋음0.7423254512717083
0.7058382423177554
# print rmse
y_predictions = lr.predict(X_train)
print(sqrt(mean_squared_error(y_train, y_predictions)))
y_predictions = lr.predict(X_test)
print(sqrt(mean_squared_error(y_test, y_predictions)))4.734144294797511
4.576957797795082
feature 유의성 검정
import statsmodels.api as sm
X_train = sm.add_constant(X_train)
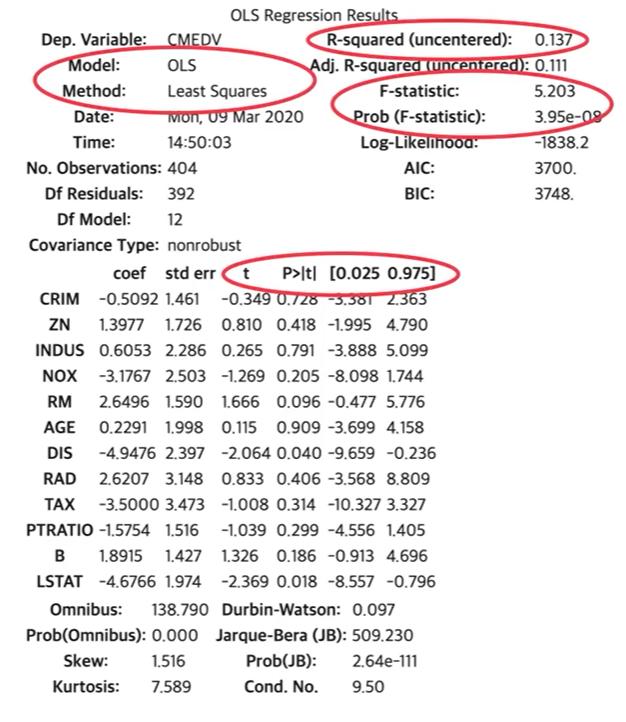
model = sm.OLS(y_train, X_train).fit()
model.summary() #summary기능을 통해 평가를 간편하게 진행 가능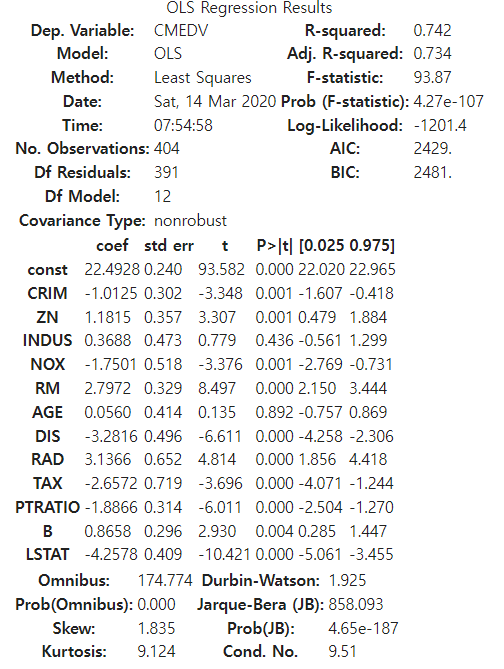
f-statistic이 0에 가까움으로 학습은 잘 되었다.
유의성의 경우 p value가 0.436인 indus, 0.892인 age가 있다. 이를 통해 CMEVD를 예측하는데는 indus와 age는 제가주는 쪽이 정확도를 올리는데 더 효과적일 것임
다중공선성
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X_train.values, i) for i in range(X_train.shape[1])]
#각 feature들을 검산하여 공선성을 확인
vif["features"] = X_train.columns
vif.round(1)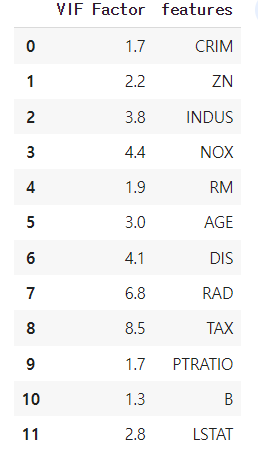
가장 높은 것은 TAX이지만 제거 기준인 10보다 낮기 때문에 심각한 공선성은 존재하지 않는다.
