1. Random Forests
1.1 Random Forests란?
다수의 기본 모델(weak-based learner)을 결정트리로 사용하는 앙상블모델
트리를 랜덤하게 여러개 만들어 종합해서 다수결이나 평균과 같은 방법으로 타겟을 예측 결과를 반환
bootstraping(=복원 추출)을 통해 여러 개의 결정트리를 사용하여 만든 앙상블 모델
집단지성, 랜덤성을 이용한 방법 → 다수결의 원칙
나 = 결정트리, 10만명 = 결정트리(기본모델)
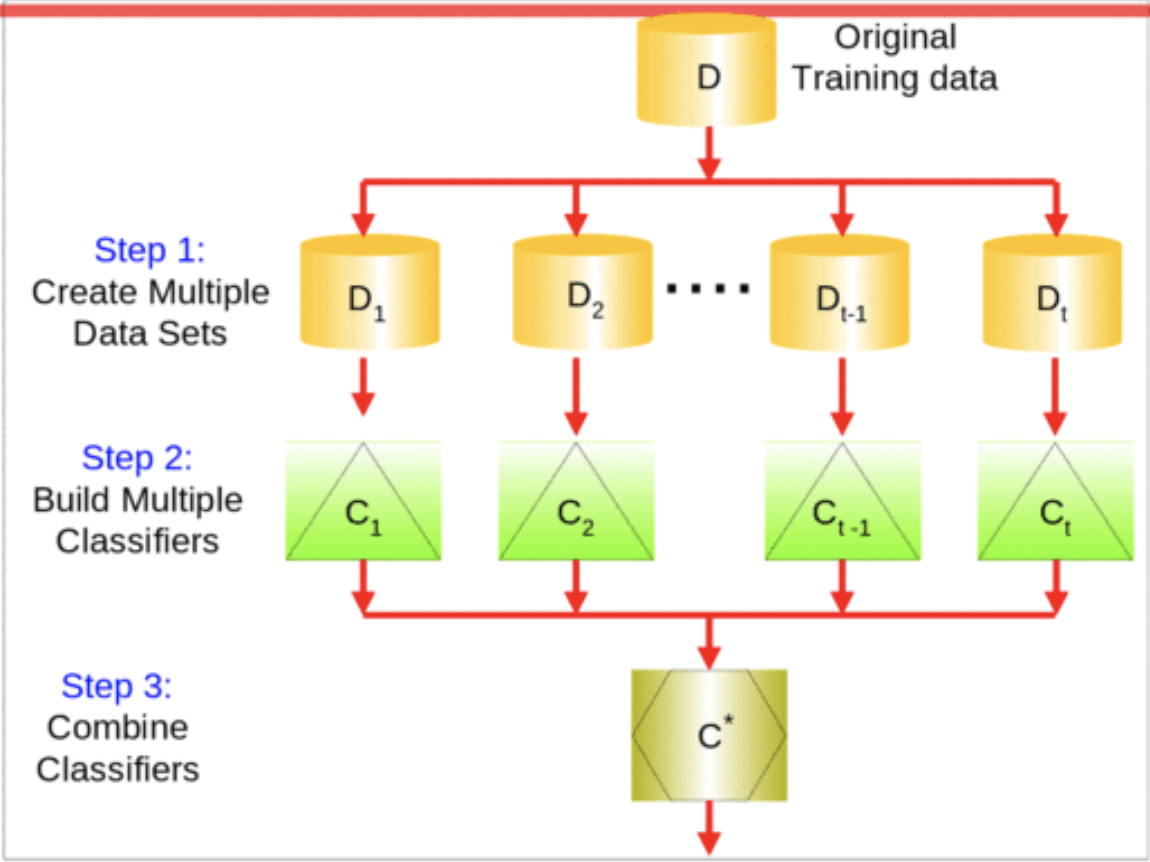
1.2 Decision Tree와의 차이
결정트리 모델은 하나의 트리만 사용하기 때문에 하나의 노드에서 오류나 에러 등이 생기면, 그 에러가 밑에 있는 하부 노드에도 여전히 영향을 끼치게 된다. 또 새로운 샘플을 분석하기에 쉽지 않다. 특성이 n개가 있는 데이터를 학습할 때에, n개를 학습을 한다.
랜덤포레스트 모델은 분석하는 Data set도 랜덤, 각 노드도 Random하게 추출 및 사용하기 때문에 결정트리 모델처럼 오류의 영향이 줄어든다. 즉, 정확도를 높일 수 있다. 또한 새로운 샘플도 쉽게 분석할 수 있다. 새로운 샘플이 들어오게 되면, 만들어 놓았던 랜덤포레스트 모델에 집어 넣어 결과를 확인해볼 수 있다. 특성이 n개가 있으면 n개 중에서 k개를 골라서 학습을 한다. (k=log2n, 밑이 2인 로그)
1.2.1 결정트리와 핵심적으로 다른 점
- 집단 지성
- 특성 무작위 선택: 특성 10개 있는 데이터 학습시
결정트리 → 특성 10개를 다 사용함
랜덤포레스트 → 특성 10개 중 k개의 특성을 뽑게 된다(k=log2n, 밑이 2인 로그)
1.3 Bootstrap
1.3.1 Bootstrap(=복원 추출)
통게학에서는 Random하게, 무작위로 샘플을 재표집하는 것을 의미한다. 추출하는 방법은 복원 추출!
샘플을 뽑더라도 다시 그 샘플을 집어놓고 새로 뽑는 것을 뜻한다.
1.3.1 기본 모델 vs 기준 모델 → 헤깔리면 안 됨.
기본 모델: 모델을 만들 때 주로 사용하는 모델. 기본모델은 앙상블 모델처럼 여러 모델을 하나로 합쳐서 새로운 모델을 만들 때 기본 재료가 되는 모델.
기준 모델: 성능을 측정하기 위한 최소한의 기준. 예측 모델의 성능을 측정하는 가장 단순하고 직관적이고, 최소한의 성능을 나타내는 기준이 되는 모델
기본모델을 여러 개 만드는 것은 알겠는데, 회귀와 분류에서는 어떻게 결과를 산출할까요?
회귀 → 평균
분류 → 다수결
1.3.2 앙상블(Ensemble)
여러 모델을 사용해서 학습하는 방법 → 여러 결과를 합치고 활용하여 평균/다수결로 결과를 반환
앙상블 모델이 결정트리 모델보다 상대적으로 과적합을 피할 수 있는 이유?
→ 결정트리는 데이터 일부에 과적합하는 경향이 있음. 그래서 다르게 샘플링 된 데이터로 과적합 된 트리를 많이 만들고 그결과를 평균내 사용하는 모델이 랜덤 포레스트. 랜덤 포레스트에서 트리를 랜덤하게 만드는 방법은 두 가지!!
1. 랜덤 포레스트에서 학습되는 트리들은 배깅을 통해 만들어 집니다(bootstrap = true). 이때 각 기본 트리에 사용되는 데이터가 랜덤으로 선택됩니다.
2. 각각 트리는 무작위로 선택된 특성들을 가지고 분기를 수행합니다(max_features = auto).
OOB로 검증할 때에는 전체 랜덤 포레스트가 아니라 자기가 나온 결정트리에만 사용이 된다.
1.3.3 배깅(BAgging)
Bagging은 Bootstrap AGGregatING의 줄임말로 분류/회귀 분석에서 사용되는 머신러닝 모델의 알고리즘 중 하나다. 랜덤포레스트 모델에 비추어 보면 Bootstrap data를 사용하고, 데이터를 분석하기 위해 결정나무 모델을 사용하는 것으로 이해할 수 있겠다. Bagging은 모델을 훈련시킬 때 분산을 줄이게 된다. 중복을 허용하여 복원 추출. 도서관의 책들처럼 사용하고 돌려 놓는 것과 같음.
여러 번 복원 추출을 했을 때, 사용하지 않은 샘플 수는? 36.8%
부트스트랩 = 복원 추출로 여러 모델을 만들죠
agg. = 그 결과를 합치는 과정
1.3.4 OOB(Out-Of-Bag)
OOB는 Bootstrapped data set을 만들 때에 새로운 데이터 셋에 포함되지 않은 데이터들을 뜻 한다.
간단히 이야기하자면, OOB는 내부적으로 훈련할 때 사용되지 않는 것들을 통해서 점수를 계산하는 방법이다.
10만개의 데이터를 받고 랜덤 포레스트가 기본모델을 100개 만들어서 결과 도출한다면?
10만 개 x 36.8% ? → 36,800 개? (X)
기준 모델 기준으로 한번 학습할 때 평균적으로 63.2%가 사용된다.
나머지가 OOB로 어떻게 val, test로 사용되는가? 사용되지 않은 모델에 대해서 테스트나 validation으로 사용된다.
OOB는 모델마다 계속 바뀐다. OOB로 검증할 때에는 전체 랜덤 포레스트가 아니라 자기가 나온 결정트리에만 사용이 된다.
pipe.named_steps['randomforestclassifier'].oob_score__
1.3.5 전체 흐름
Step1. Bootstrapped data set을 만든다(데이터의 무작위 추출).
Step2. Step1에서 만들었던 Bootstrapped data set을 활용해 결정나무 모델을 만든다. 하지만 노드에 사용하는 변수(피쳐, 특징, 컬럼 등)는 모두 랜덤하게 사용한다(변수의 무작위 추출). 그렇게 만들어진 결정나무 모델의 합이 바로 '랜덤포레스트 모델'이 된다.
Step3. OOB sample을 활용하여 만들어진 랜덤포레스트 모델을 검증(Validation) 혹은 Testing할 수 있다. 이미 답을 알고있는 훈련 모델에는 적용하지 않고, OBB sample이 훈련에 사용하지 않은 결정나무 모델에 사용된다.
1.4 순서형 인코딩(Ordinal Encoding)
1.4.1 순서형인코딩(Ordinal Encoding) vs 원핫인코딩(One_Hot_Encoding) 차이점은?
Ordinal: 열 개수는 그대로 유지(1개), 카테고리별 중요도가 설정됨
→ 카테고리 별로 중요도가 다를 때.
One_Hot: 카테고리 수에 따라 새로운 특성 생성
→ 카테고리가 많이 없고 (카테고리별)중요도가 동일할 때(명목형 데이터)
1.4.2 트리기반 모델에서는 어떤 인코딩이 좋은가? → ordinal(순서형)
트리모델은 순서를 고려하지 않음. 왜? →
특성 개수가 증가하지 않음. So? → 특성 중요도를 위해 분할하지 않아야 한다.
1.4.3 범주형 변수의 인코딩 방법이 트리모델과 선형회귀 모델에 주는 영향?
선형회귀? → One Hot Encoder 대신 ordinal을 사용하면? 카테고리별 중요도가 설정됨 → 순서가 생겨서 성능 저하!
순서가 없어야 하는 범주형에 순서가 생겨서 회귀식에 영향을 준다.
Q&A
1. 트리모델이 순서형 변수에서 순서의 영향을 받지 않는 이유는 특정 순서에 가중치를 부여하지 않기 때문이라고 이해했는데, 왜 가중치를 부여하지 않게 되는 지요?
Ordinal Encoder vs OHE
선형회귀에서 OHE → ordinal사용 시 문제: 서울 1, 부산2, 대전3, 대구4, 울산5, 광주6일 경우 서울과 부산이 합하면 대전이 되냐? 말이 안 되잖아!!
트리에서는 ordinal 사용 가능 → boolean의 형태로 결국에는 분할 된다!
즉, 분할되기 때문에 문제가 되지 않는다.
2. 랜덤포레스트에서 특성 k개를 추출하는 걸로 알고 있는데요. 영향력이 없는 특성이 포함되면 성능에 영향이 있을 것 같은데 영향력이 높은 특성을 추려 놓고 특성을 뽑아야 될까요?
특성 공학 → 특성 선택
3. 수행시간에도 큰 차이가 있나?
데이터의 크기, 특성의 수 → 복잡도를 결정
4. 타겟이 0, 1인 범주를 가질 때 분류 모델은 0을 기준으로 예측하나요, 1을 기준으로 예측하나요?(개수가 많은 것을 기준으로?)
점점 커질 수록 1에 수렴함을 알 수 있다.
5. Ordinal Encoding하는 부분을 pipeline을 통해서 하면 될까요?
pipe_ord = make_pipeline(OrdinalEncoder(), SimpleImputer(), ~~어쩌고 저쩌고~ 아무튼 가능하다.
6. n_jobs에 대한 설명?
parallel

7. Random Forest의 기본 모델은?
decision tree를 기본 모델로 사용한다.
8. 결정트리만 사용했을 때랑 비교했을 때?
장점: 상대적으로 과적합 문제를 해결
단점: 직관력을 잃는다.
9. 과적합을 완벽하게 해결할 수 있는가?
과적합을 완벽하게 해결할 수 없음. 과적합은 고질병이다.
10. 원핫인코딩과 순서형인코딩... 어떤 모델? 어떤 타입?에 사용해야 적절한가?
원핫인코딩: 명목형 & 카디널리티가 낮을 때와 순서가 없을 때
순서형인코딩: 카테고리 별로 중요도가 다를 때
*비선형모델: 트리모델은 위의 규칙에서 벗어나도 잘 학습한다.(극적인 max_depth로 중간에 끊지만 않으면...)
바이너리
타겟
11. 순서형 인코딩에서 숫자가 큰 것이 모델에 영향력이 더 크게 작용하나요?
선형회귀에서는 회귀계수의 증가에 따른 y의 변화를 보기 때문에 순서형 인코딩이 문제가 될 수 있다.
12. 실제 작업할 때 노트처럼 하나만 쓰는 게 아니라 필드 특성에 따라서 여러 인코딩을 다 섞어 쓰나요?
가능하다.
