1. Model Selection
1.1 Cross Validation
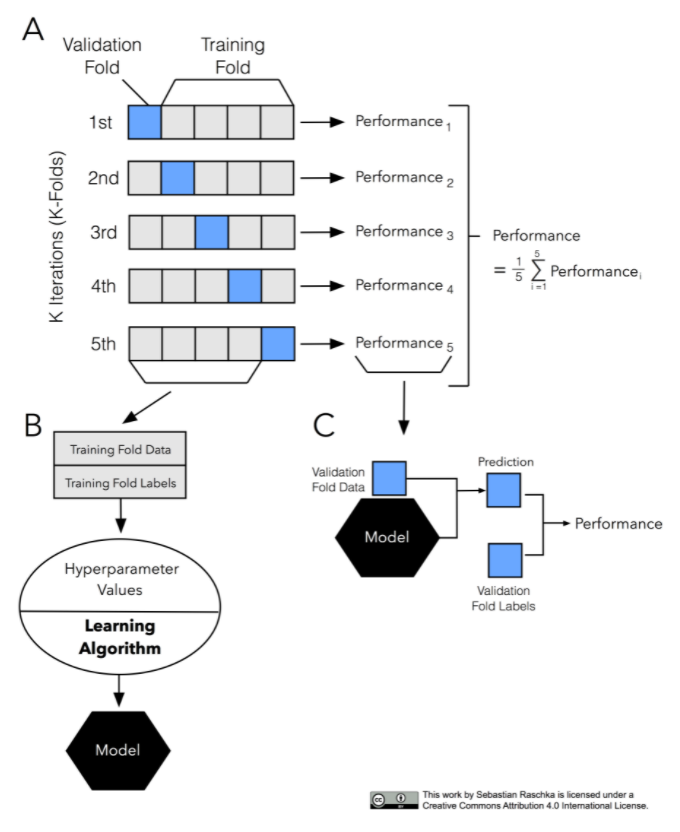
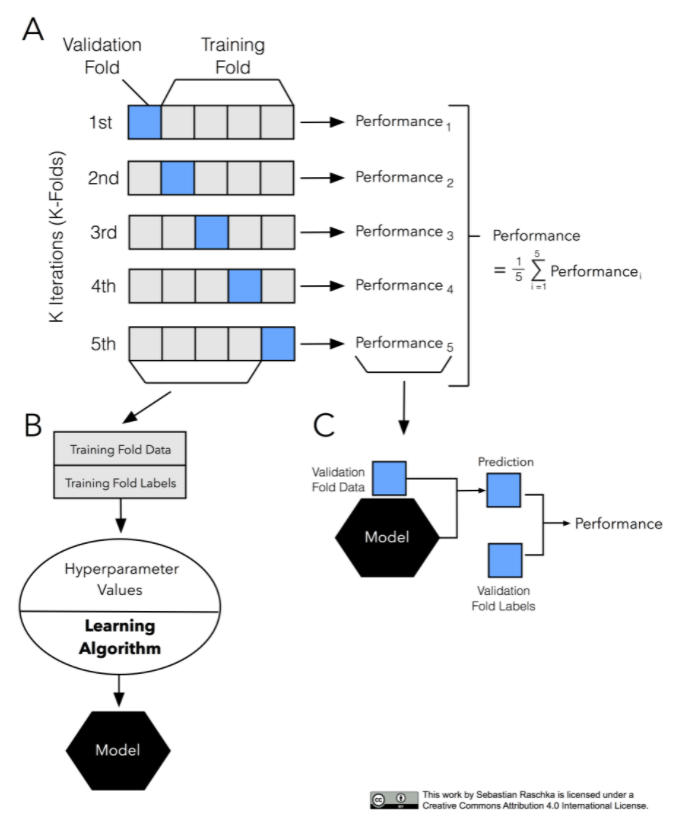
1.1.1 왜 하는가?
데이터의 크기가 작은 경우, Cross Validaion이어느 정도 해결해줄 수 있다.
서로 다른 Machine Learning 모델을 비교해주고, 얼마나 성능을 낼 수 있을지에 대해 추측해볼 수 있다.
여러 번의 검증 결과를 종합해서 일반화를 할 때의 성능을 확인할 수 있다.
- 최적화와 일반화의 차이는?(면접 단골 질문)
최적화(optimization): 파라미터(모델)와 하이퍼파라미터(연구자)를 조정해서 모델의 성능을 높이는 것. 학습할 때 하이퍼파라미터를 성능이 가장 좋은 성능을 만드는 것.
일반화(generalization): 검증 데이터나 새로운 데이터에서도 학습 데이터와 비슷한 성능과 일관된 결과를 내는 능력.
1.2 최적의 하이퍼파라미터를 구해주는 라이브러리 2가지
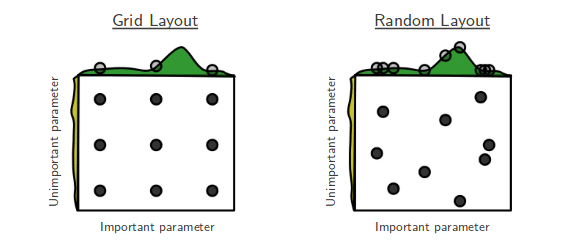
- GridSearchCV
Grid는 격자라는 뜻. 일정한 범위(격자)를 지정해주면, 범위 내의 모든 조합을 비교해서 내가 정한 Score를 기준으로 하이퍼파라미터값을 구해준다. 단, '모든' 조합을 비교하기 때문에 느리다. 대신에 정확하다. 범위를 넓게 잡으면? 당연히 오래 걸린다. - RandomizedSearchCV
이름에서도 알 수 있듯이 랜덤으로 확인해본다. Grid와 비교해보면 범위 내에서 Random하게 하이퍼파라미터의 조합을 비교해서 그 값을 추출한다. Grid에 비해 빠르고, 확률적 탐색을 진행해 어느 정도 정확하다고 볼 수 있다. 범위를 넓게 잡으면? Local Minima에 빠져서 최적의 하이퍼파라미터 값을 놓칠 수 있다.
그러면 하이퍼파라미터를 출력하면 다시 fit 시켜야하나?
그렇다. 그런데 pipe에서 수정하는 것이 아니다. 라이브러리 공식 문서를 보면 'refit'의 default=True로 되어있다. 이걸 따로 False로 바꾸지 않는 이상. 훈련한 데이터가 자동으로 재훈련된다고 볼 수 있다.
- CrossValidation(CV)와 RandomizedSearchCV의 차이?
CV는 데이터 셋의 크기가 작을 경우 이로 인해 생기는 문제를 보완해주고, 모델의 일반화를 위해 성능을 검증해보는 것으로 이해하면 좋겠다.
한편, RSCV는 이러한 CV의 개념을 활용해서 최적의 하이퍼파라미터 값을 확인해 보는 것으로 이해하면 된다!
++ Check the list of available parameters with 'estimator.get_params().keys()'
RandomizedSearchCV를 사용하다가, 지속적으로 발생한 문제였다.
sorted(pipe.get_params().keys())을 사용하면 전체 pipe에 있는 파라미터 값들을 보여준다. 이걸 그대로 Ctrl + c,v 하면 오류를 줄일 수 있다.
Q & A
- 검증데이터도 과적합일 수 있어서 교차 검증을 한다는 것인지?
→ 그렇지 않음. - 회귀 분류별 쓰이는 모델들이 있는데 어떤 모델을 선택하고, 어떻게 하이퍼파라미터를 쓸 지 너무 많은데 어떤 모델을 쓰고 어떻게 튜닝을 쓸 지 구분법이 있나요?
→ 딱히 구분법이 없다. - 과적합이라는 게 상대적인가?
→ 그렇다. 과적합은 상대적이다. - pipe를 사용해서 순차적으로 전처리나 모델셀렉션 모델링을 진행하는 것으로 알고 있는데요. pipe를 통해서 생성된 데이터프레임의 형태를 알 수 있나요?
→ pipe.namedsteps['randomforestclassifier'].oob_score - randint(1,15)... 이게 1부터 15인가요?
→ 1~15 사이의 값을 랜덤으로 반환함. - 랜덤서치, 그리드 서치 모두 똑같은 값을 내놓을 수도 있나요?
→ 가능하지만, 확률적으로 매우 희박함. - 캐글 대회에서 최적의 하이퍼파라미터 튜닝을 하고 나온 점수에서 더 높이려면 특성 공학을 더 잘 해야 하나요?
→ yes - searchcv가 cross validation일까요?
→ Cross Validation의 주 목적은 작은 데이터에서 학습시 일반화 되었는 지를 검증하는 것이다. RandomSearchCV는 하이퍼파라미터를 찾아내는 것이고, cv는 일반화 검증이면서 서로 다른 머신 러닝 모델을 비교하기 위한 것이다. 단지 CV를 활용했을 뿐이다. - simpleimputer: strategy에서 median(중앙값)은 왜 사용하는 것인가요?
→ simpleimputer의 목적은 결측치가 있을 경우에 결측치 대신에 평균이나 중앙값을 쓸 것인 지 결정하여 사용한다. - 시계열 데이터(time series)에 cv 사용 가능한가??
→ 가능하지만, 오늘 배운 내용으로는 불가능: 랜덤으로 섞기 때문에! 시계열 데이터에 적합한 cross val이 있음. - imputer를 이용해서 결측치를 대체할 때 문제가 생길 수 있기 때문에 무작정 사용하기는 어렵겠죠?(정수로만 이루어진 데이터셋에 평균으로 대체시 실수가 기입됨)
→ 답은 공식문서에 있다. 결과값을 다르게 할 수도 있다. - 만약 target이 유실되어서 10%만 남은 상태의 데이터가 주어졌을 때는 어떤 방식을 통해 해결할 수 있나요?
→ 비지도로 하거나 새로운 데이터가 주어질 때까지 기다리거나.... 답이 안 나옴. - 최적의 하이퍼 파라미터를 찾아내서 사용하면은, 개개인의 분석 차별화 요소는 피쳐엔지니어링 밖에 없을까요?(같은 데이터, 같은 하이퍼파라미터를 사용하면 똑같은 결과가 나올 거니까요.)
→ Yes. 매우 중요함. - 하이퍼 파라미터를 연구자가 조작해서 만든 특성이라고 볼 수 있나요?
→ 그렇다고 볼 수 있다. - ordinal encoding 진행할 때 순서가 고려되어 맵핑이 되어야 할 것 같은데 맵핑 우선순위를 정할 수 있나요?
→ 따로 맵핑 가능. 우선순위 여부에 대한 질문이 애매하다.

그냥 저냥 살고 있어요~