PART 1.Introduction to Reinforcement Learning

본격적인 강화학습을 배우기전 가볍게 알고가자
강화학습 - 행동에 대한 보상을 받으면서 학습하여 어떤 환경 안에서 선택 가능한 행동들 중 보상을 최대화 하는 행동 또는 행동 순서를 선택하는 방법
- Agent - 의사 결정을 수행하는 주체
- Environment - 에이전트가 학습하는 무대. 상태와 보상을 결정함으로써 다음 행동 예측하며 학습
- State - 에이전트가 환경과 상호작용할 때 어떤 상황에 있는지
- Action - 에이전트가 가능한 행동
- Reward - 에이전트가 특정 행동을 취했을 때 받는 신호
PART 2. Markov Decision Process
 상태(St)일때 상태(St+1)로 전이 될 확률
* 미래는 오로지 현재에 의해 결정
* 상태 (St)가 되기까지의 과정은 확률 계산에 영향 없음
상태(St)일때 상태(St+1)로 전이 될 확률
* 미래는 오로지 현재에 의해 결정
* 상태 (St)가 되기까지의 과정은 확률 계산에 영향 없음
Vecterization → 메모리를 효율적으로 사용하여 GPU 성능 최대화
Part 3. Monte-Carlo RL
여러 시뮬레이션 보상값에 대한 평균
- 실제 에피소드가 끝나고 받게되는 보상을 사용해서 value function 업테이트
- full sequece of state ->짧은 에피소드의 경우 유리
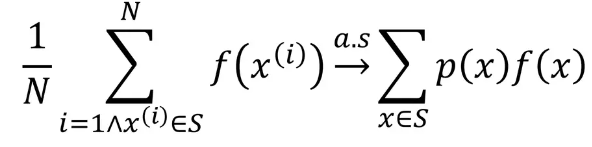
Part 4. Temporal-Difference RL
V(S.t) ⇒ expoential moving average
- 실제 보상과 다음 step에 대한 미래추정가치를 사용해서 학습
- 에피소드 중간에서도 학습
- based on only a step -> 긴 에피소드의 경우 유리
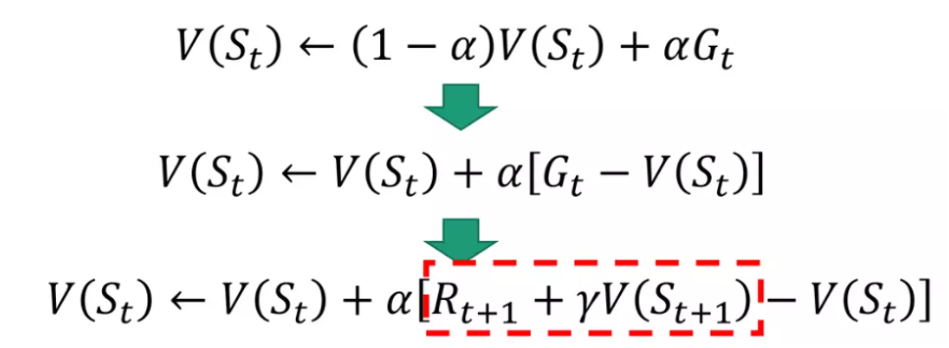
G.t = R.(t+1) + r*G.(t+1) → 재귀함수 구조
Part 5. Deep Q-Learning
기존 Q-learning + Deep learning -> memory 부족 해결 & 성능 향상
데이터 저장 형식 table -> 비선형 함수 근사로 해결
- Q-learning은 state-action (s,a)에 해당하는 Q-value인 Q(s,a)를 테이블 형식으로 저장한다. 이는 state, action space가 커지면 많은 memory, exploration time이 필요
- CNN Architecture
action을 제외한 state만 받고 action에 해당하는 여러개의 Q-value 뽑아냄
-> state 인풋에 대해 한번만 수행하면 됨 - Experience Replay
action별 수행 결과 샘플을 바로 평가에 이용하지 않고, 의도적으로 지연시킴
-> 학습 불안정성 유발하는 요인들 해결 - Target Network
이중화된 Network -> target value로 인한 학습 불안정성 개선
Lunar Lander 실습
gym 라이브러리에서 제공하는 달 착륙 게임 실습 진행
깃발 사이에 들어가는 것이 목표
필요 라이브러리 설치
!apt-get install swig3.0
!ln -s /usr/bin/swig3.0 /usr/bin/swig
!ls /usr/bin/swig
!pip3 install box2d-py
!pip3 install gym[box2d]"LunarLander-v2" 환경 생성
import gym
import matplotlib.pyplot as plt
env = gym.make("LunarLander-v2", render_mode = "rgb_array")
img = env.render()[0]
plt.imshow(img)
 >**시작전 기본 환경 확인**
>**시작전 기본 환경 확인**
파라미터 설정
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import imageio
# Configuration parameters for the whole setup
seed = 42
gamma = 0.99 # Discount factor for past rewards
epsilon = 1.0 # Epsilon greedy parameter
epsilon_min = 0.1 # Minimum epsilon greedy parameter
epsilon_max = 1.0 # Maximum epsilon greedy parameter
epsilon_interval = (epsilon_max - epsilon_min) # Rate at which to reduce chance of random action being taken
batch_size = 64 # Size of batch taken from replay buffer
max_steps_per_episode = 1000QModel -> CNN으로 구현
# Fully connected Q-network model
class QModel(nn.Module):
def __init__(self, num_inputs, num_actions):
super(QModel, self).__init__()
self.fc1 = nn.Linear(num_inputs, 150)
self.fc2 = nn.Linear(150, 120)
self.fc3 = nn.Linear(120, num_actions)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x세 개의 완전 연결(선형)층을 통하여 정보를 처리하고 ReLU 활성화 함수를 사용하여 비선형성을 추가함
# Initialize the Q-network and the target network
model = QModel(env.observation_space.shape[0], num_actions).to('cuda')
model_target = QModel(env.observation_space.shape[0], num_actions).to('cuda')
# Loss function and optimizer
loss_function = nn.SmoothL1Loss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Replay buffers
action_history = []
state_history = []
state_next_history = []
rewards_history = []
done_history = []
# Other variables
frame_count = 0
epsilon_random_frames = 50000
epsilon_greedy_frames = 100000.0
max_memory_length = 100000
update_after_actions = 4
update_target_network = 10000
def sample_batch(_batch_size):
indices = np.random.choice(range(len(done_history)), size=_batch_size)
state_sample = np.array([state_history[i] for i in indices])
state_next_sample = np.array([state_next_history[i] for i in indices])
rewards_sample = np.array([rewards_history[i] for i in indices], dtype=np.float32)
action_sample = np.array([action_history[i] for i in indices])
done_sample = np.array([done_history[i] for i in indices], dtype=np.float32)
return state_sample, state_next_sample, rewards_sample, action_sample, done_sample
def save_gif(images, filename):
with imageio.get_writer(filename, mode='I') as writer:
for image in images:
writer.append_data(image)# Function to update the Q-network
def update_network():
state_sample, state_next_sample, rewards_sample, action_sample, done_sample = sample_batch(batch_size)
state_sample = torch.tensor(state_sample, dtype=torch.float32).to('cuda')
state_next_sample = torch.tensor(state_next_sample, dtype=torch.float32).to('cuda')
action_sample = torch.tensor(action_sample, dtype=torch.int64).to('cuda')
rewards_sample = torch.tensor(rewards_sample, dtype=torch.float32).to('cuda')
done_sample = torch.tensor(done_sample, dtype=torch.float32).to('cuda')
with torch.no_grad():
future_rewards = model_target(state_next_sample).max(dim=1)[0]
target_q_values = rewards_sample + gamma * future_rewards * (1 - done_sample)
q_values = model(state_sample)
q_values_action = q_values.gather(1, action_sample.unsqueeze(-1)).squeeze(-1)
loss = loss_function(q_values_action, target_q_values)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Main training loop
for episode_num in range(100):
state = env.reset()
episode_reward = 0
images = []
for timestep in range(1, max_steps_per_episode):
frame_count += 1
epsilon = max(epsilon_min, epsilon_max - (epsilon_max - epsilon_min) * frame_count / epsilon_greedy_frames)
if np.random.rand() < epsilon:
action = env.action_space.sample()
else:
with torch.no_grad():
state_tensor = torch.tensor(state, dtype=torch.float32).to('cuda')
action = model(state_tensor.unsqueeze(0)).argmax(1).item()
next_state, reward, done, _ = env.step(action)
images.append(env.render()[0])
action_history.append(action)
state_history.append(state)
state_next_history.append(next_state)
rewards_history.append(reward)
done_history.append(done)
state = next_state
episode_reward += reward
if frame_count % update_after_actions == 0 and len(done_history) > batch_size:
update_network()
if frame_count % update_target_network == 0:
model_target.load_state_dict(model.state_dict())
if done:
break
if episode_num % 10 == 0:
print(f"Episode {episode_num}: total reward -> {episode_reward}")
save_gif(images, f'lunar_lander_episode_{episode_num}.gif')
에피소드별로 GIF를 저장하도록 함
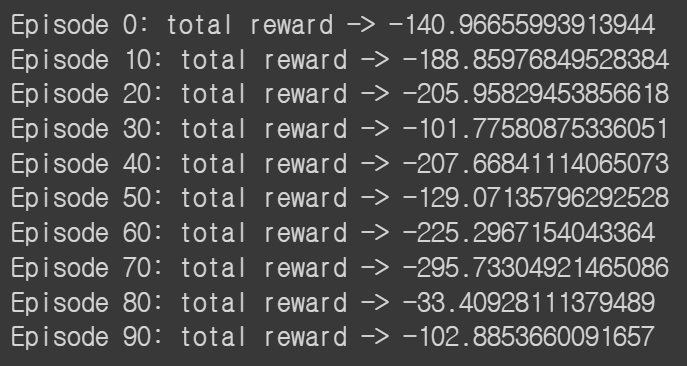
에피소드 80번째 일때 수행능력이 가장 좋았음