📌 Dynamically optimizing skew joins
Dynamically optimizing skew joins란
-
왜 필요한가?
- Skew 파티션으로 인한 성능 문제를 해결하기 위해서 필요하다.
- 한 두개의 오래 걸리는 Task들로 인한 전체 Job/Stage 종료 지연
- 이 때 disk spill이 발생한다면 더 느려지게 된다.
- Skew 파티션으로 인한 성능 문제를 해결하기 위해서 필요하다.
-
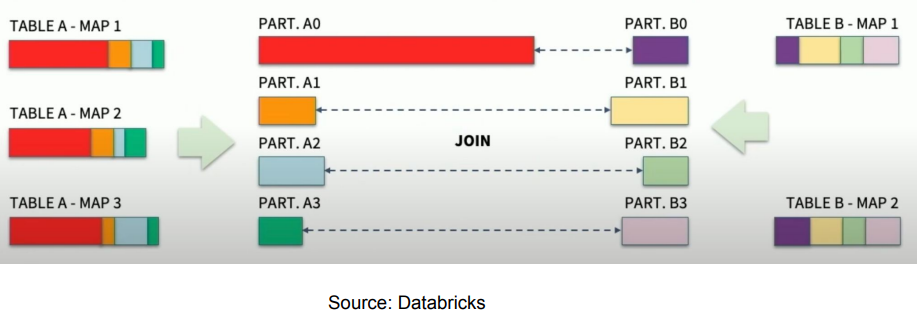
AQE의 해법
- 먼저 skew 파티션의 존재 여부를 파악한다.
- 다음으로 skew 파티션을 작게 나눈다.
- 다음으로 상대 조인 파티션을 중복하여 만들고 조인을 수행한다.
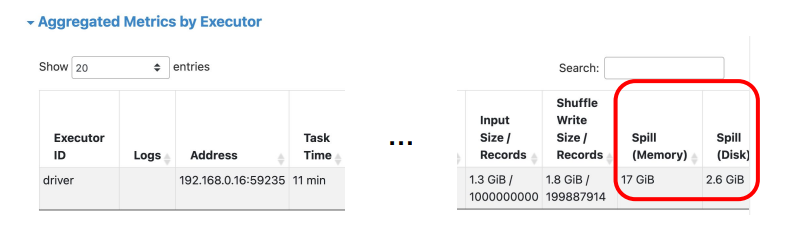
Dynamically optimizing skew joins 동작방식
- Leaf stage 실행
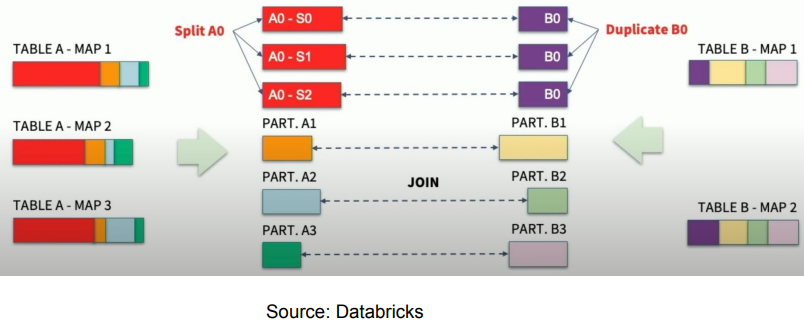
- 한쪽에 skew partition이 보이는 경우 skew reader를 통해 작은 다수의 파티션으로 재구성
- 조인 대상이 되는 반대편 파티션은 앞서 다수의 부분 파티션쪽으로 중복해서 파티션을 생성
spark.sql.adaptive.skewJoin.skewedPartitionFactor
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes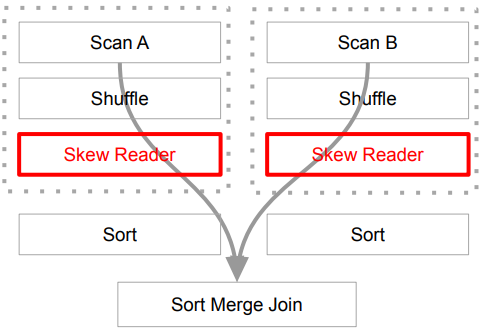
Dynamically optimizing skew joins 그림표현
Dynamically optimizing skew joins 환경변수(Spark 3.3.1)
| 환경 변수 이름 | 기본 값 | 설명 |
|---|---|---|
| spark.sql.adaptive.skewJoin.enabled | True | 이 값과 spark.sql.adpative.enabled가 true인 경우 Sort Merge Join 수행시 skew된 파티션들을 먼저 크기를 줄이고 난 다음에 조인을 수행한다. |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 5 | 파티션의 크기가 중간 파티션 크기보다 5배 이상 크고 spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes의 값보다 크면 skew 파티션으로 간주한다. |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes | 256MB | 파티션의 크기가 이 값보다 크고 중간 파티션 크기보다 5배이상 크면 skew파티션으로 간주한다. 이 값은 spark.sql.adaptive.advisoryPartitionSizeInBytes보다 커야한다. |
Demo
CREATE TABLE items
USING parquet
AS
SELECT id,
CAST(rand()* 1000 AS INT) AS price
FROM RANGE(30000000);
CREATE TABLE sales
USING parquet
AS
SELECT CASE WHEN rand() < 0.8 THEN 100 ELSE CAST(rand()* 30000000 AS INT) END AS item_id,
CAST(rand()* 100 AS INT) AS quantity,
DATE_ADD(current_date(), - CAST(rand()* 360 AS INT)) AS date
FROM RANGE(1000000000);- Coalescing
pyspark --driver-memory 2g --executor-memory 2g
SELECT date, sum(quantity) AS q
FROM sales
GROUP BY 1
ORDER BY 2 DESC;- JOIN Strategies
pyspark --driver-memory 2g --executor-memory 2g
SELECT date, sum(quantity * price) AS total_sales
FROM sales s
JOIN items i ON s.item_id = i.id
WHERE price < 10
GROUP BY 1
ORDER BY 2 DESC;- SKEW JOIN optimization
pyspark --driver-memory 4g --executor-memory 8g
SELECT date, sum(quantity * price) AS total_sales
FROM sales s
JOIN items i ON s.item_id = i.id
GROUP BY 1
ORDER BY 2 DESC;📌 Salting을 통한 Data Skew 처리
파티션 관련 환경 설정 변수들 (3.3.1 기준) - 참고
| 환경 변수 이름 | 기본값 | 설명 |
|---|---|---|
| spark.sql.adaptive.enalbed | True | Spark 3.2부터 기본으로 적용되기 시작했다.(도입은 1.6) |
| spark.sql.shuffle.partitions | 200 | Shuffle 후 만들어질 파티션의 기본 수 |
| spark.sql.files.maxPartitionBytes | 128MB | 파일 기반 데이터 소스(Parquet, JSON, ORC 등등)에서 데이터프레임을 만들 때 한 파티션의 최대 크기 |
| spark.sql.files.openCostInBytes | 4MB | 이 역시 파일 기반 데이터소스에서만 의미가 있으며 입력 데이터를 읽기 위해 몇 개의 파티션을 사용할지 결정하는데 사용된다. 대부분의 경우 별 의미 없는 변수이지만 기본적으로 코어별 입력 데이터 크기를 계산헀을 때 이 변수의 값보다 작은 경우 파티션의 크기는 이 크기로 맞춰서 만들어진다. 자세한 설명 |
| spark.sql.files.minPartitionNum | Default parallelism | 이 역시 파일 기반 데이터소스에서만 의미가 있으며 보장되지는 않지만 파일을 읽어들일 때 최소 몇 개의 파티션을 사용할지 결정하는 변수이다. 설정되어 있지 않다면 기본값은 spark.default.parallelism과 동일하다. |
| spark.default.parallelism | RDD를 직접 조작하는 경우 의미가 있는 변수로 shuffling 후 파티션의 수를 결정한다. 간단하게 클러스터 내 총 코어의 수 라고 할 수 있다. |
spark.sql.shuffle.partitions
- 클러스터 자원과 처리 데이터의 크기를 고려해서 Job마다 바꿔서 설정한다.
- 큰 데이터를 처리하는 거라면 클러스터 전체 코어의 수로 설정한다.
- AQE를 사용하는 관점에서는 조금더 크게 잡는 것이 좋다.
Salting이란?
- Salting이란 Skew Partition을 처리하기 위한 테크닉이다.
- AQE의 등장으로 인해 그렇게 많이 쓰이지는 않는다.
-> 단 AQE만으로 Skew partition 이슈가 사라지지 않는다면 사용이 필요할 수도 있다.
- AQE의 등장으로 인해 그렇게 많이 쓰이지는 않는다.
- 랜덤 필드를 만들고 그 기준으로 파티션을 새로 만들어서 처리한다.
- Aggregation 처리의 경우에는 효과적일 수 있다.
- Join의 경우에는 그리 효과적이지 않다
- AQE에 의존하는 것이 좋다.
- 사실상 Join시 사용 Salting 테크닉을 일반화한 것이 AQE의 skew Join처리방식이다.
Salting을 Aggregation에 사용한 예시
SELECT item_id, COUNT(1)
FROM sales
GROUP BY 1
ORDER BY 2 DESC
LIMIT 100;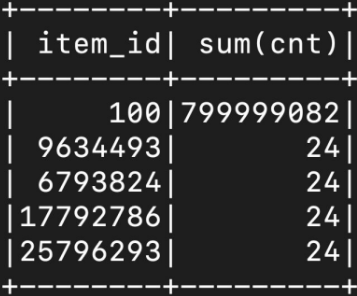
SELECT item_id, SUM(cnt)
FROM(
SELECT item_id, salt, COUNT(1) cnt
FROM (
SELECT FLOOR(RAND()* 200) salt, item_id
FROM sales
)
GROUP BY 1, 2
)
GROUP BY 1
ORDER BY 2 DESC
LIMIT 100;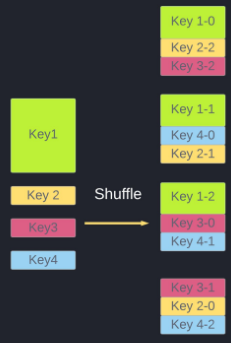
Salting을 Skew Join에 사용한 예시
SELECT date, sum(quantity*price) AS total_sales
FROM sales s
JOIN items i ON s.item_id = i.id
GROUP BY 1
ORDER BY 2 DESC;- Skew Partition이 있는 쪽에 salt추가
- 반대 Partition에 중복 레코드 만들기
- Join 조건에 salt 추가하기
SELECT date, sum(quantity*price) AS total_sales
FROM (
SELECT *, FLOOR(RAND()* 20) AS salt
FROM sales
) s
JOIN(
SELECT *, EXPLODE(ARRAY(0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19) AS salt
FROM items
) i ON s.item_id = i.id and s.salt = i.salt
GROUP BY 1
ORDER BY 2 DESC;SELECT date, sum(quantity * price) AS total_sales
FROM (
SELECT *, CASE WHEN item_id = 100 THEN FLOOR(RAND()*20) ELSE 1 END AS salt
FROM sales
) s
JOIN (
SELECT *, EXPLODE(ARRAY(0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19)) AS salt
FROM items
WHERE id = 100
UNION
SELECT *, 1 AS salt
FROM items
WHERE id <> 100
) i ON s.item_id = i.id and s.salt = i.salt
GROUP BY 1
ORDER BY 2 DESCSpill이란?
-
파티션의 크기가 너무 커서 메모리가 부족한 경우 그 여분을 디스크에 쓰는 것이다.
- Spill이 발생하면 실행시간이 늘어나고 OOM이 발생할 가능성이 올라간다.
-
Spill이 발생하는 경우 -> 메모리가 부족해지는 경우
- Skew Partition 대상 Aggregation
- Skew Partition 대상 Join
- 굉장히 큰 explode 작업
- 큰 파티션(spark.sql.files.maxPartitionBytes)이라면 위의 작업시 Spill가능성이 더 높아진다
Spill의 종류
-
Spill(memory)
- 디스크로 Spill된 데이터가 메모리에 있을 때의 크기
- Deserialized 형태라서 크기가 보통 8~10배 정도 더 크다.
-
Spill(disk)
- 메모리에서 spill된 데이터가 디스크에서 차지하는 크기
- Serialized 형태라서 보통 크기가 훨씬 더 작다
-
결국 Spill(memory)와 Spill(disk)는 같은 데이터를 가리키는데 하나는 메모리에 있을 때의 크기이고 다른 하나는 디스크에 있을 때의 크기이다
-
보통 오래 걸리는 Task들은 Spill이 있다.