📌 빅데이터에서의 SQL
- 데이터 분야에서 일하고자 하면 반드시 익혀야할 기본 기술
- 구조화된 데이터를 다루는 한 SQL은 데이터 규모와 상관없이 사용한다.
- 모든 대용량 데이터 웨어하우스는 SQL기반이다.
- Redshift, Snowflake, BigQuery
- Hive, Presto
- Spark도 예외는 아니다.
-> Spark SQL이 지원된다.
📌 Spark SQL
-
구조화된 데이터 처리를 위한 Spark 모듈
-
데이터 프레임 작업을 SQL로 처리 가능하다.
-
데이터 프레임에 테이블 이름을 지정한 후 SQL함수를 사용할 수 있다.
-> Pandas에도 pandassql 모듈의 sqldf 함수를 이용하는 동일한 패턴이 존재한다. -
HQL(Hive Query Language)과 호환을 제공한다.
-> Hive 테이블들을 읽고 쓸 수 있다.(Hive Metastore)
-
📌 Spark SQL vs. DataFrame
- SQL로 가능한 작업이라면 DataFrame을 사용할 이유가 없다.
- 두 개를 동시에 사용할 수 있다는 점을 기억해야 한다.
-
Familiarity & Readability
-> SQL이 가독성이 더 좋고 더 많은 사람들이 사용가능하다. -
Optimization
-> Spark SQL 엔진이 최적화하기 더 좋다.(SQL은 Declarative)
->Catalyst Optimizer & Project Tungsten -
Interoperability & Data Management
-> SQL이 포팅도 쉽고 접근권한 체크도 쉽다.
📌 Spark SQl 사용법
- 데이터 프레임을 기반으로 테이블 뷰 생성 : Create Table
- createOrReplaceTempView : Spark Session이 살아있는 동안 존재
- createOrReplaceGlobalTempView : Spark 드라이버가 살아있는 동안 존재
- Spark Session의 sql함수로 SQL 결과를 DataFrame으로 받는다.
namegender_df.createOrReplaceTempView("namegender")
namegender_group_df = spark.sql("""
SELECT gender, count(1) FROM namegender GROUP BY 1
""")
print(namegender_group_df.collect())📌 SparkSession 사용 외부 DB연결
- Spark Session의 read함수를 호출(로그인 관련 정보와 읽어오고자 하는 테이블 혹은 SQL을 지정)
-> 결과가 DataFrame으로 반환된다.
df_user_session_channel = sprak.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", "jdbc:redshift://HOST:PORT/DB?user=ID&password=PASSWORD") \
.option("dbtable", "raw_data.user_session_channel") \
.load()📌 Aggregation Function
- DataFrame이 아닌 SQL로 작성하는 것을 추천한다.
- Group By
- Window
- Rank
📌 Join
-
SQL 조인은 두 개 혹은 그 이상의 테이블들을 공통 필드를 가지고 Merge
-
스타 스키마로 구성된 테이블들로 분산되어 있던 정보를 통합하는데 사용한다.
-
왼쪽 테이블을 LEFT라고 하고 오른쪽 테이블을 RIGHT라고 한다면?
- Join의 결과는 방식에 따라 양쪽의 필드를 모두 가진 새로운 테이블을 생성
- Join의 방식에 따라 다음 두 가지가 달라진다.
- 어떤 레코드들이 선택되는가?
- 어떤 필드들이 채워지는가?
-
다양한 종류의 Join - 참고
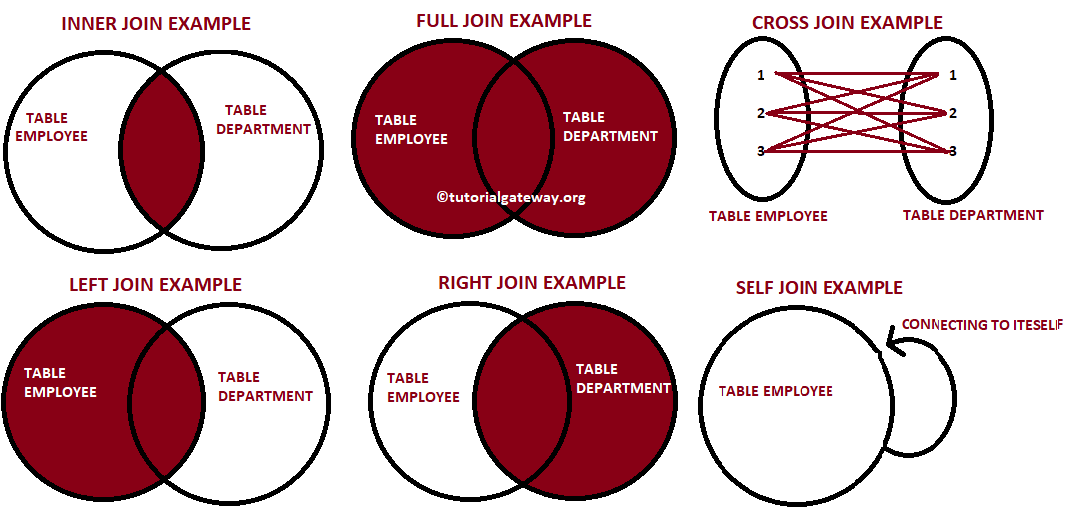
Join 실습
- Vital
| UserID | VitalID | Date | Weight |
|---|---|---|---|
| 100 | 1 | 2020-01-01 | 75 |
| 100 | 3 | 2020-01-02 | 78 |
| 101 | 2 | 2020-01-01 | 90 |
| 101 | 4 | 2020-01-02 | 95 |
- Alert
| AlertID | VitalID | AlertType | Date | UserID |
|---|---|---|---|---|
| 1 | 4 | WeightIncrease | 2020-01-02 | 101 |
| 2 | NULL | WissingVital | 2020-01-04 | 100 |
| 3 | NULL | WissingVital | 2020-01-04 | 101 |
INNER JOIN
-
양쪽 테이블에서 매치가 되는 레코드들만 반환한다.
-
양쪽 테이블의 필드가 모두 채워진 상태로 반환된다.
SELECT * FROM Vital v
JOIN Alert a ON v.vitalID = a.vitalID;| v.UserID | v.VitalID | v.Date | v.Weight | a.AlertID | a.VitalID | a.AlertType | a.Date | a.UserID |
|---|---|---|---|---|---|---|---|---|
| 101 | 4 | 2020-01-02 | 95 | 1 | 4 | WeightIncrease | 2021-01-02 | 101 |
LEFT JOIN
-
왼쪽 테이블(Base)의 모든 레코드들을 반환한다.
-
오른쪽 테이블의 필드는 왼쪽 레코드와 매칭되는 경우에만 채워진 상태로 반환된다.
SELECT * FROM raw_data.Vital v
LEFT JOIN raw_data.Alert a ON v.vitalID = a.vitalID;| v.UserID | v.VitalID | v.Date | v.Weight | a.AlertID | a.VitalID | a.AlertType | a.Date | a.UserID |
|---|---|---|---|---|---|---|---|---|
| 100 | 1 | 2020-01-01 | 75 | NULL | NULL | NULL | NULL | NULL |
| 100 | 3 | 2020-01-02 | 78 | NULL | NULL | NULL | NULL | NULL |
| 101 | 2 | 2020-01-01 | 90 | NULL | NULL | NULL | NULL | NULL |
| 101 | 4 | 2020-01-02 | 95 | 1 | 4 | WeightIncrease | 2021-01-02 | 101 |
FULL JOIN
-
왼쪽 테이블과 오른쪽 테이블의 모든 레코드들을 반환한다.
-
매칭 되는 경우에만 양쪽 테이블들의 모든 필드들이 채워진 상태로 반환된다.
SELECT * FROM raw_data.Vital v
FULL JOIN raw_data.Alert a ON v.vitalID = a.vitalID;| v.UserID | v.VitalID | v.Date | v.Weight | a.AlertID | a.VitalID | a.AlertType | a.Date | a.UserID |
|---|---|---|---|---|---|---|---|---|
| 100 | 1 | 2020-01-01 | 75 | NULL | NULL | NULL | NULL | NULL |
| 100 | 3 | 2020-01-02 | 78 | NULL | NULL | NULL | NULL | NULL |
| 101 | 2 | 2020-01-01 | 90 | NULL | NULL | NULL | NULL | NULL |
| 101 | 4 | 2020-01-02 | 95 | 1 | 4 | WeightIncrease | 2021-01-02 | 101 |
| NULL | NULL | NULL | NULL | 2 | NULL | MissingVital | 2020-01-04 | 100 |
| NULL | NULL | NULL | NULL | 3 | NULL | MissingVital | 2020-01-04 | 101 |
CROSS JOIN
- 왼쪽 테이블과 오른쪽 테이블의 모든 레코드들의 조합을 반환한다.
SELECT * FROM raw_data.Vital v CROSS JOIN raw_data.Alert a;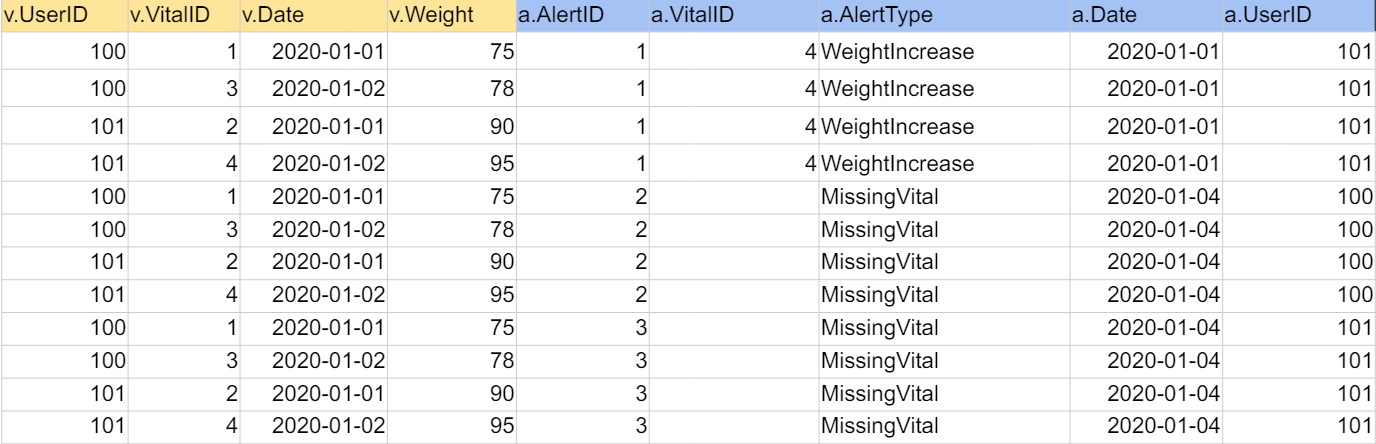
SELF JOIN
- 동일한 테이블을 alias를 달리해서 자기 자신과 조인한다.
SELECT * FROM raw_data.Vital v1
JOIN raw_data.Vital v2 ON v1.vitalID = v2.vitalID;| v1.UserID | v1.VitalID | v1.Date | v1.Weight | v2.UserID | v2.VitalID | v2.Date | v2.Weight |
|---|---|---|---|---|---|---|---|
| 100 | 1 | 2020-01-01 | 75 | 100 | 1 | 2020-01-01 | 75 |
| 100 | 3 | 2020-01-02 | 78 | 100 | 3 | 2020-01-02 | 78 |
| 101 | 2 | 2020-01-01 | 90 | 101 | 2 | 2020-01-01 | 90 |
| 101 | 4 | 2020-01-02 | 95 | 101 | 4 | 2020-01-02 | 95 |
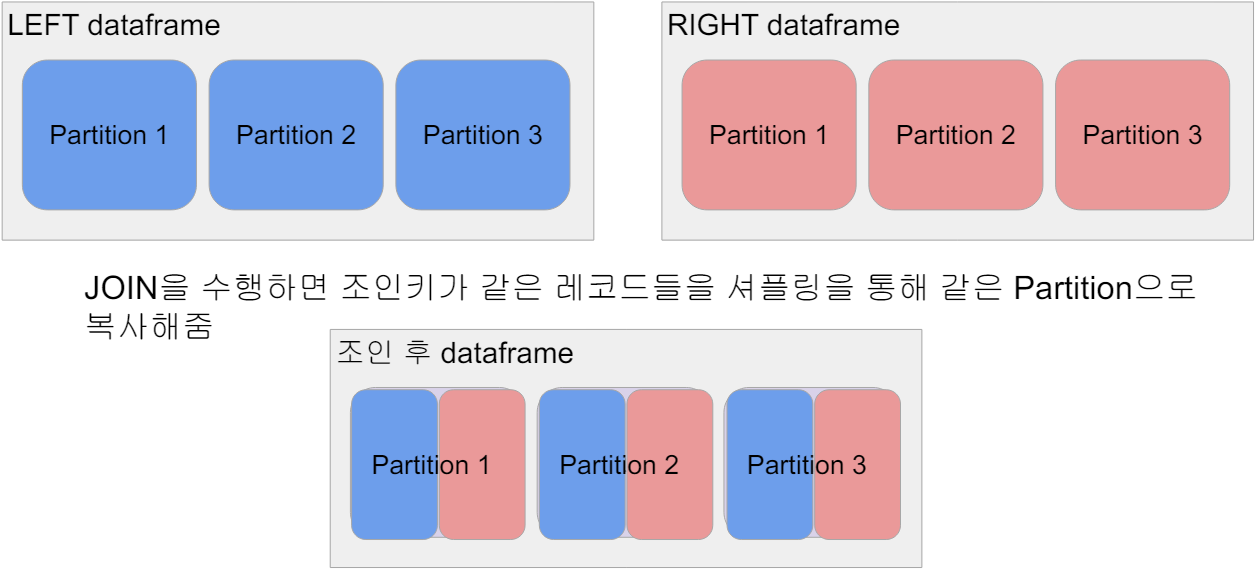
최적화 관점에서 본 조인
-
Shuffle Join
- 일반 조인 방식
- Bucket JOIN: 조인 키를 바탕으로 새로 파티션을 만들고 조인을 하는 방식
-
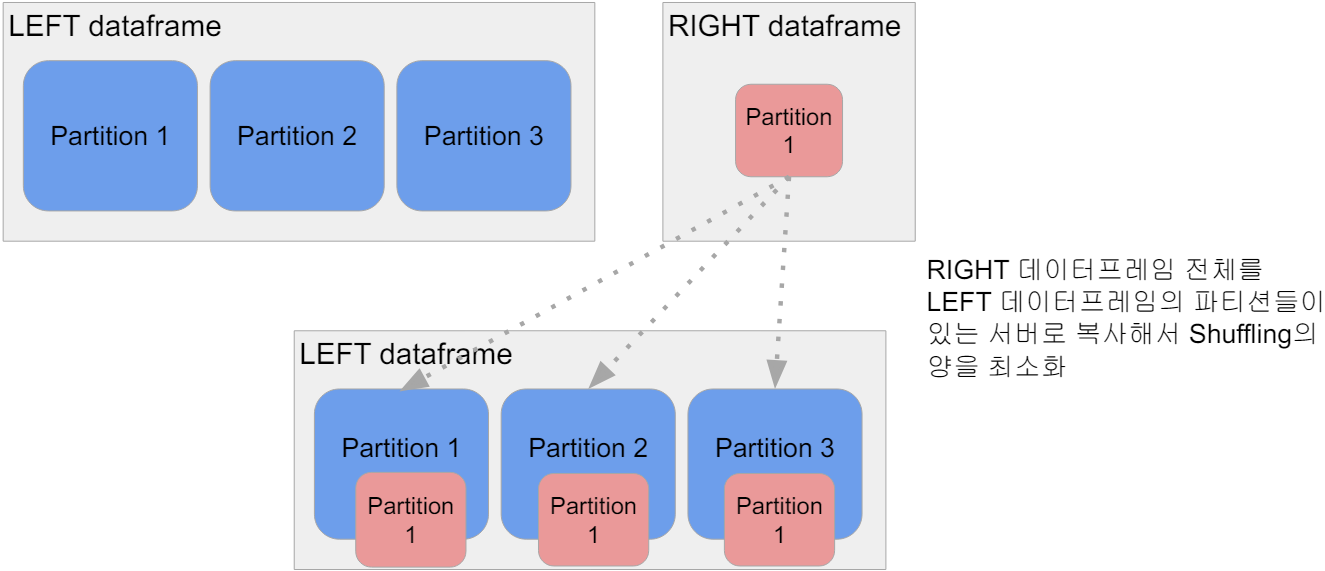
Broadcast Join
- 큰 데이터와 작은 데이터 간의 조인
- 데이터 프레임 하나가 충분히 작으면 작은 데이터 프레임을 다른 데이터프레임이 있는 서버들로 뿌리는 것이다.(broadcasting)
-> spark.sql.autoBroadcastJoinThreshold 파라미터로 충분히 작은지 여부를 결정한다.
JOIN
Broadcast JOIN
📌 UDF
- User Defined Function의 약자
- DataFrame이나 SQL에서 적용할 수 있는 사용자 정의 함수
- Scalar 함수 vs. Aggregation 함수
- Scalar 함수 예시 : UPPER, LOWER, ...
- Aggregation 함수(UDAF) 예시 : SUM, MIN, MAX
UDF 사용 방법(1)
- 함수 구현
- Python 함수
- Python Lambda 함수
- Python Pandas 함수
- pyspark.sql.functions.pandas_udf로 annotation
- Apache Arrow를 사용하여 Python객체를 Java객체로 변환하는 것이 훨씬 더 효율적이다.
UDF 사용 방법(2)
-
함수 등록
- pyspark.sql.functions.udf
-> DataFrame에서만 사용 가능하다. - spark.udf.register
->SQL 모두에서 사용 가능하다.
- pyspark.sql.functions.udf
-
함수 사용
- .withColumn, .agg
- SQL
-
성능이 중요하다면?
- Scala & Java로 구현하는 것이 좋다.
- Python을 사용해야 한다면 Pandas UDF로 구현해야한다.
UDF - DataFrame에 사용(1)
import pyspark.sql.functions as F
from pyspark.sql.types import *
upperUDF = F.udf(lambda z:z.upper())
df.withColumn("Curated Name", upperUDF("Name"))
def upper(s):
return s.upper()
# Test
upperUDF = spark.udf.register("upper", upper)
spark.sql("SELECT upper('aBcD')").show()
# DataFrame 기반 SQL에 적용
df.createOrReplaceTempView("test")
spark.sql("""SELECT name, upper(name) "Curated Name" FROM test""").show()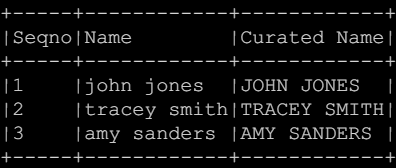
UDF - DataFrame에 사용(2)
data = [
{"a":1,"b":2},
{"a":5,"b":5}
]
df = spark.createDataFrame(data)
df.withColumn("c"F.udf(lambda x, y: x + y)("a", "b"))
def plus(x, y):
return x + y
plusUDF = spark.udf.register("plus", plus)
spark.sql("SELECT plus(1, 2)").show()
df.createOrReplaceTempView("test")
spark.sql("SELECT a, b, plus(a, b) c FROM test").show()
UDF - Pandas UDF Scalar Function
from pyspark.sql.functions import pandas_udf
import pandas as pd
@pandas_udf(StringType())
def upper_udf2(s: pd.Series) -> pd.Series:
return s.str.upper()
upperUDF = spark.udf.register("upper_udf", upper_udf2)
df.select("Name", upperUDF("Name")).show()
spark.sql("""SELECT name, upper_udf(name) `Curated Name` FROM test""").show()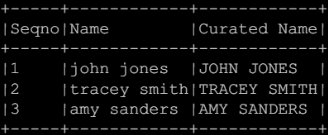
UDF - DataFrame/SQL에 Aggregation 사용
from pyspark.sql.functions import pandas_udf
import pandas as pd
@pandas_udf(FloatType())
def average(v: pd.Series) -> float:
return v.mean()
averageUDF = spark.udf.register('average', average)
spark.sql('SELECT average(b) FROM test').show()
df.agg(averageUDF("b").alias("count")).show()