DataBase - MySQL
Database
컴퓨터로 데이터관리의 필요성이 대두되었다.
처음 데이터관리의 해결책으로 나온 것이 File 이다.
File은 사용이 쉽고, 전송이 빠르다는 장점이 있어, 현재도 사용되고 있고, 미래에도 사용될 것이다.
하지만 File은 구조화된 데이터가 아니어서 데이터가 폭발적인 현대사회에서 데이터를 다루기에는 한계가 있다.
그래서 나온 해결책이 데이터를 구조화해서 저장하는 Database이다.
데이터베이스를 통해 우리는 데이터를 구조화된 틀에서 데이터에 쉽게 접근하며, 데이터의 가공이 가능하게 되았다.
우리가 사용하고자 하는 데이터베이스의 제품은 MySQL이다.
MySQL은 무료이고, 오픈소스이며, 관계형데이터베이스를 기반으로 한 데이터베이스 제품이다.
Database의 목적
스프레드시트 vs 데이터베이스
스프레드시트와 데이터베이스의 공통점은 데이터를 표 형태로 구조화해서 사용한다는 점이다.
차이점이라면 스프레드시트가 데이터의 조작을 원하는 경우는 클릭을 해서, 데이터를 가공한다면,
데이터베이스는 컴퓨터언어(SQL)를 통해서 데이터를 조작 할 수 있다.
이렇게 저장된 데이터는 웹, 앱등에서 공유가 가능하며, 빅데이터나 인공지능으로 데이터분석을 할 수도 있다.
현재 우리가 사용하고 있는 웹페이지들도 데이터베이스와 연동되어서 필요한 데이터를 자동으로 불러오거나 저장을 해서 화면에 랜더링을 해주는 것이다.
MySQL 설치
설치완료 후 작업
-
환경설정
MySQL 시작하기 -
터미널 조작
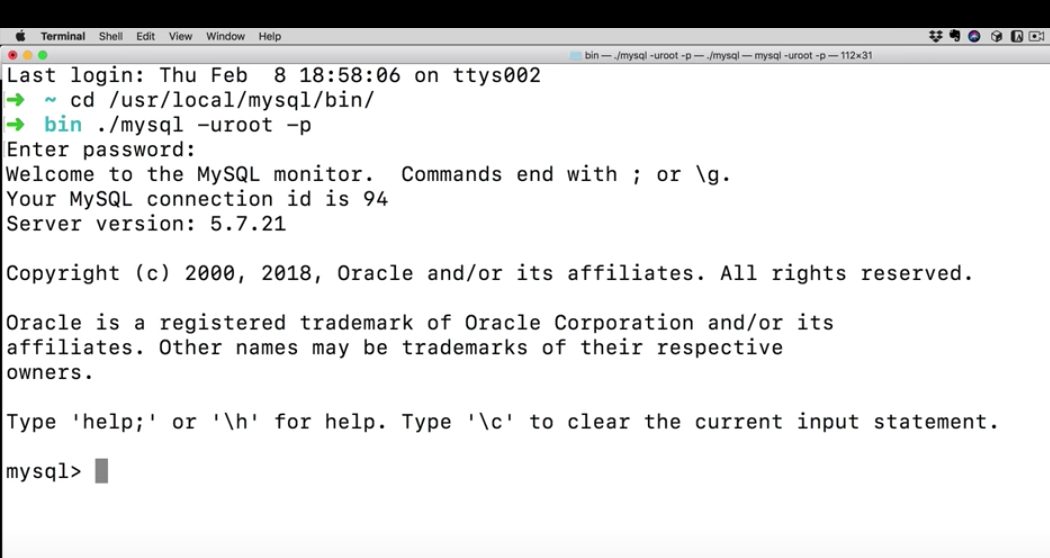
MySQL이 설치된 폴더로 이동해서 mysql -uroot -p를 이용해서 MySQL Server에 접속한다.
MySQL의 구조
MySQL의 전체적인 구조에 대해서 알아보자.
-
Table
Table은 데이터를 저장하는 표이다. -
Database,Schema
Table이 많아지면 연관된 Table를 그룹핑한다. 그룹핑은 폴더와 같다. -
Database Server
Database,Schema가 많아지면 이를 Database server에 저장한다.
MySQL을 설치했다는 것은 Database Server라는 프로그램을 설치했다는 것과 같다.
이 프로그램이 가진 기능으로 작업을 한다.
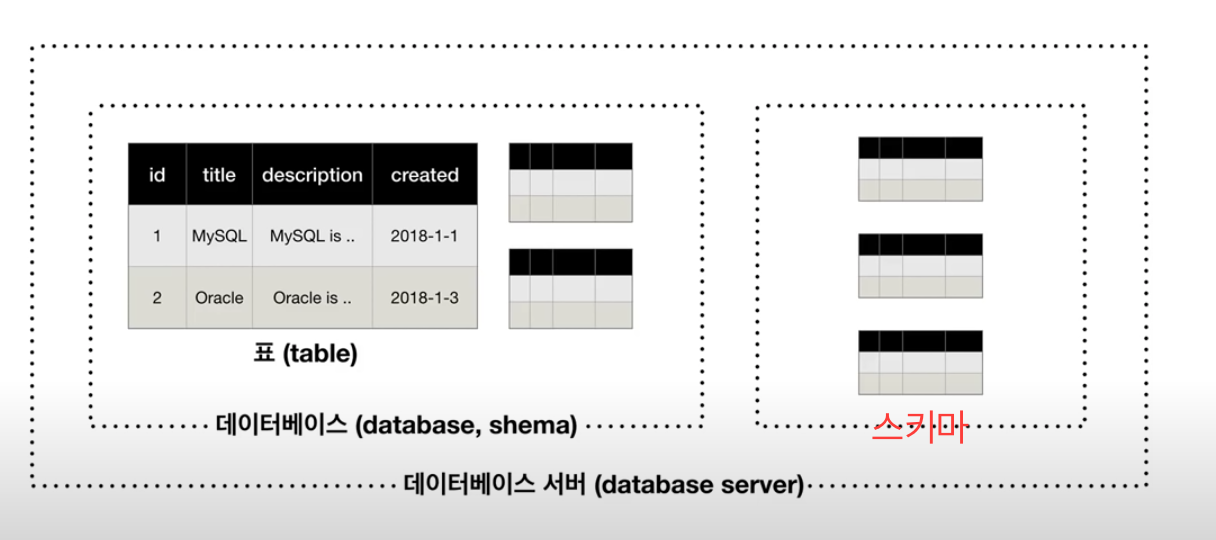
Database 서버접속
데이터베이스의 효용
-
보안
File의 경우 운영체제가 뚫리면, File의 탈취가 바로 가능하다.
하지만 데이터베이스는 자체적인 보안체계를 가지고 있어서 안전하다. -
권한
권한기능을 이용해서 사용자에 따라 데이터베이스의 사용에 제한을 설정 할 수 있다.
Database,Schema 만들기
-
CREATE DATABASE 데이터베이스이름(스키마이름);
새로운 스키마 생성 -
DROP DATABASE 데이터베이스이름(스키마이름);
생성된 스키마 삭제
-
SHOW DATABASES;
생성된데이터베이스들 보기, 현재 존재하는 스키마들 출력
-
USE 데이터베이스이름(스키마이름);
작업하고자 하는 스키마로 이동
스키마 안에 테이블을 생성하기 위해서 이동해야 한다.
SQL과 테이블의 구조
SQL
SQL은 관계형데이터베이스 모델을 참조하는 데이터베이스 제품에서 많이 사용되는 컴퓨터 언어이다.
Structured Query Language 줄여서 SQL이라는 언어는 구조화된 질의 언어라고 한다.
데이터베이스 서버를 제어할 때 사용하는 언어로 중요하다.
Table
Table의 구조는 Row(행) 와 Column(열) 으로 이루어져 있다.
Row는 데이터 하나하나를 의미하고, Column은 데이터의 구조를 의미한다.
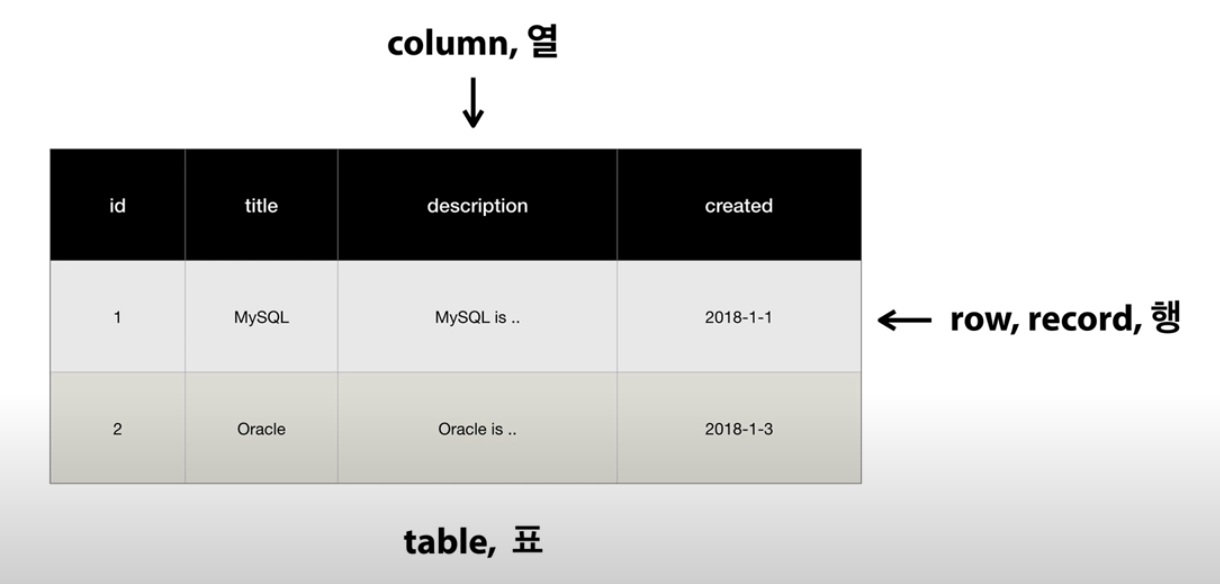
테이블의 생성
테이블을 생성 할때 제일 먼저 하는 것은 데이터의 분류체계를 만드는 것이다.
데이터의 분류는 테이블의 컬럼을 통해서 만들수 있다.
컬럼을 만들 때 컬럼에 데이터 타입을 강제해서 들어온는 값을 제한 할 수 있다.
또한 조건을 걸어서 데이터 추가 시 원하는 데이터 형식에 맞게 들어 올 수 있게 한다.
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
....
);
CREATE TABLE topic(
id INT(11) NOT NULL AUTO_INCRENMENT,
title VARCHAR(100) NOT NULL,
description TEXT NULL,
create DATETIME NOT NULL,
author VARCHAR(30) NULL,
profile VARCHAR(100) NULL,
PRIMARY KEY(id)
);
-
NOT NULL
반드시 입력을 해야 한다는 것이다. -
AUTO_INCREMENT
자동으로 1씩 증가한다는 것이다. -
PRIMARY KEY
성능, 중복 방지 두가지 측면이 있다.
각각의 값들이 고유하고, 중복이 되면 안된다.
참고 사항

비밀번호를 바꾸라는 오류가 발생
SET PASSWORD = PASSWORD();CRUD
- CREATE
- READ
- UPDATE
- DELETE
데이터베이스의 본질인 CRUD이다.
SQL을 이용해 데이터베이스에 어떻게 CRUD가 가능한지 알아보도록 하자!!
INSERT =======>
CRUD의 CREATE
테이블에 데이터를 추가하기 위해서 사용하는 SQL문의 INSERT
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);INSERT INTO topic( title, description, created, author, profile)
VALUES ("MYSQL", "MYSQL is...", NOW() , "ehdus", "developer");
SHOW TABLES #스키마안에 있는 테이블 정보를 볼 수 있다.
DESC 테이블이름 #테이블의 구조를 볼 수 있다.SELECT =======>
CRUD의 READ
SELECT는 테이블에서 원하는 정보를 가지고 오는 것이다.
SELECT 테이블의 컬럼명 FROM 테이블이름SELECT * FROM topic;
SELECT id, title, created, author FROM topic;where절 이용해서 조건을 만들어서 데이터 가지고 오기
SELECT * FROM topic;
SELECT id, title, created, author FROM topic WHERE author = "ehdus";
SELECT id, title, created, author FROM topic WHERE author = "ehdus" ORDER BY = id ASC|DESC;
SELECT id, title, created, author FROM topic WHERE author = "ehdus" ORDER BY = ASC|DESC LIMIT 2;데이터베이스는 대용량 데이터를 보관하므로 한번에 많은 데이터를 가지고 오는
* 과 같은 키워드는 잘못사용하면 컴퓨터에 부담이 된다.
LIMIT 키워드를 이용해서 가지고 오는 개수에 제한을 줄 수 있다.
UPDATE =======>
CRUD의 UPDATE
업데이트가 적용될 대상을 적지 않으면 모든 컬럼에 적용되므로 주의해야 한다.
UPDATE 테이블이름 SET 컬럼명 = "데이터" WHERE 업데이트가 적용될 대상DELETE =======>
CRUD의 DELETE
삭제가 적용될 대상을 적지 않으면 모든 컬럼이 삭제되므로 주의해야 한다.
DELETE FROM 테이블이름 WHERE 적용될 대상관계형데이터베이스의 필요성
왜 관계형데이터베이스가 필요한가?
중복된 데이터가 있으면 데이터 관리시 불필요한 작업이 늘어나게 된다.
중복된 데이터를 따로 빼내어 새로운 데이터를 만들고, 테이블끼지 참조 할 수 있다면, 데이터의 관리가 좀 더 쉬워질 것이다.
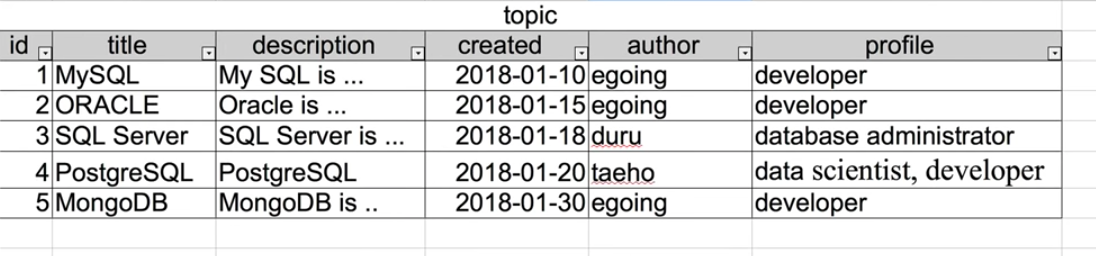
아래의 사진은 두개의 테이블을 합쳐서 새로운 데이터 테이블을 만들 었다.
테이블 분리하기
하나의 테이블에서 중복된 데이터가 있으므로 author테이블과 topic테이블로 나누었다.

JOIN
JOIN은 관계형 데이터베이스의 핵심이라고 말할 수 있다.
관계형이란 Relational으로 테이블간의 관계를 의미한다. 중복된 데이터들을 따로 테이블로 만들어서 유지보수를 쉽게 만들 수 있다. 또한 JOIN을 이용해서 테이블 끼리 관계를 만들어서 필요에 따라 원하는 데이터를 가지고 올 수 있다.
JOIN을 통해 분리된 테이블을 마치 하나의 테이블처럼 만들어서 가지고 올 수 있다.
SELECT * FROM topic LEFT JOIN autor ON topic.author_id = author.id;topic테이블과 author테이블을 JOIN 해주는데
topic테이블의 author_id 와 author 테이블의 id가 같은 것끼리 JOIN을 해라.
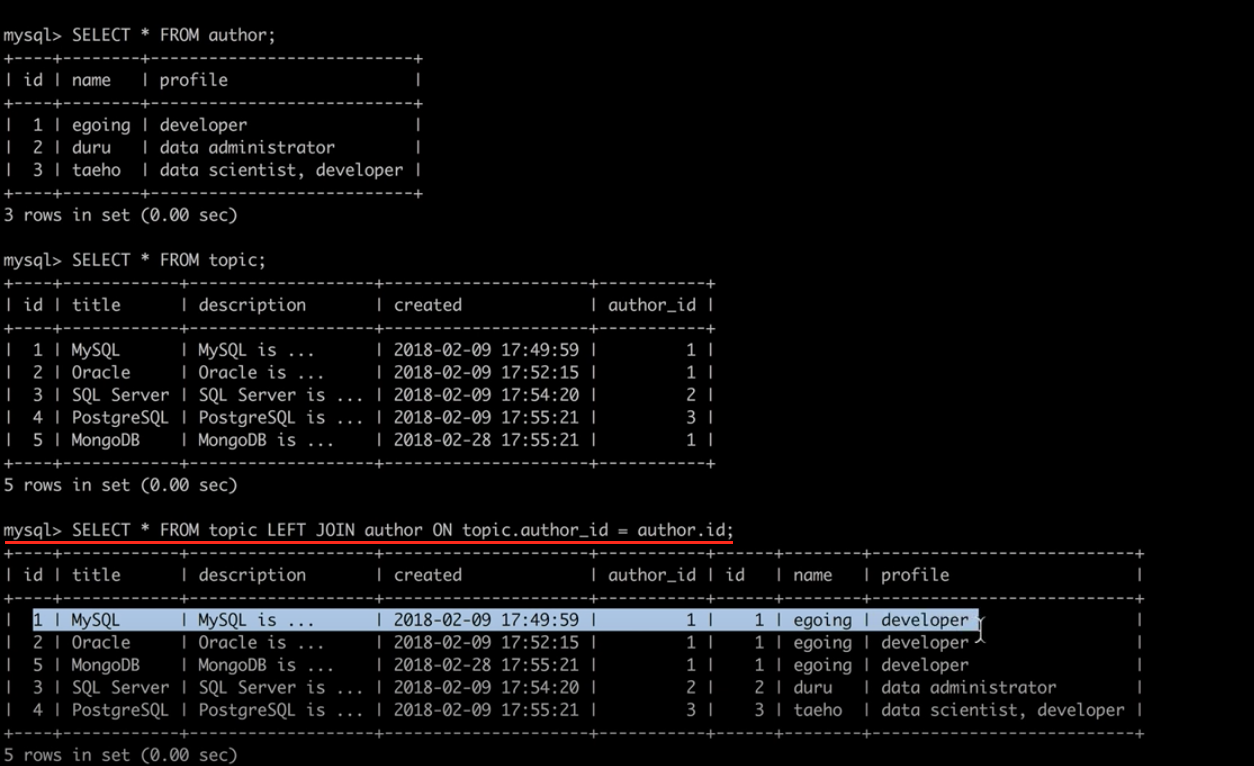
SELECT topic.id AS topic_id , title, description, created, name, profile FROM topic LEFT JOIN autor ON topic.author_id = author.id;인터넷과 데이터베이스
인터넷과 데이터베이스의 관계
웹은 인터넷 위에서 동작한다.
web browser <==> web server
web client <==> web server
database client <==> database server
MySQL도 클라이언트 쪽과 서버쪽으로 나뉘어 있다.
우리가 지금까지 사용한 것은 클라이언트 쪽으로 클라이언트 쪽에서 터미널창에서 작업을 해서 서버측에 데이터를 보내는 것이다.(My SQL monitor)
MySQL Client
MySQL Monitor는 MySQL의 하나의 클라이언트로 이곳에서 우리는 데이터를 조작했다. MySQL Server를 설치하면 MySQL 모니터가 따라서 설치된다고 생각해도 좋다. GUL기반이 아닌 CLI기반이다. 많은 서버들은 데이터베이스 본연에 집중하기 위해서 GUI를 제공하지 않고 CLI로만 다루는 경우가 많다.
우리는 MySQL을 다운로드해서 그 안의 클라이언트 쪽에서 작업을 하면, 그 작업한 내용이 서버측으로 넘어가서 저장되게 된다.
CLI든 GUI든 SQL을 MySQL서버에 전송해서 데이터베이스 서버를 제어하게 된다.
추가 학습 자료
-
sql
-
index
-
modeling
-
backup => mysqldump, binary log
-
cloud => 임대해서 서버를 이용
-
programming => 데이터베이스를 부품으로 해서 프로그래밍에 활용한다.
-
python mysql api
