Paper: Deep contextualized word representations
🔍1. Introduction
Pre-trained word representations은 많은 neural language 이해 모델에서 중요한 부분임.
단, 이는 high quality 표현을 학습하는 데에는 좀 어려움이 있음.
다양한 NLP Task에서 사용되긴 하나, 단어당 고정된 표현만 생성해내는 어려움 존재.
이상적인 모델은 단어 표현 시에 하단 두 가지를 만족해야 함.
1) 단어 사용 시의 복잡한 특징(ex. 구문/의미)
2) 언어적 문맥에 따라서 어떻게 변하는지(=다의성)
본 논문에서는 위 두 가지를 만족하는 deep contextualized word representation(심층 맥락적 단어 표현)을 소개하려고 함.
이는 기존 모델에 쉽게 통합될 수 있고, 다양한 언어 이해 문제에서 성능 향상을 크게 이뤄냄.
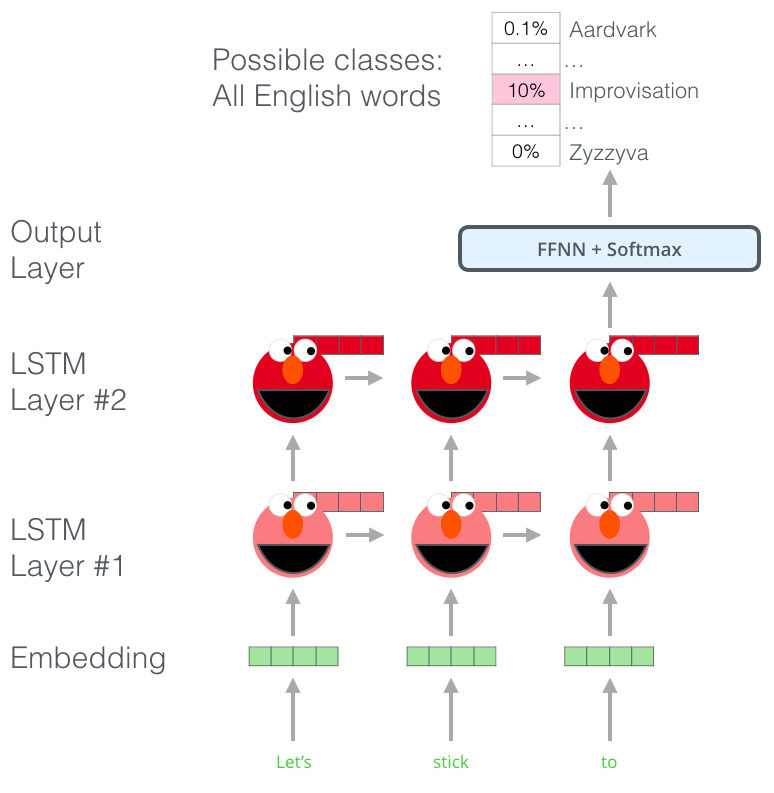
ELMo
ELMo는 양방향 LSTM(biLSTM)에서 도출된 벡터를 사용함.
해당 LSTM은 대규모 text corpus에서 언어 모델(LM)을 목적으로 훈련되었음.
때문에, 해당 모델을 Embeddings from Language Models, ELMo라고 부르는 것임.
ELMo(Embeddings from Language Models)는 기존 단어 임베딩 방식(각 단어 유형에 고정된 표현 할당)과 달리, 입력 문장 전체의 함수로 각 토큰의 표현을 만듦.
특히, 모든 biLSTM 내부 레이어를 활용해서 Task별로 선형 결합을 학습하여 성능을 향상시킴.
이렇게 internal states(내부 상태)를 결합하여 단어 표현을 풍부하게 만들 수 있음.
- higher-level LSTM states: 단어 의미가 context-dependent(문맥에 의존되는)인 경우에서 효율적임.
- lower-level LSTM states: 단어의 구문(syntax)적 측면을 잘 나타내어 모델링함. (ex. 품사 태깅에 굳)
→ 각 Task별로 유용하게 사용 가능.
또한, ELMo는 기존 방식과 달리 비라벨 데이터로 사전 학습한 후, 가중치를 고정하고, Task 모델을 추가적으로 활용하여 훈련 데이터 size가 작은 환경에서도 높은 성능을 산출했고, 일반적인 biLM 표현을 활용하게 하여 성능 향상에 도움을 줌.
✅2. ELMo: Embeddings from Language Models
앞서 언급했듯, ELMo는 기존 단어 임베딩과 달리, 입력 문장의 전체 문맥을 고려해서 단어 표현을 생성함.
이는, character convolution(문자 기반 합성곱)을 이용한 two-layer biLM(양방향 언어 모델)에서 계산되어, 내부 network 상태의 선형 함수로 구성됨.
특히, 반지도 학습(semi-supervised learning)이 가능하고, 기존 NLP 아키텍처에 쉽게 통합할 수 있다는 장점이 있음.
Bidirectional language models
길이가 N인 Token 시퀀스 (t_1, t_2, ..., t_N)이 주어졌을 때,
forward language model(순방향 언어 모델)은 하단과 같이 시퀀스 확률을 계산함.
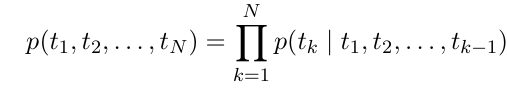 각 토큰 t_k의 확률은 이전 토큰들을 기반으로 모델링 됨.
각 토큰 t_k의 확률은 이전 토큰들을 기반으로 모델링 됨.
이렇게 해서 언어 모델이 텍스트 데이터를 이해하는 것임.
최신 neural language 모델의 경우, 맥락에 의존하지 않는 token 표현 x_k_LM 을 계산함.
(token embedding이나 characters 기반 CNN을 통해)
이는, L개의 Forward(순방향) LSTM 층을 통과함.
각 위치 k에서 LSTM 층 j는 문맥에 의존하는 표현 h_k,j_LM을 출력하게 됨.
그리고 최상위 LSTM 층의 출력인 h_k,L_LM은 Softmax계층과 함께 사용되어서 다음 토큰 t_k+1을 예측하게 되는 것임.
Backward LM은 Forward LM과 비슷하지만, 시퀀스를 반대로 처리함.
따라서 하단과 같이 현재 토큰의 미래 문맥(t_k+1, t_k+2, ..., t_N)을 기반으로 이전의 토큰을 예측하게 되는 것임.
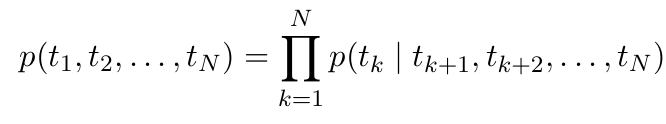
biLM(양방향 언어 모델)은 순방향과 역방향 LM을 결합함.
순방향 & 역방향의 log likelihood를 동시에 극대화하는 방식으로 정의됨.
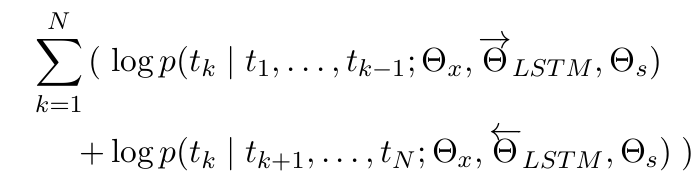
- Θ_x: 토크 표현 매개변수
- Θ_LSTM: LSTM 가중치
- Θ_s: Softmax 매개변수
이를 통해서 단어의 문맥 의존적인 표현을 더욱 다양하게 만들어줌.
순방향/역방향에서 하단 두 변수는 공유함.
- Θ_x: 토크 표현 매개변수
- Θ_s: Softmax 매개변수
단, Θ_LSTM(LSTM 가중치)은 독립적인 매개변수로 유지함.
ELMo
ELMo는 biLM 중간 layer 표현들을 task에 맞게 조합한 것임.
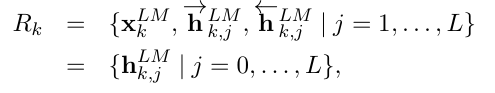 ↑ 각 token t_k에 대해서, L-층 biLM은 2L+1개의 representation 집합 R_k를 계산하게 됨.
↑ 각 token t_k에 대해서, L-층 biLM은 2L+1개의 representation 집합 R_k를 계산하게 됨.
- h_k,0_LM: token layer 출력
- →/← h_k,j_LM: biLSTM 층의 양방향 출력 벡터
ELMo를 후속 모델에 포함시켜햐 하니, 모든 레이어를 single vector로 압축함.
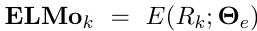
이때, 가장 단순한 방법이긴 한 것은 최상위 레이어만 선택하는 것.
단, 일반적으로 모든 biLM layer를 가중합으로 처리하여 task별 표현을 계산하는 편임.
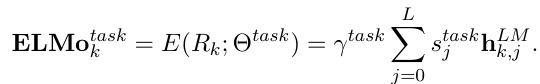
- s_j_task: softmax로 정규화된 가중치
- γ_task: task 모델이 전체 ELMo 벡터 크기를 조정할 수 있도록 하는 scalar parameter
추가적으로, 각 biLM layer의 활성값 분포 차이 보정을 위해서, layer 정규화를 적용하는 것이 도움이 되기도 했음.
Using biLMs for supervised NLP tasks
pre-trained biLM과 지도 학습된 아키텍처가 주어졌을 때, biLM을 사용해서 Task 모델 개선하는 방법
:
1) 각 단어에 대한 biLM의 모든 layer 표현을 기록함.
2) task 모델이 이 표현들을 linear combination(선형 조합)할 수 있도록 학습시킴.
ELMo 추가 시
1) biLM 가중치 고정
2) ELMo 벡터(ELMo_k_task)를 기존 토큰 표현 (x_k)에 concatenate(병합)시키고, 이거를 task RNN에 전달
모델 구조를 크게 바꾸지 않아도, 다양한 NLP task에서 성능 개선 가능.
또한, ELMo에 dropout을 적당히 추가하면 과적합을 방지할 수 있음.
그리고, ELMo 가중치 정규화도 진행하면, 전체적인 모델 안정성 & 성능 향상 가능.
✅3. Evaluation
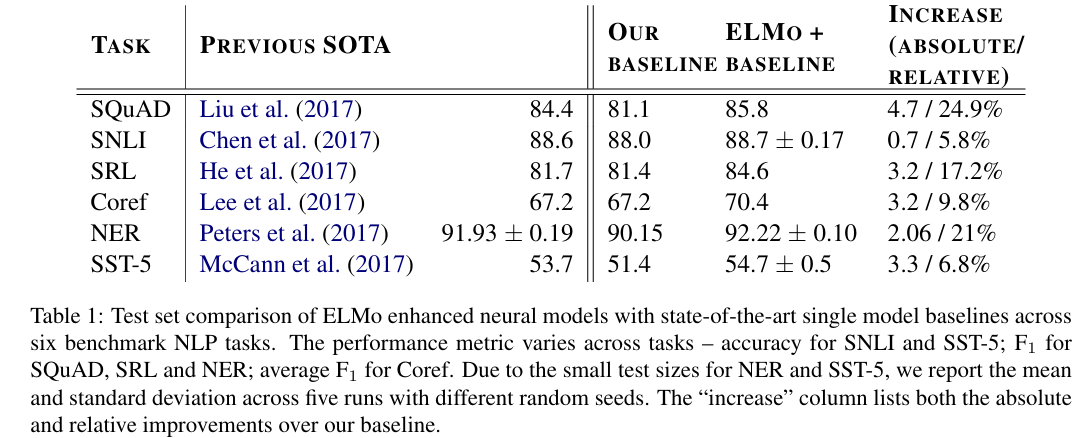 위 표를 통해 ELMo가 다양한 6개의 benchmark NLP Tasks에서 성능 향상을 이뤄낸 것을 확인할 수 있음.
위 표를 통해 ELMo가 다양한 6개의 benchmark NLP Tasks에서 성능 향상을 이뤄낸 것을 확인할 수 있음.
각 Task에서 단순히 ELMo만 추가했는데, 성능이 뛰어나게 좋아진 것임. 상대적 오류도 기존에 비해 6~20% 감소하는 양상을 보임.
Question answering
Stanford Question Answering Dataset (SQuAD): '질문-답변' 쌍을 포함한 10만 개 이상의 데이터셋
기준 모델의 경우, BiDAF(Bidirectional Attention Flow) 모델로, 양방향 attention 구성 뒤에 self-attention layer를 추가한 구조임.
이 모델에 ELMo를 추가했더니,
테스트 셋에서 F1 score가 4.7% 개선하였고, 기준 모델보다 상대적 오류 24.9% 감소, single 모델 기준 state-of-art 1.4% 개선해냄.
Textual entailment
premise(전제) 기반으로, 가설 참/거짓 여부 결정하는 task이며, Stanford Natural Language Inference (SNLI) corpus를 데이터셋으로 사용.(약 55만 개의 '전제-가설' 쌍 포함)
기준 모델 ESIM(sequence model)은 '전제-가설'을 biLSTM으로 인코딩하고, matrix attention를 추가하고, local inference & 다른 biLSTM inference 조합의 layer를 추가함.
이 모델에 ELMo 추가한 결과,
평균적으로 정확도 0.7% 향상을 이뤄내었고, 5개의 모델 앙상블 결과 정확도가 89.3%로 증가하였음. 이는 기존 최고 기록 88.9%를 뛰어 넘는 수치임.
Semantic role labeling
SRL(Semantic role labeling)은 문장에서 '술어-인수' 구조(predicate-argument structure)를 모델링하는 것으로, "누가 누구에게 무얼 했나?"와 같은 질문에 답을 하는 구조임.
기준 모델 SRL은 BIO tagging 방식(데이터 라벨링 방식)로 모델링 진행.
8층의 biLSTM을 사용했고, 순/역방향 layer가 교차해서 배치됨.
이 모델에 ELMo 추가한 결과,
테스트 셋에서 F1 score가 81.4%에서 84.6%로 3.2% 증가하였고, 기존 최고 모델보다 1.2% 개선된 성과를 보임.
Coreference resolution
Coref은 텍스트 내에서 같은 대상을 의미하는 표현들을 찾아서 연결하는 작업임.
기준 모델은 biLSTM과 attention 메커니즘 사용해서 span 계산.
Softmax mention ranking 모델 적용해서 coreference chains을 찾음.
이 모델에 ELMo 추가한 결과,
테스트 셋에서 F1 score가 67.2% 에서 70.4%로 3.2% 증가했으며, 기존 앙상블 결과보다 1.6% 또한 개선됨.
Named entity extraction
NER Task는 Reuters RCV1 corpus에서 추출된 뉴스 기사로 구성됨.
(해당 데이터에는 사람/장소/조직/기타 4가지 유형으로 태그 지정됨)
기준 모델은 pre-trained word embeddings을 사용했고, character-base CNN 표현을 추가했으며, 2개 biLSTM 층 & CRF(Conditional Random Field) loss 사용.
이 모델에 ELMo 추가한 결과,
biLSTM-CRF 모델은 92.22% F1 score 기록함.
이전 연구에서는 biLM의 top layer만 사용했는데, ELMo는 모든 biLM layer를 가중 평균 했으니, 여러 task에서 성능이 개선되는 것을 보일 수 있었던 것임.
Sentiment analysis
SST-5는 영화 리뷰 문장 기반 감정 분석 task. (어려운 작업)
문장의 감정을 very negative/negative/neutral/positive/very positive 이렇게 5개 라벨 중 하나로 분류.
기준 모델은 BCN(Biattentive Classification Network)으로 CoVe(Context Vector) 임베딩 추가 시, 최고 성능을 내었음.
이 모델의 CoVe를 ELMo로 교체했더니, 정확도가 기존 최고 성능 대비 1.0% 절대적으로 증가함을 확인할 수 있었음.
✅4. Analysis
Alternate layer weighting schemes

기존의 방법처럼 최상위 레이어만 사용하는 것보다 모든 레이어를 활용하면 성능 개선을 이뤄냄을 확인할 수 있음.
또한 정규화 매개변수 γ를 1로 설정했을 때(모든 레이어 단순 평균) SQuAD에서 F1 score가 0.3% 추가적으로 개선됨을 확인할 수 있음.
또한, γ을 0.001(개별 레이어 가중치 학습)로 설정했을 때, SQuAD에서 F1 score가 0.2% 더 개선됨을 확인할 수 있었음.
ELMo에서는 대부분 작은 γ 값이 더 선호됨을 확인 가능.
Where to include ELMo?
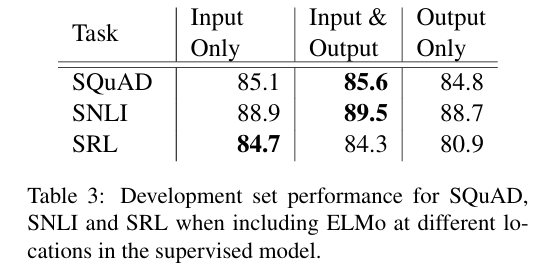
SNLI & SQuAD
: ELMo를 입/출력 레이어 모두에 포함하면, 입력 레이어에만 포함한 것보다 더 높은 성능을 보임을 확인할 수 있음.
SRL
: ELMo를 입력 레이어에만 포함한 경우 성능이 가장 높았음. 이는 biLM 정보보다 task 문맥 표현이 더 중요하기 때문임.
What information is captured by the biLM’s representations?

ELMo 추가 시, 단순한 word vectors만 사용할 때보다 성능 개선 가능.
word vectors만 사용할 때에는 한계가 있는데, biLM의 contextual representations가 word vector가 잡지 못하는 정보까지 인코딩 해준다는 것.
실험을 통해 다의어의 품사 및 의미까지 완벽히 구별하는 것을 확인할 수 있음.
Sample efficiency
sample efficiency: 모델이 최고 성능 도달 시에 필요한 파라미터 수/학습 데이터 크기 줄이는 능력
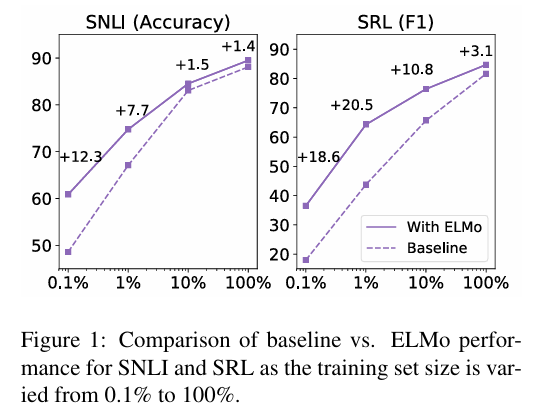
ELMo 추가 시, sample efficiency를 크게 줄일 수 있었음.
그리고, 학습 데이터가 작을 때에도 ELMo를 사용함으로써 높은 성능 달성을 이뤄낼 수 있었음.
Visualization of learned weights
 softmax-normalized가 진행된 학습 layer의 가중치(weights)를 시각화한 것임.
softmax-normalized가 진행된 학습 layer의 가중치(weights)를 시각화한 것임.
즉, ELMo의 여러 레이어가 다양한 Task에서 어떻게 활용되는지 확인하고자 함.
입력 레이어에서는 biLSTM의 첫 번째 레이어가 task 모델에서 가장 많이 활용되는 모습을 보임.
특히, syntactic information(구문 정보)가 중요한 task에서 첫 번째 layer를 가장 많이 활용함.
출력 레이어에서는 약간 하위 레이어를 선호하는 모습이 보이지만, 전체 레이어의 정보를 조합하는 것이 더 중요하다는 것을 나타내고 있음.
SRL이나 감정 분석 task에서 상위 레이어와 하위 레이어를 적절하게 조합해서 성능을 최적화 하고자 하는 모습을 확인할 수 있음.
🔚5. Conclusion
본 논문에서는 biLM을 활용해서 high-quality의 deep context-dependent representations(심층 맥락 의존적 표현)를 학습하는 방법을 제안함.
ELMo를 다양한 NLP task에 적용하면서 여러 실험에서 우수한 성능 향상 결과를 확인할 수 있었음.
biLM layer는 문맥 기반의 구문적/의미적 정보를 나눠서 효율적으로 표현하는데, 이때 모든 layer를 활용하면 task 성능을 최적화할 수 있음을 확인할 수 있음. (단일 layer보다 뛰어난 성능)
