[논문 리뷰] Faster R-CNN - Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (2015)
[논문 리뷰]
Paper: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
🔍1. Introduction
최근의 객체 탐지 분야의 발전은 Region Proposal Methods와 Region-based convolutional neural networks(R-CNN)의 성공에 의해 이루어짐.
초기 R-CNN은 계산 비용이 너무 컸지만, 이후에 나온 제안(ex. Fast R-CNN)들 덕분에, convolution 연산을 공유함으로써 계산 비용이 대폭 줄어들었음.
다만, 여전히 Region Proposal 단계가 최신 detection systems에서 계산 병목 현상(bottleneck)으로 작용하고 있음.
본 논문에서는, Deep Convolutional Neural Network을 사용해서 Region Proposal을 계산함으로써, 더 나은 해결책을 제시하고자 함.
- Proposal 계산이 detection network의 계산에 포함(통합)되어서 거의 cost-free함
RPN(Region Proposal Network)
: RPN은 최신식의 객체 탐지 네트워크과 convolutional layer를 공유함
Convolutional 연산을 공유하기 때문에, Proposal 계산의 추가 비용이 매우 적음.(연산 효율성 극대화)
또한, 기존 Fast R-CNN에서 사용되던 Convolutional Feature Map을 Region Proposal 생성에도 활용.
Convolutional Feature 위에 추가적으로 Convolutional Layer를 더해서 RPN을 설계함.
RPN은 FCN(fully convo
lutional network)의 일종으로 detection proposal에 대해서 end-to-end 학습 가능.
RPN은 다양한 크기/비율을 가진 Region Proposal 예측을 효율적으로 가능하게 설계됨.
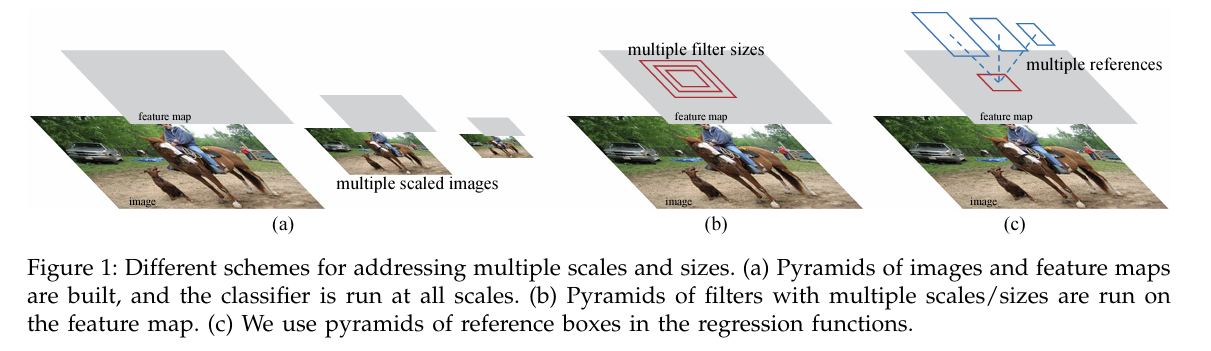 ↑ (a) & (b) : 기존 방법들(이미지 피라미드, 필터 피라미드), (c) : Anchor Box 참조 pyramid of regression references 방법
↑ (a) & (b) : 기존 방법들(이미지 피라미드, 필터 피라미드), (c) : Anchor Box 참조 pyramid of regression references 방법
위 기존 방법(a, b)들과 달리, Anchor Box 도입!
Anchor Box는 pyramid of regression references(회귀 참조 피라미드)로 생각할 수 있는데, 다양한 크기/비율에 대해서 이미지나 필터를 나열할 필요가 없음.
해당 모델은 단일 scale 이미지를 사용해서 학습하고, 결과적으로 실행 속도도 빨라지는 양상을 보임.
(a): Pyramids of images and feature maps(이미지 & 특징 맵 피라미드)
- 다양한 scale의 이미지 생성 후 각 scale에서 특징 맵 계산. 그리고 모든 scale에서 분류기 실행해서 객체 탐지.
→ 느리고, 계산 비용 너무 큼
(b): Pyramids of filters with multiple scales/sizes(다양한 스케일/크기 필터 피라미드)
- 단일 피처 맵에서 다양한 스케일과 크기를 가진 필터를 사용해서 객체 탐지.
→ 필터 크기 다양하게 설정해야 하고, 모든 필터 처리해야 돼서 복잡함
(C): pyramid of regression references(Anchor Box 참조)
- Anchor Box를 참조 박스로 사용해서 다양한 스케일/비율 한 번에 처리 가능. 이미지나 필터 피라미드 생성 없이 다양한 크기 물체 적용 가능.
→ 단일 이미지로 스케일 처리 가능하기에 간단하고, 실행 속도 빨라져서 효율적임
RPN & Fast R-CNN 통합해야 하니,
→ Region Proposal Task & 객체 탐지 Task에 대한 fine-tuning을 번갈아서 하는 방식 제안
→ Convolutional Feature를 공유해서 효율성을 높임
✅2. RELATED WORK
Object Proposals
Object Proposal의 주요 방식
1. 초픽셀 그룹화
: 대표적인 방법 - Selective Search, CPMC, MCG
: 저수준 특징(질감, 색상 등)을 기반으로 초픽셀 병합해서 물체가 있을 것 같은 후보 영역 생성.
2. 슬라이딩 윈도우
: 대표적인 방법 - Objectness in Windows, EdgeBoxes
: 이미지 내 가능한 모든 영역을 일정 간격으로 조사해서 후보 영역 생성
Deep Networks for Object Detection
가장 대표적인 연구는 R-CNN.
Region Proposal 영역을 객체 카테고리/배경으로 분류하기 위해 CNN을 end-to-end로 학습함.
R-CNN은 주로 분류기 역할이고, 객체 경계를 예측하지는 않음(단, Bounding Box Regression을 통해 Bounding Box를 보정하는 경우 제외).
R-CNN의 정확도(객체 위치 제안)는 Region Proposal 모듈 성능에 크게 의존.
여러 연구에서는 딥러닝을 사용해 객체 bounding boxes를 예측하는 방법을 제안했으며,
OverFeat/MultiBox/DeepMask 등이 등장.
이러한 연구에 이어서 합성곱 연산에 대한 연구가 점점 더 관심 증가됨.
그 중에 적응형 크기 풀링(adaptively-sized pooling)(SPP)과 Fast R-CNN이 대표적임.
→ Convolutional Feature 공유를 통해 효율성과 정확도 향상.
✅3. FASTER R-CNN
Faster R-CNN은 두 가지 모듈로 구성(RPN+Fast R-CNN Detector)
1. deep fully convolutional network: Region Proposal 만드는 역할.
2. Fast R-CNN detector: 만들어진 Region Proposal로 객체 탐지 수행
이 시스템이 single 통합 네트워크로 구성되어 있어서, 객체 탐지 작업 수행하는 것.
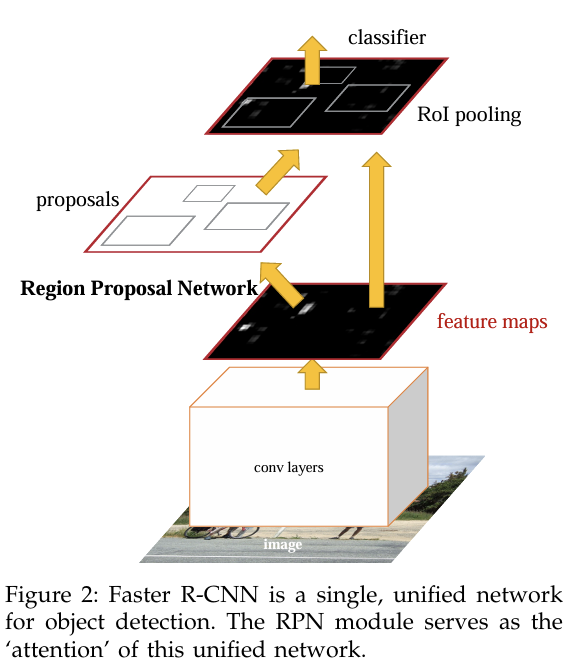
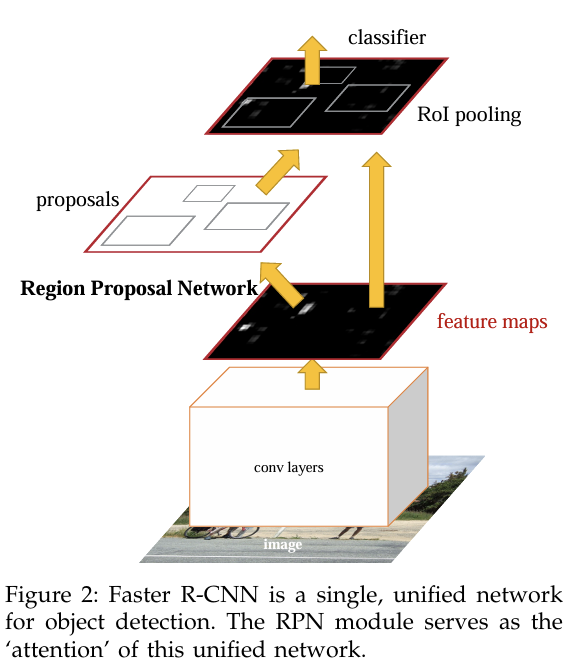
RPN 모듈은 마치 Attention 메커니즘이 "어디를 look 해야할지" 알려주는 것과 같은 역할을 함. 따라서 RPN의 작동으로 인해 Fast R-CNN이 주목할 영역을 제안하는 것.
Region Proposal Networks
RPN은 어떤 크기의 이미지든 input으로 받아들이고, 사각형 형태의 Region Proposal과 Objectness Score을 출력함.
RPN은 FCN(Fully Convolutional Network)로 모델링됨.
RPN의 궁극적 목표: Fast R-CNN 객체 탐지 network와 계산을 공유하는 것. 두 network는 공통된 Convolutional Network를 공유한다...
Region Proposal 생성 과정
: 슬라이딩 윈도우 방식으로 작은 네트워크가 마지막으로 공유된 Convolutional Layer에서 생성된 피처맵 위를 이동.
이 작은 네트워크가 입력 피처맵의 n x n 윈도우를 입력으로 받아들이고, 각 윈도우는 낮은 차원의 feature로 매핑됨.
매핑된 피처는 두 개의 Fully-connected Layer에 입력됨.
Box Regression Layer(reg) → 객체 bounding box 위치 예측
Box Classification Layer(cls) → box에 객체가 있는지의 여부 분류
Anchors
Anchor는 슬라이딩 윈도우 center에 위치한 Reference Box(참조 박스).
region proposal을 위한 기준점 역할을 함.
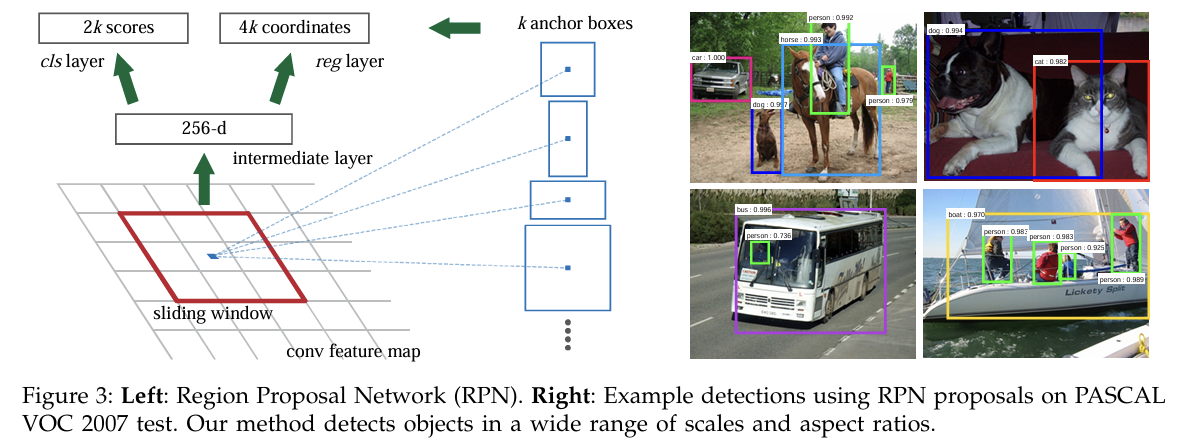 Anchor는 각각 특정 scale & aspect ratio를 가짐.
Anchor는 각각 특정 scale & aspect ratio를 가짐.
Anchor 총 개수
: Convolutional Feature Map 크기 = W x H일 때, 총 W x H x k개의 Anchor가 존재(보통 약 2,400개)
Translation-Invariant Anchors
Anchor는 이미지 내 위치 변화(translation)에도 잘 작동하는 것을 보여줌.
동일한 Convolutional Feature에서 학습이 이루어지므로, 네트워크는 translation invariance(불변성)을 확보하게 됨.
또한, translation invariance는 모델 크기를 줄이는 양상을 보임.
MultiBox 대비 적은 파라미터 수를 가진 것을 확인할 수 있고, 특히 소규모 데이터셋(ex. PASCAL VOC)에서 더 안정적으로 학습할 수 있음.
Multi-Scale Anchors as Regression References
각각의 Anchor는 다양한 scale과 aspect ratio를 가짐.
이를 통해 기존의 이미지/필터 피라미드 방식이 가지는 한계(복잡성 문제) 극복할 수 있음.
또한 단일 네트워크로 다양한 크기의 객체를 처리할 수 있음.
Loss Function
RPN의 목표는 네트워크가 정확한 Region Proposal을 생성하도록 학습하는 것임.
RPN 학습 시에, 각 Anchor에 대해서 binary class label(이진 클래스 라벨=객체 여부)을 지정하게 됨.
- Positive Label
- Ground-truth box와 Intersection-over
Union(IoU)가 가장 높은 Anchor
- IoU가 0.7이상인 Anchor - Negative Label
- 모든 Ground-Truth Box에 대해 IoU가 0.3보다 작은 Anchor - positive/negative 둘 다 아닌 Anchor: 학습에 포함 X
하단과 같이 손실함수 구성
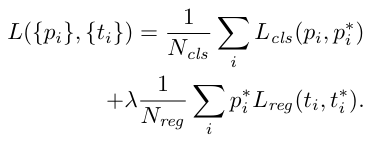
총 손실 = Classification Loss + Regression Loss이 됨.
- Classification Loss: Anchor가 객체인지 아닌지를 분류
- Regression Loss: 예측 box와 실제 box의 위치/크기 차이 최소화, Regression Loss는 Positive Anchor에만 활성화.
Normalization과 가중치(lamda) 설정을 통해서 Balance를 맞춤.
또한, bounding box regression을 통해, Anchor Box를 Ground-Truth Box로 변환함.
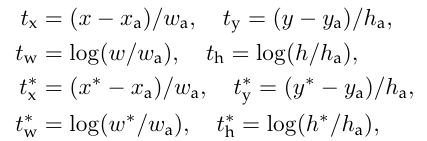
- x, y, w, h: Box 중심 좌표 & 크기
- x_a, y_a, w_a, h_a: Anchor Box 좌표 & 크기
기존 방식(동일한 Regressor 사용)과 달리, RPN은 각 scale/size에 대해서 별도의 Regressor을 사용하기에 다양한 size를 처리할 수 있음.
Training RPNs
RPN은 역전파 & SGD(확률적 경사 하강법)을 사용해서 end-to-end 학습을 할 수 있음.
Image-centric 샘플링 전략
- 각 미니 배치를 single 이미지에서 가져옴.(단 이 이미지에 positive/negative anchor 포함)
- Positive와 Negative Anchor의 비율은 최대 1:1
- 한 이미지에서 anchor 256개를 샘플링하는데, Positive Sample이 128개보다 적으면 Negative Sample로 채움
새로운 Layer는 평균 0, 표준편차 0.01인 가우시안 분포로 초기화.
공유된 Convolutional Layer는 ImageNet 분류 모델로 사전 학습.
학습률: 0.001 (60k 미니배치) → 0.0001 (20k 미니배치)
Momentum: 0.9
Weight Decay: 0.0005
Sharing Features for RPN and Fast R-CNN
RPN과 Fast R-CNN이 따로 따로 학습되면, Convolutional Layer를 다르게 수정하기에, Feature를 공유할 수 있도록 하는 학습 방법이 필요함
1) Alternating Training
RPN을 먼저 학습하고 생성된 Proposal으로 Fast R-CNN 학습하는 방식.
Fast R-CNN에 의해 튜닝된 네트워크를 사용해서 RPN을 재초기화함.
이 과정 반복 → 공유된 Feature 학습.
본 논문 모든 실험에서 사용된 방식임.
2) Approximate Joint Training
RPN과 Fast R-CNN을 하나의 네트워크로 병합.
확률적 경사 하강법에서 생성된 Proposal을 고정된 Proposal처럼 사용해 Fast R-CNN에 학습시킴.
Backpropagation에서는 RPN과 Fast R-CNN 손실의 Backward Signals를 공유된 Layer에 결합해서 업데이트함.
구현이 쉽고, 훈련 시간이 줄어든다는 장점이 있으나, proposal box들의 좌표 파생값을 무시한다는 단점 존재
3) Non-Approximate Joint Training
Proposal Box 좌표에 대한 Gradient도 포함되어야 가능한 방법임. 구현이 복잡함.
4-Step Alternating Training
본 논문에서는 4단계로 구성된 alternating training 방법을 제안함.
1) RPN 학습 단계
- ImageNet 사전 학습된 모델로 초기화.
- Region Proposal Task에 대해 RPN을 end-to-end로 학습
2) 앞 단계 Proposal 사용해서 Fast R-CNN 학습
- 이때 별도의 Convolutional Layer 사용하므로, RPN과 Fast R-CNN이 Convolutional Layer 공유 X
3) Fast R-CNN 기반으로 재초기화된 RPN 학습
- 공유된 Convolutional Layer 고정함
- RPN의 고유 Layer만 Fine-tuning
- 이때부터 RPN과 Fast R-CNN이 Convolutional Layer 공유하는 것
4) 공유 Layer 고정 후, Fast R-CNN 고유 Layer만 Fine-tuning
해당 과정을 통해 두 네트워크가 같은 Convolutional Layer를 공유하며 통합된 네트워크를 만들 수 있는 것임.
✅4. EXPERIMENTS
Experiments on PASCAL VOC
데이터셋
: PASCAL VOC 2007
: 20개 객체 클래스, 5,000개의 학습 이미지, 5,000개의 테스트 이미지로 구성
모델
: ZFNet - 5개 Convolutional Layer & 3개 Fully-connected Layer
: VGG-16 - 13개 Convolutional Layer & 3개 Fully-connected Layer
평가 기준
: mAP(Mean Average Precision)
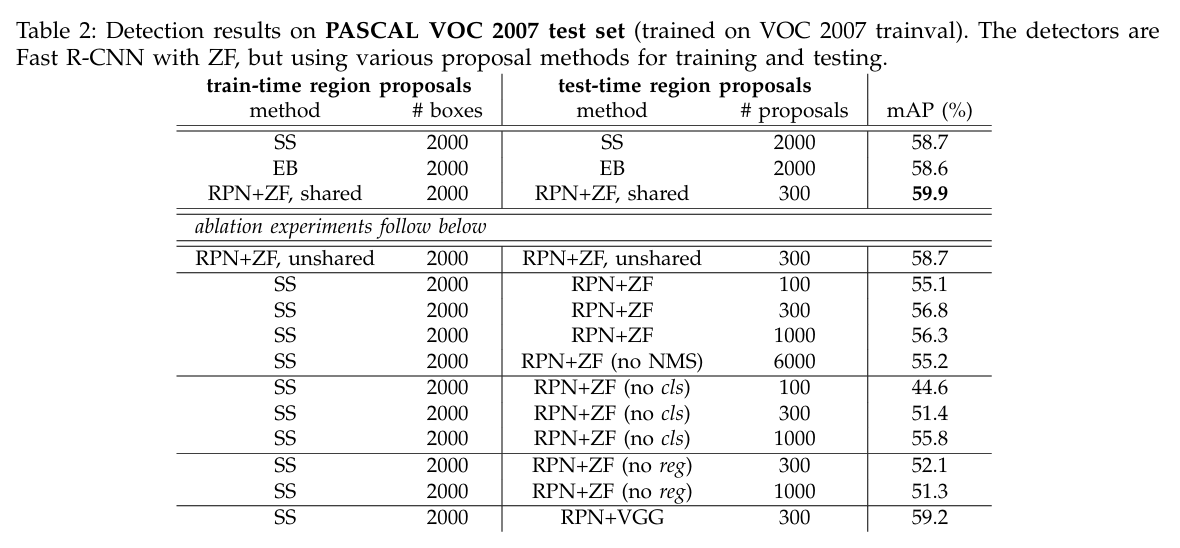 ↑ 다양한 Region Proposal 방법(ZF)
↑ 다양한 Region Proposal 방법(ZF)
SS(Selective Search): 2000 Proposal/mAP = 58.7%
EB(EdgeBoxes): 2000 Proposal/mAP = 58.6%.
RPN: 최대 300 Proposal/mAP = 59.9%
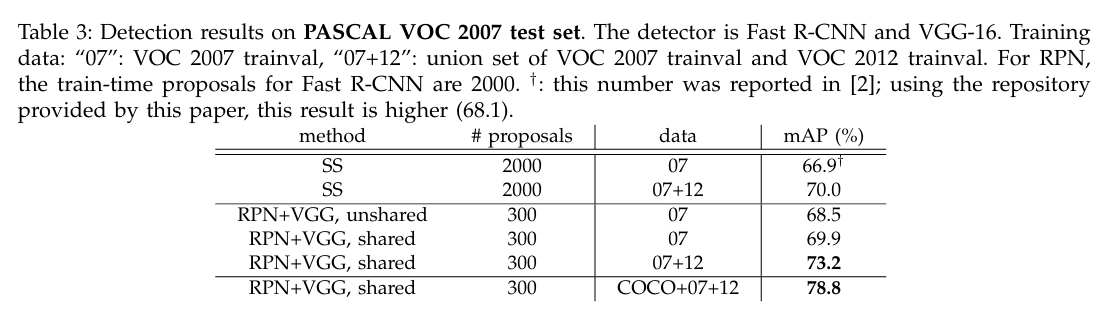 ↑ VGG-16 기반 성능
↑ VGG-16 기반 성능
SS(Selective Search): 2000 proposals/mAP = 66.9%
RPN + VGG:
- Shared Features: mAP = 69.9%.
- VOC 2007+2012 데이터로 학습 시: mAP = 73.2%.
 ↑ Timing 효율
↑ Timing 효율
SS + Fast R-CNN: 1830ms (0.5 fps)
RPN + Fast R-CNN: 198ms (5 fps)
ZFNet 사용 시: 59ms (17 fps)
RPN이 Convolutional Feature를 공유함으로써 다른 것들에 비해 빠른 속도를 구현하였으며, proposal 개수가 현저히 적어서 Fully-connected Layer의 계산 비용 또한 감소시킴.
Experiments on MS COCO
데이터셋
: MS COCO
: 80개 객체 클래스, 80k train 이미지 & 40k validation 이미지
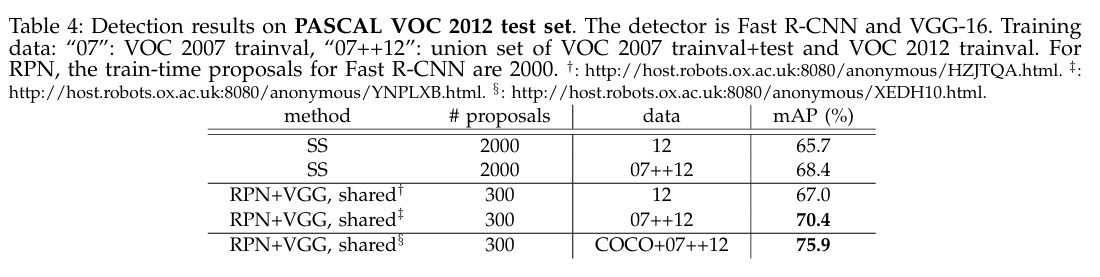 ↑ RPN + VGG
↑ RPN + VGG
VOC 2007+2012: mAP = 70.4%
VOC 2007+2012 + COCO: mAP = 75.9%
COCO에서 학습한 모델이 PASCAL VOC 때 보다 더 높은 성능(mAP) 구현.
COCO 데이터가 작은 객체 & 복잡한 이미지에 대해 탐지를 더 잘 해냄을 알 수 있음.
From MS COCO to PASCAL VOC
Transfer Learning(전이 학습)을 진행함.
COCO에서 학습한 모델을 PASCAL VOC로 transfer해서 성능 평가.
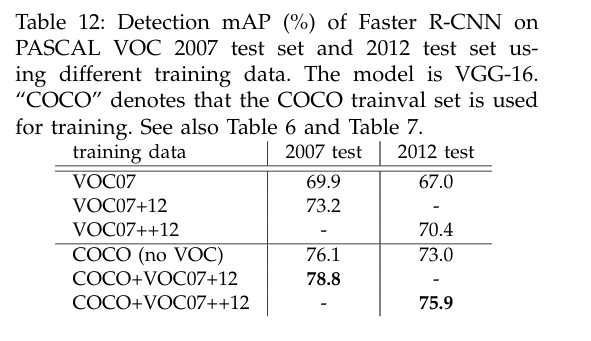
VOC 데이터셋에 COCO 데이터를 추가로 학습했을 때, 성능이 크게 향상된 것을 확인할 수 있음.
- COCO+VOC07+12 & 2007 test: mAP = 78.8%
- COCO+VOC07++12 & 2012 test: mAP = 75.9%.
🔚5. CONCLUSION
RPN을 사용해서 더 효율적인 Region Proposal을 생성할 수 있는 방법을 제안함.
RPN은 Fast R-CNN와 Convolutional Feature를 공유하여, Region Proposal에서의 추가 연산 비용을 거의 없앴음.
이를 통해, 딥러닝 기반 객체 탐지 시스템을 구축해서, 거의 실시간 급의 프레임 속도로 동작할 수 있었음.
또한, 학습된 RPN은 Region Proposal 품질 향상을 이뤄내어, 궁극적으로 전체 객체 탐지 정확도 또한 개선함.
