[논문 리뷰] EfficientNet - EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (2019)
[논문 리뷰]
Paper: EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
🔍1. Introduction
ConvNets(컨볼루션 신경망)는 accuracy를 더 높이기 위해 Scaling up(확장)하는 방식을 주로 사용함.
하지만, 컨볼루션 신경망은 아직 이를 확장하는 과정이 명확하지 않음.
일반적인 기존 확장 방법은 깊이(Depth) 또는 너비(Width)를 증가시키는 것임. 또는 이미지 해상도(Resolution)를 증가시키는 것도 있음.(점점 더 인기 추세)
기존 연구에서는 depth, width, resolution 중 하나만 scale up 하도록 했었음.
물론 2~3개도 동시 scale up이 가능하지만, arbitrary(임의적인) scaling은 복잡한 manual tuning이 필요하고, 여전히 최적이 아닌 정확도 & 효율성을 보이고 있음.
본 논문에서는 ConvNet 확장 방식의 원리를 연구하고, rethink 해보려고 함.
특히, Networks의 depth, width, resolution을 균형 있게 조절하는 것이 중요한데, 이 부분의 경우 scaling ratio를 이용해서 조절할 수 있음.
이러한 단순하면서도 효과적인 compound scaling method를 본 논문에서 소개하고자 함.
앞서 언급했듯, compound scaling method는 기존의 arbitrary한 scaling up 방식과는 달리, network의 width, depth, resolution을 일정한 비율로 확장하고자 함.
예를 들어서 연산량은 2^N배 늘린다면, depth는 α^N배, width는 β^N배, resolution은 γ^N배로 늘리는 것.
α, β, γ는 depth, width, resolution의 상수 계수로, 작은 모델에서 이 값들을 정의하고, 더 큰 모델에서도 같은 비율로 확장하는 것.
좀 더 직관적으로 이해하자면, input image가 커지면,
네트워크는 더 많은 layer가 필요해서 receptive field를 증가시켜야 되고,
또한 더 많은 channels가 필요해서 아주 세밀한 patterns를 더 잘 capture해야 함.
기존 연구에서 width와 depth의 연관성이 있음은 밝혀졌지만, width, depth, resolution 이렇게 세 가지 요소를 모두 연관지어서 정량적으로 분석한 것은 본 연구가 처음임.
새로운 baseline network를 설계하고, 이를 compound scaling 기법을 통해 확장한 것이 EfficientNets임.
EfficientNet은 여러 분야에서 SOTA 성능을 달성하며 효과적인 모델임을 입증해옴.
✅2. Related Work
ConvNet Accuracy
AlexNet 우승(ImageNet, 2012) 이후, ConvNet의 Accuracy는 모델을 더 크게 증가시키며 향상되어옴.
GoogleNet, SENet, GPipe 등 다양한 모델들이 등장하여 높은 accuracy를 달성했음.
하지만, 더 높은 accuracy를 내기 위한 과정에서 hardware memory limit이 존재했음.
더 높은 성능 향상을 위해서 단순히 모델만 키우는 것이 아닌, 효율성을 더 개선하는 방면이 중요함.
ConvNet Efficiency
ConvNet은 종종 Over-parameterized(과적합) 문제가 생김.
Model Compression(모델 압축)을 통해서 해당 과적합 문제를 해결하고자 하는데, 이는 Accuracy를 줄이면서 Efficiency를 향상시키는 방법임.
최근에는 경량화된 ConvNet 모델로 SqueezeNet, MobileNet, ShuffleNet이 등장했음.
또한, NAS(neural architecture search, 신경망 아키텍처 탐색) 기법이 인기를 얻고 있음.
이는 네트워크 width, depth, convolution kernel types & sizes를 자동으로 최적화하여 기존 모델들보다 더 효율적으로 Mobile ConvNets를 만들 수 있음.
다만, Mobile 환경에서는 우수한 기법이지만, 더 큰 모델에서는 design space와 tuning cost가 너무 크기에 적용하는 데에 한계가 있음.
따라서, 본 논문에서는 Super Large ConvNet을 연구하고, Model Scaling 기법을 통해 SOTA accuracy 성능을 높이고자 함.
Model Scaling
ResNet의 경우 Network Depth(레이어 개수)를 조정해서 모델 크기를 확장/축소할 수 있음.
WideResNet/MobileNet의 경우, Network Width(채널 개수)를 조절하여 모델 크기 조정 가능.
또한, input image size를 늘리면 accuracy를 올릴 수 있음.(다만 이는 더 많은 FLOPS(연산 횟수)를 요구함)
기존 연구들에 의하면 Neworks의 Depth와 Width는 ConvNet의 Expressive Power(표현력)에 중요한 요소임이 밝혀짐.
다만, ConvNet을 어떻게 더 최적의 방법으로 확장해야 하는지는 Open Question임.
따라서 본 논문을 통해, ConvNet의 Width, Depth, Resolution 각 요소를 균형 있게 확장하는 체계적이고 실험적인 연구를 진행하고자 함.
✅3. Compound Model Scaling
Problem Formulation
ConvNet의 Layer i(레이어 한 층)는 다음과 같은 함수 형태로 정의 가능함.
Y_i = F_i(X_i)
- F_i: 연산자(Operator)
- Y_i: 출력 텐서(Output Tensor)
- X_i: 입력 텐서(Input Tensor)
- tensor shape: <H_i, W_i, C_i>
- H_i, W_i: 공간적 차원(spatial dimension)
- C_i: 채널 차원(channel dimension)
ConvNet의 N은 여러 layer로 구성된(연결된) 형태로 표현될 수 있음.
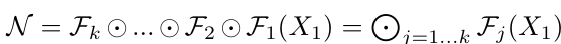
ConvNet layer의 경우 여러 stage로 나뉘고, 같은 stage의 모든 layer는 같은 아키텍처를 공유함.
따라서 하단처럼 ConvNet을 정의할 수 있음.
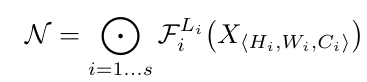
- L_i: stage i에서 layer가 반복되는 횟수
- X_Hi,Wi,Ci: 해당 레이어의 입력 tensor
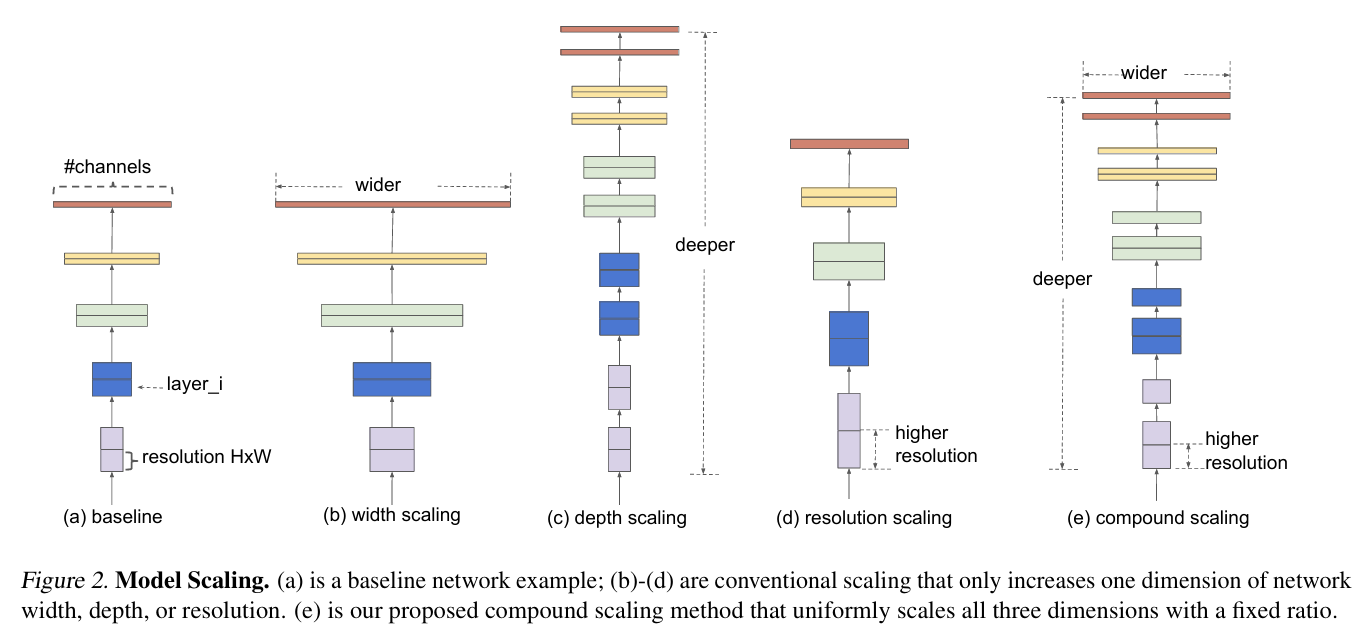
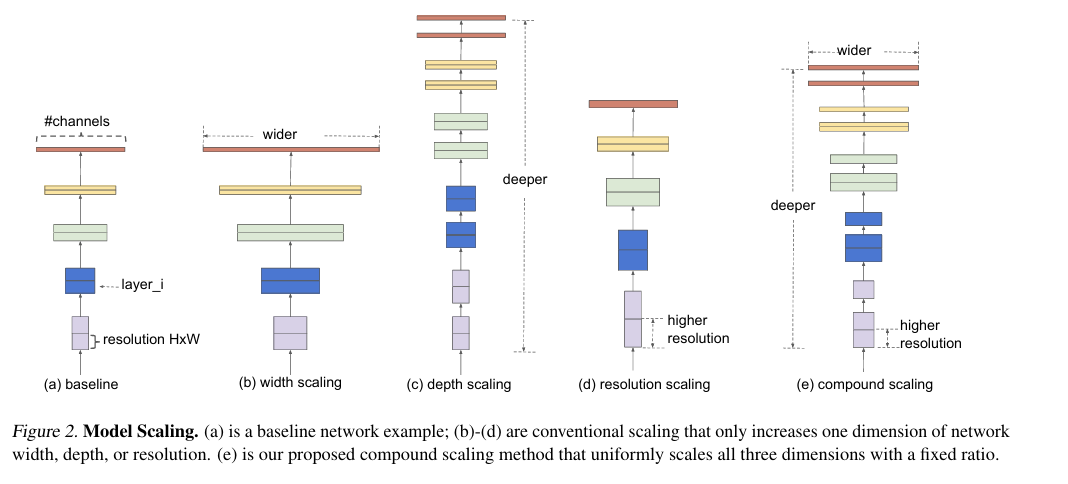
상단에서 확인할 수 있듯, network가 깊어질수록 spatial dimension은 줄어들고, channel dimension은 늘어나는 양상을 보임.
(a): Baseline Network
(b)~(d): 기존의 확장 방식
(e): compound scaling(본 논문 제안 방법)
일반적인 ConvNet 설계는 개별 layer의 F_i를 최적화하는 것이 중심이지만, Model Scaling의 경우, Depth/Width/Resolution(L_i, C_i, H_i, W_i)을 확장하는 것이 중점 사항임.
따라서 Baseline Network를 기반으로 하여 L_i, C_i, H_i, W_i 만을 조정해서 모델을 확장하고자 함.
design space를 줄이기 위해, 모든 layer에서 같은 비율로 확장하기에, 각 layer에 같은 확장 계수를 적용함.
주어진 연산 자원(resource constraints)에서 accuracy를 maximize하는 것이 목표이므로, network width/depth/resolution(w/d/r)을 최적화하는 문제로 define함.

d, w, r은 각 요소의 확장 계수이며, 그 외의 것은 앞서 정의된 값들임.
메모리 사용량과 FLOPS(연산량)에 일정 제한을 둠.
Scaling Dimensions
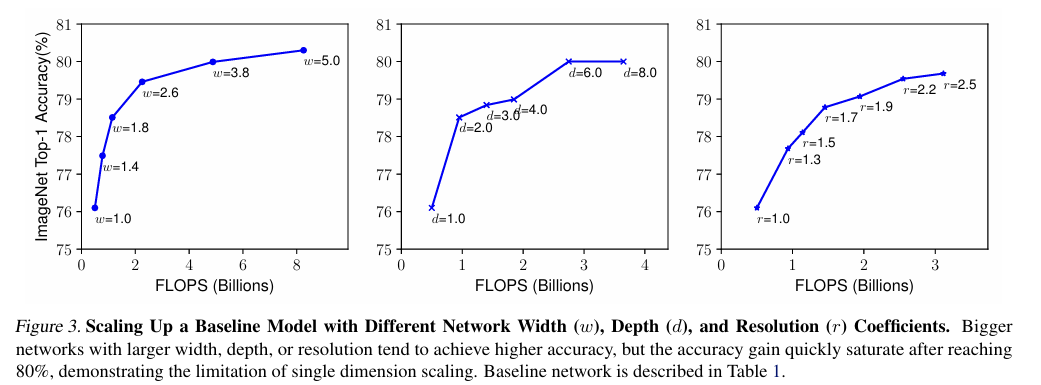 ↑ Scaling Up a Baseline Model with Different Network Width (w), Depth (d), and Resolution (r) Coefficients
↑ Scaling Up a Baseline Model with Different Network Width (w), Depth (d), and Resolution (r) Coefficients
Depth(d)
Depth Scaling은 ConvNet에서 가장 일반적으로 사용되는 방법임.
직관적으로 보자면, Deep ConvNet은 더 Rich & Complex한 Features를 학습할 수 있음.
일반화 성능도 좋아서 새로운 task에 적용하기도 쉬움.
다만, 너무 deep하면, 기울기 소실 문제가 생겨, 학습에 어려움이 있음.
이를 해결하기 위해 Skip connection/Batch Normalization같은 기법이 사용되었음.
하지만, 너무...너무 very deep한 network에서는 accuracy가 둔화되는 양상을 보인다는 한계가 존재함.
Width(w)
Width Scaling은 주로 small size model에서 사용됨.
직관적으로 보면, wider한 network는 더 세세한 features를 학습할 수 있고, 학습하기에도 더 쉬움.
다만, width가 너무 넓고, shallow한 network는 고차원의 features를 학습하기에는 한계가 있음.
width가 너무 넓어지면 accuracy가 일정 수준에서 saturation(포화)됨.
하단 표에서 확인가능하듯, 너무 w값을 늘리면, 어느 순간부터 accuracy 향상이 둔화됨.
Resolution (r)
input images의 resolution을 높이면, 더 세세한 patterns를 포착할 수 있음.
해상도가 높아질수록 accuracy가 향상되긴 하지만, 이 또한 일정 수준 이상에서는 향상 폭이 둔화됨.
결론적으로
w, d, r 중 한 가지만을 확장하면 accuracy는 향상이 되지만, 일정 수준 이상에서는 향상 폭이 점차적으로 둔해지는 Diminishing Returns 현상이 발생하게 됨.
Compound Scaling
Networks의 Scaling Dimensions는 independent하지 않음!
resolution이 높아지면 depth도 증가해야하고(larger receptive field가 필요하기 때문), width도 증가해야 함(더 큰 이미지에서 more pixels를 처리해야 하기 때문).
따라서, Single Dimension Scaling이 아닌, 세 가지 요소들을 균형 있게 조정해야 함.
이것이 바로 Compound Scaling 기법이며,
Compound Coefficient(컴파운드 계수)를 활용해서 network의 w/d/r을 균형 있게 확장하고자 함.
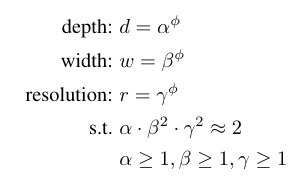
- ϕ: 사용자 지정 계수(coefficient)-얼마나 많은 연산 resource를 사용할지 결정
- α, β, γ: network depth/width/resolution을 확장하는 Scaling Ratio
- FLOPS: Network 연산량이 너무 급격하게 증가하지 않도록, (α•β^2•γ^2)^ϕ≈2^ϕ 이렇게 수식적으로 제약을 두고 최적화를 진행함. (α/β/γ 두 배 늘리면 FLOPS가 2배/4배/4배 증가돼서 저렇게 비율 설정해둔 것)
✅4. EfficientNet Architecture
Model Scaling은 기존 Baseline Network의 F_i(연산자)를 변경하지 않음. 따라서 애초에 Baseline Network를 좋은 것으로 고르는 것이 중요함.
본 연구에서 Scaling method의 effectiveness를 입증하기 위해 새로운 mobile-size baseline인 EfficientNet을 개발했음.
일단 먼저 EfficientNet-B0는 <Tanetal.,2019>연구에서 영감을 받아서 개발된 모델인데, NAS(Multi-Objective Neural Architecture Search, 다중 목표 신경망 아키텍처 검색)를 사용해서 Accuracy와 FLOPS를 동시에 최적화했음.
ACC(m)-[FLOPS(m)/T]^w를 최적화 목표로 두었음.
- ACC(m): 모델 m의 accuracy
- FLOPS(m): 모델 m의 연산량
- T: target FLOPS
- w: -0.07로, accuracy와 FLOPS 간의 trade off를 조절하는 하이퍼파라미터
EfficientNet-B0의 경우, 기존 MnasNet 모델과 비슷한 구조를 갖고 있지만, FLOPS Target과 Accuracy 부분에서 더 높은 성능을 내기 위해 설계됨.
특히, MBConv(Mobile Inverted Bottleneck Block)과 Squeeze and Excitation 모듈을 사용하여, 더 적은 연산으로도 성능을 유지하고(MBConv), 네트워크의 중요한 feature를 더 잘 학습할 수 있도록 하여 더 높은 성능을 도출할 수 있게 함(Squeeze and Excitation).
그리고, EfficientNet-B0을 기반으로 compound scaling을 통해 B1~B7으로 확장하였음.
STEP 1
먼저 ϕ=1로 설정하고, 두 배의 연산 resources가 주어진다고 가정 후, 작은 범위에서 최적의 확장 계수인 α,β,γ을 찾음.
그 후, 앞서 언급된 수식을 기반으로 최적의 값들을 찾음(α=1.2/β=1.1/γ=1.15).
그리고
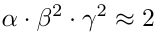 위 조건을 통해 모델 확장 시 FLOPS가 급작스럽게 증가하지 않도록 조절함.
위 조건을 통해 모델 확장 시 FLOPS가 급작스럽게 증가하지 않도록 조절함.
STEP 2
앞서 상수를 "α=1.2/β=1.1/γ=1.15" 이렇게 고정한 후, 같은 확장 계수를 사용해서 B1~B7을 생성함.
이는 B0(small baseline network)에서 한 번만 search를 한 후, 같은 확장 비로 나머지 모델(B1~B7)을 생성하게 되는 것.
따라서 FLOPS가 급격하게 증가하지도 않으면서, 균형 있는 모델 확장이 가능하게 됨.
✅5. Experiment
Scaling Up MobileNets and ResNets
MobileNets과 ResNets에 해당 compound scaling 기법을 적용하는 실험을 진행함.
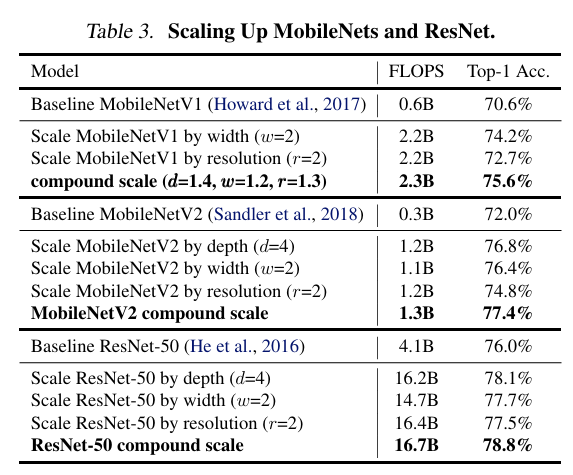
결과적으로 single-dimension scaling methods와 비교했을 때, compound scaling 방법이 모든 모델에서 더 높은 accuracy를 도출했음.
따라서 해당 기법이 다양한 ConvNets에서 효과적임을 확인할 수 있음.
ImageNet Results for EfficientNet
ImageNet 데이터셋에서 EfficientNet 모델을 학습해보는 실험을 진행함.
-
RMSProp optimizer
-
Decay = 0.9
-
Momentum = 0.9
-
batchnorm momentum = 0.99
-
weight decay = 1e-5
-
Learning Rate: 0.256(2.4epoch마다 0.97배 감소)
-
SiLU(Swish-1)activation 사용
-
AutoAugment(데이터 증강 기법) 적용
-
Stochastic Depth(확률적 깊이 기법) 적용
-
모델 bigger → Regularization 필요 → Dropout 비율 증가시킴
-
Early Stopping 적용
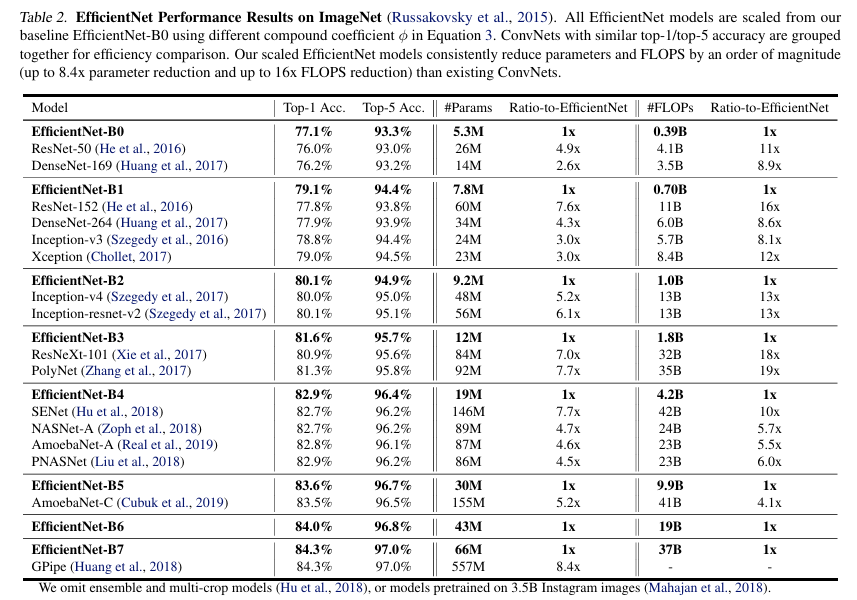
결과적으로, EfficientNet은 기존 ConvNet 모델보다 적은 파라미터와 FLOPS로 더 나은 accuracy를 달성함.
EfficientNet-B7의 경우, top1 accuracy를 달성하며 기존 최고 best 모델인 GPipe보다 8.4배 더 작은 모델을 구현한 것.
위와 같은 성능 향상은
↓↓↓
better architectures
better scaling
better training settings
↑↑↑
덕분이라고 볼 수 있음.
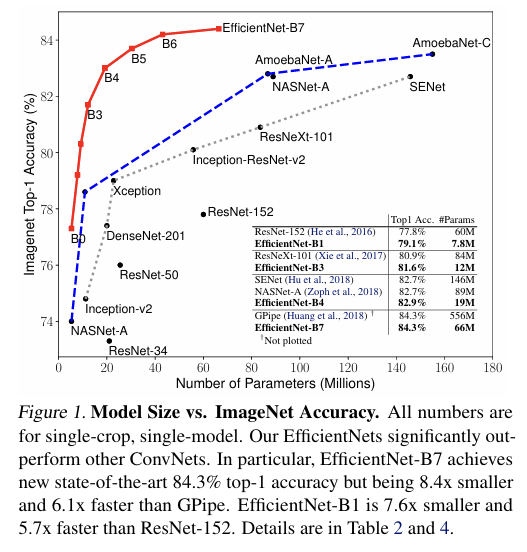
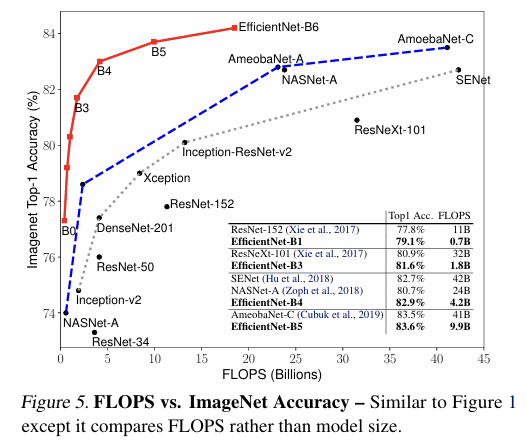
위 table을 통해 다양한 ConvNet과 EfficientNet를 비교해보았음.
결과적으로 EfficientNet이 기존 타 모델들에 비해 FLOPS와 파라미터가 적으면서도, 그 이상의 accuracy를 구현해냄.

EfficientNet의 실제 속도 평가를 위해, 타 ConvNet 모델들과 inference latency(추론 속도)를 측정했음.
결과적으로 EfficientNet-B1/B7이 기존 타 모델에 비해 아주 빠른 속도를 보임을 확인할 수 있었음.
Transfer Learning Results for EfficientNet
EfficientNet이 다양한 Transfer Learning(전이 학습) 데이터셋에서 얼마나 잘 작동하는지도 실험함.
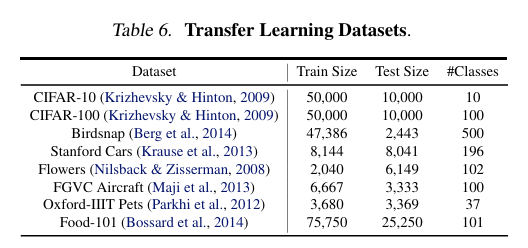 ↑ Transfer Learning Datasets
↑ Transfer Learning Datasets
ImageNet에서 pre-trained를 진행한 후, 새로운 dataset에서 fine-tuning을 하여 성능을 확인했음.
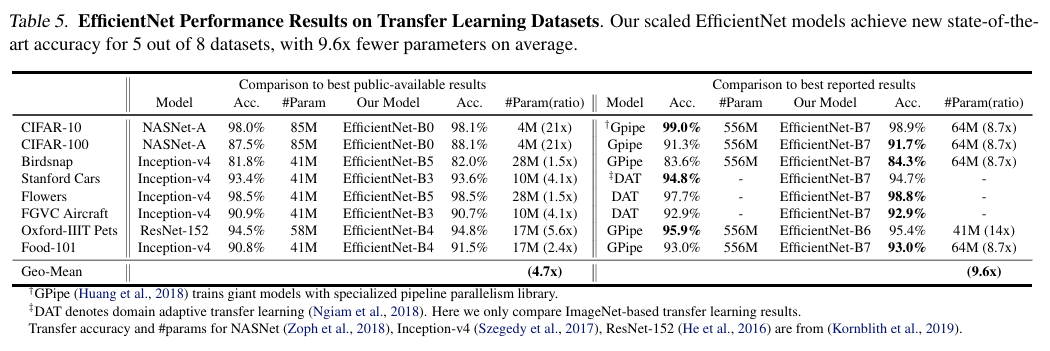 ↑ EfficientNet Performance Results on Transfer Learning Datasets
↑ EfficientNet Performance Results on Transfer Learning Datasets
결과적으로 EfficientNet은 기존 모델 NASNet-A & Inception-v4에 비해 우수한 성능을 내었음.
또한, 최신 SOTA 모델인 GPipe & DAT과 성능 비교도 진행했으며, 결과적으로 8개 데이터셋 중 5개에서 더 높은 accuracy를 보임.
전체적으로, 연산량과 파라미터를 줄이면서도 높은 accuracy를 보이는 모델임을 확인할 수 있었음.
✅6. Discussion
EfficientNet의 성능 향상에 scaling method가 어떤 기여를 했는지를 분석하고자, 하단 표처럼 EfficientNet-B0을 기반으로 다양한 scaling method를 적용했음.
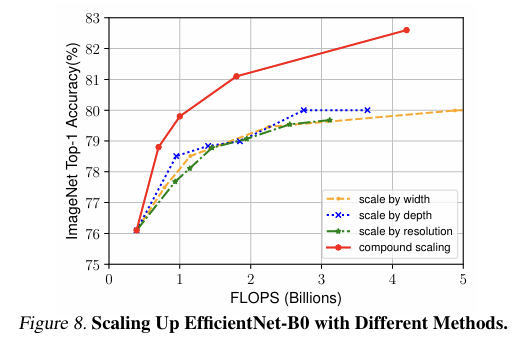
결과적으로, FLOPS이 증가함에 따라서 모든 methods가 accuracy 향상을 이루어 냈으나, Compound Scaling이 Single Scaling보다 더 높은 accuracy를 기록함.
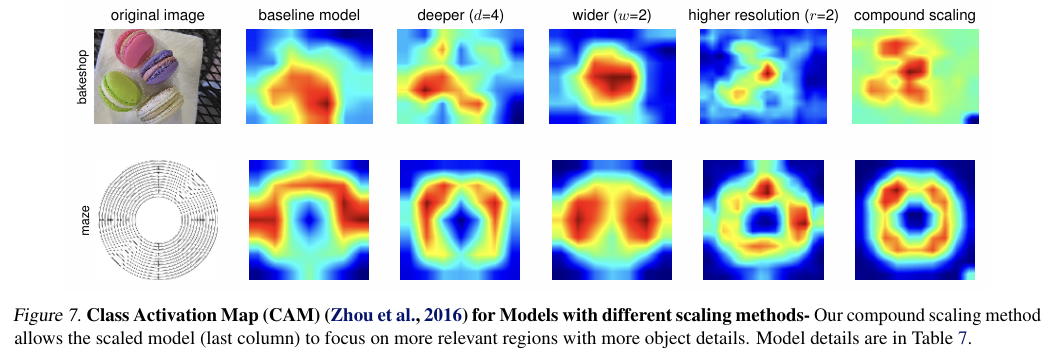
왜 compound scaling method가 더 나은 방법인지 이해하기 위해, CAM(class activation map, 모델이 이미지의 어떤 부분을 중점으로 보는지 확인 가능)을 비교했음.
결과적으로, Compound Scaling 모델이 relevant regions를 더 집중적으로 학습하고, object의 details를 더 잘 포착함.
🔚7. Conclusion
본 논문에서는 ConvNet의 Scaling 방법을 연구했으며, Network의 너비(Width), 깊이(Depth), 해상도(Resolution) 각 세 요소를 균형 있게 조절하는 것이 중요함을 확인했음.
Compound Scaling 기법을 활용하여 특정한 연산 Resource 안에서 모델을 효율적으로 Scale up 할 수 있었음.
다양한 ConvNet 모델과 비교했을 때, 적은 파라미터와 FLOPS로도 더 높은 accuracy를 보였음.
즉, EfficientNet은 기존 모델들보다 성능과 효율성 부분 모두에서 뛰어난 결과를 보임.
