Paper: U-Net: Convolutional Networks for Biomedical Image Segmentation
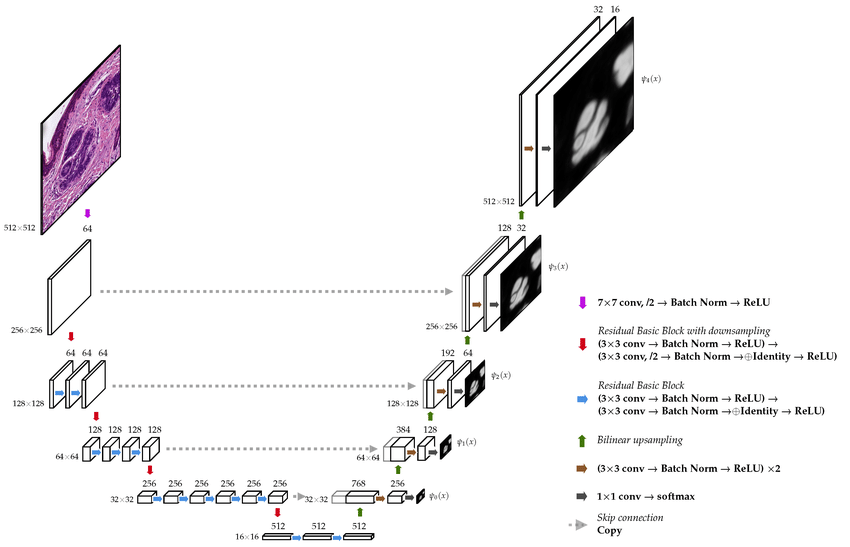
🔍0. Background
Classification & Semantic Segmentation
기존의 딥러닝 모델
: 주로 이미지 전체에 1개의 정답을 예측하는 데 사용되었음.
(ex. 개 ? 고양이 ? 사람 ?)
이는 이미지를 전체적으로 하나의 class로 분류하는 데 적합한 방법임.
이것이 Classification.
다만, 딥러닝이 다양한 field에서 사용되고, 발전함에 따라...
의료 영상 분야에서는 단순 class 분류만으로는 부족함.
훨씬 더 정교하고 정확한 예측이 필요함.
(ex. 종양이 '어디에' 있는지, '어떤 크기로' 있는지 등)
이럴 때 쓰이는 것이 Semantic Segmentation.
= 이미지 내 모든 픽셀 하나하나마다 어떤 class에 속하는지 예측함.
(ex. 이 픽셀은 종양이다. 이 픽셀은 배경이다. 등)
🔍1. Introduction
Deep convolution networks는 최근 많은 visual recognition task에서 높은 성과를 보여옴.
단, convolutional networks는 사용 가능한 데이터셋의 크기와, 네트워크 구조의 한계가 있었음.
이는, krizhevsky의 연구(AlexNET)를 통해 ImageNet 데이터셋에서 8개 layer와 수백만 개 parameters를 가진 대규모 네트워크를 훈련하여 극복할 수 있었고, 이 이후로 더 크고, 깊은 신경망이 훈련되어 왔음.
일반적으로, Convolutional networks는 classification tasks(분류 작업)에 사용됨.
이는 이미지에 single class label을 출력함.(ex. 개 or 고양이 구분 → '개'라는 하나의 클래스 label을 출력 = 이미지의 전반적인 영역에서 분류 작업을 하는 것. 이미지 내의 개별 픽셀이나 부분 정보에 대해서는 고려 X)
하지만, Biomedical image processing(의료 영상 처리)같은 분야의 visual task에서는 각 픽셀에 클래스 라벨을 할당해야 하는 'localization이 포함된 output'을 필요로 함. 또한, 의료 영상 처리 task의 경우, 수천 장의 학습 이미지를 얻는 것이 현실적으로 어렵다는 문제 존재.
그래서, sliding-window(슬라이딩 윈도우)텍스트 방식의 네트워크를 훈련시켜 문제를 해결하고자 했음.
픽셀 주변 local region(patch)을 input으로 써서 각 픽셀의 클래스 라벨을 예측하고자 함.
→ localization 수행 가능했고, patch 단위의 학습 데이터는 실제 학습 이미지 수보다 더 많았음.
→ 이 network는 ISBI 2012의 EM segmentation 부문에서 우승함.
다만, 이 방법에는 두 가지 문제가 존재함.
1. 속도가 느림
: network가 각 patch에 대해서 따로따로 실행되어야 하기 때문에, 속도가 꽤 느림.
2. trade-off 문제
: localization 정확도와 context 사용 간 trade-off 현상 문제가 존재함.
- 큰 patches에서는 더 많은 max-pooling layer가 필요하고, 이는 동시에 localization 정확도를 떨어뜨림
- 작은 patches에서는 network가 작은 context만 볼 수 있음
→ 이후 여러 layer에서 feature를 결합해서 분류 output을 내는 방법을 제시함.
→ Localization과 Context 사용을 동시에 향상시킴.
본 논문에서는, Fully Convolution Network(FCN) 아키텍처를 기반으로, 아주 적은 훈련 이미지를 사용하며, 더 정밀한 segmentation(세분화)를 할 수 있도록 개선했음.
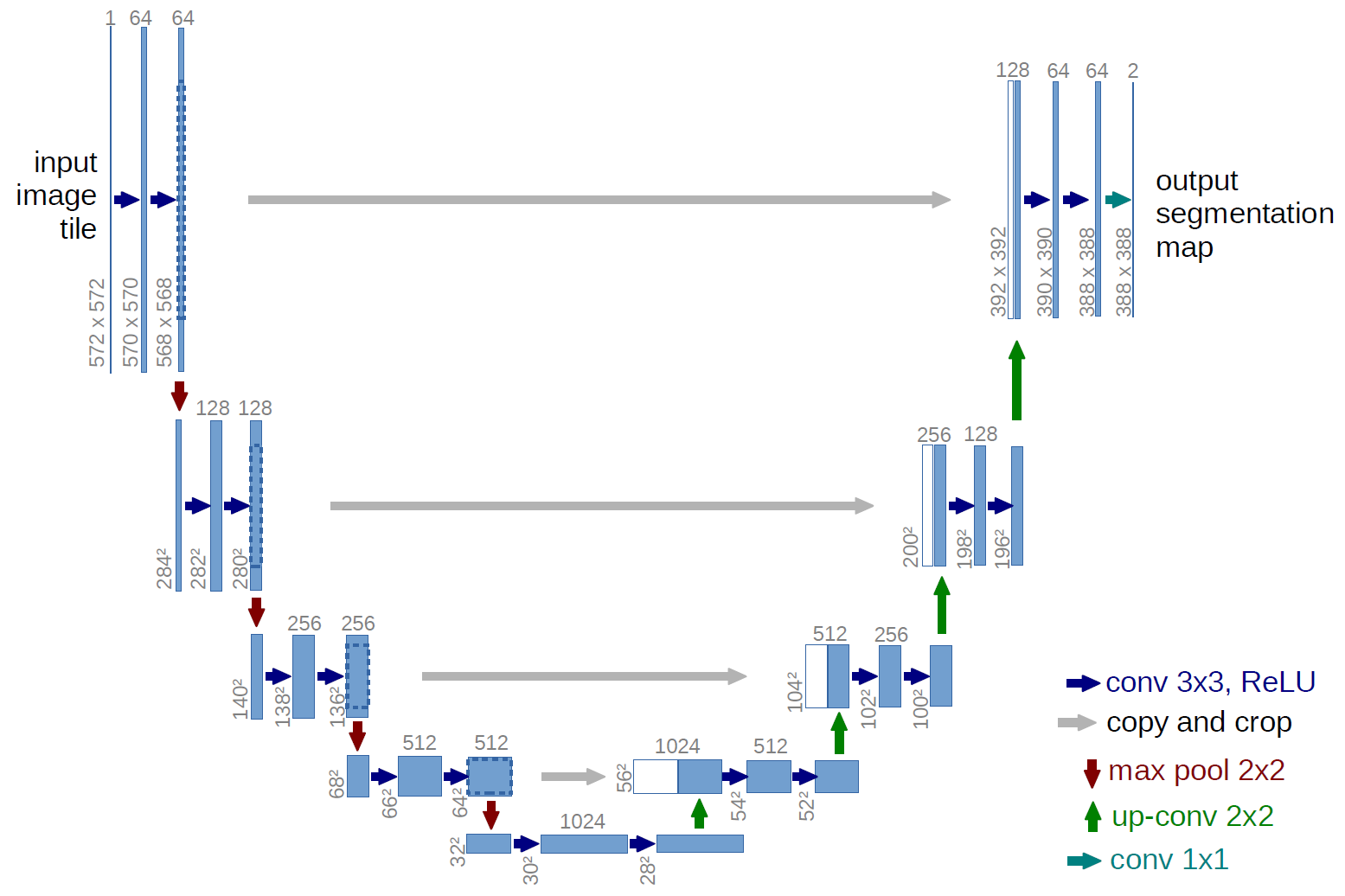 ↑ U-net architecture(ex. 32 X 32 pixel)
↑ U-net architecture(ex. 32 X 32 pixel)
- blue box: multi-channel 피처 맵
- box 위에 표시된 수: 각 채널 수
- box 좌측 하단에 표시된 수: x-y 크기. 각 피처 맵이 몇 pixel로 구성되어 있는지 확인 가능.
- white box: copied 피처 맵(이전 경로에서 추출된 피처맵)
- arrow: 각각의 different operation
기존 아키텍처에서는 일반적인 contracting network(수축 network)에 연속된 layer를 추가해서, pooling operators를 upsampling operators로 대체하는 것임.
이를 통해, output의 해상도를 높일 수 있음.
그리고, localization을 하기 위해, contracting path의 고해상도 feature를 upsampling한 output과 결합.
이렇게 되면, 연속적인 convolution layer는 이 정보를 기반으로 더 정밀한 output을 생성할 수 있음.
U-Net, 업샘플링 단계에서의 수정(개선) 사항
-
업샘플링 단계에서 많은 피처 채널을 추가해서, 네트워크가 context information을 더 높은 해상도 layers로 전달할 수 있음.
그렇게 되면, 업샘플링 단계와 contracting path가 대칭형이 되어서, U자형의 아키텍처를 만들게 됨. -
이 네트워크에는 fully connected layers가 없고, 각 합성곱 연산에서 valid한 부분에서만 사용.
즉, segmentation map이 input image에서 모든 context를 활용할 수 있는 픽셀만 포함한다는 것.
→ overlap-tile strategy*를 통해 임의의 큰 이미지를 seamlessly(균일하게) segmentation할 수 있도록 함.
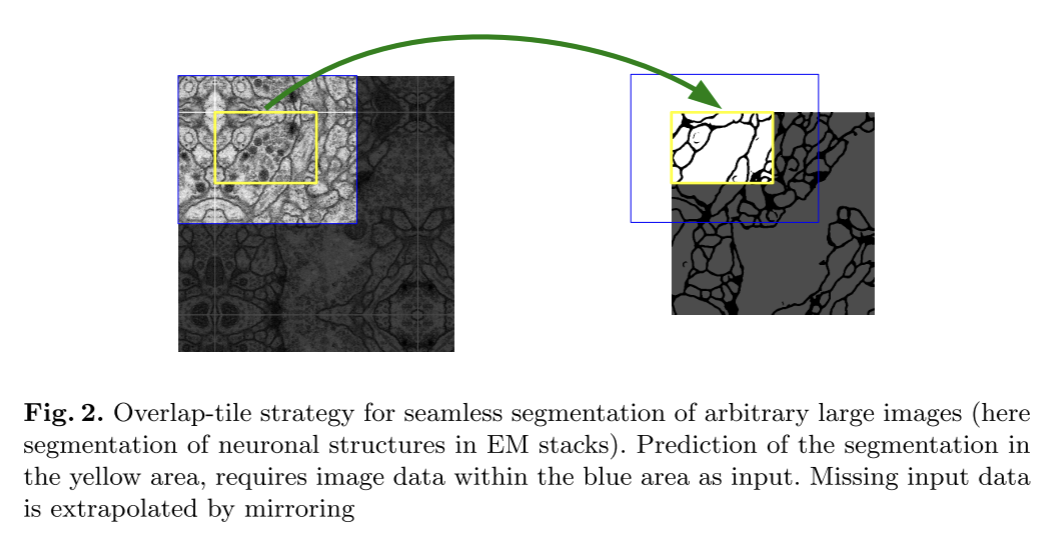
overlap-tile strategy*
: 임의의 크기를 가진 이미지를 끊김 없이 segmentation할 수 있는 방법으로, 큰 이미지를 여러 개 작은 tile로 나누어서, 타일 간 경계를 고려해서 overlap 시키는 방식.
경계 pixel 예측 시 부족한 context(데이터 좀 부족한 영역에서)는 input 이미지를 mirroring(거울 대칭)해서 보완. GPU 메모리 제한된 환경에서도 이미지 크기 상관 없이 높은 해상도/정확도로 이미지 처리 가능.
-
Biomedical tasks에서는 사용 가능한 학습 데이터 수가 적음. 따라서 elastic deformations(탄성 변형)를 적용해서, data augmentation 진행
→ network가 해당 변형에 대해 invariance(불변성) 학습하게 되는 것
→ Biomedical segmentation에서 흔한 tissue(조직) 변형을 효율적으로 시뮬레이션 할 수 있으니, 효과적임 -
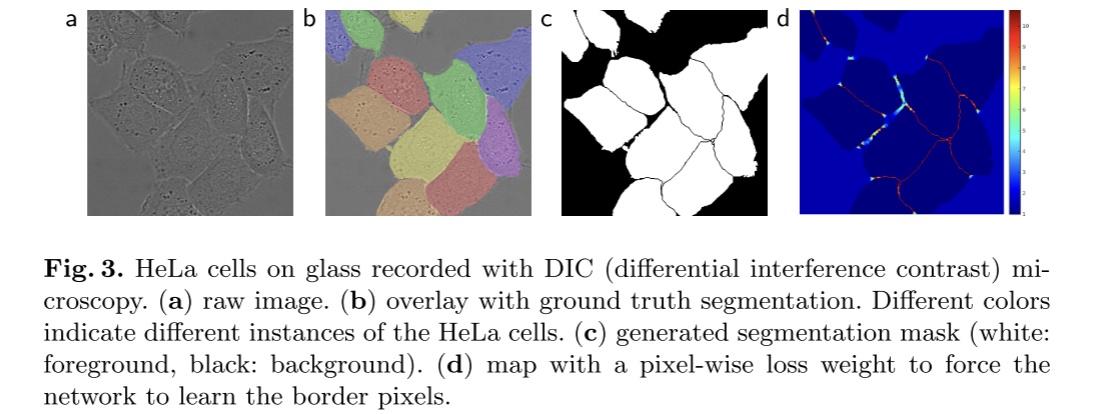
Cell segmentation tasks에서는 같은 class의 touching objects(접촉하는 객체)를 분리하는 것이 중요.
따라서 weighted loss(가중치 손실 함수) 를 통해, 접촉하는 세포(객체) 사이를 구분하는 배경 labels에 높은 weight를 부여하여 해결함.
결과적으로 해당 방법이 다양한 Biomedical Segmentation 문제를 해결하는데 활용됨.
성능도 높고, 대회에서도 훌륭한 성과로 우승을 하기도 함.
✅2. Network Architecture
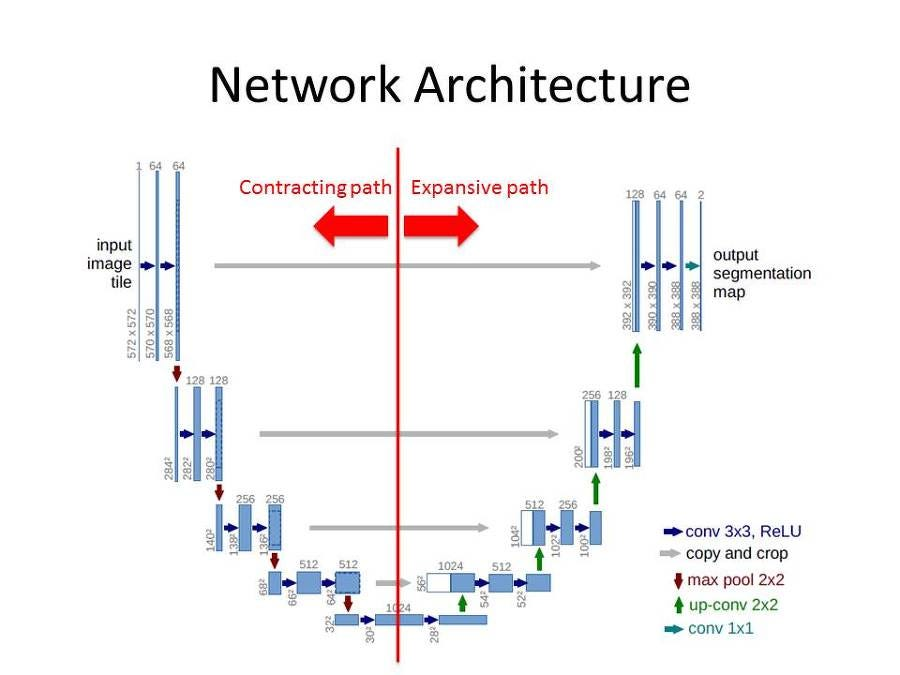
↑ U-net architecture(ex. 32 X 32 pixel)
네트워크 아키텍처를 살펴보자면,
좌측 contracting path(수축 경로) & 우측 expansive path(확장 경로)로 구성.
contracting path(수축 경로-특징 추출)
- 일반적인 합성곱 신경망 구조
- 3 X 3 convolution 2번 적용하고, 이 각각은 ReLU 활성화 함수로 이어짐
- 2 X 2 max pooling(stride=2)을 통해서 downsampling 진행
- downsampling 마다 feature channels 수 2배 증가
expansive path(확장 경로-해상도 복원)
- upsampling을 통해서 2 X 2 up-convolution 진행하고,feature channel 수 반으로 줄임
- 이때, 수축 경로에서 cropped된 feature map과 결합함
- 그 후에, 3 X 3 convolution 적용하고, 이 각각은 ReLU 활성화 함수로 이어짐
- cropping은 컨볼루션마다 테두리 pixel이 손실되기 때문에 필요함.
final layer
1 X 1 convolution을 사용해서 각 64차원 특징 벡터를 필요한 클래스 개수로 mapping.
총 network는 23개의 convolutional layers.
tiling할 때, output segmentation map을 매끄럽게 처리하려면, input tile size를 잘 선택해야 함.
모든 max-pooling 연산이 x와 y size가 짝수인 layer에 적용되도록 input tile size를 설정해야한다는 것. (U-Net에서 2 X 2 max-pooling이 기본적으로 쓰이는 편이라)
✅3. Training
- input 이미지와 이의 segmentation map이 network를 훈련하는데에 쓰임. 훈련에서는 SGD(Stochastic Gradient Descent, 확률적 경사 하강법) 사용.
- padding을 하지 않는 convolution을 사용하기 때문에, output 이미지 크기가, input 이미지 크기보다 작아짐.(가장자리 크기 만큼)
- GPU 메모리 효율성을 위해서 large input tiles 사용하고, 대신 batch size는 single image로 설정.
- 높은 momentum(0.99)를 사용해서 이전 학습 samples의 기울기가 현재 optimization step에 많은 영향을 미치도록 함. (작은 배치 사이즈 한계 보완)
Energy Function
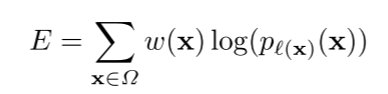
에너지 함수는 최종 feature map에 대해 pixel 단위로 soft-max 계산하고, 이걸 cross entropy loss function이랑 결합한 것을 뜻함.
soft-max
pixel 위치 x ∈ Ω에서 feature 채널 k의 a_k(x)를 기반으로 확률 p_k(x)를 계산함.
- a_k(x): pixel 위치 x에서 채널 k의 활성값
- K: 클래스 총 개수
- p_k(x): 최대 함수 근사값-pixel 위치 x에서 클래스 k에 속할 확률)
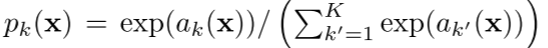
p_k(x) ≈ 1은 class k가 해당 pixel 활성값이 가장 높은 class임을 의미.
cross entropy
각 pixel에서 p_l(x)(X)가 실제 label l(x)와 얼마나 일치하는지를 평가함.
- l(x): pixel x의 실제 label
- w(x): pixel x에 대한 weight map(가중치 맵).
- 특정 pixel에 더 중요도를 부여함.
- 클래스 간 pixel 빈도 차이를 해결함
- touching cells 간 small separation borders를 학습하도록 함. (세포 간 경계 학습)(separation borders는 morphological operations(형태학적 연산)를 사용해서 계산. touching objects 간 분리 명확히 학습 가능.)
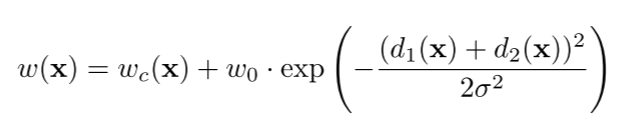 ↑ weight map 수식
↑ weight map 수식
-w_0: 가중치 기본값
- σ: 표준편차
- d_1: pixel x로부터 가장 가까운 객체 경계까지의 거리
- d_2: pixel x로부터 가장 가까운 객체 경계까지의 거리
Data Augmentation
Data Augmentation는 적은 수의 학습 sample로도 network가 invariance(불변성) & robustness(강인성)을 학습하라 수 있도록 하기 위해 필수적임.
microscopical images에서는 shift(이동) & rotation(회전)에 대해 불변성을 가져야하고, deformation(변형) & gray value(gray scale 값) 변화에 대해서 강인성을 가져야 함.
random elastic deformations(랜덤 탄성 변형)는 미세한 영상 segmentation 작업에서 network 성능 극대화를 위한 핵심 기법임. 이미지가 적어도 network가 다양한 변형에 대해 강인하도록 학습시킴.(ex. 세포 조직이 왜곡/변형된 이미지도 처리를 정확히 잘할 수 있는 것. 세포에서는 조직 왜곡/변형/기형 현상이 흔해서 이런 작업을 해서 성능을 높이도록 함)

Drop-out layer는 수축 경로에서 data augmentation의 역할을 하며 network의 성능을 향상시킴.
✅4. Experiments
본 실험에서는 U-Net을 3가지의 segmentation tasks에 적용하였음.
(1) Segmentation of neuronal structures in electron microscopic recordings
전자 현미경 기록에서 neuronal structures(신경 구조)를 세분화하는 것.
- EM segmentation challenge 데이터셋 기반
- 초파리의 VNC(ventral nerve cord, 복부 신경관)에서 얻은 연속 단면 전자 현미경 이미지 사용
- 학습 세트: 이미지 30장(512 X 512 pixel size)
- segmentation map은 완전하게 label 지정된 상태임
- cell(세포): 흰색
- membrane(막): 검은색 - Warping Error/Rand Error/Pixel Error로 Error 계산
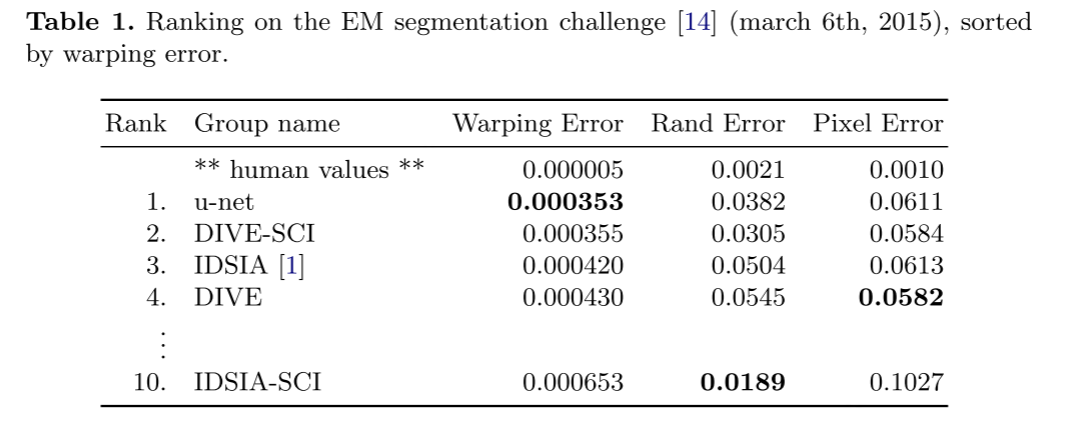 ↑ Ranking on the EM segmentation challenge
↑ Ranking on the EM segmentation challenge
결과적으로, input data를 7가지 회전 버전으로 평균화했더니,
추가 전/후처리 없이 Warping Error: 0.0003529/Rand Error: 0.0382라는 성능을 기록함.
Rand Error가 다른 알고리즘에 비해 성능이 좋지 못하지만, 다른 알고리즘들은 U-Net과 달리 후처리 기법을 사용했음.
(2) cell segmentation task in light microscopic images
light microscopic images(광학 현미경 이미지)에서 cell segmentation을 작업을 수행하는 데에도 사용됨.
첫 번째 데이터 셋 - < PhC-U373 >
- 데이터 셋 PhC-U373 사용
- Glioblastoma-astrocytoma U373 cells 데이터를 위상차 현미경으로 촬영한 데이터. polyacrylimide 기질 위 세포가 촬영된 이미지.
- 학습 세트: 이미지 35장. 부분적으로 label 지정된 상태(partially annotated)
두 번째 데이터 셋 - < DIC-HeLa >
- 데이터 셋 DIC-HeLa 사용
- DIC(differential interference contrast) Microscopy(차등 간섭 현미경)으로 촬영된 falt-glass 위의 HeLa 세포 이미지
- 학습 세트: 이미지 20장. 부분적으로 label 지정된 상태(partially annotated)
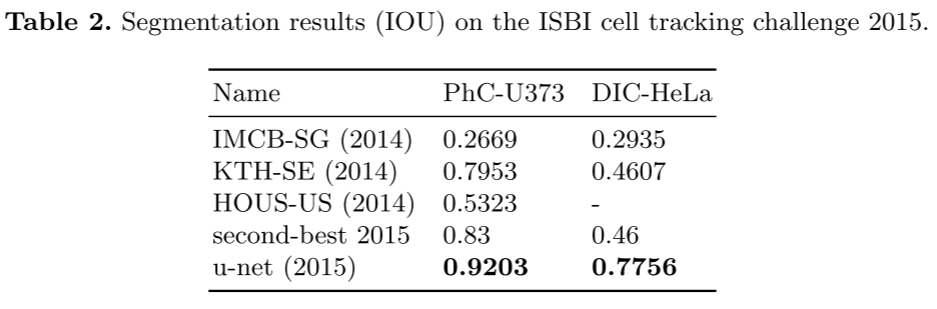
결과적으로,
PhC-U373
평균 IOU(Intersection Over Union, 교집합) 값: 92% 달성.
DIC-HeLa
평균 IOU(Intersection Over Union, 교집합) 값: 77.5% 달성.
두 데이터 셋 모두에서 U-Net이 타 알고리즘 성능에 비해 월등히 뛰어남을 확인할 수 있음.
🔚5. Conclusion
U-Net은 다양한 biomedical segmentation 작업에서 우수한 성능을 보임.
특히 elastic deformations(탄성 변형)를 data augmentation 단계에서 활용하여, annotated image가 적은 상황에서도 우수한 성능을 낼 수 있었음.
🔖6. Reference
