Paper: Rethinking the Inception Architecture for Computer Vision
🔍1. Introduction
AlexNet
- 2012년 ImageNet Competition에서 우승한 모델
- "최초의 딥러닝 혁신 모델"
- 6천만 개의 파라미터 & 계산량 多
- 8개 레이어(5개 컨볼루션 레이어+3개 풀리 커넥티드 레이어)로 구성
VGGNet
- 2014년 ImageNet Competition에서 준우승한 모델
- 간단 & 일관된 구조 → 단순성으로 성능 증대에 기여
- AlexNet보다 성능 우수. But, 계산 비용 & 파라미터 多(1억 3천만 개)
- 16~19개 레이어로 구성
GoogLeNet(Inception v1)
- 2014년 ImageNet Competition에서 우승한 모델(Google에서 개발)
- Inception이라는 독특한 구조의 모듈 사용 → 계산 비용↓ & 성능 ↑
- 500만 개의 파라미터 → 계산 효율성 Good
- 22개의 레이어로 구성
- 효율성 중점으로 설계
Inception v2, v3 ...
- GoogLeNet의 후속 모델
- Inception 계속 발전
- 2,500만 개 이하 파라미터
- 효율성 & 성능 균형에 기여
✅2. General Design Principles
1. Avoid Representational Bottlenecks
"표현 병목*을 피하라(특히 네트워크 초기에!)"
피해야 하는 이유
: 네트워크 초기에 표현 병목 발생 → 정보 손실 ↑ → 학습 & 예측 성능 ↓
고려 사항
- 표현 size는 최종 표현에 도달하기 전, input에서 output으로 갈 수록 "완만하게" 줄여야 함. 극단적 압축 X!!!
- 정보 내용(information content)은 단지 표현의 차원만으로는 평가 불가!
Why?
: 오직 차원만으로는 상관 구조와 같은 중요한 요소를 무시하기 때문.
차원(dimensionality)은 단지 정보 내용의 개략적인 추정에만 도움을 줌.
표현 병목 Representational Bottleneck*
: 네트워크 내에서 데이터를 극단적으로 압축해서 정보 전달이 충분히 되지 못하는 현상
2. Higher dimensional representations
네트워크 내에서, 더 높은 차원의 표현은 local하게 처리가 더 쉬움.
컨볼루션 네트워크에서 tile per activation* 을 늘리면, 분리된 특징을 얻기 더 쉬움
→ 네트워크 학습이 더 빨라짐
tile per activation?(타일 당 활성화 수)*
: tile = CNN에서 이미지 처리 시 작은 부분 조각으로 나누어서 작업함. 이 조각이 tile.
: activation = tile 처리로 인해 생성되는 값, 특징.
=> tile 당 activation을 늘린다? = tile 당 더 많은 출력 채널 수/활성화 값을 생성한다!
→ 더 다양하고 정교하게 데이터 표현 가능(feature들이 독립적으로 분리되기에, 학습도 더 효율적 & 빠름. 신경망이 데이터 이해를 더 잘 할 수 있도록 도와준다~)
3. Spatial aggregation - embedding & representational power
Spatial aggregation(공간적 집계)* 은 낮은 차원 embedding(임베딩)을 사용해도 representational power(표현 능력)에 큰 손실 없이 수행 가능.
즉, 컨볼루션을 축소해도, 표현력을 크게 잃지 않고, 정보를 효과적으로 처리할 수 있음.
Why?
: 공간 집계 맥락에서 출력이 사용될 경우, 인접한 유닛 간 강한 상관관계로 인해, 차원이 축소될 때 정보 손실이 줄어들기 때문(중요한 정보는 잘 보존된 상태)
→ 쉽게 압축 가능 → 차원 축소가 학습을 더 빠르게 촉진하는 것.
차원 축소하면? 데이터가 간결해지기에, 학습 속도도 빠르고 효율적임!
Spatial aggregation(공간적 집계)*
: 컨볼루션 네트워크에서 여러 입력 데이터를 공간적으로 통합해서 특징 추출을 하는 과정
4. Balance the width and depth
"신경망의 너비와 깊이 균형을 잘 조절하라!"
신경망에서의 최적의 성능은 단계 당 필터 수(너비)와 신경망의 깊이(층수)를 균형있게 함으로써 달성 가능.
너비와 높이를 병렬적으로 증가하는 것이 가장 최적의 성능 향상 방법임.
따라서 컴퓨팅 파워(계산 자원)는 신경망의 너비와 깊이 간 균형 잡힌 분배를 해야 함.
해당 원칙들을 모호한 상황에서 신중하게 쓰는 것이 중요!
✅3. Factorizing Convolutions with Large Filter Size
Factorization into smaller convolutions
더 작은 컨볼루션으로 분해
5x5, 7x7처럼 큰 공간 필터의 컨볼루션은 계산 관점에서 비쌈.
(예를 들어 5x5 컨볼루션은 같은 필터 수를 사용하는 3x3 컨볼루션에 비해 계산 비용이 2.78배 더 비쌈)
→ 큰 공간 필터의 컨볼루션을 같은 입력 사이즈와 출력 깊이를 가진, 동시에 더 적은 파라미터를 가진 다중 계층 신경망으로 대체할 수 있어야 함.
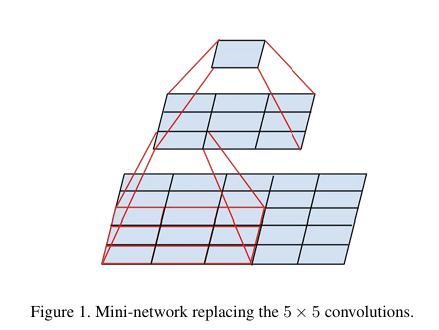 ↑ 5x5 합성곱 연산 그래프인데, 이를 두 계층 합성곱 구조로 대체
↑ 5x5 합성곱 연산 그래프인데, 이를 두 계층 합성곱 구조로 대체
→ 첫 번째 계층: 3x3 합성곱, 두 번째 계층: 3x3 출력 격자 위의 fully connected layer
=> 5x5 합성곱을 3x3 합성곱 두 계층으로 대체하는 것과 동일
인접한 tile 간의 가중치(weights)를 공유하면서 파라미터 수를 확실하게 줄이는 것
=> 계산량 줄이면서, 표현력은 유지. 계산 비용 ↓ 효율성 ↑
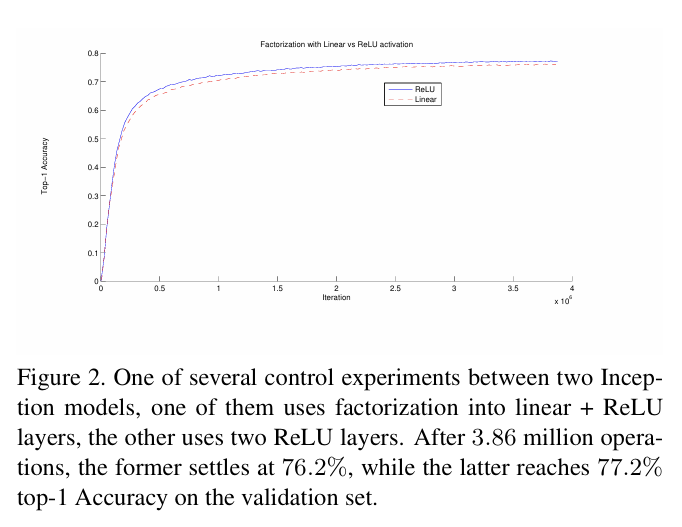 ↑ 두 인셉션 모델 간의 몇몇 제어 실험한 결과
↑ 두 인셉션 모델 간의 몇몇 제어 실험한 결과
빨간색 모델: 선형+ReLU 계층 사용
파란색 모델: RelU+ReLU 계층 2단계 구성
결과적으로,
빨간색 모델: 76.2% 정확도
파란색 모델: 77.2% 정확도 => 성능 더 Good
=> 선형 활성화 대신 ReLU 쓰는 것이 성능이 더 좋음.
ReLU 활용이 네트워크 학습 능력을 더 잘 올릴 수 있도록 기여함.
Spatial Factorization into Asymmetric Convolutions
비대칭 합성곱으로 공간적 분해를!
위에서의 3x3 필터를... 더 작게(ex. 2x2 필터) 분해하는 것은?
!!!다만!!!
2x2 분해보다, 비대칭 합성곱 분해가 더 낫다는 것.
예를 들어, 3x3 필터를
1. 두 개의 2x2 합성곱으로 분해
→ 계산 비용 11% 절감
2. 3x1 + 1x3 비대칭 합성곱으로 분해
→ 계산 비용 33% 절감
=> 비대칭 합성곱이 더 나음
다만, 레이어 초기에서는 잘 작동하지는 않음.
중간 단계에서는 좋은 결과를 도출해냄(ex. mxm 피처 맵에서, m이 12~20 사이인 경우)
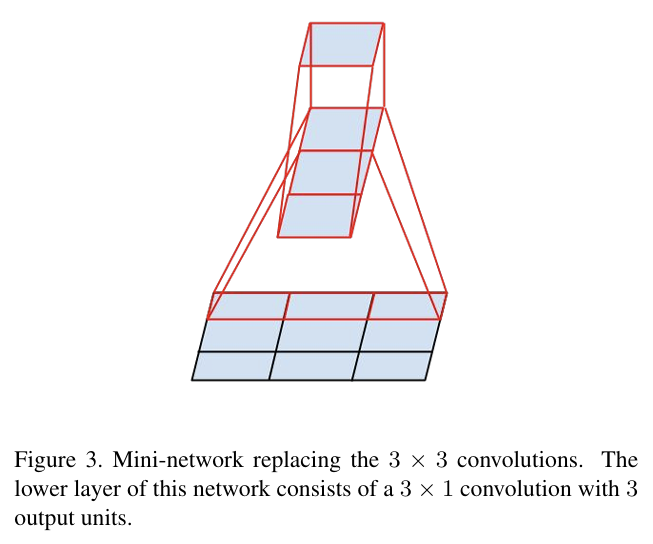 ↑ 원래 인셉션 모듈 구조
↑ 원래 인셉션 모듈 구조
 *↑ 5x5 합성곱을 두 개의 3x3 합성곱으로 대체한 구조
*↑ 5x5 합성곱을 두 개의 3x3 합성곱으로 대체한 구조
✅4. Utility of Auxiliary Classifiers
보조 분류기의 유용성
본래 보조 분류기의 목적
: 유용한 그레디언트를 낮은 레이어까지 전달하여 즉시 유용하게 만드는 것 & 깊은 신경망에서 그래디언트 소실 문제를 방지함으로써 수렴을 향상하는 것
But, 보조 분류기가 학습 초기 단계에서 수렴 개선을 이뤄내지 못함.
학습 후기 단계에 가까워질수록, 보조 분류기를 포함한 신경망이 보조 분류기가 없는 신경망의 정확도 추월... 그리고 정확도가 조금 더 높은 수준에 도달.
더불어 배치 정규화나 드롭 아웃 기법과 함께 사용할 때, 효과가 더 .
✅5. Efficient Grid Size Reduction
효율적인 그리드 사이즈 축소
기존: 합성곱 신경망은 피처맵의 그리드 사이즈를 줄이기 위해서 pooling 연산 사용.
But, 표현 병목이 생겨서, 최대 pooling or 평균 pooling 적용 전, 신경망 필터 수를 늘림.
다만... 계산 비용이 너무 큼.
→ 대안으로 합성곱과 함께 pooling 전환하여 계산량을 1/4로 줄일 수 있음.
다만... 표현 병목으로 인해 신경망 표현력이 감소함.
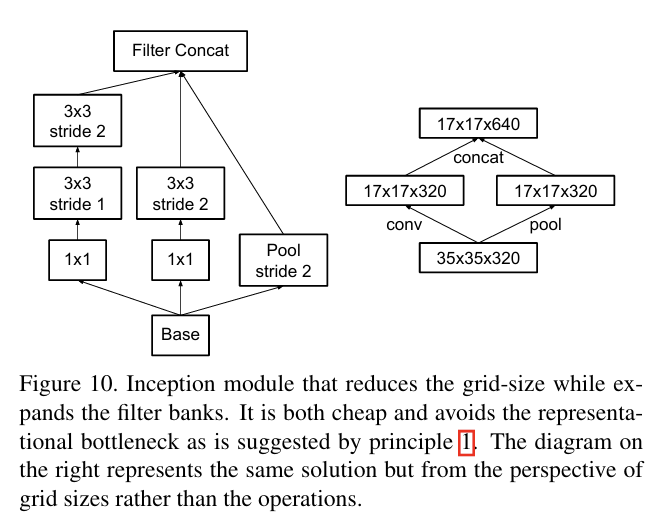
→ 계산 비용 감소 & 표현 병목 제거를 모두 가능하게 하는 방식
stride=2인 block P(pooling layer)와 C(convolution layer) 사용.
pooling과 합성곱을 병렬로 실행한 후, 그 결과를 병합함으로써 계산 비용 감소 & 신경망 표현력 유지 가능!
✅6. Inception-v2
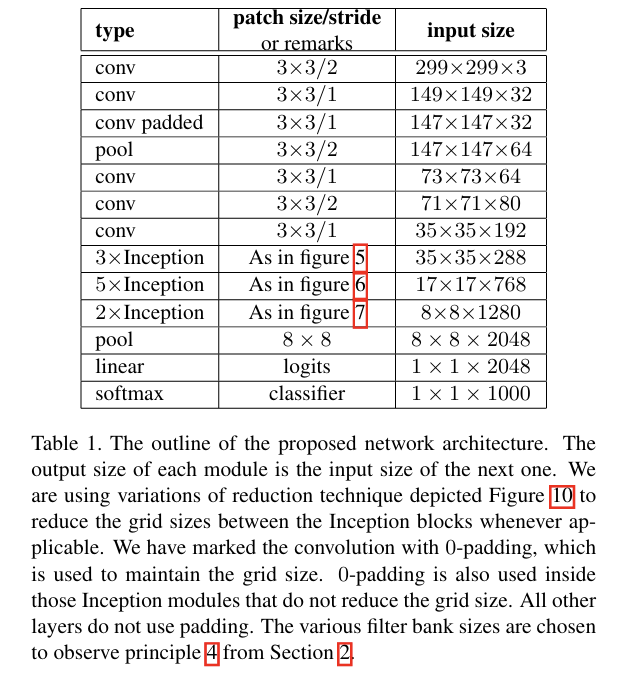 ↑ ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 2012에서 성능이 향상된 새로운 아키텍처 Inception V2
↑ ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 2012에서 성능이 향상된 새로운 아키텍처 Inception V2
<구성>
초기 합성곱 레이어
|
풀링 레이어
|
중간 합성곱 레이어
|
인셉션 모듈
|
풀링 레이어
|
linear logits
|
softmax classifier
큰 크기 필터 분해/그리드 사이즈 축소/zero-padding 사용/비대칭 합성곱/보조 분류기 사용
→ 계산량 축소 및 성능 향상
✅7. Label Smoothing Regularization
라벨 스무딩(Label Smoothing)을 통한 모델 정규화
: 모델이 특정 라벨에 과도하게 자신감을 갖는 것을 막기 위해 Label Smoothing Regularization을 시행
기존 Cross-Entropy
: 정답 레이블이 0 또는 1일 경우, 과적합되기 쉽고, 특정 라벨에 과도하게 자신감을 가짐
→ Label Smoothing Regularization 도입
: 레이블 분포를 수정
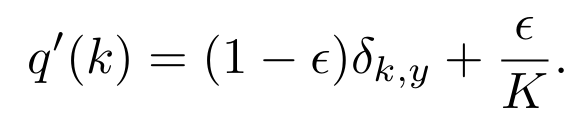 → logit 중 최대값과 나머지 값들의 편차가 과도하게 커지는 것을 방지하여 학습의 안정성을 높이고, 일반화 성능 향상함
→ logit 중 최대값과 나머지 값들의 편차가 과도하게 커지는 것을 방지하여 학습의 안정성을 높이고, 일반화 성능 향상함
✅8. Performance on Lower Resolution Input
낮은 해상도 Inout에서의 성능
: Input 해상도만 높인다고 해서 성능 향상으로 귀결되는 것은 X. 계산량과 모델 용량이 유지되어야 함.
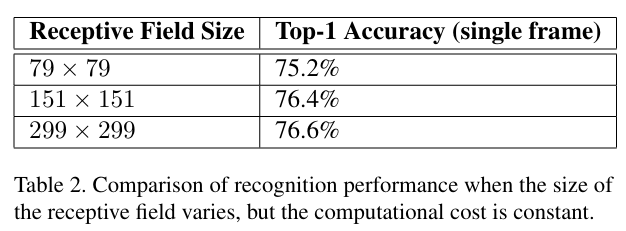
세 번의 Input 해상도 실험을 했는데, 신경망 성능이 해상도가 높을 수록 향상되는 양상이 있지만, 계산 비용은 거의 차이 X.
→ small object 처리 시, high cost & low resolution 신경망 사용하는 것을 고려해 봐야 함
✅9. Experimental Results and Comparisons
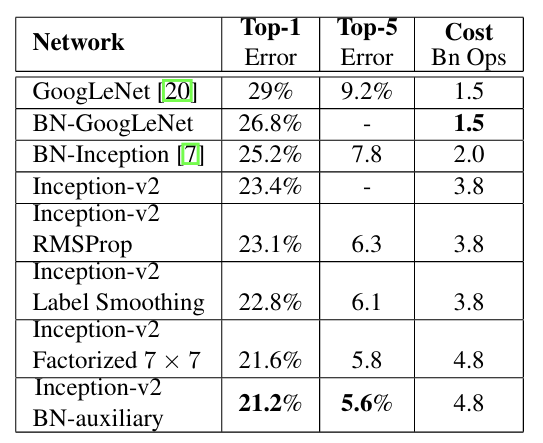 ↑ 누적 성능 실험 결과
↑ 누적 성능 실험 결과
GoogLeNet에서부터 Inception V3까지
신경망에서 각 사항들을 누적해서 적용한 결과, 성능이 향상된 것을 볼 수 있음.
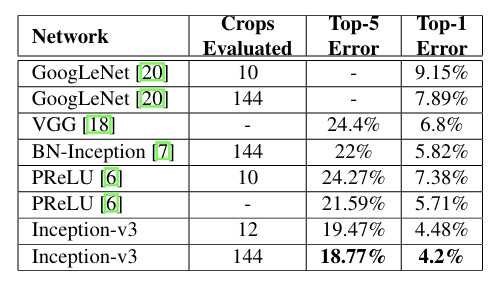 ↑ 멀티 크롭 성능 평가 결과
↑ 멀티 크롭 성능 평가 결과
멀티 크롭 성능 평가 결과에서도 Inception V3는 가장 높은 성능을 기록한 것을 확인할 수 있음.
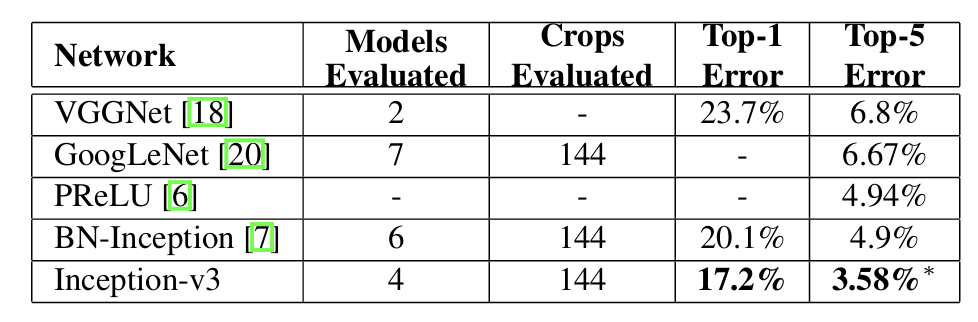 ↑ 앙상블 성능 평가 결과
↑ 앙상블 성능 평가 결과
앙상블 성능 평가 결과에서도 Inception V3가 우수한 성능을 기록한 것을 확인할 수 있음.
🔚10. Conclusions
Inception V3
: 합성곱 분해/신경망 차원 축소를 통해 계산 비용 절감 구현
: 배치 정규화를 적용한 Auxiliary Classifiers(보조 분류기) & Label Smoothing Regularization(라벨 스무딩 정규화) 기법을 활용하여 높은 품질의 신경망 학습 가능
