Paper: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
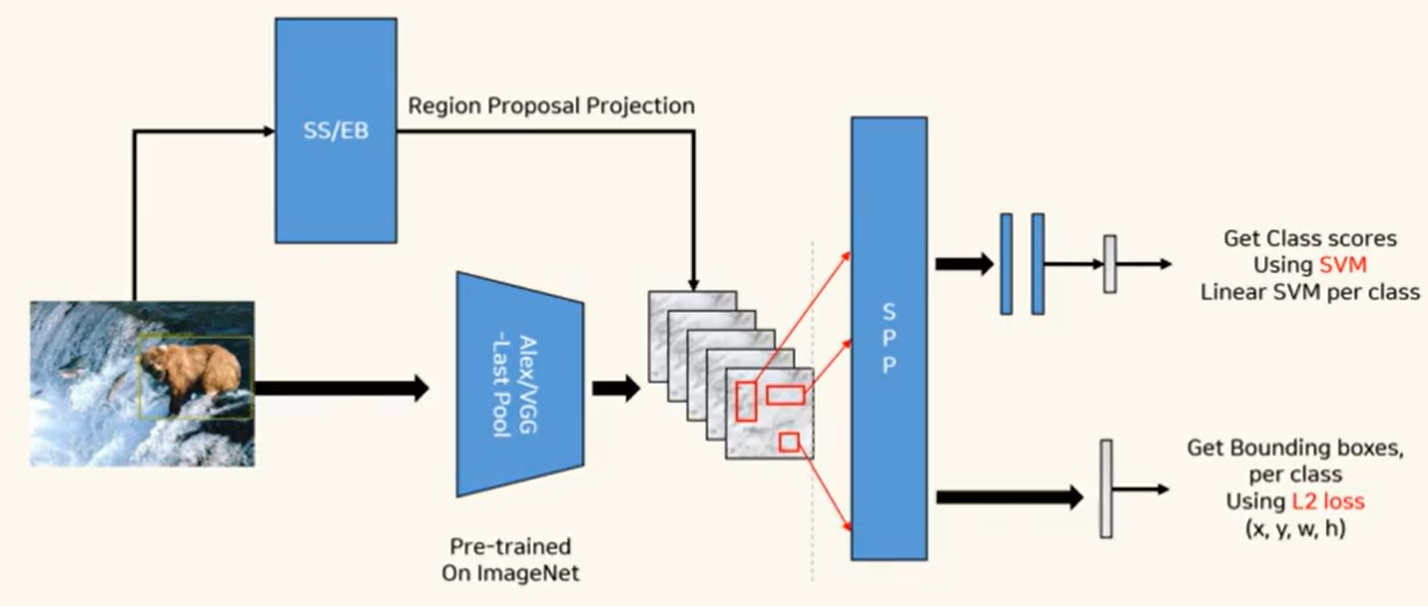
🔍0. Background
BoW(Bag of Words)
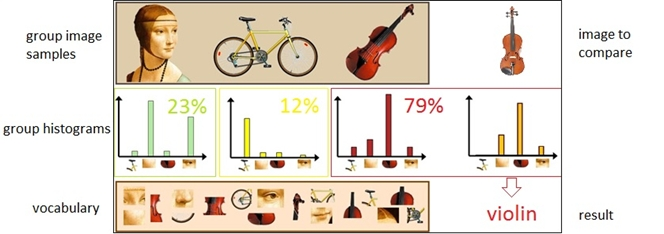
Computer Vision 분야에서 Bag-of-(Visual-)Words 모델
: 이미지의 feature를 'Word'로 취급하여 이미지 classification이나 이미지 검색에 사용할 수 있음.
이미지 내에서 추출한 Word들이 얼마나 자주 등장하는지를 나타내는 vector를 의미함.
(이 등장 횟수를 histogram 형태로 표현하는 것)
다만, BoW 방식의 경우, 이미지에서 뽑아낸 feature의 '등장 횟수'만 세어서 표현한 것이기 때문에, 이미지의 공간적 정보는 무시되었음(무엇이 어디에 있는지). 이렇게 되면, 비슷한 물체가 서로 다른 위치에 있는 경우도 제대로 구분 못하는 상황이 되어버림.
그래서 등장하게 된 것이 Spatial Pyramid Matching.
Spatial Pyramid Matching
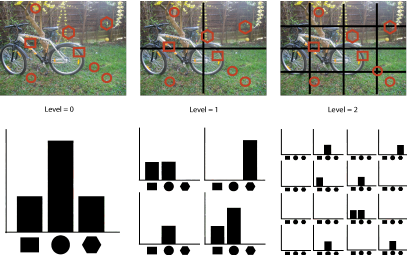
이 방식은 이미지를 단순히 전체 영역으로만 보는 것이 아닌, 여러 단계의 Pyramid 구조로 나눔.
이렇게 되면, 각 영역의 feature를 따로 분석하게 되어서 feature의 spatial 배치도 함께 고려 가능.
ex.
처음: 이미지 하나의 큰 영역으로 봄.
다음: 2x2 grid로 총 4개로 나누어 보고
그 다음: 4x4 grid로 더 작게 나누어 보고
.
.
.
이렇게 해서 큰 영역 → 작은 영역으로 나누면서 특징 추출하는 방식.
- feature 추출 후
- visual word 생성
- spatial pyramid로 image 나누고, 각 영역마다의 visual word를 기반으로 histogram 생성
- 각 level의 histogram을 concatenate(이 과정에서 가중치 부여가 되는데, 더 세분화된 작은 영역에 더 큰 가중치 부여)
- pyramid histogram을 통해서 이미지 간 유사도 계산 및 분류
위와 같은 과정으로 동작한다고 보면 됨.
그러면 Spatial Pyramid Matching과 Spatial Pyramid Pooling의 차이는?
SPM
: 주로 CNN 이전, 전통적인 이미지 특징(SIFT 등)에 사용
이미지를 여러 영역으로 나누고, 영역마다 histogram으로 표현해서 이미지 분류에 활용.
SPP
: 주로 CNN의 마지막 단계에서 사용.
CNN feature 맵을 여러 영역으로 나눠 Pooling을 해서 이미지 size에 관계없이 고정된 특징 벡터를 얻는 방식.
SPM이 전통적 이미지 처리 방식에 쓰였다면, SPP는 CNN(딥러닝)에서 사용하는 방법이라고 생각하면 된다고 함.
🔍1. Introduction
기존 합성곱 신경망의 한계
: 기존 CNN은 고정된 입력 이미지 사이즈* 가 필요했음. (ex. 224x224)
하지만 이는, input 이미지의 비율(ratio)과 크기(scale)에 한계를 줌.
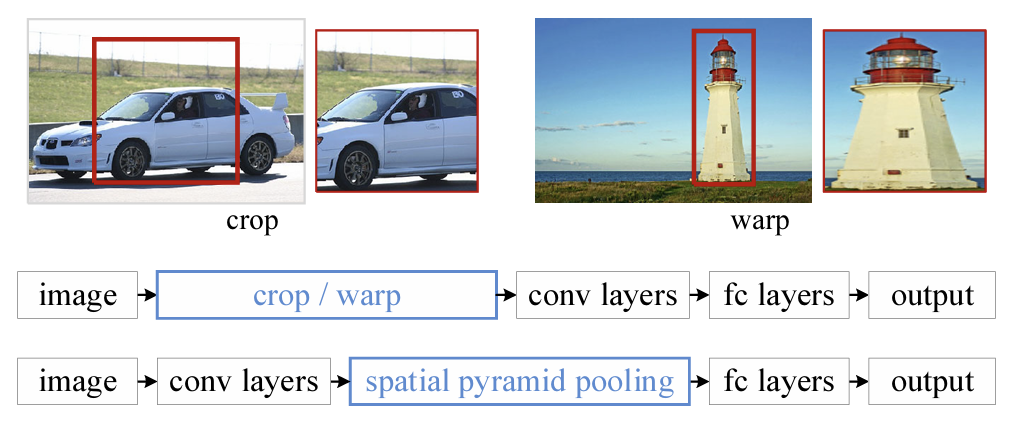 첨부된 사진처럼, 임의의 사이즈의 이미지에 적용할 때, 기존 방법들은 보통 cropping 또는 warping을 통해서 이미지를 fixed size에 맞춤.
첨부된 사진처럼, 임의의 사이즈의 이미지에 적용할 때, 기존 방법들은 보통 cropping 또는 warping을 통해서 이미지를 fixed size에 맞춤.
다만, cropping 방식에서, crop된 부분은 전체 객체를 포함하지 못할 수 있고,
warping 방식에서, warp된 내용들은 원치 않은 기하학적 왜곡을 불러일으킬 수 있음.
→ 인식 정확도가 내용물 손실(content loss)이나 왜곡(distortion)으로 인해 저하될 수 있음.
또한, 미리 지정된 비율은 객체 크기가 다양할 때, 적절하지 않을 수 있음.
고정된 입력 이미지 사이즈
: CNN은 주로 convolution layer와 fully-connected layer로 구성됨
- convolution layer: sliding-window 방식으로 작동. 피처맵 출력, fixed image size를 요구하지 않고, 어떠한 피처맵 사이즈도 만들 수 있음
- fully-connected layer: fixed size/length가 필요함.
→ fixed size 제약은 더 깊은 단계의 신경망에 있는, 오직 "fully-connected layers"에서 발생하는 것
Introduce a SPP(Spatial Pyramid Pooling)
신경망에서의 fixed-size 제약을 없애기 위해, SPP layer를 합성곱 마지막 layer 위에 추가함.
SPP 레이어는 피처를 pooling해서 고정된 길이(fixed length)의 출력을 생성하며, fully connected layer로 전달.
즉, 초기 단계에서 이미지를 cropping하거나 warpping하지 않아도, 신경망 구조의 깊은 단계에서 정보를 종합할 수 있다는 것.
앞서 첨부된 사진을 하단 부분을 통해, SPP 레이어 도입 시 신경망 구조가 어떻게 달라지는지 확인 가능(상단: 기존 CNN, 하단: SPPNet 구조)
SPPNet 특징
- BoW(Bag-of-Words)모델의 확장판
- input size와 상관 없이, 고정된(fixed) 길이의 output 생성 가능
- multi-level spatial bin을 사용함. 이게 객체 변형에 강함
- 다양한 scale에서, input scale의 유연성 덕분에, feature들을 pooling할 수 있음
- 임의 크기의 이미지/윈도우에서 테스트 표현을 생성할 수 있을 뿐만 아니라, 학습 중에도 다양한 size와 scale의 이미지를 처리할 수 있게 함
- 객체 탐지에서도 강점을 보임
- SPPNet은 전체 이미지에서 오직 한 번만 합성곱 레이어를 실행한 후, feature map에서 SPP를 사용해서 feature를 추출함. 따라서 R-CNN의 100배 이상의 속도를 냄
✅2. DEEP NETWORKS WITH SPATIAL PYRAMID POOLING
Convolutional Layers and Feature Maps
fully-connected layer 때문에 심층 신경망은 고정된 이미지 size를 필요로 하는 것.
fully-connected layer가 고정된 길이(fixed-length)의 벡터를 input으로 요구하기 때문.
반면, 합성곱 레이어는 임의의 사이즈 input도 수용 가능. 합성곱 레이어는 sliding filter를 사용하고, output 값은 거의 input과 동일한 비율을 가짐. 이 output이 feature map. feature map의 경우 responses의 강도와 공간적 position을 포함함.
 위 사진을 통해, feature map은 input size를 고정하지 않고, 심층 합성곱 레이어에서 생성됨을 확인할 수 있음.
위 사진을 통해, feature map은 input size를 고정하지 않고, 심층 합성곱 레이어에서 생성됨을 확인할 수 있음.
The Spatial Pyramid Pooling Layer
합성곱 레이어의 output은 가변 size지만, classifiers(SVM, softmax) 또는 fully-connected layer는 고정된 길이의 벡터를 필요로 함.
이러한 벡터들은 Bag-of-Words(BoW)를 통해서 생성될 수 있음.
다만, 앞서 언급되었듯 SPP는 BoW의 개선된 방법이라, local spatial bins에서 pooling을 해서 공간 정보를 유지할 수 있음.
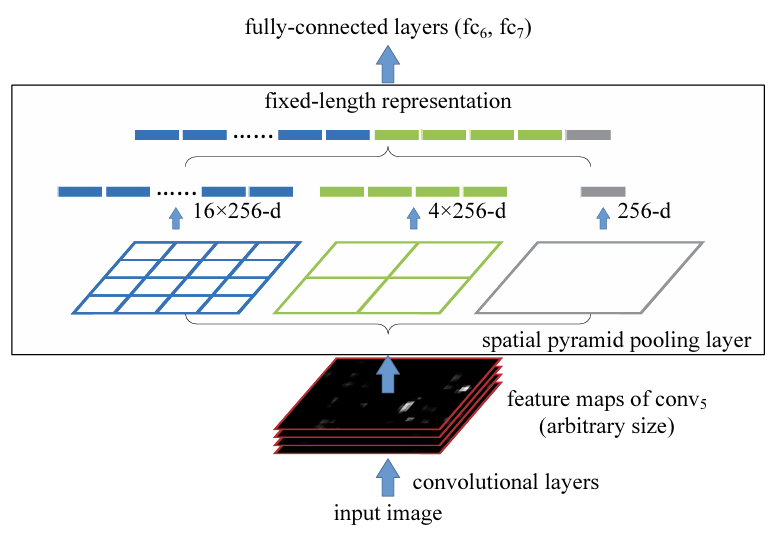 ↑ SPP 레이어를 포함한 신경망 구조
↑ SPP 레이어를 포함한 신경망 구조
임의 사이즈의 이미지 처리를 위해서, 마지막 pooling layer를 SPP layer로 교체함.
SPP layer의 출력은 kM차원의 벡터.(k=마지막 컨볼루션 레이어의 필터 개수, M=bin의 개수)
이 fixed-dimensional vectors가 fully-connected layer의 input으로 사용됨.
SPP 사용 시 input 이미지는 크기에 제한받지 않기에, 입력 이미지가 어떤 크기든지 심층 신경망 적용 가능.
coarsest pyramid level은 전체 이미지를 포함하는 single bin으로 구성되는데, 이게 global pooling 작업에 해당하는 것.
ex. 모델 크기와 과적합을 줄이기 위해 global average pooling 사용/weakly supervised learning 객체 인식을 위해 global max pooling 사용.
→ global pooling=Bag-of-Words와 유사함
Training the Network
이론적으로, 앞서 설명한 신경망 구조는 input 이미지 크기에 상관 없이, 역전파를 사용해서 학습 가능.
But, 실제 GPU 구현에서는 fixed input 이미지를 더 선호.
그렇다면 GPU 구현과 SPP 기법을 둘 다 고려한 솔루션은?
Single-Size Training
고정된 크기로 입력된 이미지를 사용하는 신경망을 고려.
여기서도 crop이 사용되지만(warp 사용 X), 이때 cropping이라는 것은 data augmentation(데이터 증강)을 위해 수행됨.
(SPPNet에서는 이미지 center나 모서리 4개 부분에서 고정된 크기의 이미지를 잘라내서, 이걸 data augmentation으로 활용하는 것. "crop으로 인한 정보 손실 최소화" by multi-level pooling or data augmentation)
특정 크기의 이미지에서, 미리 SPP에 필요한 bin의 size를 계산할 수 있음.
마지막 pooling layer에서는 다단계 피라미드 pooling을 사용해서 다양한 공간 정보를 통합함.
구현이 간단하고, 기존 fixed size input 신경망과 동일한 설정으로 학습이 가능하나, 사용되는 input size가 고정되어 있기에, 모든 입력 데이터의 실제 size나 비율을 반영하는 데에는 어려움이 존재.
Multi-size training
입력 이미지의 크기를 다양한 크기(ex. 224x224, 180x180)로 설정하여 학습.
각각의 크기에 대해서 고정된 크기의 input network를 따로 구현하지만, 각 network 모두 동일한 파라미터를 공유하는 구조.
각 epoch마다 학습 크기를 전환하여 network를 학습하는 구조.
다양한 크기의 입력 이미지를 시뮬레이션할 수 있음 → 실제 데이터의 다양성 더 잘 반영한다는 장점 존재.
또한, 파라미터를 공유하기에, 각 network 간의 일관성 유지 가능.
Single-Size Training/Multi-Size Training은 Train 단계에서만 사용됨.
Test 단계에서는 SPPnet을 임의 크기의 이미지에 바로 적용할 수 있음.
Test 단계에서는 input image size가 이미 정해져 있기 때문에, Train 단계에서 다양한 이미지 처리해서 입력 데이터를 효과적으로 처리하는 역할을 수행하는 것.
✅3. SPP-NET FOR IMAGE CLASSIFICATION
Experiments on ImageNet 2012 Classification
ImageNet 2012의 1,000-category training set을 이용해서 신경망 학습을 시킴.
- smaller dimension(이미지의 작은 변): 256이 되도록 resizing
- 이미지 중앙 or 모서리 네 부분에서 224x224 size crop
- data augmentation: horizontal flipping(수평 뒤집기) & color altering(색상 변환) 적용
- fully-connected layer 2개에 dropout 적용(과적합 방지)
- 학습률: 0.01로 시작. error 정체 시, 두 번에 걸쳐 학습률을 10분의 1로 감소
Baseline Network Architectures
합성곱 신경망 아키텍처와 독립적이라는 것이 SPP의 장점.
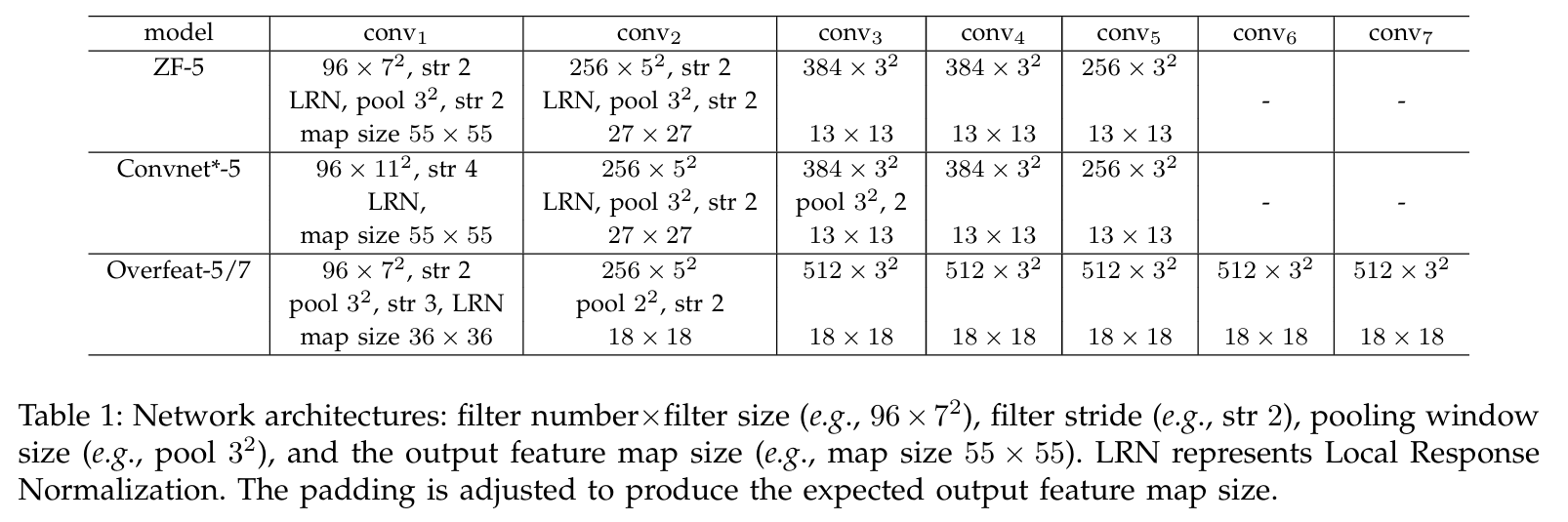 ↑ 다양한 network에서의 baseline architectures
↑ 다양한 network에서의 baseline architectures
SPPNet이 위 모든 architecture에서 정확도(accuracy)를 향상시킨다는 것을 확인.
Multi-level Pooling • Multi-sizeTraining • Full-imageRepresentations Improve Accuracy
Multi-level Pooling/Multi-sizeTraining/Full-imageRepresentations이 정확도를 향상시키는 양상을 보였음.
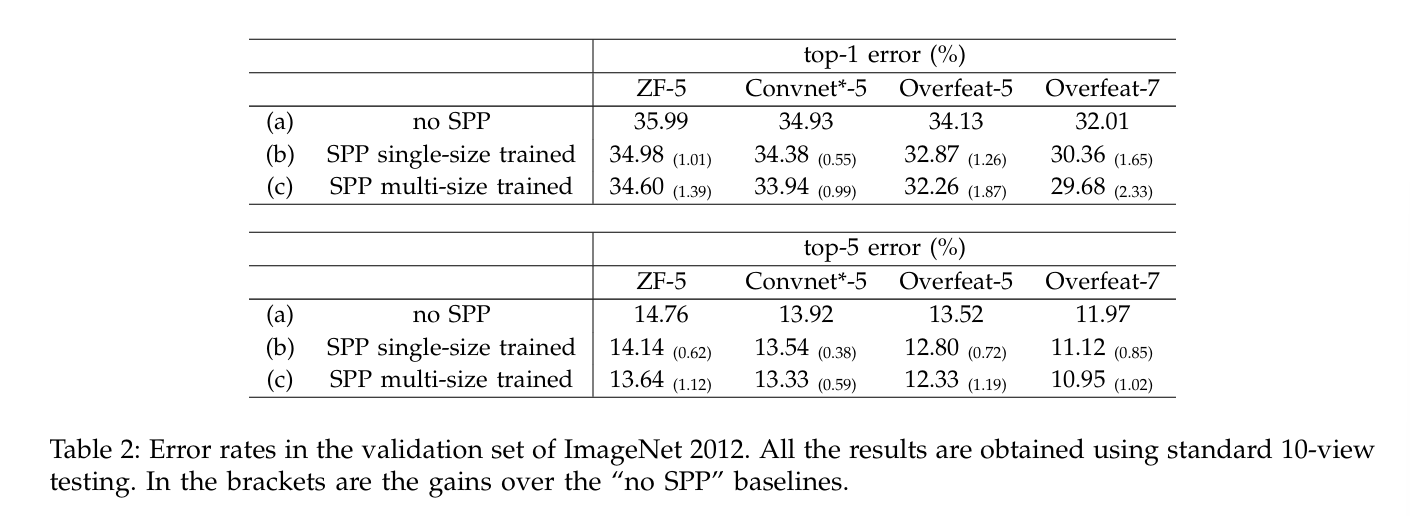 ↑ ImageNet 2012의 validation set에서의 Error Rate
↑ ImageNet 2012의 validation set에서의 Error Rate
신경망의 합성곱 레이어는 기존 모델 구조랑 같지만, 마지막 합성곱 레이어는 SPP 레이어로 대체.
위에서 SPP 레이어는 4-level pyramid(6x6, 3x3, 2x2, 1x1)(총 50개 bin 사용)
Multi-level Pooling이 좋은 성능을 낼 수 있었던 것은
: 단순 more 파라미터? (X)
객체 변형(object deformations)과 공간적 배치(spatial layout)의 변화에 강하기 때문.
Multi-size Training이 Single-size Training 대비 성능 향상을 이뤄냄을 확인할 수 있었음.
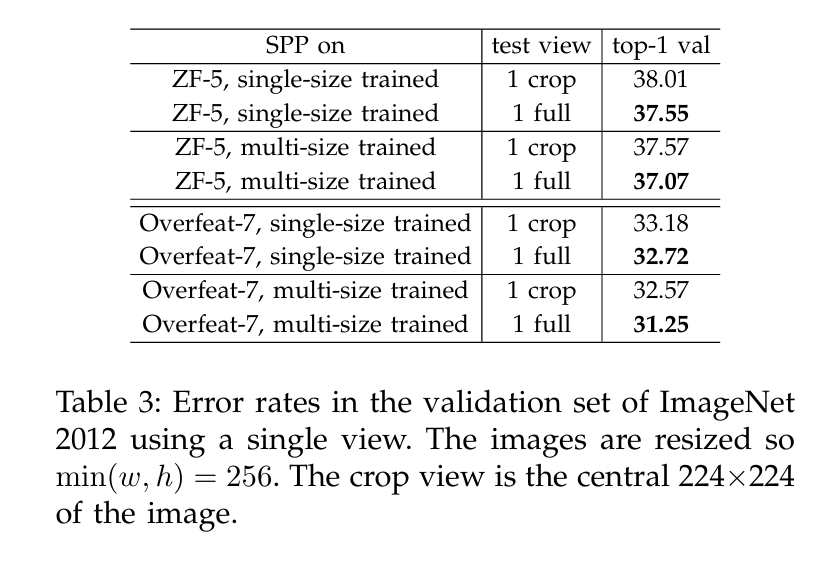
input image의 작은 변을 256이 되도록 resize하고, 가로세로 비율을 유지하며 전체 이미지(Full-image) 사용.
더불어 single view-center 224x224 crop의 경우도 같이 비교함.
그 결과, Full-image Representations이 객체의 전체적인 정보가 보존되기 때문에, 더 좋은 성능을 보임을 확인할 수 있었음.
✅4. SPP-NET FOR OBJECT DETECTION
R-CNN은 상당히 높은 quality의 결과를 만들고, 기존 방법들보다 성능이 크게 향상함.
다만, 이미지의 모든 윈도우에 대해 심층 신경망을 반복적으로 적용해야 하므로, 시간 소요가 큼.
또한 testing 단계에서 feature extraction이 주요 병목(bottleneck)으로 작용한다는 단점이 존재함.
SPPNet, Object Detection에서도 사용 가능!
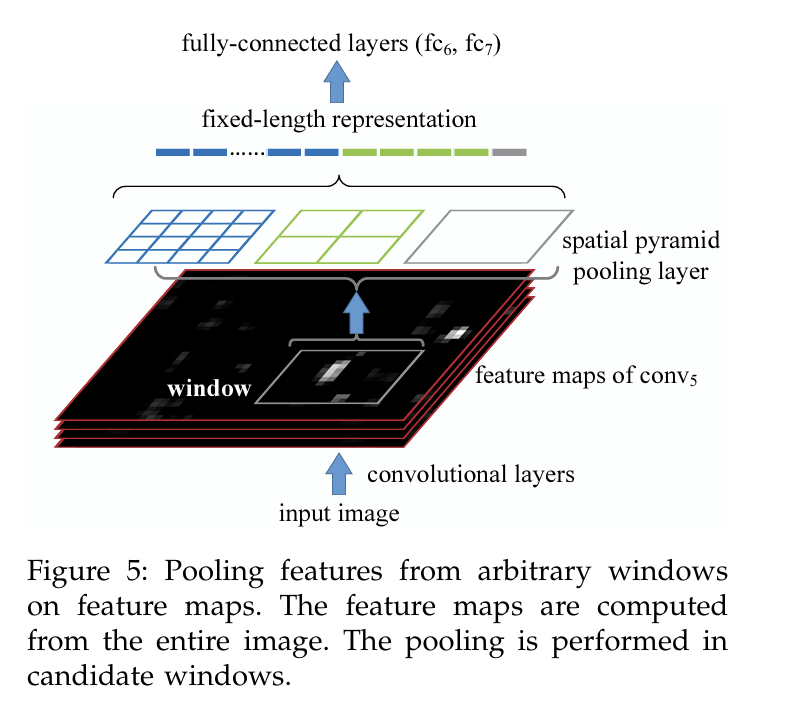
전체 이미지를 대상으로 한 번만 합성곱 연산을 수행하여 feature map을 생성함.
그 후 feature map에서 각 후보 window에 대해 SPP(Spatial Pyramid Pooling)를 적용하여 각 window의 fixed-length representation을 생성함.
이렇게 SPPNet은 합성곱 연산이 한 번만 수행 되기에, R-CNN 대비 빠른 속도로 수행 가능.
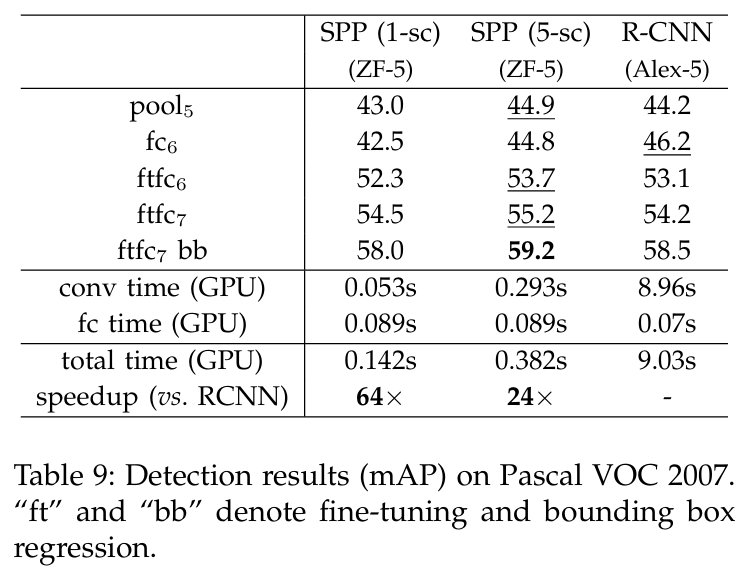 ↑ Detection results on Pascal VOC 2007
↑ Detection results on Pascal VOC 2007
fine-tuning이 된 fc layer를 사용할 경우, R-CNN의 fine-tuning 결과와 대등하거나 살짝 더 낫다는 것을 확인할 수 있음.
fully-connected layer(fc6, fc7)가 이미지 영역에 맞게 학습된 상태에서는 featue map 영역에서의 strong activation을 적절히 처리하지 못함.
따라서 fine-tuning을 통해 적절한 방식으로 detection 작업을 해결하려고 하는 것.
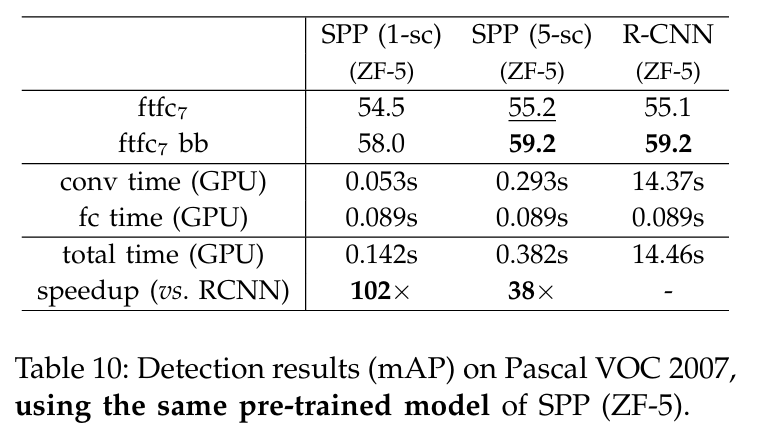 ↑ Detection results on Pascal VOC 2007 + using the same pre-trained model of SPP
↑ Detection results on Pascal VOC 2007 + using the same pre-trained model of SPP
SPPNet의 multi-level pooling과 ZF-5의 아키텍처가 AlexNet보다 더 낫기 때문에, R-CNN과 비슷한 평균 score을 기록할 수 있었음.
(SPP가 없는 ZF-5를 사용하면, R-CNN 성능 하락)
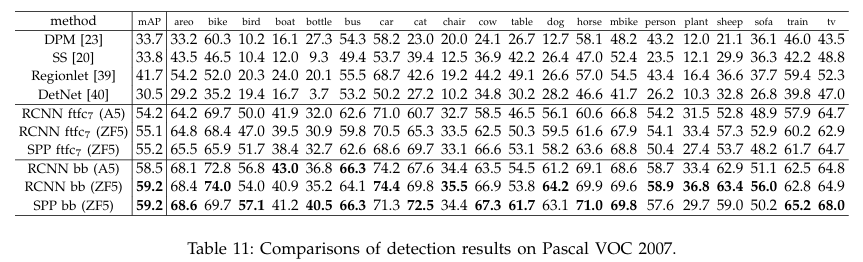 ↑ Detection results for each category on Pascal VOC 2007
↑ Detection results for each category on Pascal VOC 2007
기존 객체 탐지 방법(DPM, SS, Regionlet, DetNet)과 R-CNN과 SPP-Net 기반 모델들의 성능을 비교하였고, SPP-Net이 대개 높은 mAP를 기록하였으며, bounding box(bb) 회귀 적용 후 성능 향상이 더 이루어짐을 확인할 수 있음.
SPP-Net은 R-CNN 대비 속도와 성능 면에서 우수한 양상을 보임.
 ↑ Detection results on Pascal VOC 2007. Theresultsofbothmodelsuse“ftfc7bb”.
↑ Detection results on Pascal VOC 2007. Theresultsofbothmodelsuse“ftfc7bb”.
SPP-Net(1) mAP: 59.2
SPP-Net(2) mAP: 59.1
모델 결합 후: 60.9 → 20개 중 17개 카테고리에서 더 나은 성능을 보임.
두 모델의 상호 보완적인 현상은 주로 합성곱 layer 때문임을 알 수 있음.
따라서, model combination이 detection 성능을 향상시키는 방법 중 하나임을 확인할 수 있었음.
🔚5. Conclusions
딥러닝에서 SPP(Spatial Pyramid Pooling)는 다양한 scale, size, aspect ratio를 다루는데 유연한 solution임.
SPP layer를 통해 신경망을 훈련시키는 솔루션을 제안했고, 이는 분류 및 탐지(classification and detection) 분야에서 뛰어난 정확도(accuracy)를 보여주었음. 또한, 심층 신경망 기반의 탐지 속도를 크게 향상시킴.
해당 연구는 CV 분야에서 오랜 기간 검증된 기술/인사이트가 심층 신경망 기반의 recognition에서 여전히 중요한 역할을 할 수 있다는 것을 보여줌.
🔖6. Reference
https://www.youtube.com/watch?v=SMEtbrqJ2YI&t=570s
https://vgg.fiit.stuba.sk/2015-02/bag-of-visual-words-in-opencv/
https://www.youtube.com/watch?v=m3anASWelsc&t=9s
https://www.researchgate.net/figure/Spatial-pyramid-matching_fig1_254051049
