CLIP-RC : Exploring Regional Clues in CLIP for Zero-Shot Semantic Segmentation(2024)
이 논문, "Exploring Regional Clues in CLIP for Zero-Shot Semantic Segmentation" 은 제로샷 의미론적 분할(ZS3)을 수행하는 CLIP 모델을 개선하는 새로운 방법을 제안합니다. 제로샷 의미론적 분할은 모델이 학습하지 않은 범주(미지의 클래스)에 대해서도 이미지를 픽셀 단위로 분할하는 작업입니다. 이 논문은 CLIP 모델이 이미지-텍스트 페어를 사용하여 학습되었지만, 픽셀 수준의 분할 작업에 대한 성능이 부족하다는 점을 지적하며 이를 해결하는 방안을 제시한다.
핵심 내용은 다음과 같습니다:
문제 정의:
CLIP은 대규모 이미지-텍스트 데이터로 학습되어 이미지 인식 능력은 뛰어나지만, 픽셀 단위의 의미론적 분할 작업에서 성능이 부족합니다. 특히, 이미지 수준의 정보를 픽셀 수준으로 세밀하게 전달하는 데 한계가 있습니다.
제로샷 의미론적 분할(ZS3) 작업에서는 미지의 클래스를 정확하게 분할해야 하므로 CLIP의 픽셀 단위 성능을 향상시키는 방법이 필요합니다.
CLIP-RC 모델:
논문에서는 새로운 방법인 CLIP-RC (CLIP with Regional Clues)를 제안합니다. 이 모델은 지역 단위 브리지(Region-Level Bridge, RLB)를 도입하여 이미지 수준에서 픽셀 수준으로의 정보 전달을 개선합니다.
CLIP-RC는 다음의 두 가지 주요 개선점을 제공합니다:
세밀한 의미론적 정보 제공: 이미지의 특정 영역을 분류하고, 이를 기반으로 세밀한 의미를 파악하여 픽셀 수준으로 전달합니다.
과적합 방지: 학습 단계에서 과적합을 방지하기 위해 추가적인 제약(Recovery Decoder with Recovery Loss)을 도입하여, 학습된 지식과 일반화 능력을 균형 있게 유지합니다.
CLIP-RC의 주요 구성 요소:
지역 단위 브리지(RLB): 이 모듈은 이미지의 특정 지역 정보를 추출하여 세밀한 분류 기능을 제공합니다. 이를 통해 이미지 수준에서 픽셀 수준으로 자연스럽게 연결됩니다.
지역 정렬 모듈(RAM): 다양한 피처 세트를 정렬하고, 지역 및 글로벌 정보를 결합하여 더 세밀한 분류 기능을 제공합니다.
복원 디코더 및 복원 손실(RDL): 학습 과정에서 과적합을 방지하며, 다양한 클래스에 대한 일반화 능력을 높입니다.
실험 및 성능:
PASCAL VOC 2012, PASCAL Context, COCO-Stuff 164K 등 다양한 데이터셋에서 CLIP-RC는 기존의 최첨단(SOTA) 모델을 능가하는 성능을 보여줍니다.
Inductive Setting(미지의 클래스를 사전 지식 없이 분류하는 설정)과 Transductive Setting(미지의 클래스 이름이 알려진 상태에서 분류하는 설정)에서 모두 CLIP-RC는 우수한 성능을 기록했습니다.
특히, 미지의 클래스 분류에서 큰 성능 향상을 보여 ZS3 작업에서 CLIP-RC의 뛰어난 효율성을 입증했습니다.
주요 기여:
CLIP-RC는 이미지 수준에서 픽셀 수준으로 정보를 전달하는 지역 단위 브리지를 제안하여 제로샷 의미론적 분할에서 성능을 크게 향상시켰습니다.
과적합을 줄이기 위한 복원 디코더와 손실 함수 도입으로 모델의 일반화 능력을 유지하면서도 높은 성능을 달성했습니다.
Abstract
CLIP은 대규모 image-text pairs를 활용한 강력한 pre-training 덕분에 visual recognition에서 큰 진전을 보여주었다. 그러나 여전히 중요한 과제가 남아 있다. 그것은 image-level knowledge를 어떻게 pixel-level understanding tasks, 예를 들어 semantic segmentation으로 전환할 것인가 하는 문제다. 이 논문에서는 이러한 문제를 해결하기 위해 CLIP 모델의 능력과 zero-shot semantic segmentation task의 요구 사이의 격차를 분석한다. 분석과 관찰을 바탕으로, 우리는 zero-shot semantic segmentation을 위한 새로운 방법인 CLIP-RC (CLIP with Regional Clues)를 제안한다. 이 방법은 두 가지 주요 통찰을 제공한다. 첫째, fine-grained semantics를 제공하기 위해 region-level bridge가 필요하다. 둘째, training 단계에서 overfitting을 완화해야 한다. 이러한 발견을 바탕으로 CLIP-RC는 PASCAL VOC, PASCAL Context, 그리고 COCO-Stuff 164K를 포함한 다양한 zero-shot semantic segmentation benchmarks에서 state-of-the-art 성능을 달성하였다.
1. Introduction
Zero-shot 인식 능력 외에도, ZS3 작업을 완료하려면 픽셀 수준에서 지역을 정확히 지정할 수 있는 능력도 필수적인데, CLIP은 이 부분에서 부족하다. 이러한 CLIP의 localization 한계를 보완하기 위해, 연구자들은 두 가지 접근 방식인 one-stage methods [47(SAN: side adapter network for open-vocabulary
semantic segmentation), 55(Zegclip)]와 two-stage methods [7( Decoupling zero-shot semantic segmentation), 14(Open-vocabulary semantic segmentation with decoupled one-pass network.), 33(Freeseg), 46, 52(Extract free
dense labels from CLIP)]를 제안했다.
Two-stage methods는 먼저 class-agnostic mask generators를 사용해 초기 마스크 proposals을 생성한다. 그런 다음, CLIP 모델을 사용하여 이들에 semantic 정보를 제공한다. 추가적인 class-agnostic segmentation 모델을 도입했기 때문에, 이러한 방법들은 많은 계산 비용이 든다.
이 논문에서는 one-stage methods에 초점을 맞춘다. One-stage 접근법은 추가적인 계산 오버헤드를 피하고 CLIP 모델을 ZS3에 맞게 직접 fine-tuning한다. Fine-tuning 과정에서 두 가지 중요한 요소가 있다.
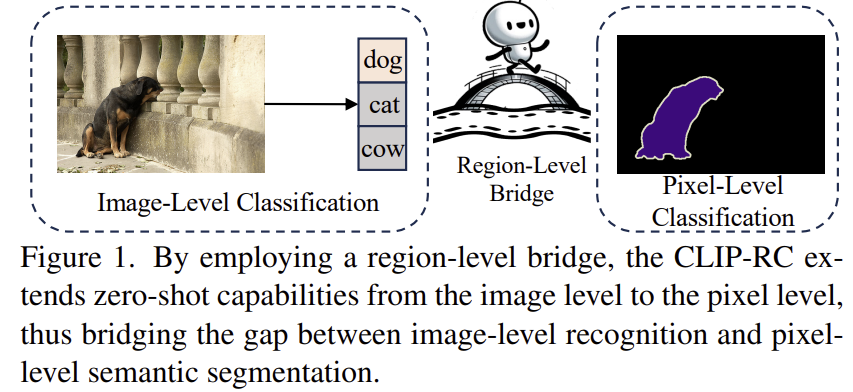
1. 첫째, image-level understanding features를 pixel-level understanding features로 전환하는 것이 segmentation 작업을 완료하는 핵심이다. --> region-level bridge를 도입하여 image-level classification과 pixel-level semantic segmentation 간의 격차를 줄임
2. 둘째, fine-tuning 과정에서 모델이 tuning 중에 본 클래스만 인식하려는 경향을 보인다(이를 catastrophic forgetting이라고 한다). 이는 모델의 zero-shot 인식 능력을 저하시킬 수 있다. --> recovery decoder와 이에 대응하는 recovery loss를 도입
이러한 차이점들은 CLIP 모델의 능력과 ZS3 작업의 요구 사항 사이의 격차를 나타낸다. 이 격차를 해소하기 위해 우리는 새로운 방법인 CLIP-RC를 제안한다.
CLIP-RC는 중요한 관찰에서 영감을 받았다. Fig. 2에서 보여주듯이, 우리는 간단히 CLIP의 지역 수준 분류 성능을 테스트했다. 그 결과, CLIP이 지역 인식에서 강력한 성능을 보인다는 것을 발견했다. Region-level recognition 능력은 image-level 인식보다 더 세밀한 인식 능력으로, pixel-level segmentation 작업에 더 가깝다. 따라서 우리는 이것이 CLIP과 ZS3 작업을 연결하는 적합한 bridge가 될 수 있다고 믿는다. 이를 바탕으로 우리는 ZS3를 위한 새로운 접근법인 CLIP-RC (CLIP with Regional Clues) 를 도입한다. 이 방법은 regional clues를 활용하여 image-level과 pixel-level 이해 사이의 격차를 메우는 역할을 한다고 Fig. 1에서 설명하고 있다.

또한 우리는 fine-tuning 과정에서 추가적인 제약을 통해 overfitting 문제를 해결하는 방법을 탐구했다. 구체적으로는 recovery loss를 가진 recovery decoder를 제안했다. 이 방법은 CLIP-RC가 ZS3에 적응하면서도 고유의 generalization 능력 손실을 최소화하도록 설계되었다. 즉, task-specific tuning과 광범위한 지식을 유지하는 사이에서 미세한 균형을 맞추도록 설계되었다. 이를 통해 학습한 클래스와 학습하지 않은 클래스 모두에서 신뢰할 수 있는 성능을 보장한다.
우리의 기여는 다음과 같이 요약할 수 있다:
- 우리는 ZS3를 위한 새로운 프레임워크인 CLIP-RC (CLIP with Regional Clues) 를 도입했다. 이 방법은 region-level bridge를 도입하여 image-level classification과 pixel-level semantic segmentation 간의 격차를 줄이고, ZS3 작업에 더 나은 해결책을 제공한다.
- 우리는 overfitting을 완화하기 위해 recovery decoder와 이에 대응하는 recovery loss를 도입했다. 이 접근법은 task-specific knowledge와 모델의 고유한 generalization 능력 사이의 균형을 효과적으로 맞춘다.
- CLIP-RC를 사용하여 다양한 벤치마크에서 ZS3 작업의 state-of-the-art 성능을 위한 새로운 기준을 세웠다. 이 성과는 이전 방법들을 큰 차이로 능가한다.
3. Method
3.1. Method Overview
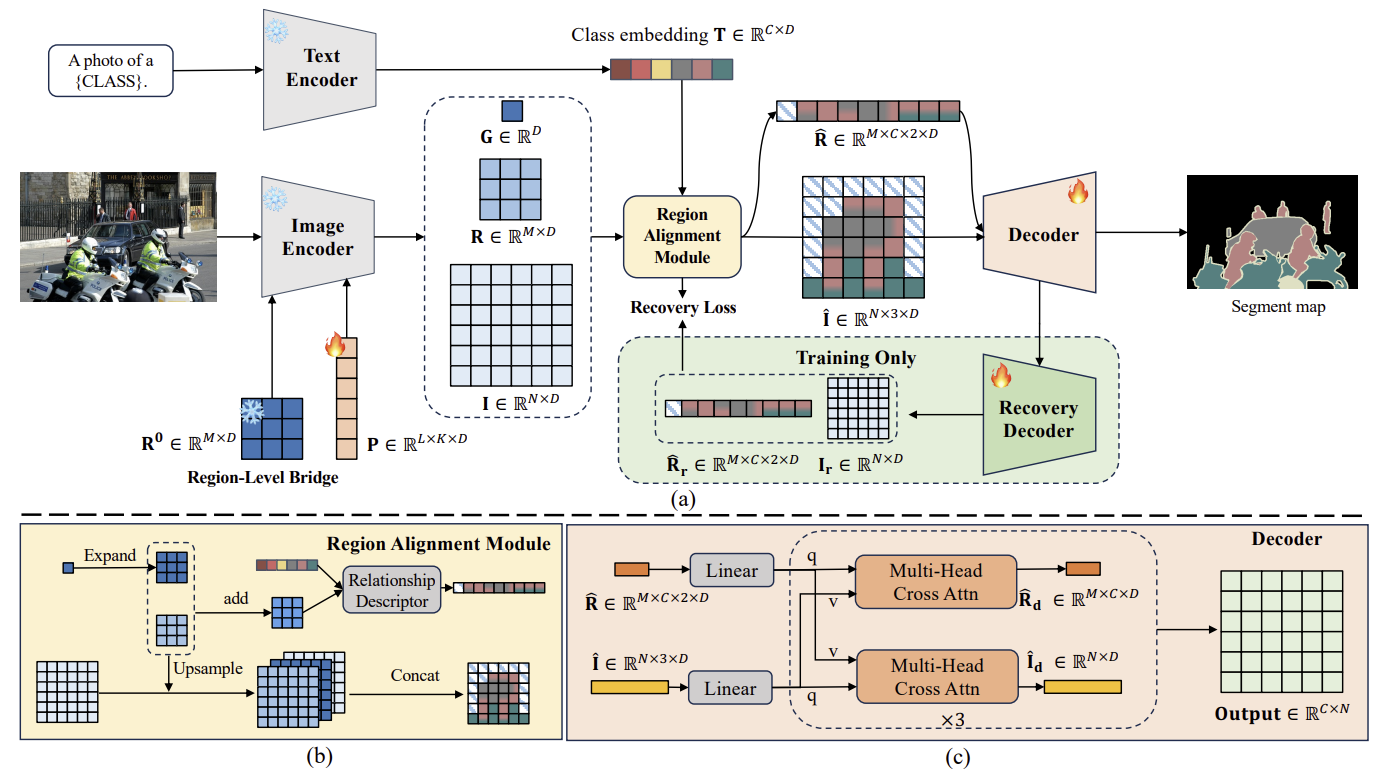
Fig. 3(a)에서 보이는 것처럼, CLIP-RC는 세 가지 주요 구성 요소를 가진다: Region-Level Bridge (RLB), Region Alignment Module (RAM), 그리고 Recovery Decoder with Recovery Loss (RDL) 이다. 먼저, Sec. 3.2에서 자세히 설명하듯이, 이미지는 인코더에 입력되어 global features, image features, 그리고 RLB에 의해 추출된 region category features를 얻는다.
Sec. 3.3에서는 RAM을 사용하여 이러한 feature 세트를 정렬하고, 더 세밀한 범주형 feature를 가진 image features를 만든다. 이 feature들은 text embedding과 결합되어 regional relationship descriptors를 얻는다. 그 후, semantic segmentation을 위한 디코더가 이 feature들을 사용하여 segmentation map을 예측하고 생성한다. 훈련 중 overfitting을 최소화하기 위해,
Sec. 3.4에서 논의된 RDL을 사용하여 task-specific features와 general knowledge 사이의 균형을 보장한다.

Figure 3. 우리가 제안한 CLIP-RC의 프레임워크. (a) 이미지는 image encoder에 입력되고, 그 결과 image feature (I), region-level bridging을 통해 추출된 region category information feature (R), 그리고 global feature (G)가 생성된다. 이후 이 세 가지 feature 세트는 text embedding (T)과 정렬되고 결합되어 regional relationship descriptors를 생성한다. 마지막으로, semantic segmentation을 위한 디코더가 이 feature들을 사용하여 segmentation map을 추론하고 생성한다. 훈련 중 overfitting을 방지하기 위해 recovery decoder와 recovery loss가 사용된다. (b) region alignment module. (c) 디코더 구조의 세부사항.
