이 논문은 "형태 인식 제로샷 의미론적 분할 (SAZS: Shape-Aware Zero-Shot Semantic Segmentation)"이라는 주제로, 새로운 제로샷 의미론적 분할(ZSS) 프레임워크를 제안합니다. ZSS는 테스트 중 추가 학습 없이 이전에 본 적 없는 객체 범주를 예측하는 것을 목표로 합니다. 주요 내용을 요약하면 다음과 같습니다:
문제 배경: 기존의 의미론적 분할 모델은 학습과 테스트 단계에서 동일한 범주에만 초점을 맞추는 닫힌 집합(closed-set) 설정에 국한되어 있습니다. 그러나 실제 세계에서는 학습 중에 보지 못한 객체를 만나게 되는 개방형 환경(open world)이 더 일반적입니다. 제로샷 의미론적 분할(ZSS)은 이러한 격차를 해소하고, 학습 중 보지 못한 범주에 대해서도 추가 학습 없이 이미지를 분할하려는 시도입니다.
제로샷 분할의 과제: 최근에는 CLIP과 같은 대규모 사전 학습된 비전-언어 모델을 사용한 제로샷 분할 접근법이 등장했습니다. 이들은 보지 못한 범주를 인식하는 데 좋은 성과를 보였지만, 객체의 형태(모양)를 세밀하게 구분하는 데는 어려움을 겪고 있습니다. 이는 자율 주행이나 의료 영상과 같은 중요한 응용에서 문제가 될 수 있습니다.
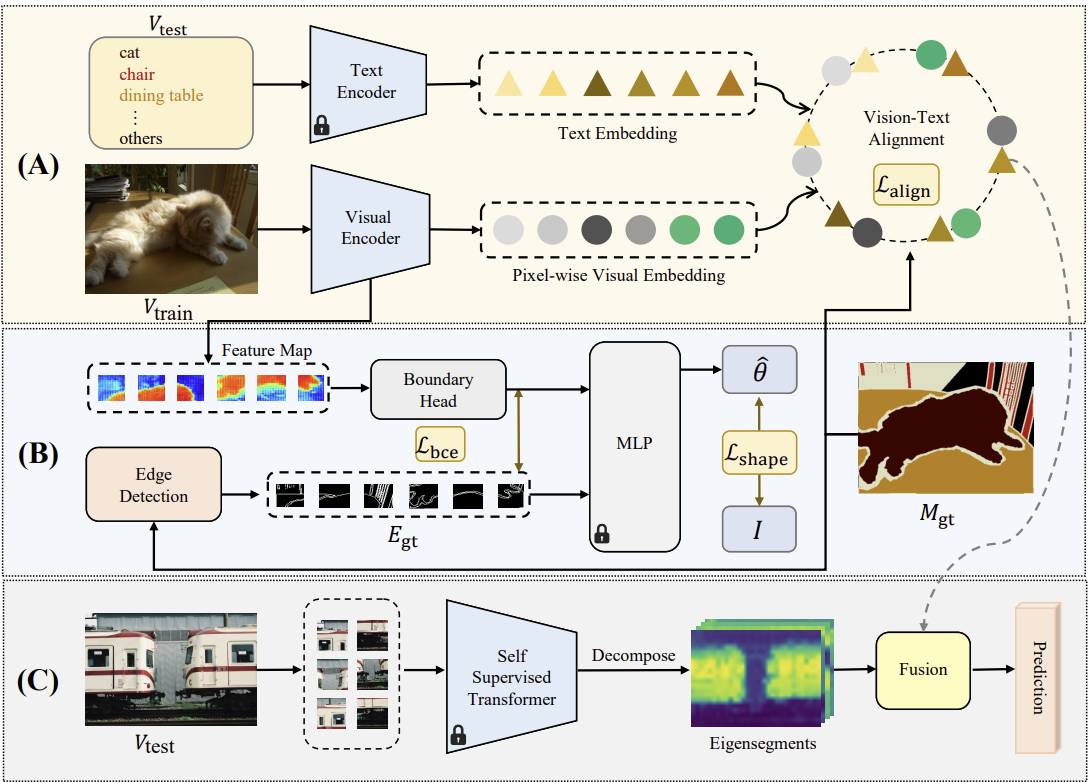
SAZS 프레임워크: 제안된 형태 인식 제로샷 의미론적 분할(SAZS) 프레임워크는 정확한 객체 경계를 인식하는 형태 인식(Shape-Aware)을 통해 보지 못한 범주의 객체 분할 성능을 향상시키는 것을 목표로 합니다. 주요 구성 요소는 다음과 같습니다:
비전-언어 정렬(Vision-Language Alignment): 학습 중에는 입력 이미지의 픽셀 단위 시각적 임베딩(visual embedding)을 CLIP의 사전 학습된 텍스트 인코더를 통해 얻은 범주의 텍스트 임베딩(text embedding)과 정렬합니다. 이를 통해 대규모 언어 지식의 도움을 받아 의미론적 분할을 보다 정확하게 수행할 수 있습니다.
경계 탐지(Boundary Detection): 모델이 객체의 형태 정보를 더 잘 학습할 수 있도록 경계 탐지 작업을 추가로 수행합니다. 이는 예측된 경계와 실제 경계를 비교하며, 모델이 객체의 정확한 경계선을 학습하도록 돕습니다.
스펙트럴 분석을 통한 형태 인식(Spectral Analysis): 테스트 중에는 학습된 신경망의 예측 결과를 자기지도(self-supervised) 방식으로 얻은 형태 기반 분할 정보(eigensegments)와 결합합니다. 이를 통해 모델이 학습 시 보았던 범주에 의존하지 않고, 보지 못한 범주의 객체도 보다 정확하게 인식할 수 있습니다.
성능: SAZS는 PASCAL-5i 및 COCO-20i와 같은 다양한 데이터셋에서 기존 최첨단(SoTA) 방법들보다 더 우수한 성능을 보였습니다. 특히 형태 인식(shape-awareness)을 통해 이전에 본 적 없는 범주에서도 정확한 분할을 수행할 수 있었으며, 스펙트럴 분석을 활용한 예측 결과 결합이 큰 성능 향상을 가져왔습니다.
