ZegCLIP: Towards Adapting CLIP for Zero-shot Semantic Segmentation
https://arxiv.org/pdf/2212.03588
Ziqin Zhou, Bowen Zhang, Yinjie Lei, Lingqiao Liu, Yifan Liu
1. Introduction

이 논문은 CLIP의 제로샷 능력을 이미지 수준에서 픽셀 수준으로 확장하여 파이프라인을 간소화하는 것을 목표로 한다. 제안된 방법은 lightweight decoder를 사용해 text prompts를 CLIP에서 추출한 local embeddings 과 매칭함. 이를 통해 학습된 클래스의 분할 성능을 향상시키고, 보지 못한 클래스까지 일반화할 수 있기를 기대했다.
그러나 기본 방법은 training set에 overfit되는 문제가 있었으며, unseen classes에서는 적절한 분할 결과를 내지 못했습니다. 이를 해결하기 위해 세 가지 디자인 제안하였다.
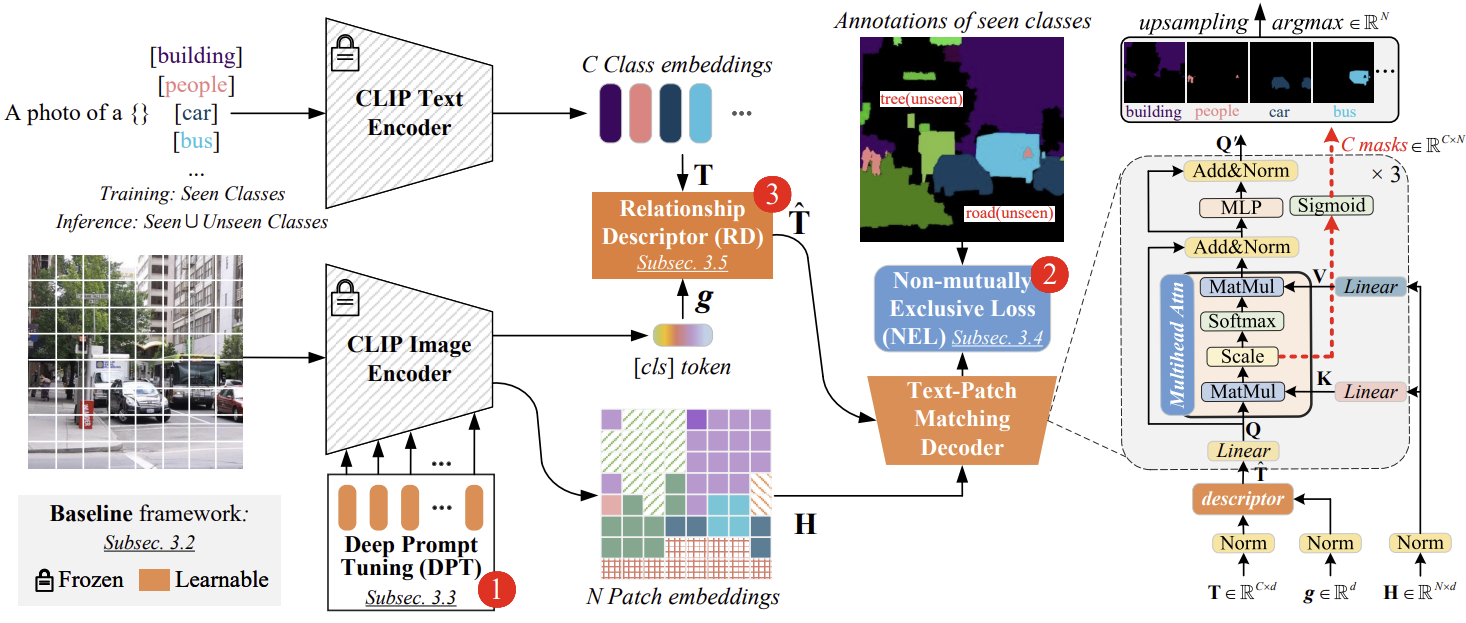
- Design 1: Using Deep Prompt Tuning (DPT) instead of fine-tuning or fixing for the CLIP image encode.
fine-tuning은 seen classes에 overfitting될 수 있는 반면, prompt tuning은 CLIP의 고유한 제로샷 능력을 더 잘 유지합니다. - Design 2: Applying Non-mutually Exclusive Loss (NEL) function when performing pixel-level classification
독립적으로 한 클래스의 posterior probability을 생성 - Design 3: Relationship Descriptor (RD)
CLIP의 text-patch embeddings을 매칭하기 전에 text embedding에 image-level prior를 통합함으로써 학습한 클래스에 과적합되는 것을 효과적으로 방지하는 것입니다.
2. Related Works
Zero-shot Semantic Segmentation
Zero-shot Semantic Segmentation는 타겟 모델은 학습 중에 주석이 달린 데이터를 사용하여 학습된 클래스를 분할한 후, 보지 못한 클래스도 분할함.
- SPNet, ZS3, CaGNet, SIGN, Joint, STRICT : 학습된 클래스에서 보지 못한 클래스로 의미 매핑의 일반화 능력을 향상시키는 전략을 따름
- Zegformer and zsseg : develop an extensive proposal generator and use CLIP to classify each region, then 예측 결과를 통합 -> 이러한 방법 이미지 수준에서 CLIP의 제로샷 능력을 유지하지만, 각 제안을 분류해야 하므로 계산 비용이 불가피하게 증가
(region proposals을 생성한 후, 잘라낸 영역을 CLIP에 입력하여 제로샷 분류를 수행하는 두 단계 처리 방식) - MaskCLIP+은 CLIP을 창의적으로 적용하여 새로운 클래스에 대한 가상 주석을 생성(“전이적(transductive)” 방식)하여 자체 학습에 활용합니다. 이 방법은 경쟁력 있는 성능을 달성했지만, 추론 중 보지 못한 클래스의 이름이 학습 중에 제공되지 않는 "유도적(inductive)" 설정에서는 무효화될 수 있습니다.
3. Method
3.1. Problem Definition
3.2. Baseline: One-stage Text-Patch Matching
3.3. Design 1: Deep Prompt Tuning (DPT)
3.4. Design 2: Non-mutually Exclusive Loss (NEL)
3.5. Design 3: Relationship Descriptor (RD)

잡다한거 다해요