
2. Machine Learning Pipeline
📌 2-1. 머신러닝 프로세스 개요
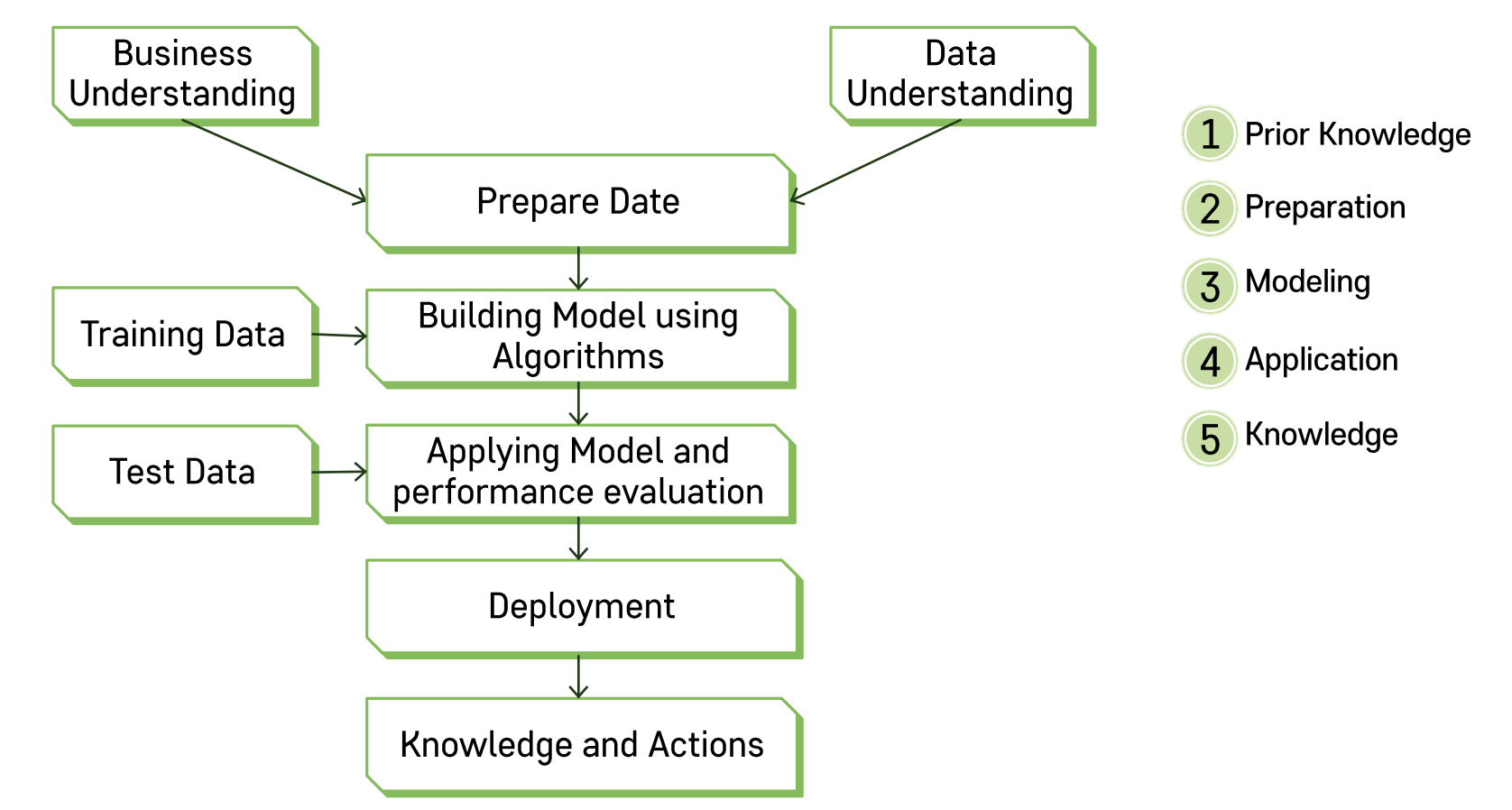
❗️ 검증을 통해 최적의 모델을 찾는 것이 가장 중요하다.
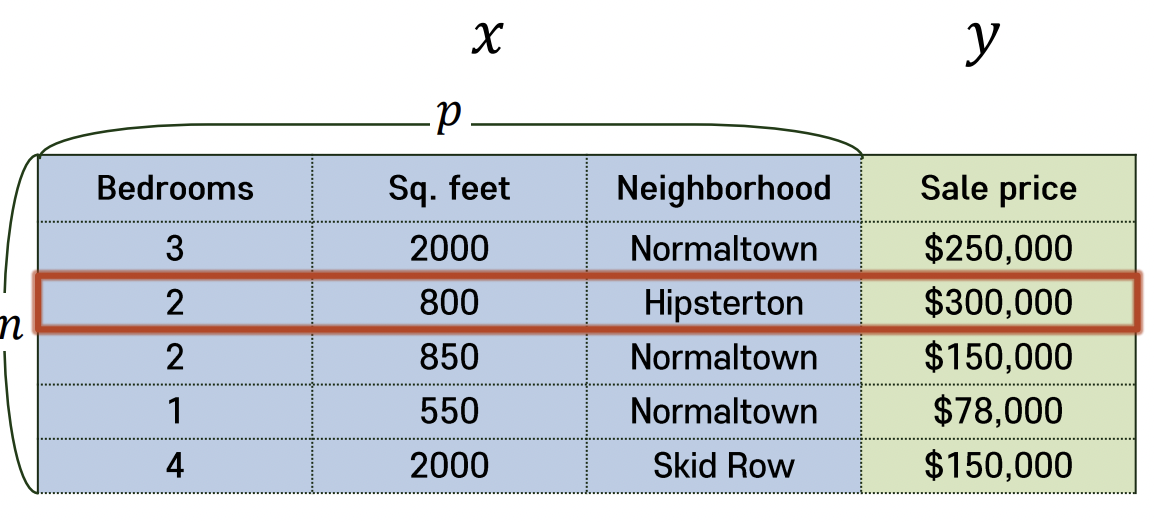
X = n * p
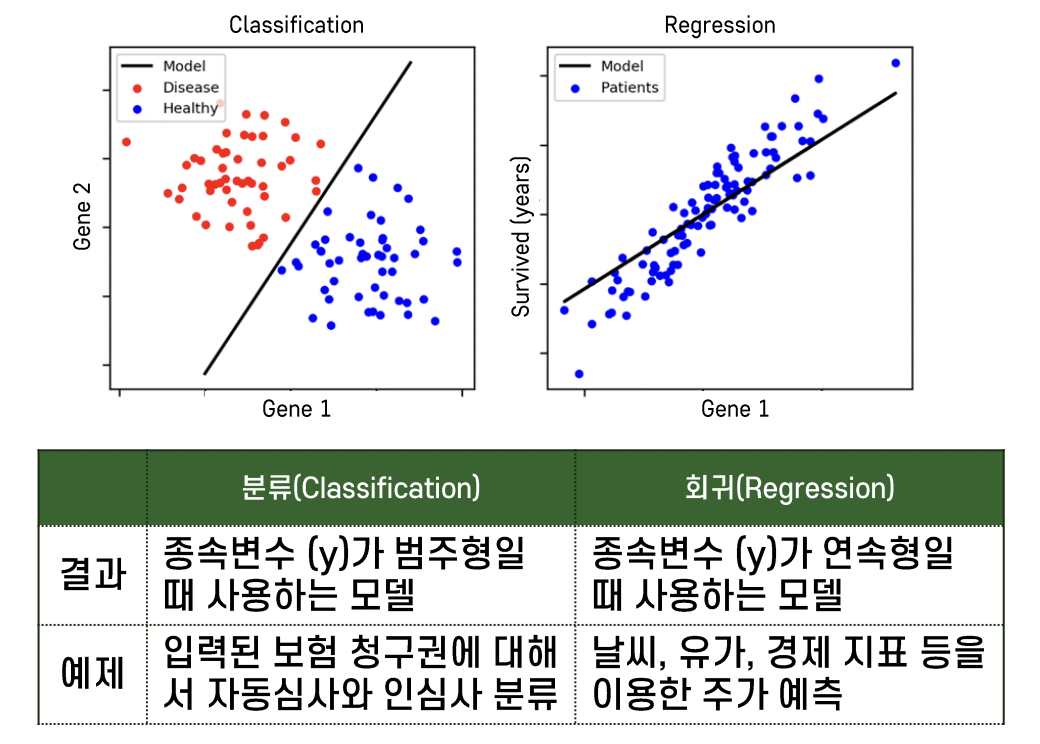
✅ 분류와 회귀
✅ Data 준비 과정
1) EDA
: 데이터 모델링 하기 전 변수별 기본적인 특성을 탐색하고 데이터 분포의 특징 이해
2) 결측치
3) 데이터 타입 및 변환
: 여러 종류의 데이터 타입을 확인하고 이를 분석이 가능한 형태로 변환
4) 정규화
: 데이터 변수들의 단위가 크게 다른 경우 모델 학습에 영향을 줄 수 있기 때문에 정규화
5) 이상치
: 학습에 영향을 줄 수 있는 이상치 처리
6) Feature Selection
: 많은 변수 중에서 모델링을 할 때 중요한 변수들만 선택
7) Data Sampling
: 모델을 검증하거나 앙상블 모델링을 할 때 데이터를 일부 추출하는 과정
✅ 모델링
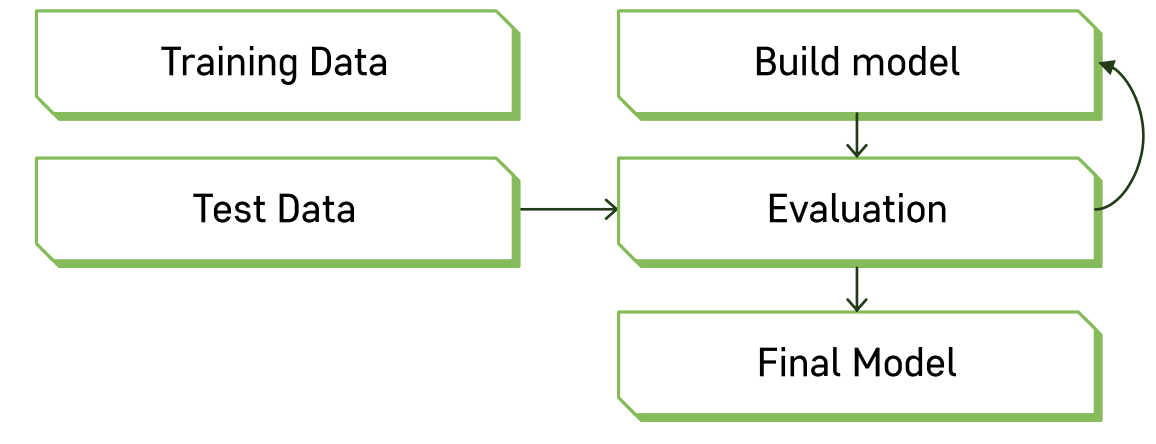
❗️ Evaluation -> Bulid model (train model)로 돌아가는 것을 feedback 이라고 하는데, 이 과정을 계속 반복하여 최적의 모델을 찾는 것이 중요
✅ 모델 검증 (Underfitting | Overfitting)
Training error (loss): 학습 데이터 내에서 발생하는 오차
Validation error (Testing error | Generalisation error): 테스트 데이터에서 발생하는 오차
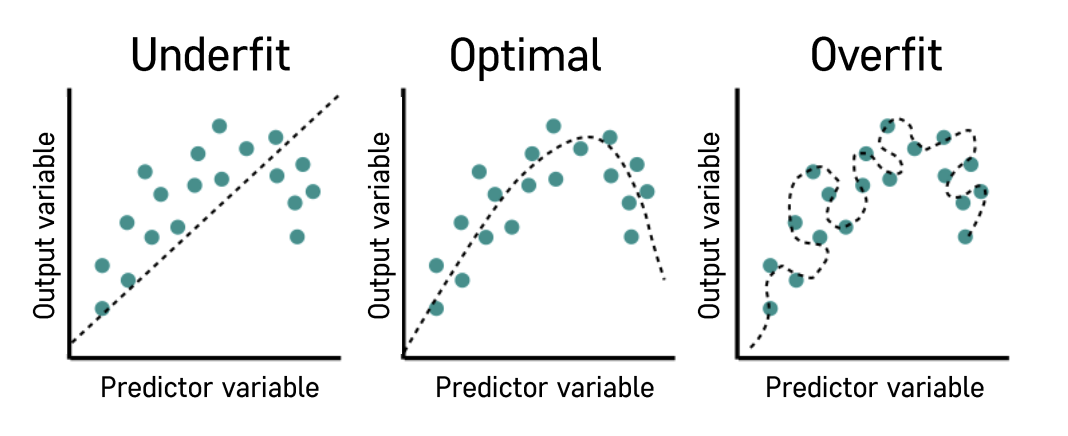
💡 오차가 크면 Underfitting이나 Overfitting을 의심해 봐야함
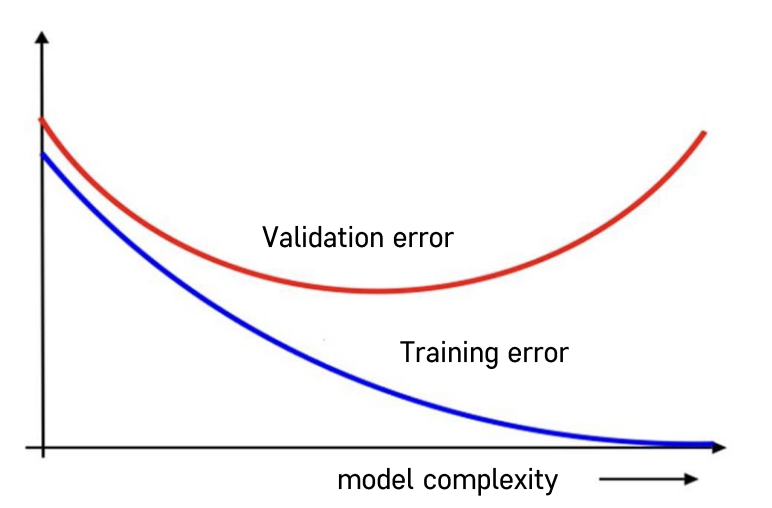
모델이 복잡해질수록 training error는 줄어드는 반면 validation error는 커지게 된다.
- 모델이 너무 복잡하거나 너무 간단해서 오차가 큰 경우 underfit이나 overfit 될 수 있음.
💡 Validation error가 가장 낮은 지점 (optimal model)을 찾는 것이 목적
