서울시 각 구별, 범죄 현황과 경찰서 구역별 분석
1.데이터 가져오기, 기본정보 알아보기
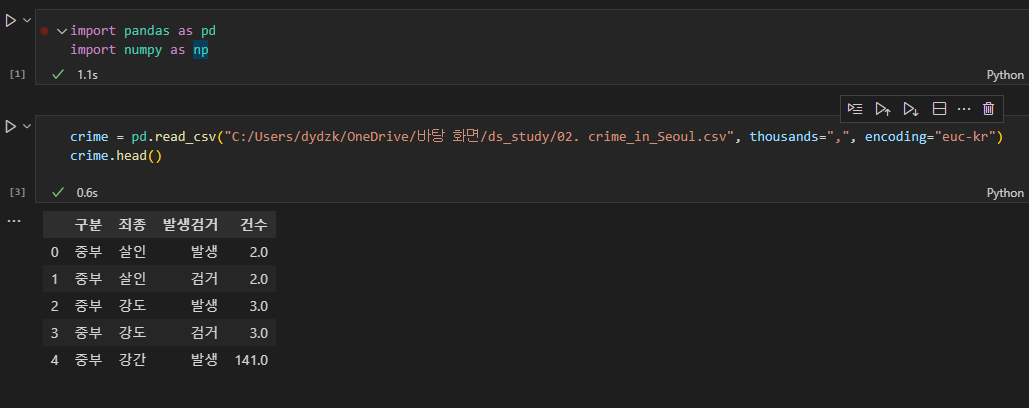
- csv 파일을 가져올 때, 20,000 과 같이 ','로 구분되어진 데이터가 데이터프레임에서 int 나 float이 아닌 문자열로 인식될 수 있으므로 thousands = "," 인자를 넣어서, 콤마로 구분되어진 숫자도 int형으로 인식할 수 있도록 해준다.
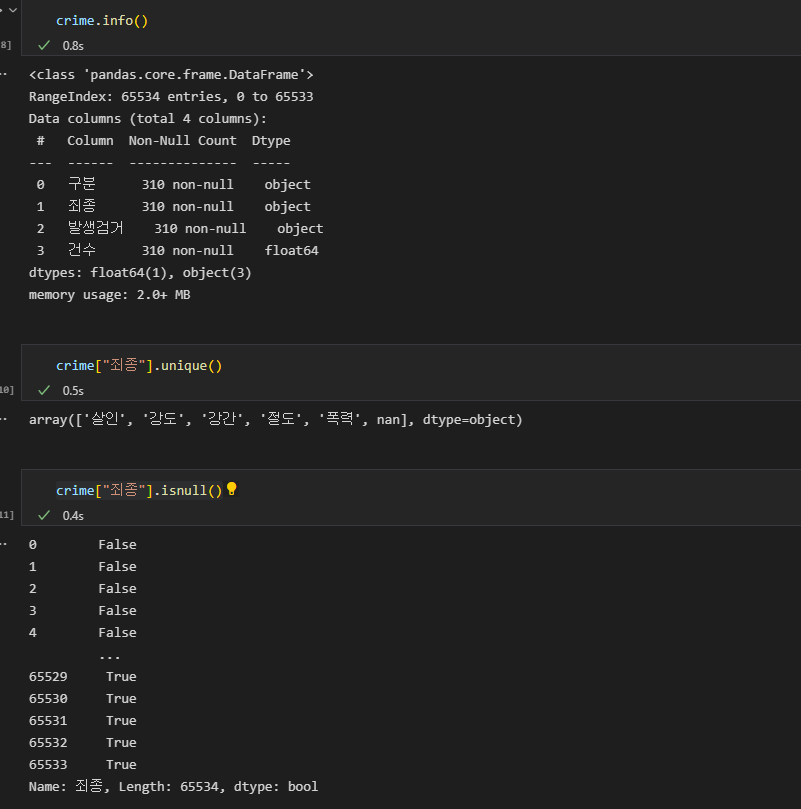
- 건수는 float형태로 잘 반영되었다. 죄종의 데이터를 확인해보면, nan 이라는 값이 있고 isnull()을 이용해보면 null값이 True인 경우들이 있다.
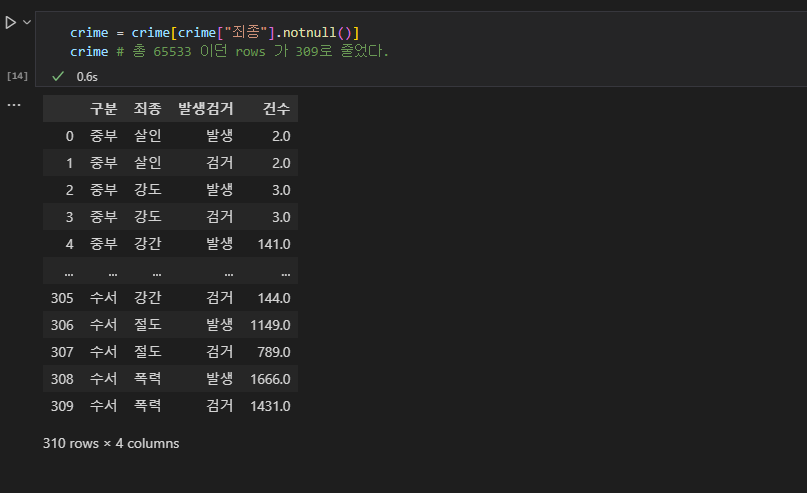
- nan 값은 데이터 분석에서 제외하고 보기 위해서, crime에 notnull()을 한 값들만 새로 초기화 시켜준다. 총 65333이던 rows 값이 nan값을 제외하고 310으로 줄었다.
2. pivot_table 이용
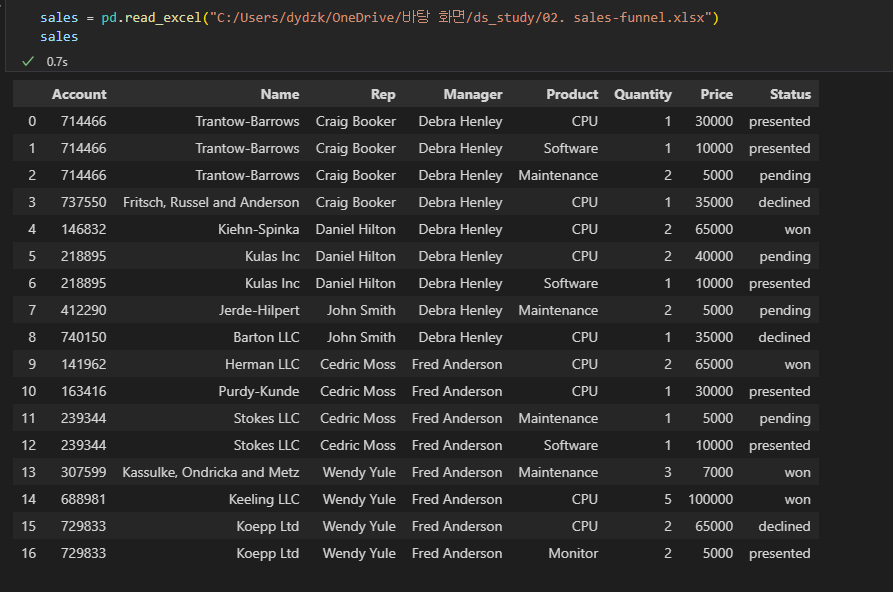
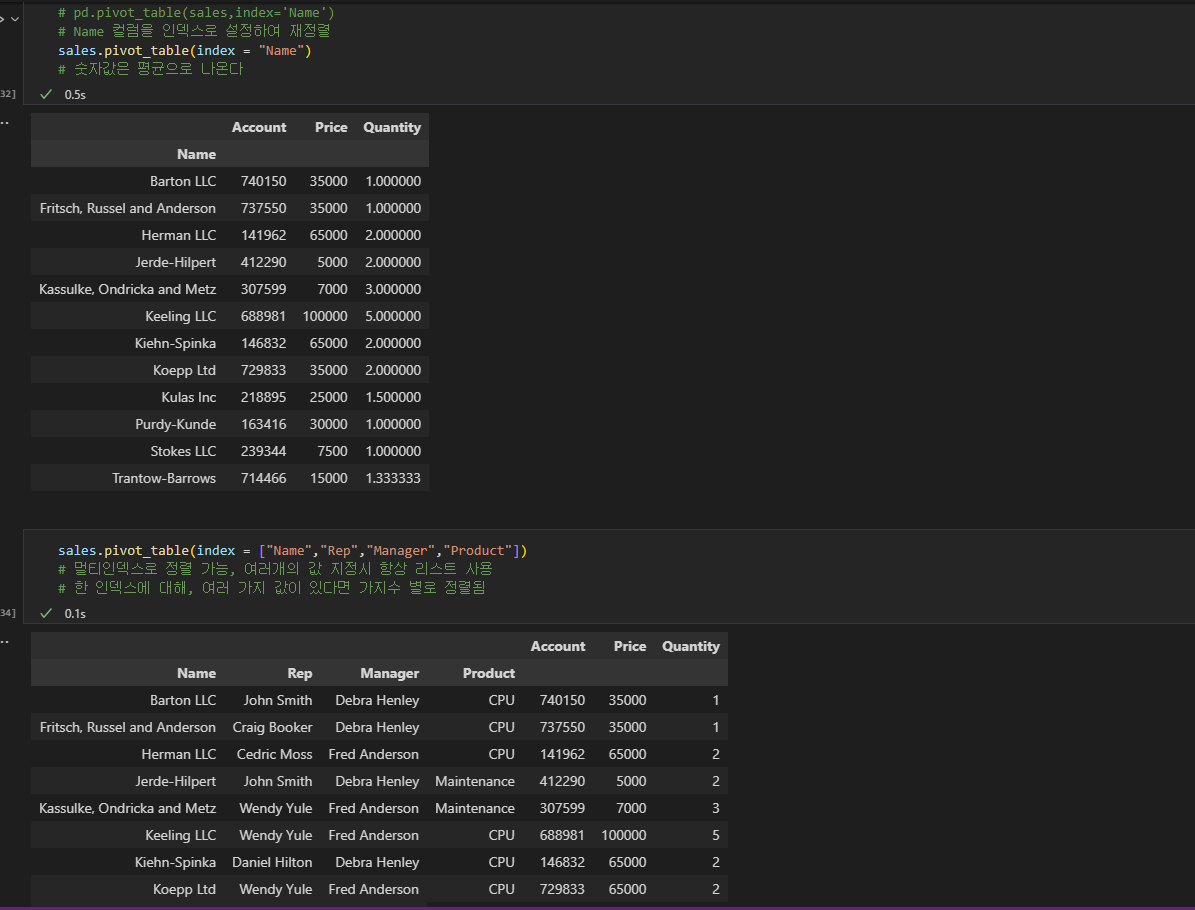
- pivot_table() 메소드를 사용해, 원하는 컬럼을 인덱스로 잡아 재정렬을 할 수 있다. 예를들어, 다음과 같은 경우 각 고객이 어떤 제품을 몇개 샀는지 따로따로 적힌 리스트에서, 고객명을 인덱스로 잡아 그 고객이 어떤걸 몇개 샀는지 한번에 정리되도록 인덱스를 바꿀 수 있다.
-
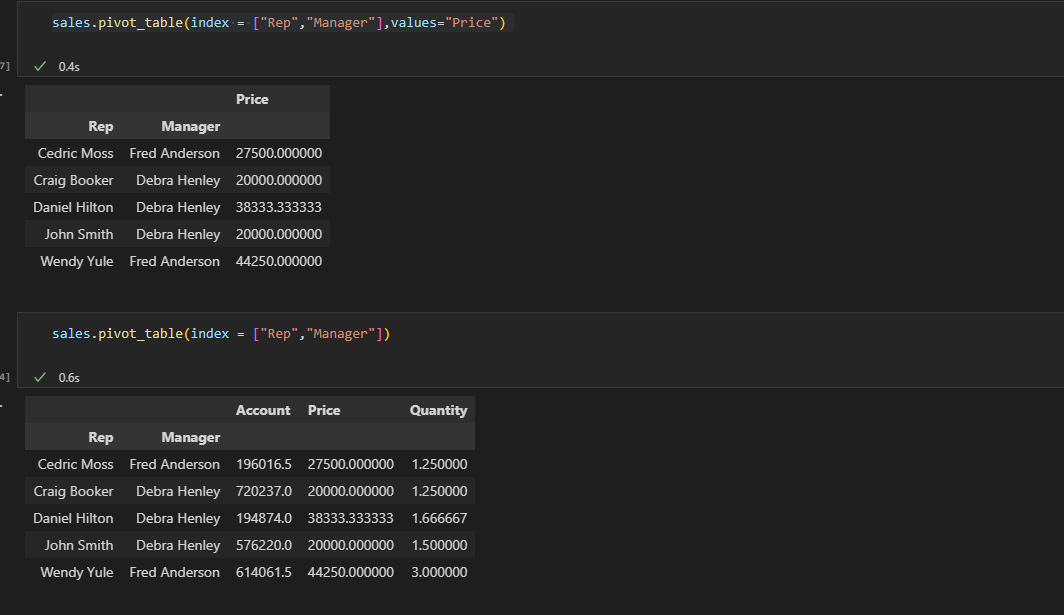
여러개의 인덱스를 사용하는 경우, 숫자값은 평균값으로 계산되어 나오고 카테고리가 여러개인 문자열 데이터의 컬럼은 같은 이름 내에서 몇가지 카테고리 별로 컬럼값들이 정리된다.
-
인덱스 지정시, 그에 맞는 숫자형태의 데이터 값이 컬럼으로 분류되고 이때 기본적으로 평균값으로 출력된다. valuse에 컬럼을 지정해주면, 특정 컬럼에 관해서만 분류된다.
-
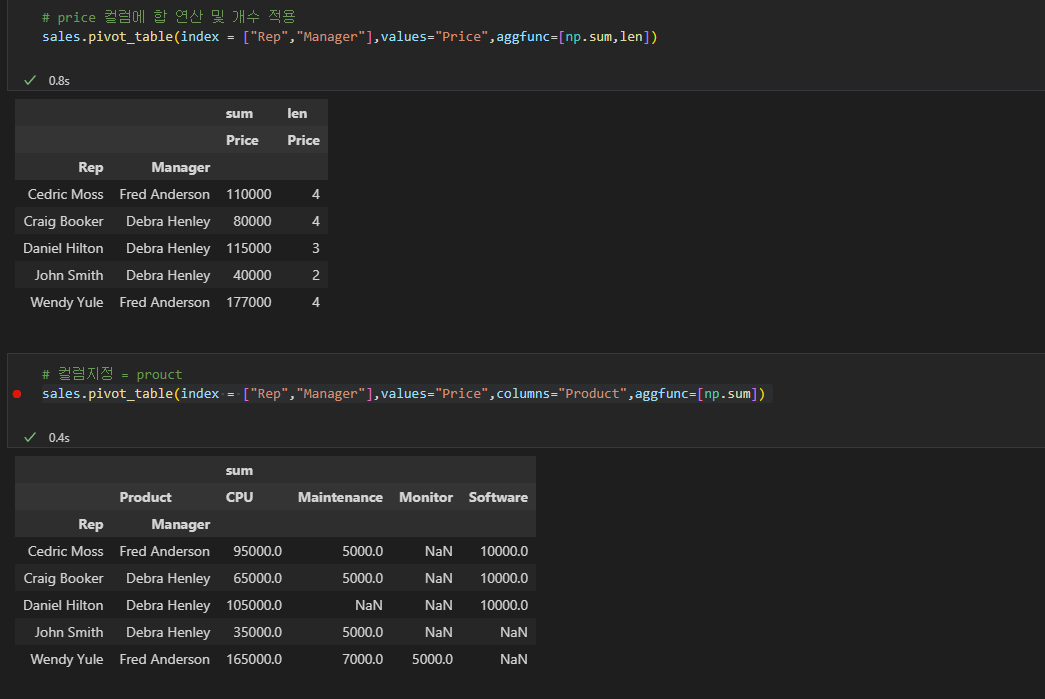
기본적으로 숫자형태의 값은 평균값으로 계산되는데 aggfunc=[np.sum] 인자를 이용해 [] 안에 넘파이 제공 함수를 사용하여 합 등 원하는값으로 계산할 수 있다.
-
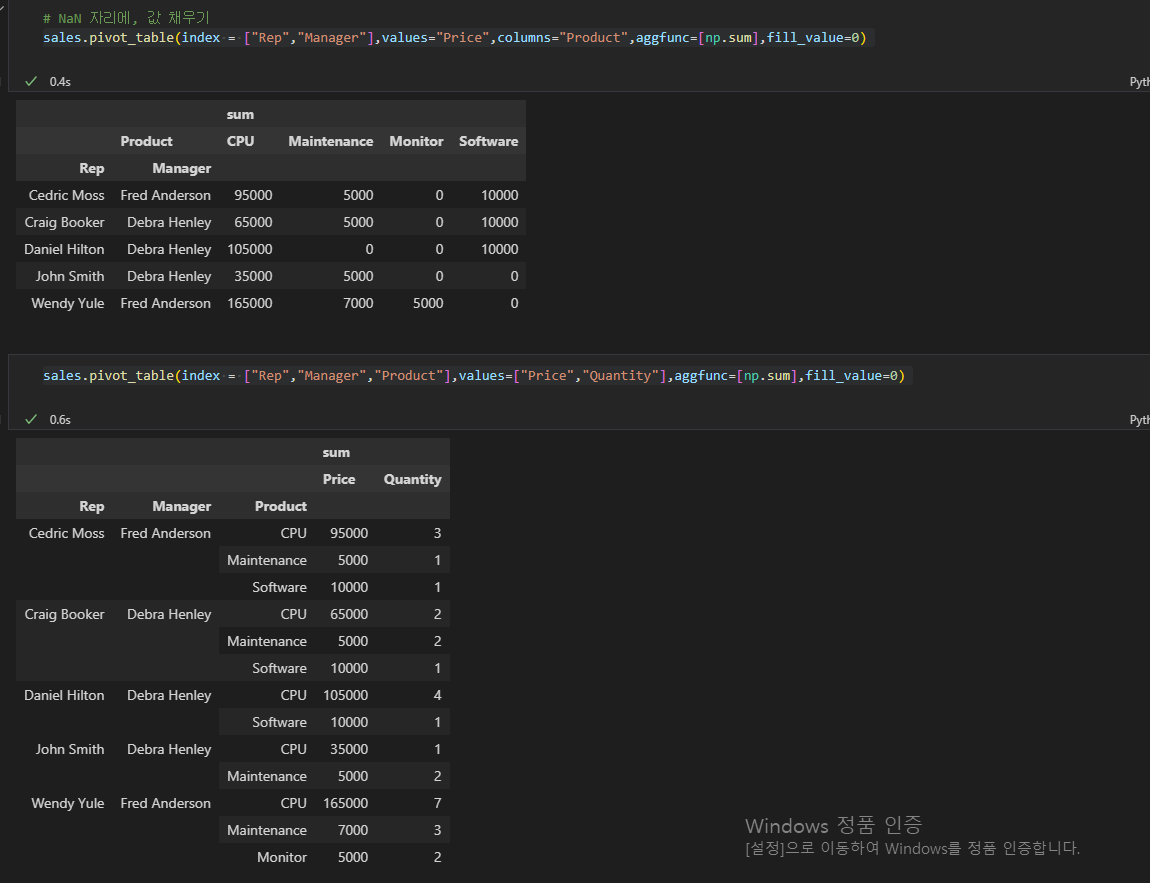
index , values , columns 값 모두 여러개 가능하고 [] 리스트 안에 작성해야한다. NaN 값이 있으면 후에 데이터프레임 전체 계산에서 object 데이터 형태에서 에러가 날 수 있으므로 fill_values 인자를 통해 원하는 값으로 채울 수 있다.
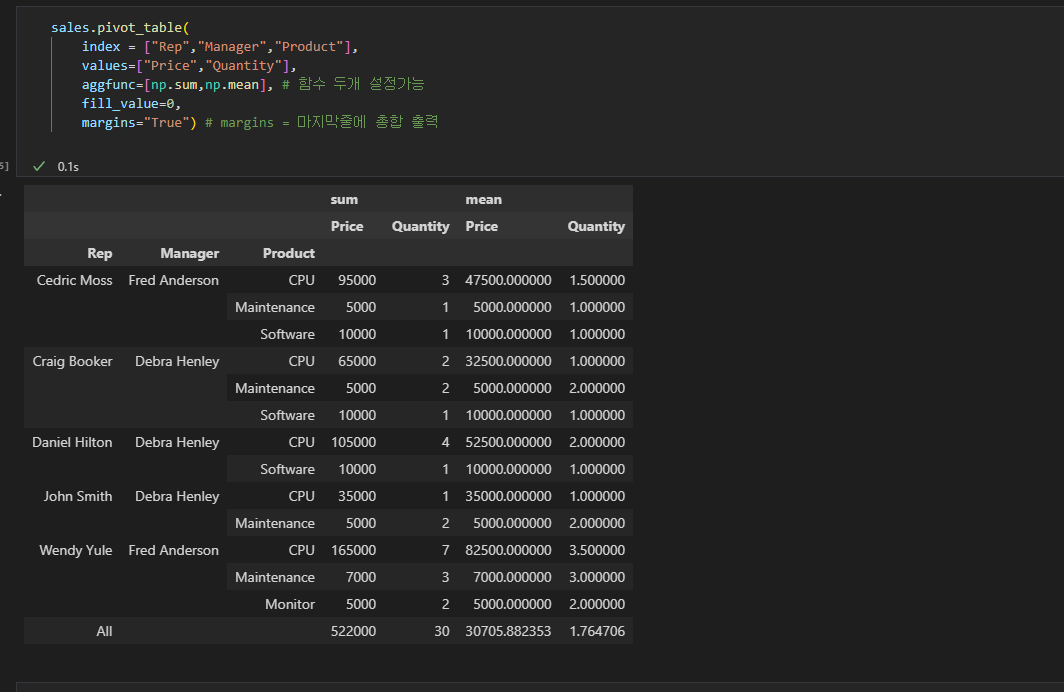
- margins = True 인자를 통해, 데이터프레임의 마지막 줄에 모든 총 계를 구할 수 있다.

화이팅!