서울시 각 구별, 범죄 현황과 경찰서 구역별 분석
1. raw data 전처리
-
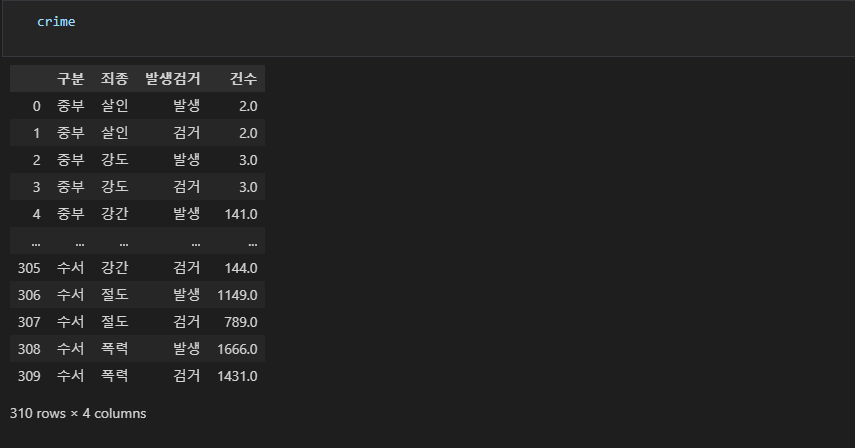
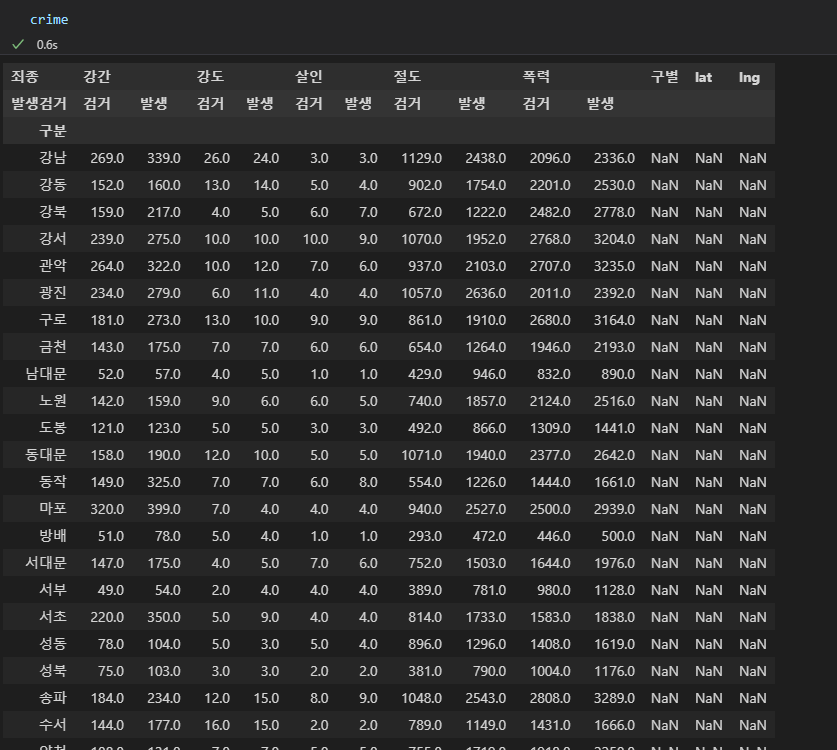
지역명 죄종 발생검거구분 건수 등이 나와 있고, 이를 각 지역별로 발생된 건수와 검거된 건수로 나누어 보기 위해 pvot_table 이용
-
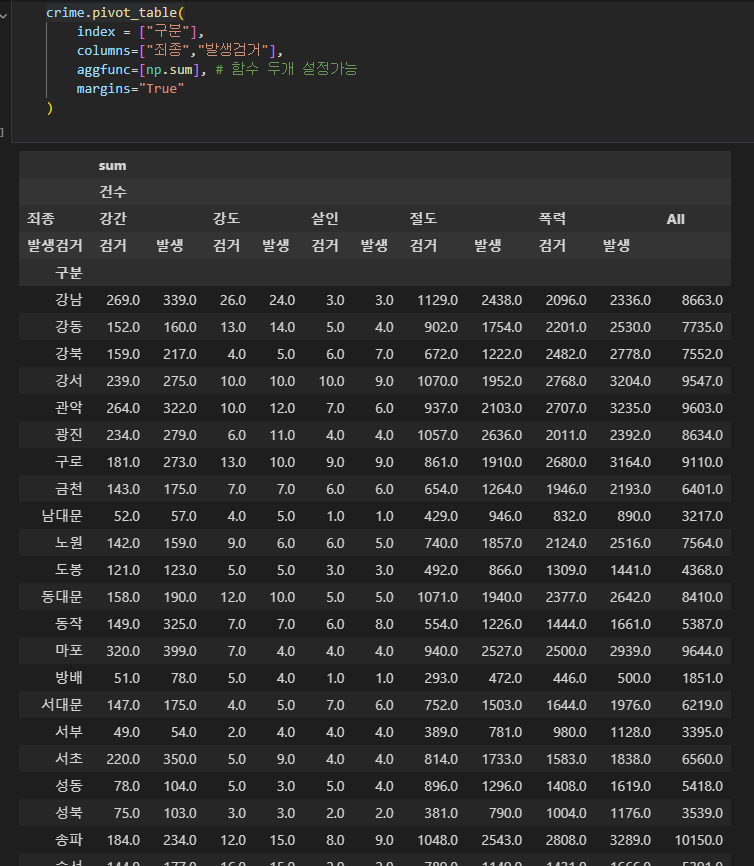
인덱스는 지역명, 컬럼을 죄종, 발생검거로 두어서 죄종별로 발생 / 검거 를 구분지어서 건수의 합계를 구함
-
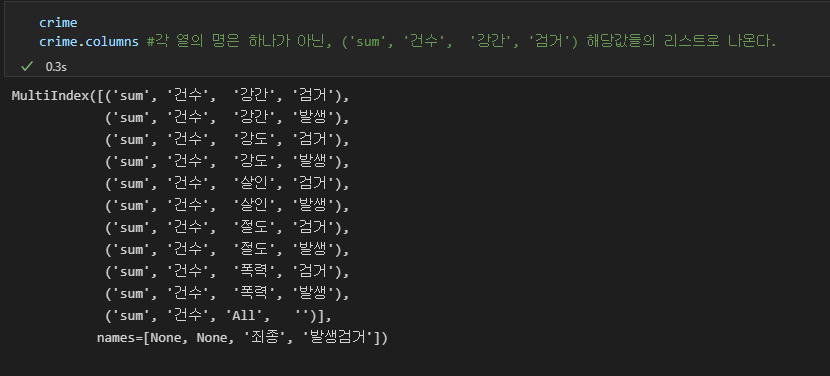
컬럼명을 조회해 보면, 리스트로 나오고 다중 컬럼으로 네가지 값이 들어있다.
-
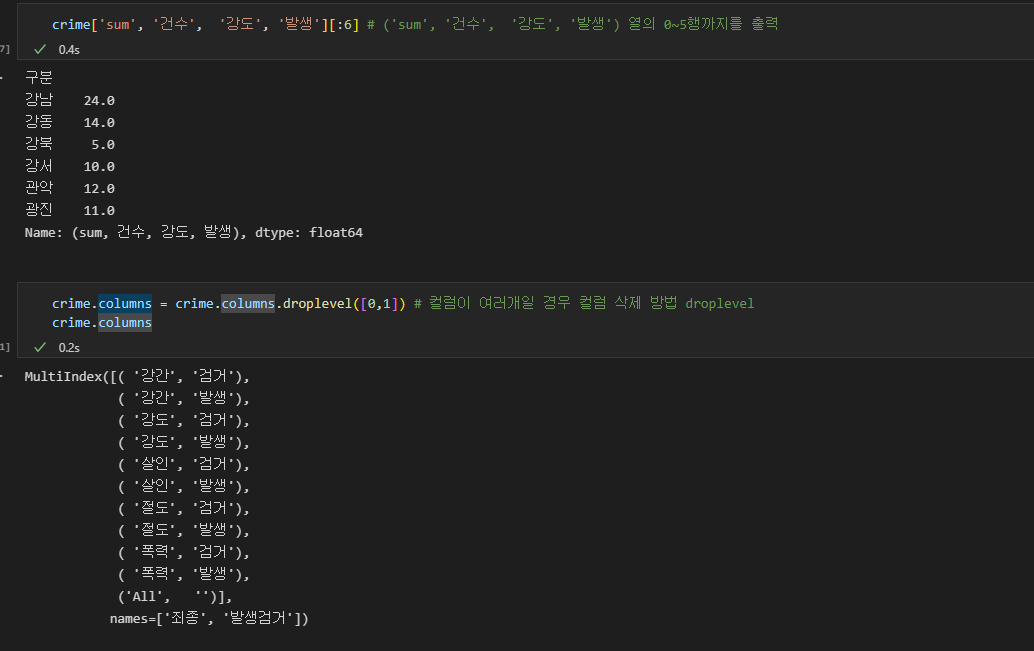
이 중 가장 위의 행 두 줄값은 필요없으므로 삭제하고 이때, 다중 컬럼 삭제는 df.cloums.droplevel[삭제할 열 인덱스] 로 한다.
- for 문의 간단한 복습, for문의 출력을 한줄로 포함하고 리스트에 담아서 출력하는 리스트 컴프리헨션
2. googlemaps 이용
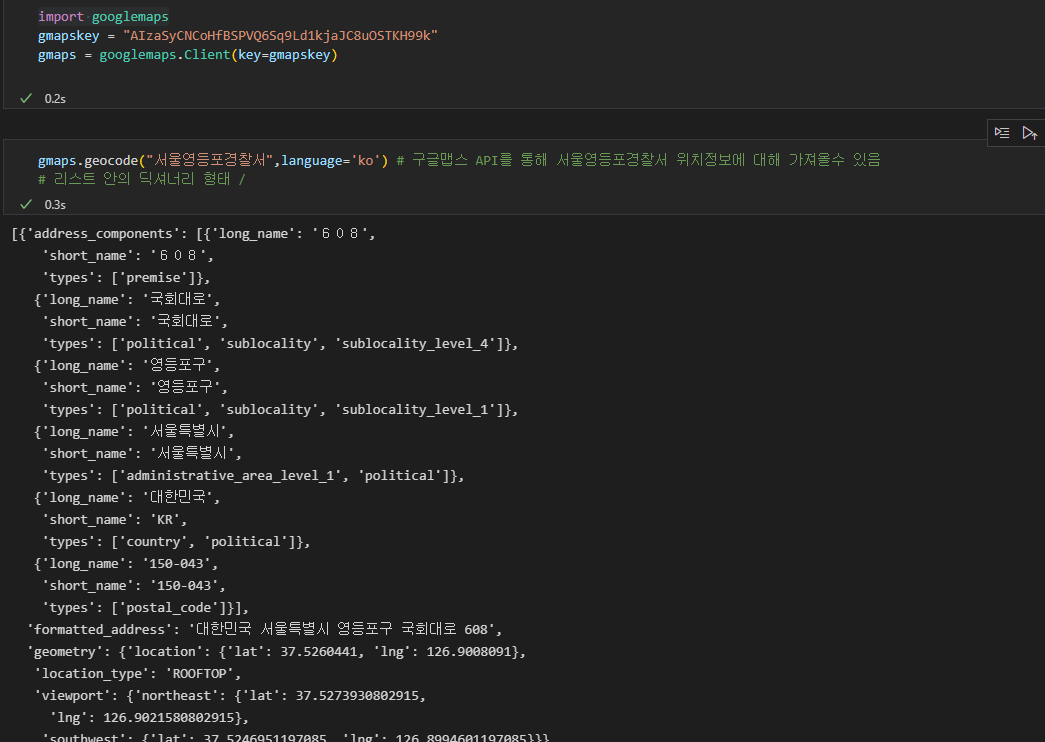
- googlemaps 를 이용하기 위해 불러오고 설치한다음, API를 설정하는 과정. 서울영등포경찰서로 테스트해서 제대로 위도 경도 및 위치가나오는지 확인한다.
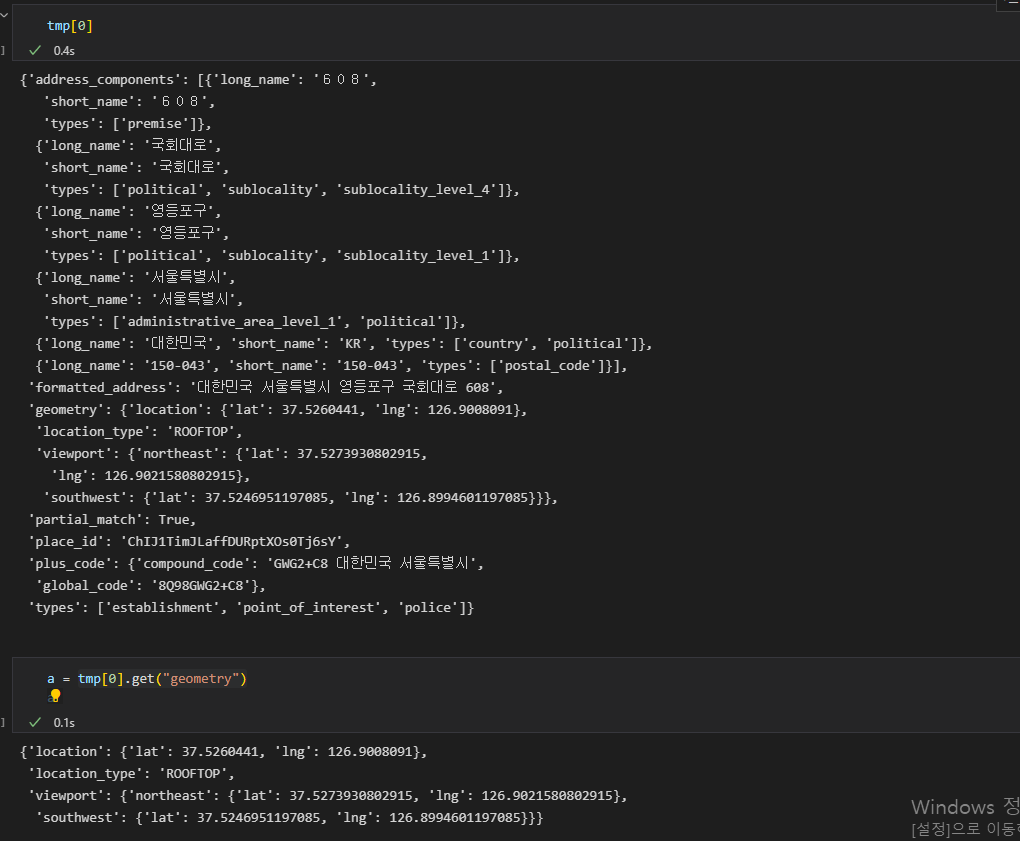
- 첫번째 리스트에 모든 값이 들어있고, 딕셔너리 형태로 값이 들어있다. .get() 으로 값에 접근한다.
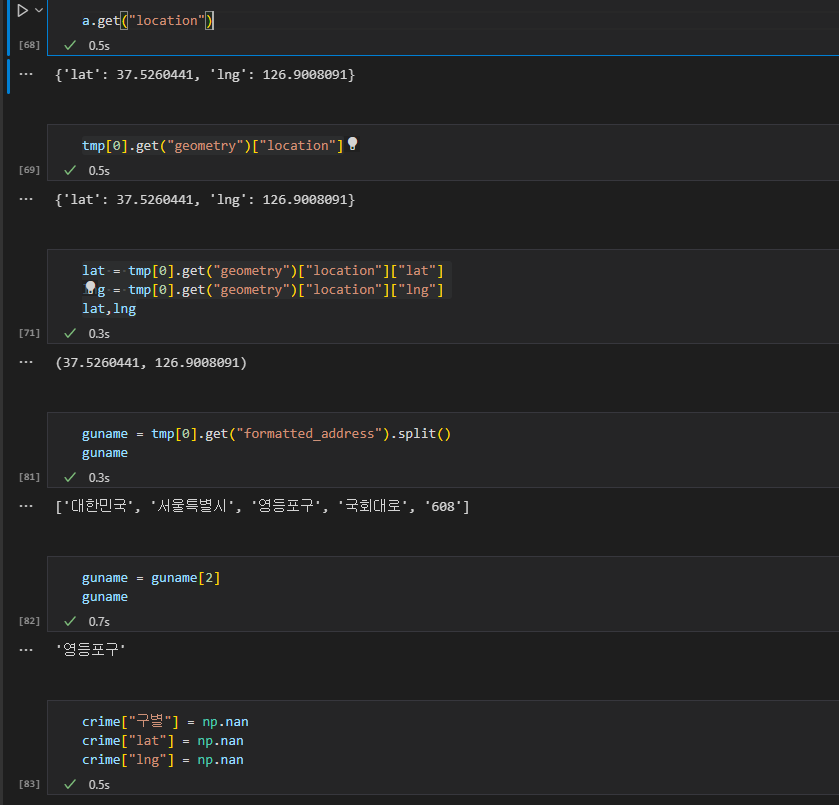
3. 구별, 위도, 경도 컬럼을 만들어 데이터 값 넣기
-
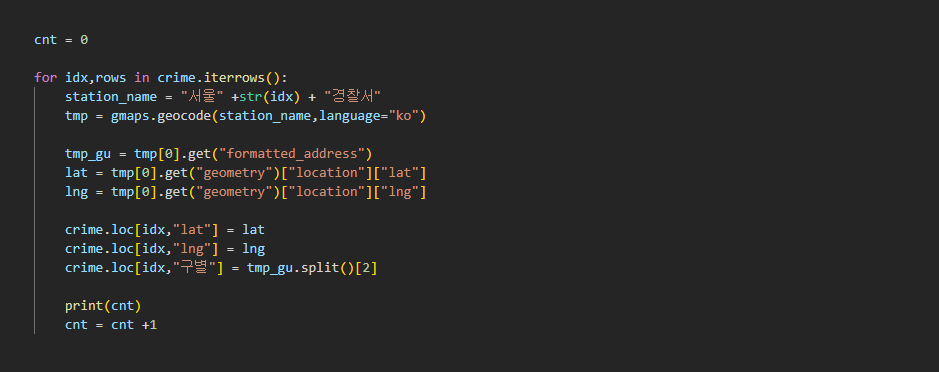
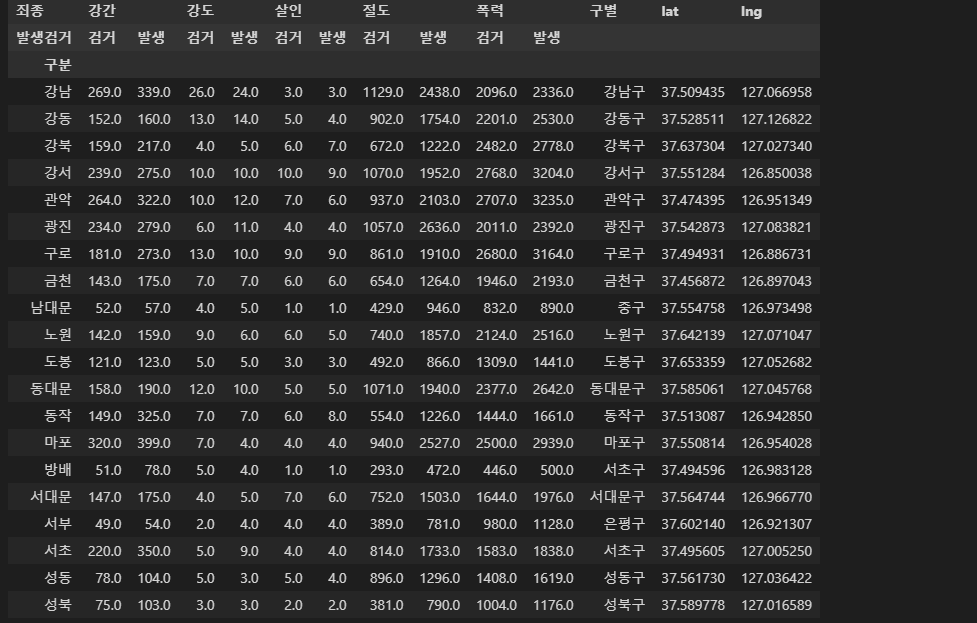
geometry의 values 값중에서 location에 접근하여 lat 와 lng 즉, 위도 경도 값을 가져온다. formatted_address에 저장된 주소 값에서, split으로 단어를 나눈다음 구 명이 담긴 인덱스 2 의 값을 가져오면 영등포구 만 가져올 수 있다.
-
crime 데이터 프레임에, 넘파이 사용하여 nan 값의 컬럼을 세개 만든 후 값을 넣는다.
-
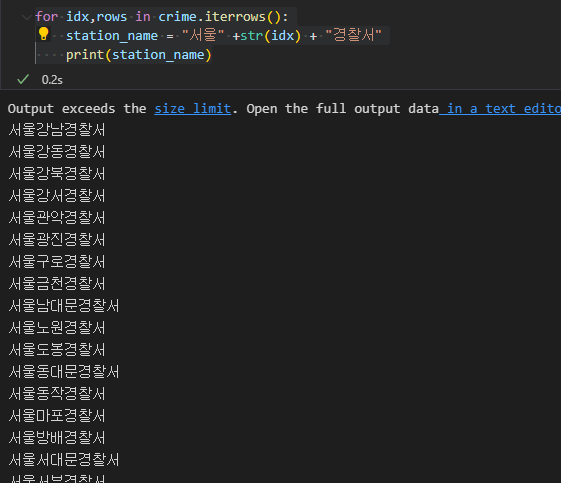
iterrows 를 이용해 인덱스와 컬럼값을 출력할 수 있다. 이때, 서울영등포경찰서 처럼 검색하여 주소를 가져오기 위해 "서울" 과 "경찰서" 를 추가하여 for문을 돌린다.
-
lat 와 lng 값을 loc를 이용해 각 행의 컬럼 데이터 값으로 넣고 구별 컬럼의 값에도 데이터를 넣는다.

화이팅!