파이썬 / 데이터 분석
1.7/4 기록 "파이썬 공부"
컴파일러와 인터프리터 컴파일러example.py 란 파일로 저장↓컴퓨터가 읽을 수 있도록 기계어로 바꾸는 과정을 하는것 : 컴파일러컴파일한다example.class 등 확장자명이 바뀌어 새로운 파일이 생성됨1001 00110110 01011001 1100내용을 입력하세
2.7/7 기록 "파이썬 공부"
ㅡㅡㅡ
3.7/8
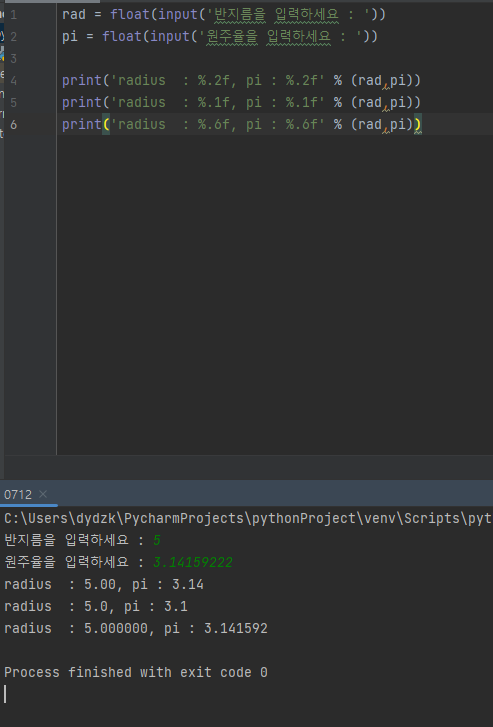
print 함수를 이용해 원하는 내용을 출력 print('') print 함수를 이용해 '' 안에 쓰는 글은 문자열로 받아들여 그대로 출력됨'' 안에 출력하고 싶은 내용을 입력 후 , 콤마를 쓰고 그 후에 변수명을 쓰면 '' 안의 문자열 뒤에 변수명이 출력됨. 연속된
4.7/9
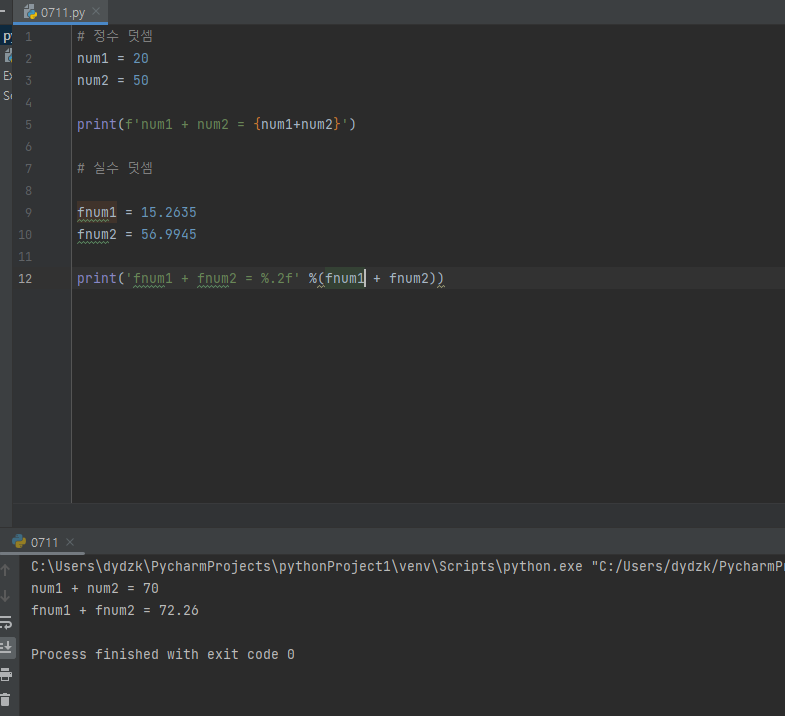
연산자의 종류산술 연산자 : + - \* / %(나누기에서 몫만) //(나누기에서 나머지만) \*\*(몇제곱) 할당 연산자 : = +=(+한값을 할당) -= \*= /= %= //=비교 연산자 : > >= <= < ==(같다) !=(같지않다)논리 연산자
5.7/10
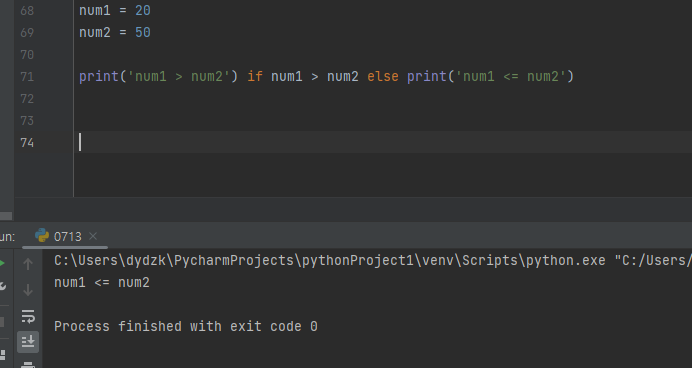
A if 조건식 else B : 조건식의 결과가 True 이면 A를 실행하고 그렇지 않은 경우 B를 실행한다.A 와 B 자리에 바로 print 를 넣어, 출력이 되도록 하였다.
6.7/11
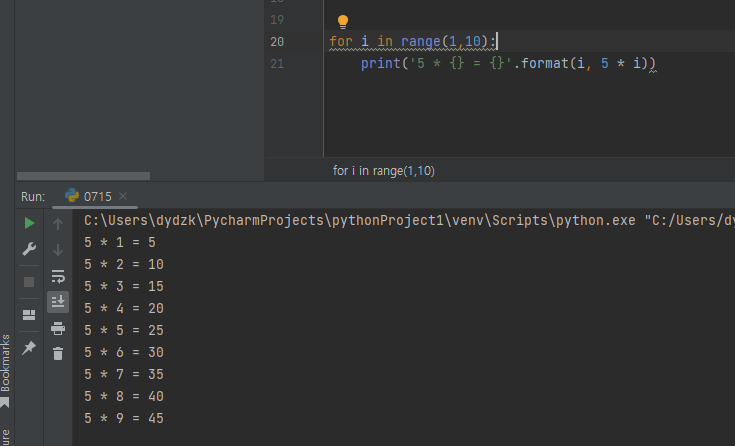
1.반복문(1) for 문(2) while 문
7.7/12
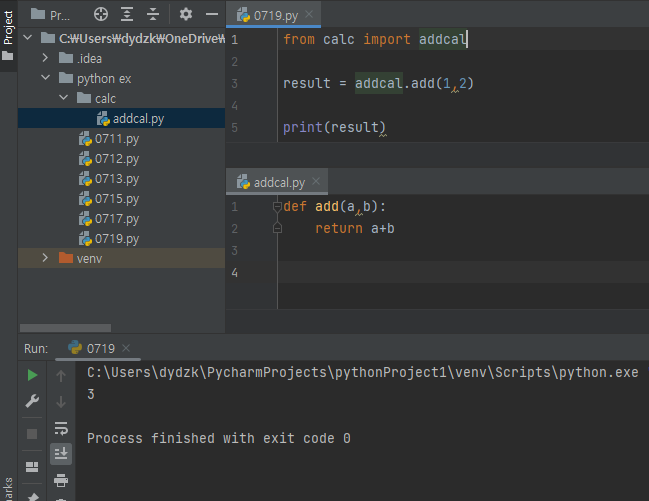
패키지와 모듈클래스와 객체객체의 속성과 기능객체와 메모리
8.7/13
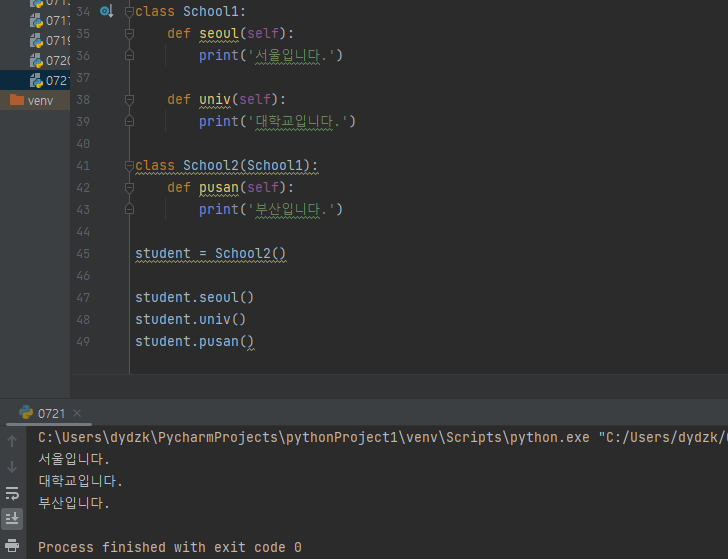
클래스 상속생성자다중 상속오버라이딩
9.7/14
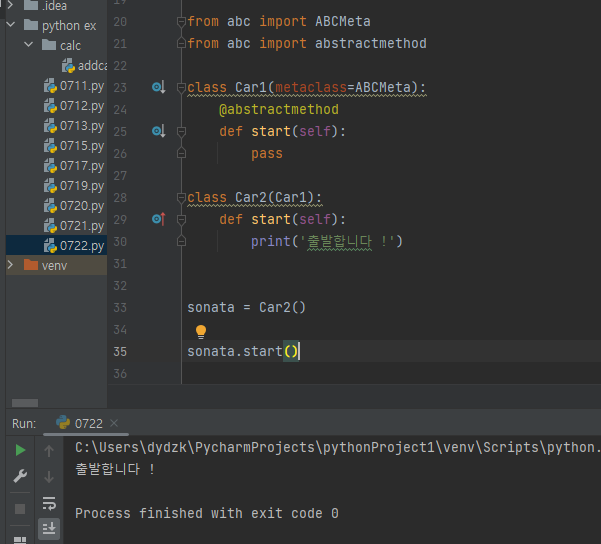
ㅏㅏ
10.7/15
텍스트 파일 쓰기텍스트 파일 읽기, 열기with ~ as 문wirtelines(), readlines(), readline()
11.7/17
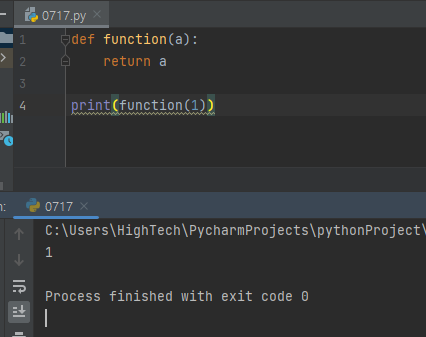
1. 함수
12.7/19
;
13.07/20

피보나치 수열팩토리얼군수열순열
14.7/21
조합확률
15.7/22
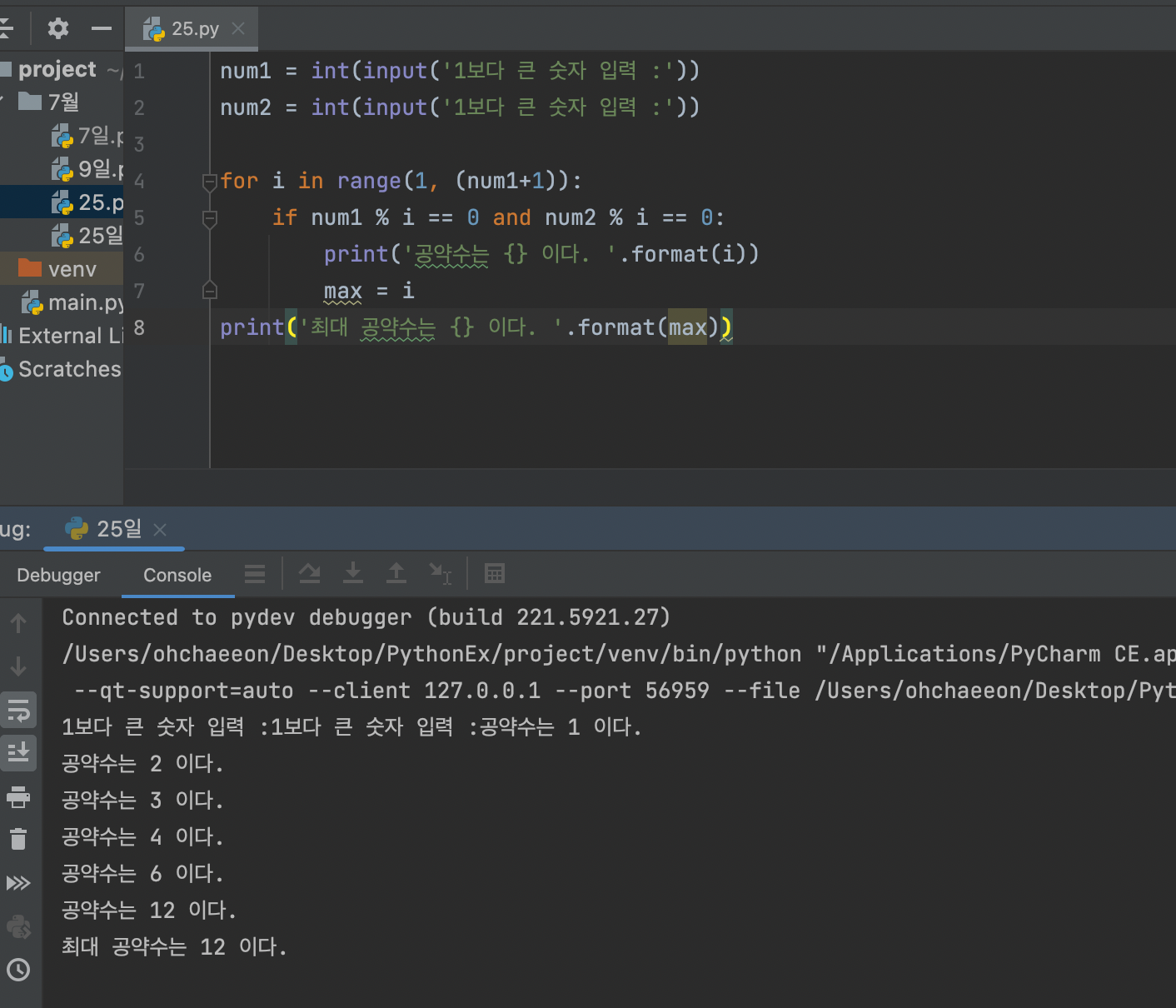
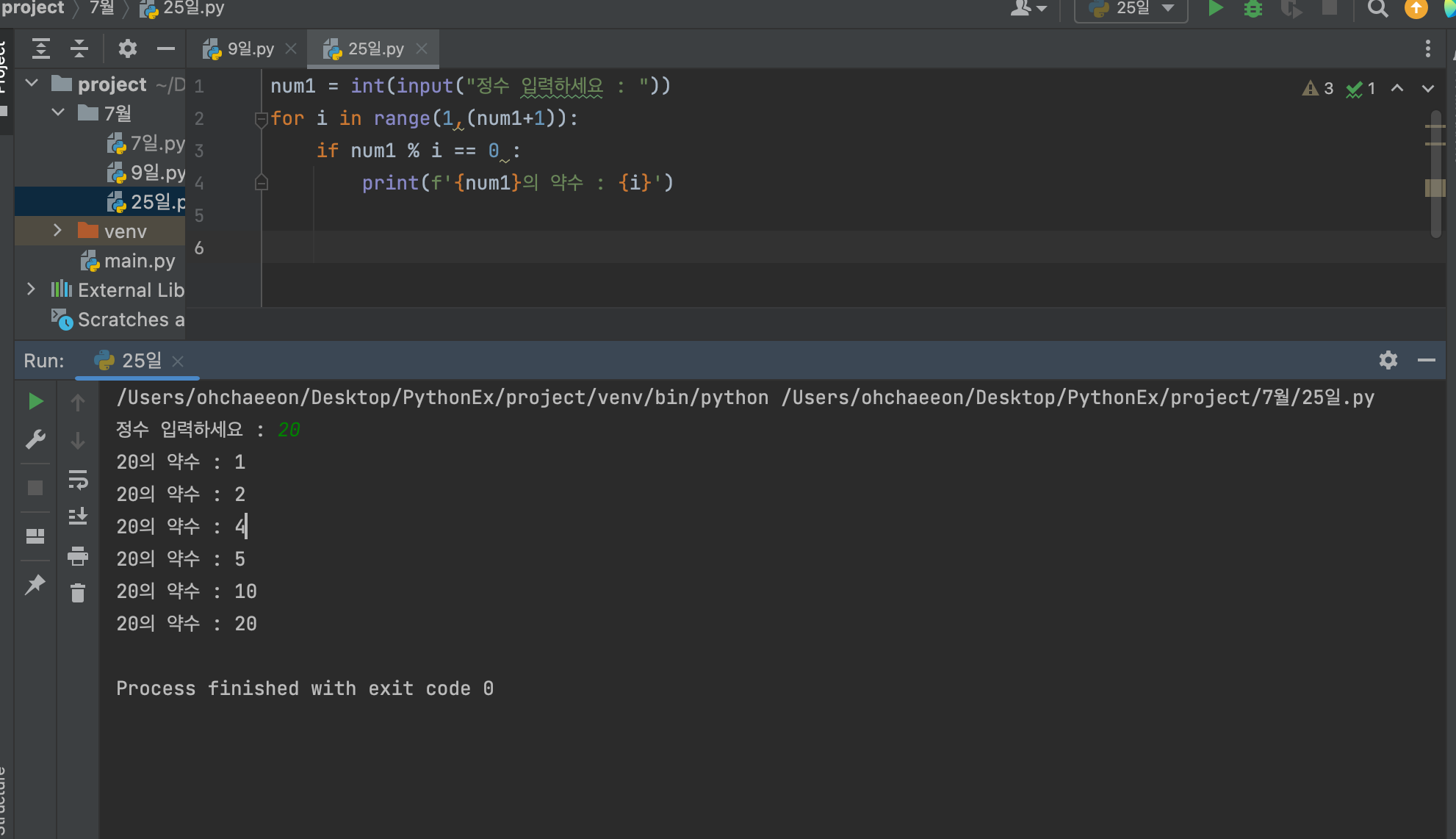
EX) 20의 약수 = 1,2,4,5,10,20 등 20을 나누어 떨어지게 하는 모든 수 for 문 내의 i 를 반복해서 돌아갈때 나머지가 0이 되는 수를 찾으면 전부 약수가 된다.EX) 2,3,5,7,11,13,17,19 ... 1과 2/3/5..처럼 약수가 1포함
16.7/25
자료구조리스트(1) for 문(2) while 문enumerate
17.7/26
리스트 추가리스트 삭제리스트 연결 및 정렬리스트 순서바꾸기와 슬라이싱
18.7/27
튜플튜플 길이 결합튜플 슬라이싱과 정렬for 문while 문
19.7/29
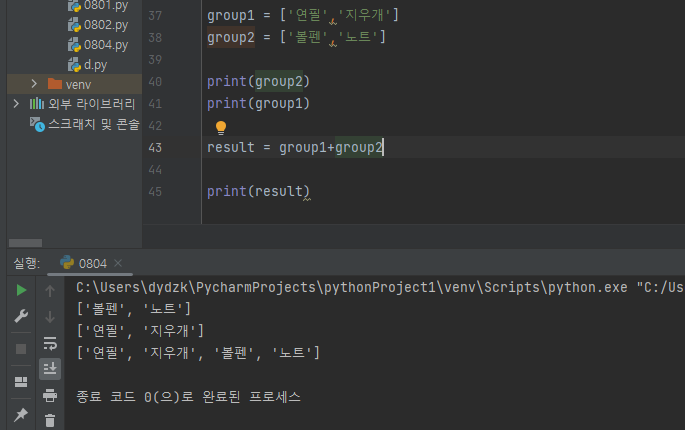
(1) extend()함수리스트에 다른 리스트를 연결시킬수 있다. 덧셈 + 연산자를 이용해 expend 함수의 기능을 그대로 할 수도 있다.
20.08/01
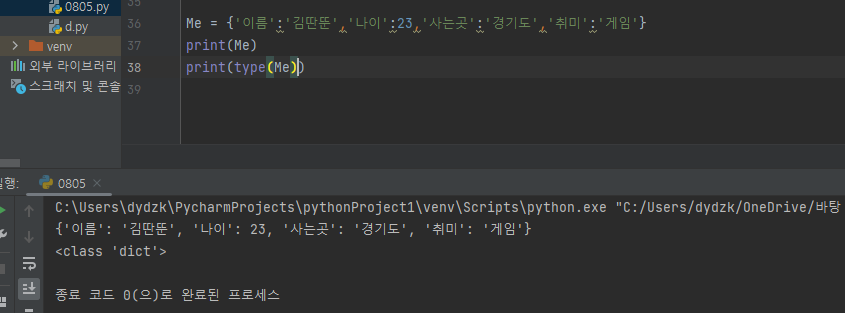
딕셔너리 조회딕셔너리 추가딕셔너리 수정딕셔너리 삭제
21.08/02
22.08/04
23.08/05
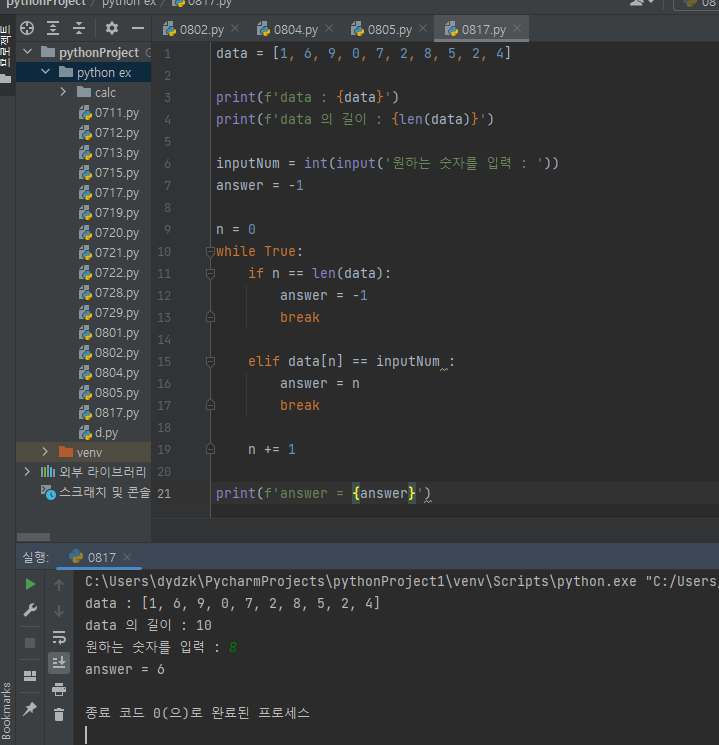
어떤 문제를 풀기위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현한것을 말한다. 문제풀이에 필요한 계산절차나 처리과정의 순서를 말한다고 보면 된다. 선형으로 나열된 데이터를, 순서대로 스캔하면서 원하는 값을 찾아내는 방법. 데이터가 나열되어 있는 리스트에서, 해당
24.08/16
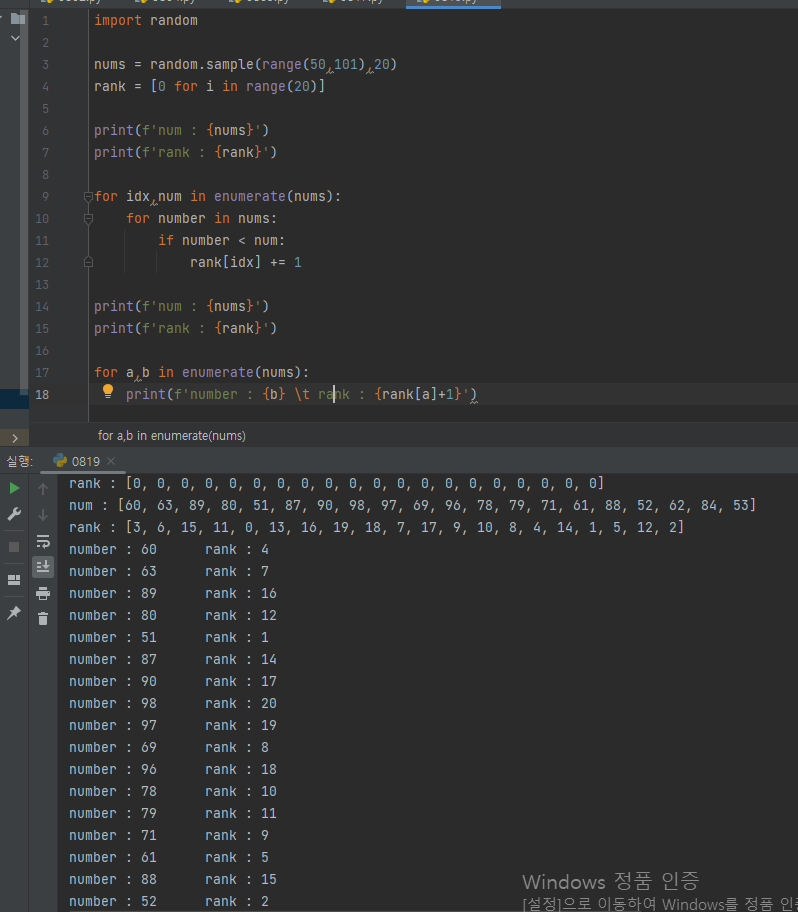
데이터의 나열에서, 앞의 값과 비교하면서 크고 작음을 이용해 순서를 알아낸다. 데이터의 나열에서, 나열된 숫자만큼 0으로 채워진 리스트를 하나 만든다. 앞의 값과 뒤의 값을 비교해서 작은수의 인덱스 값에 해당하는 0으로 채워진 리스트 데이터값에 +1을 한다. for 문
25.08/17
최대값최소값최빈값근삿값
26.08/21
평균재귀하노이병합 정렬퀵 정렬
27.08/22
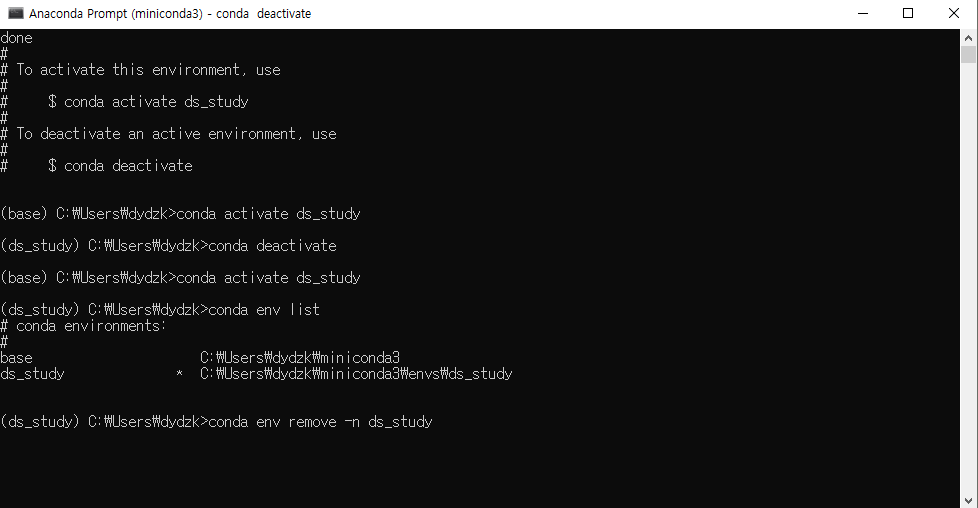
미니콘다 설치 / 콘다 환경설정vscode / 주피터 노트북데이터 읽기pandas
28.08/23
pandas dataframe dataframe 은 series들이 여러개 합쳐진 형태로, 여러개의 행과 여러개의 열의 조합이다. index, value, cloumn 으로 구성된다.
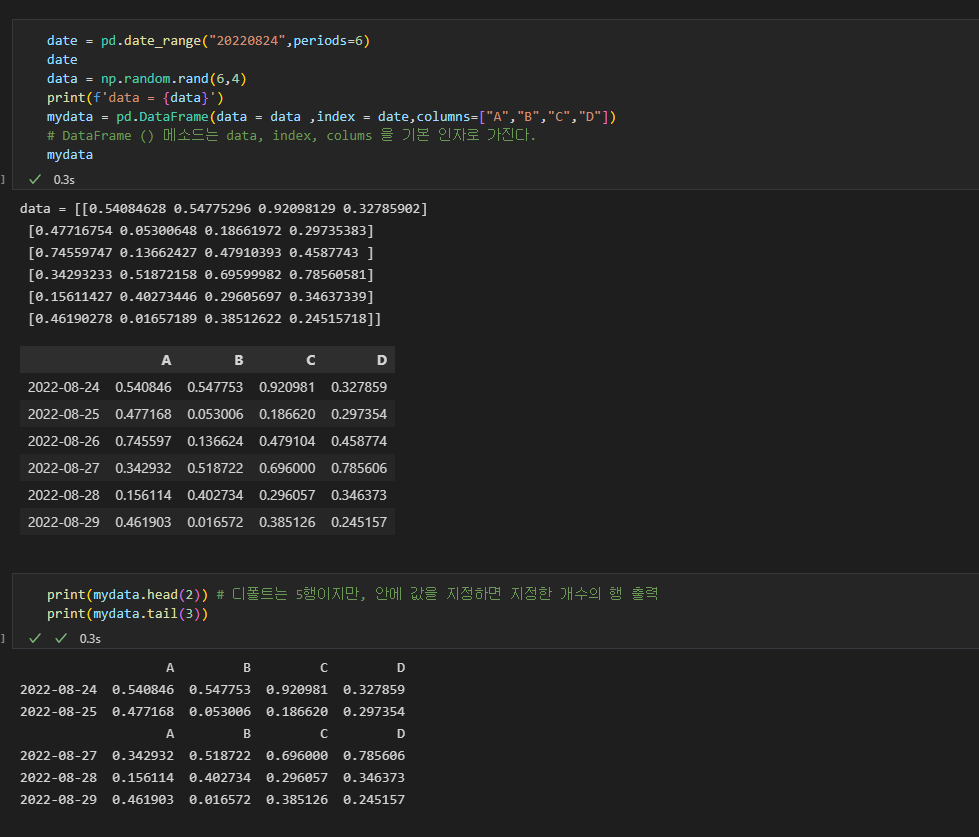
29.08/24
pandas 를 사용하기 위해, 반드시 import pandas를 해주어야 하고 as pd 는 앞으로 판다스를 pd로 줄여 사용하겠다는 의미이다. 판다스를 이용해 csv파일(데이터들이 ,로 구분되어진 파일 형태)을 읽어들일수 있다. 파일을 불러올때는 cctv = pd.
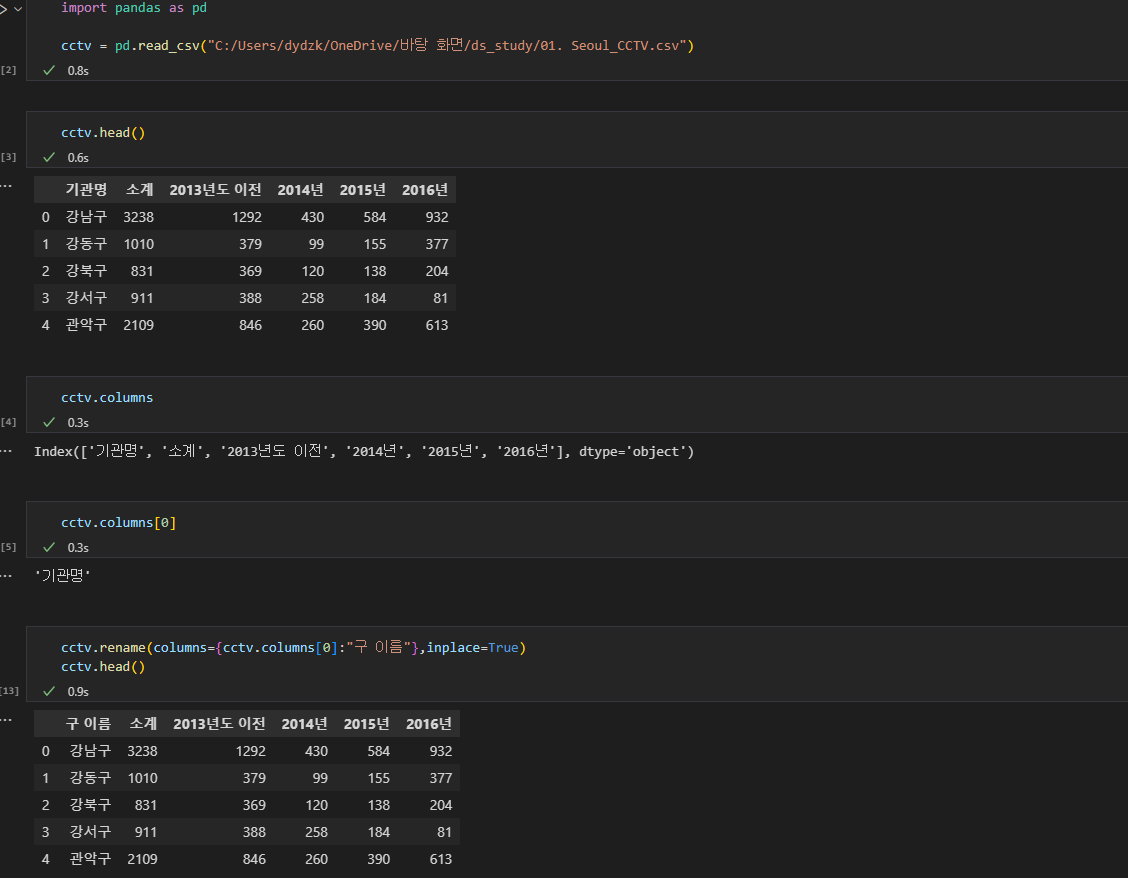
30.08/25
서울 각 구별 CCTV 설치 현황 데이터프레임과 서울 각 구별 인구수에 대한 데이터프레임을 병합한다. 이때, 구 이름 을 기준으로 병합하며 같은 구이름을 가진 행의 각 칼럼별 값 들이 합쳐지게된다. 각 구의 인구수별 CCTV 현황에 관한 상관관계를 분석하기 위해서 년도
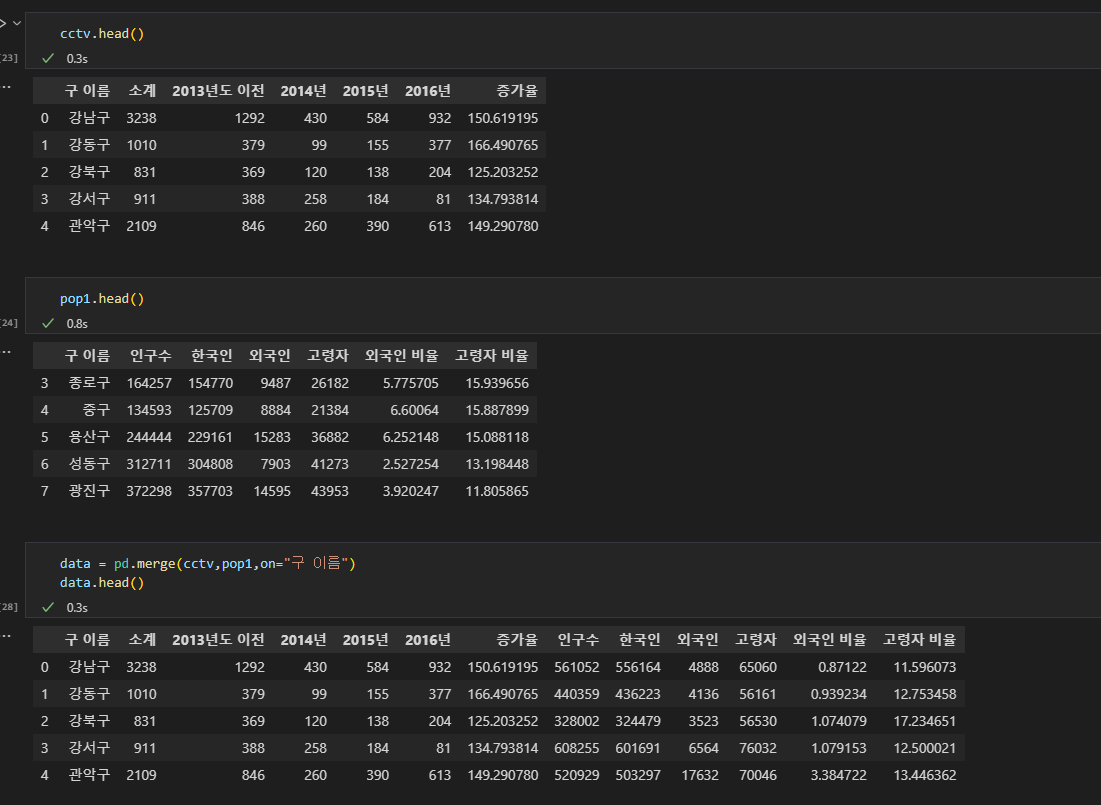
31.08/26
업로드중..
32.08/29
업로드중..
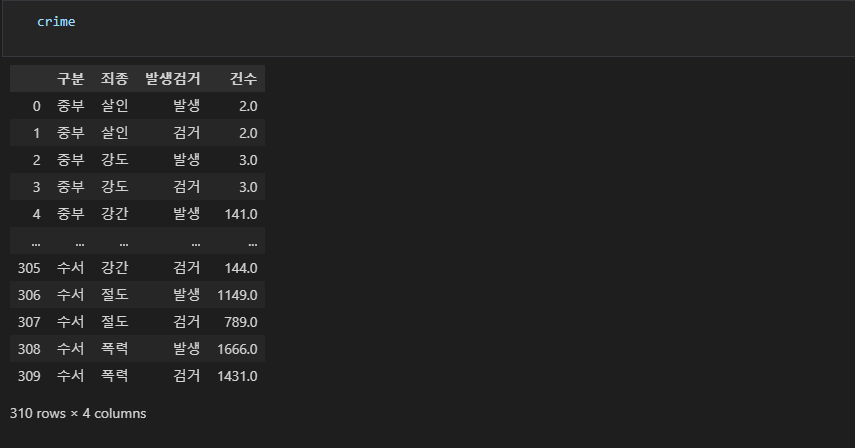
33.08/30
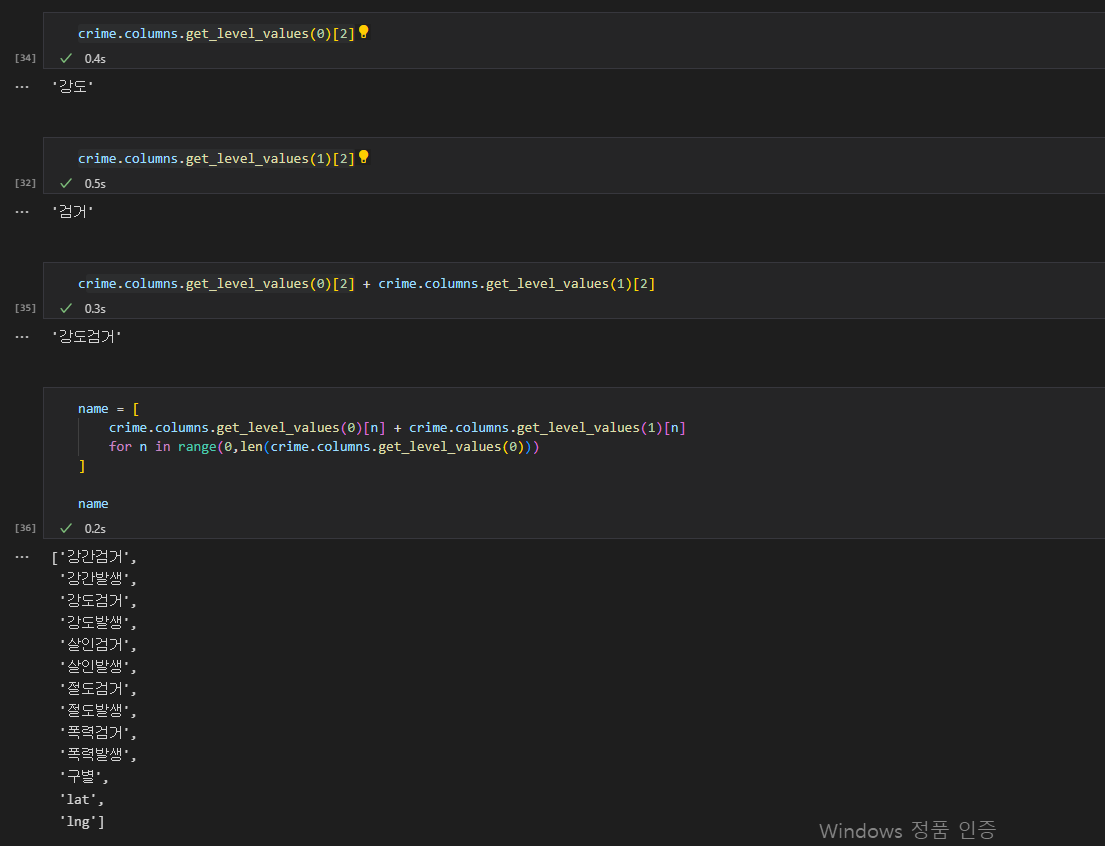
df.cloumns 로 컬럼에 접근할 수 있고, 각 컬럼명들은 리스트에 담겨있다. 그러므로 각 리스트의 인덱스를 지정하여 원하는 컬럼값에 접근할 수 있다.두줄로 나뉘어 있는 두개의 컬럼 명을 합쳐서 하나로 만들기 위해, 첫번째 열의 단어와 두번째 열의 단어를 (둘다 스
34.08/31
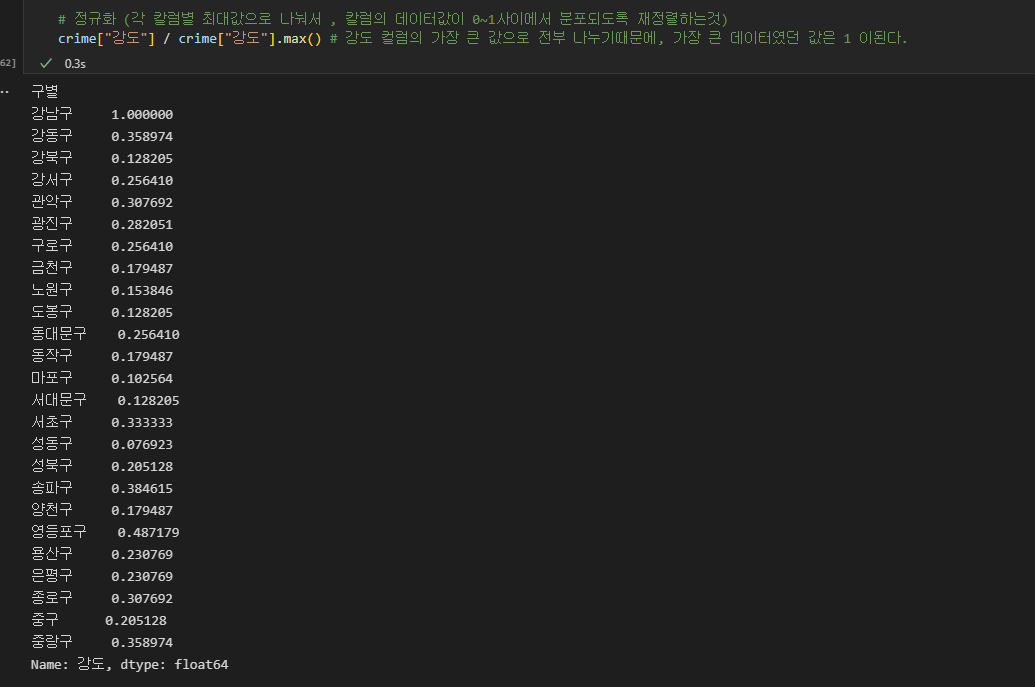
4\.
35.09/01
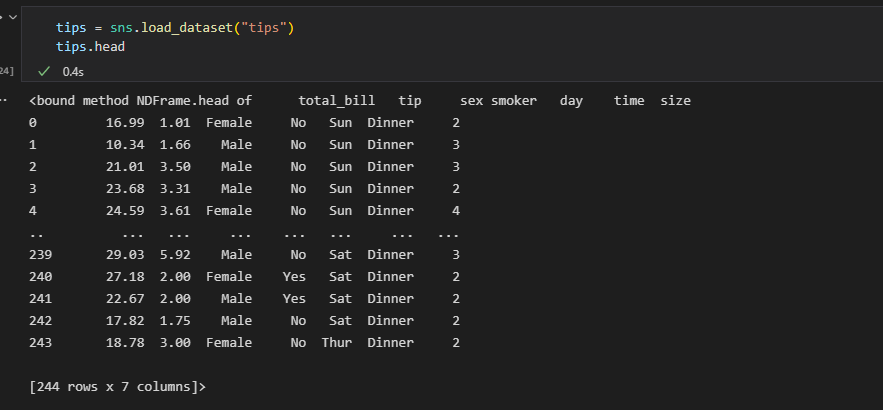
seaborn 패키지에서 몇가지 예시 데이터셋을 기본적으로 내장하고있다. 그중 tips라는 데이터셋을 가져와서 데이터 정리 연습해보았다.
36.09/05
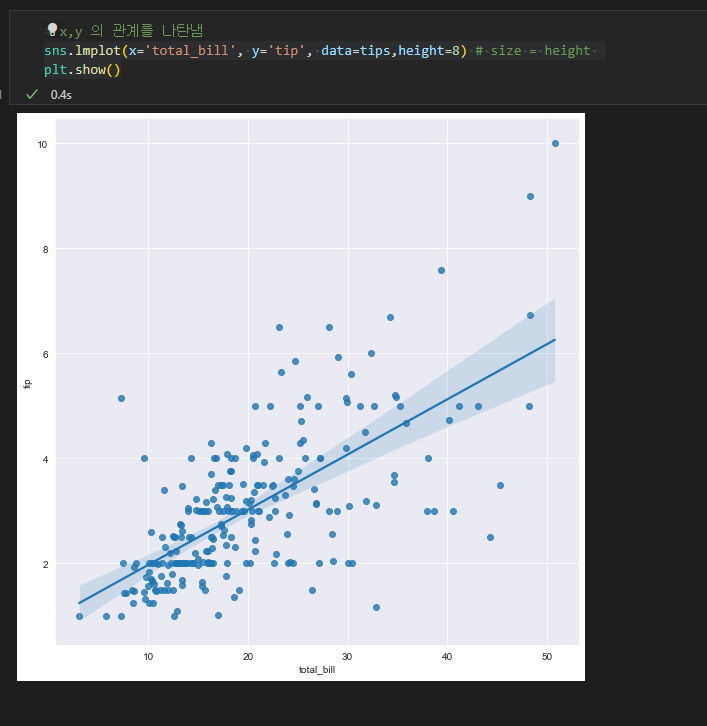
x,y 에 지정한 두 값의 관계를 나타낸다. 즉, total_bill 값과 tip 의 값을 점으로 그래프에 나타내고, 그것을 평균화하여 직선을 그린것. 전체적으로 x값에 따라 y 값의 분포가 어떤식으로 나타나는지 알수있다. hue 인자를 추가하여, smoker 인지 아
37.09/06
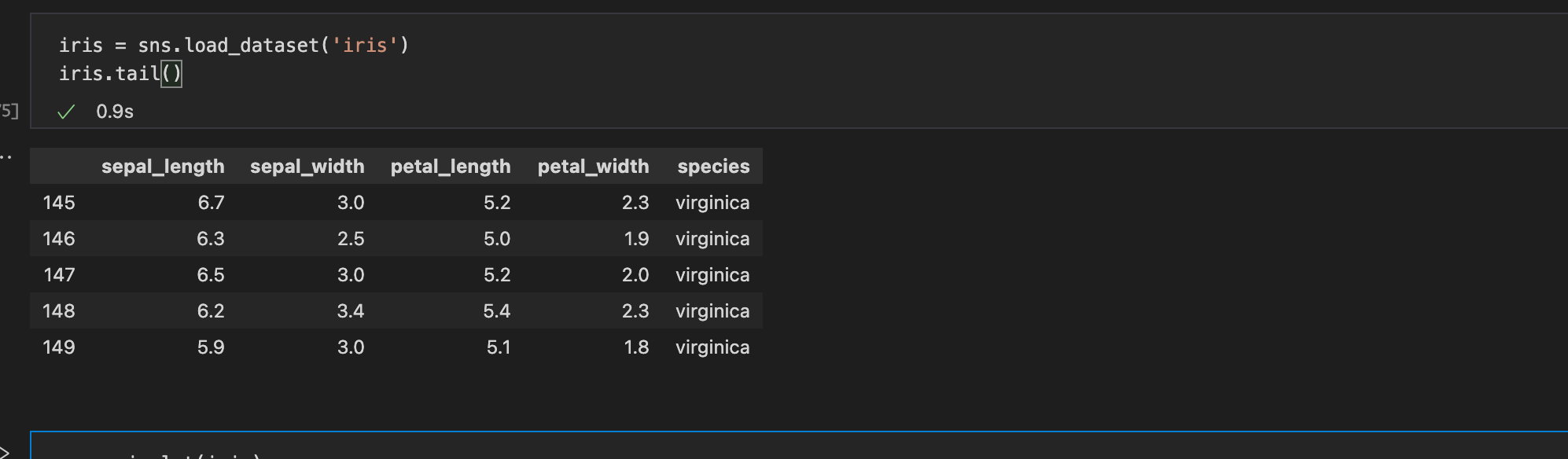
꽃잎 이미지를 통해, 길이와 너비를 분석하고 사진에 맞는 꽃잎의 카테고리를 분류해둔 데이터셋이다. pairplot() 을 하면, iris 데이터셋의 모든 컬럼을 각 x,y축에 대해 표현한다. scatter 나 막대그래프 형으로 표현됨.ticks 옵션을 주면 그래프에서
38.09/07
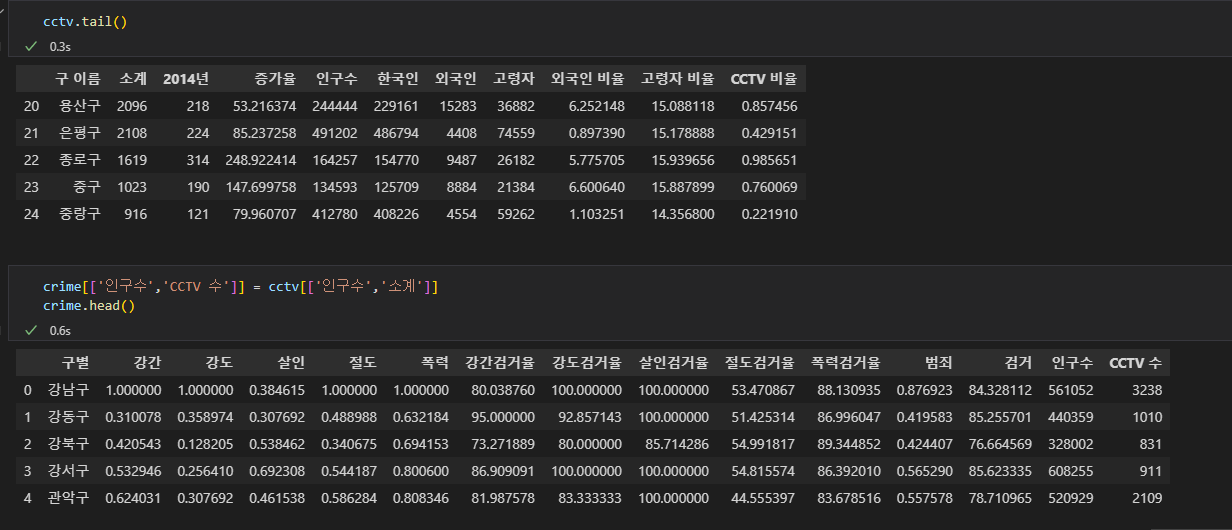
crime 데이터에, CCTV 데이터셋의 총 인구수 컬럼과 총 CCTV 수의 컬럼을 추가한다. pairplot 의 옵션, kind 를 바꾸면 그래프의 형태를 바꿔서 볼 수 있다.가장 흔하게 보는 타입은, reg로 상관관계를 보는것이다. x,y 축에서 비교해볼 값을 설정
39.09/08
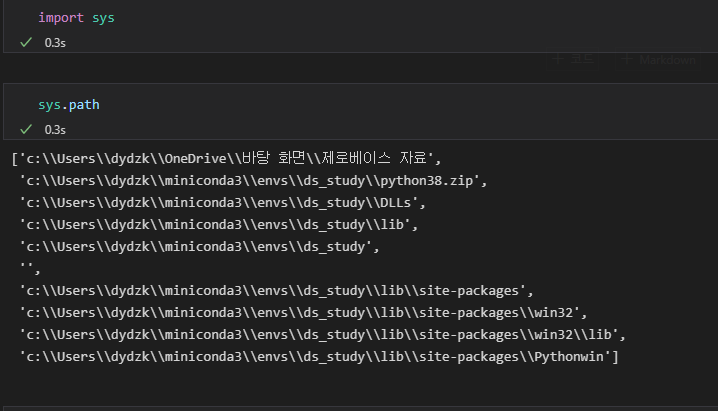
직접 만든 모듈을 vs code에서 사용하기 위해서 import 해주어야한다. 그때, 외부 모듈 파일을 특정경로에 넣은 후에 vs code에서 import 해야하는데 해당 경로를 알기 위해서 sys를 예시로 import 했다. sys.path 를 통해 sys가 있는 위