1. 두 가지 컬럼을 나타내기 위해 두 줄로 정리된 컬럼명 정리
-
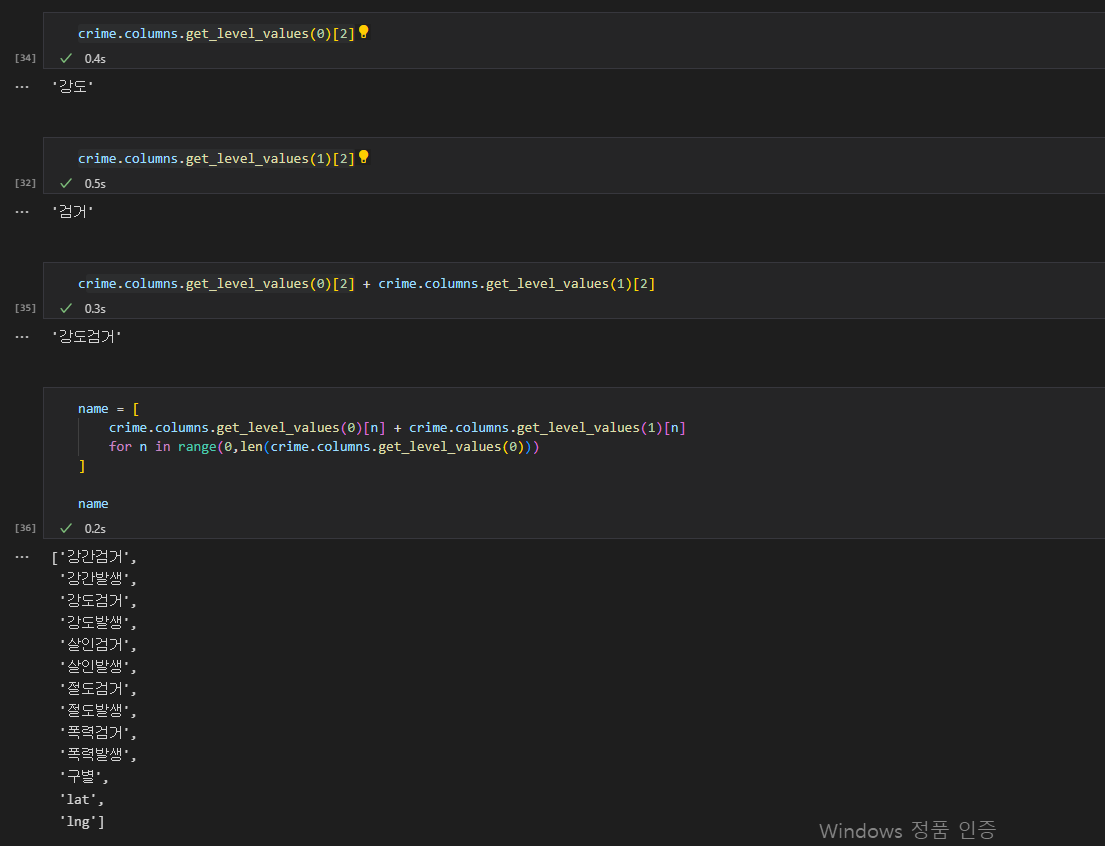
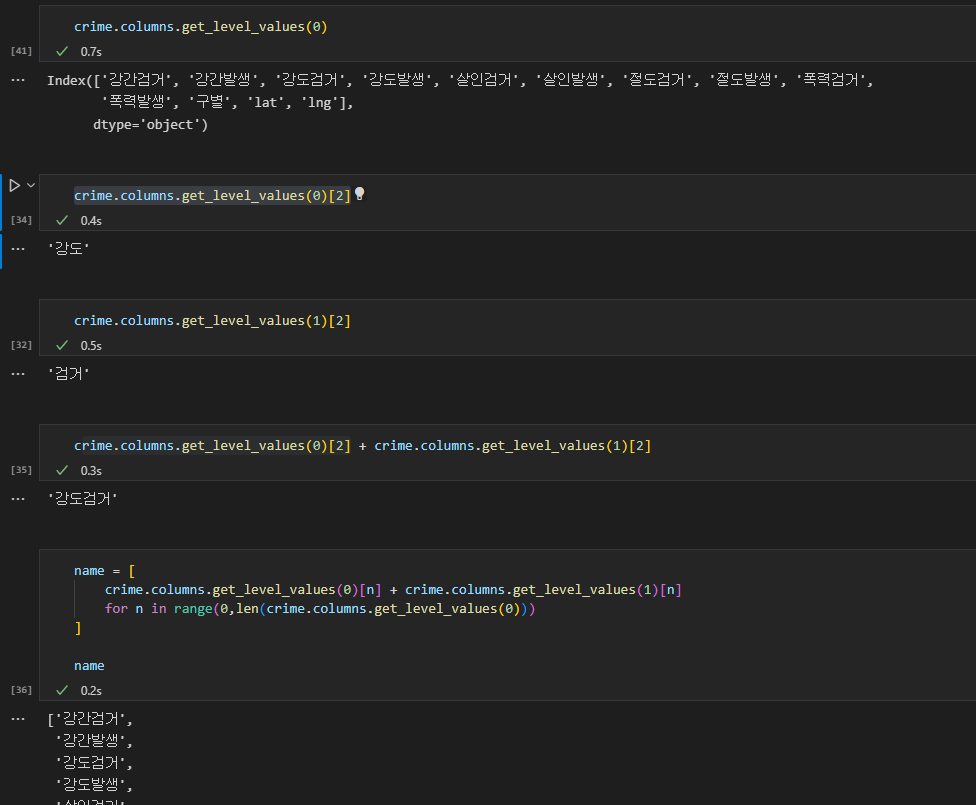
df.cloumns 로 컬럼에 접근할 수 있고, 각 컬럼명들은 리스트에 담겨있다. 그러므로 각 리스트의 인덱스를 지정하여 원하는 컬럼값에 접근할 수 있다.
-
두줄로 나뉘어 있는 두개의 컬럼 명을 합쳐서 하나로 만들기 위해, 첫번째 열의 단어와 두번째 열의 단어를 (둘다 스트링 값이므로 + 이용) 합쳐서 컬럼명을 새로 생성한다.
-
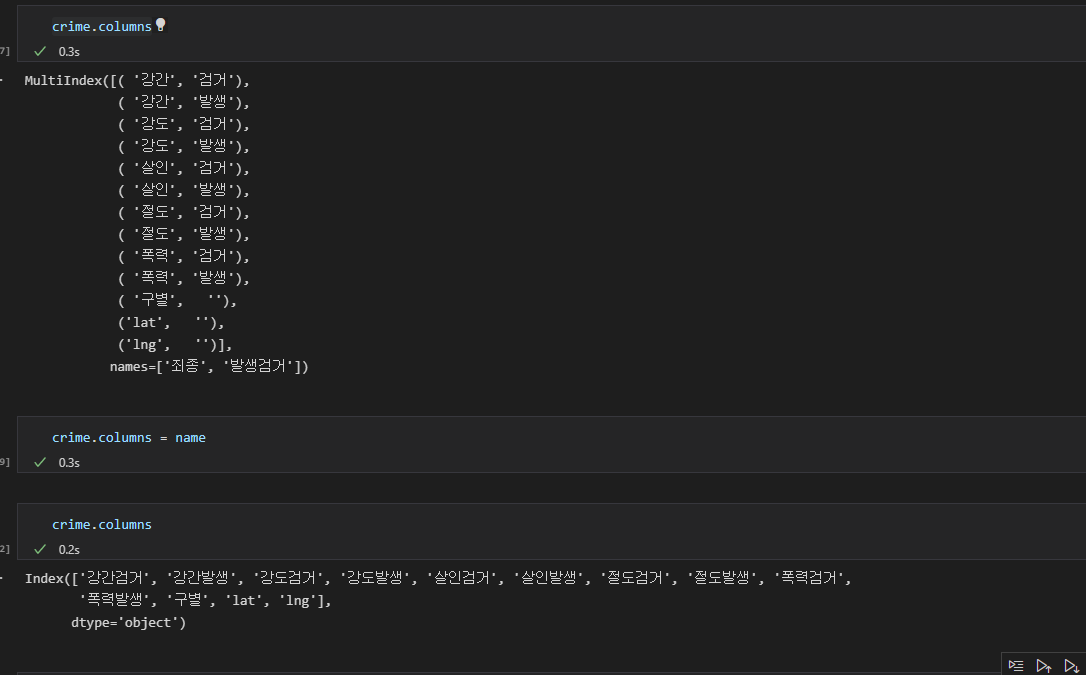
리스트 컴프리헨션을 이용하여, 합쳐서 새로 만든 컬럼명을 리스트에 모아두고 그것을 새로운 컬럼명으로 지정한다.
-
원래 컬럼명은 [(첫째 열의명 , 두번째 열의명), (첫째 열의명 , 두번째 열의명)] 의 형태로 리스트에 담겨있었는데, 이를 하나로 합쳤으므로 [컬럼명1, 컬럼명2..] 으로 컬럼명이 한 단어로 바뀌었다.
2. 각 죄목별 검거율 컬럼 생성하기
-
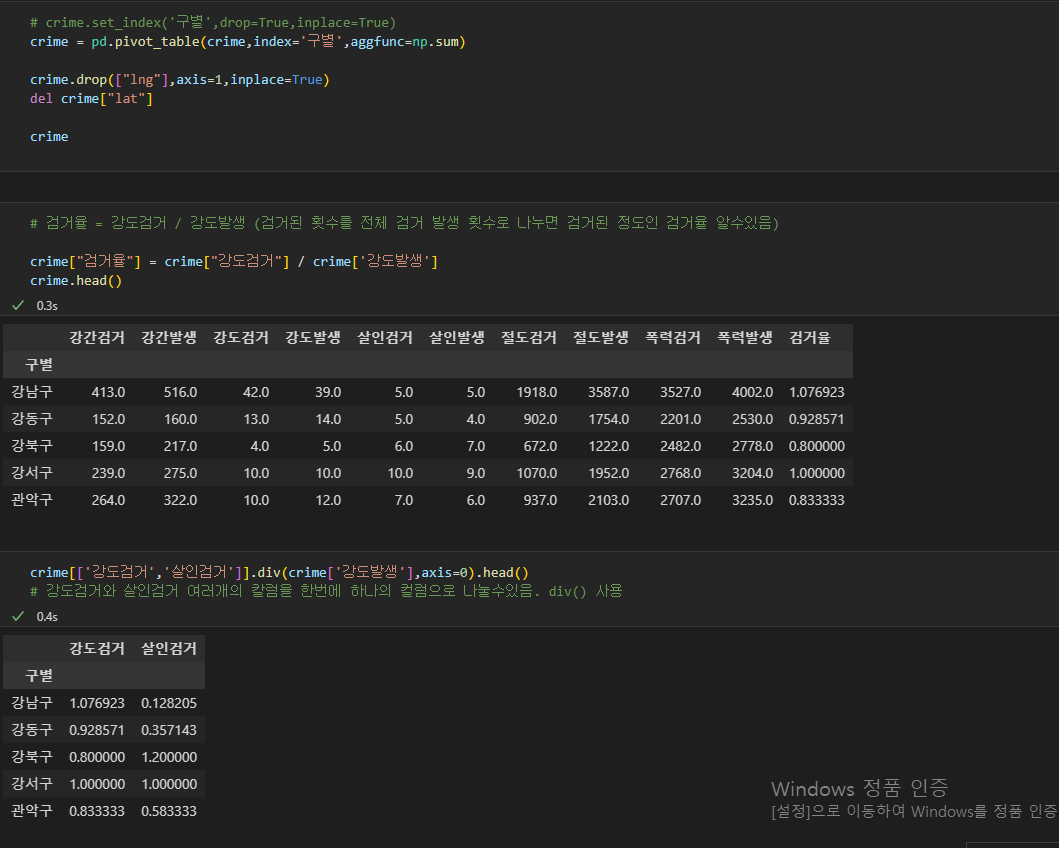
검거율 = 각 죄목 검거 된 횟수 / 각 죄목 전체 발생수 로 정하여 새로운 컬럼을 생성한다.
-
여러개의 컬럼을 하나의 컬럼 값으로 나눌 경우 div()함수 사용하여 한번에 여러개의 컬럼도 나눌 수 있다.
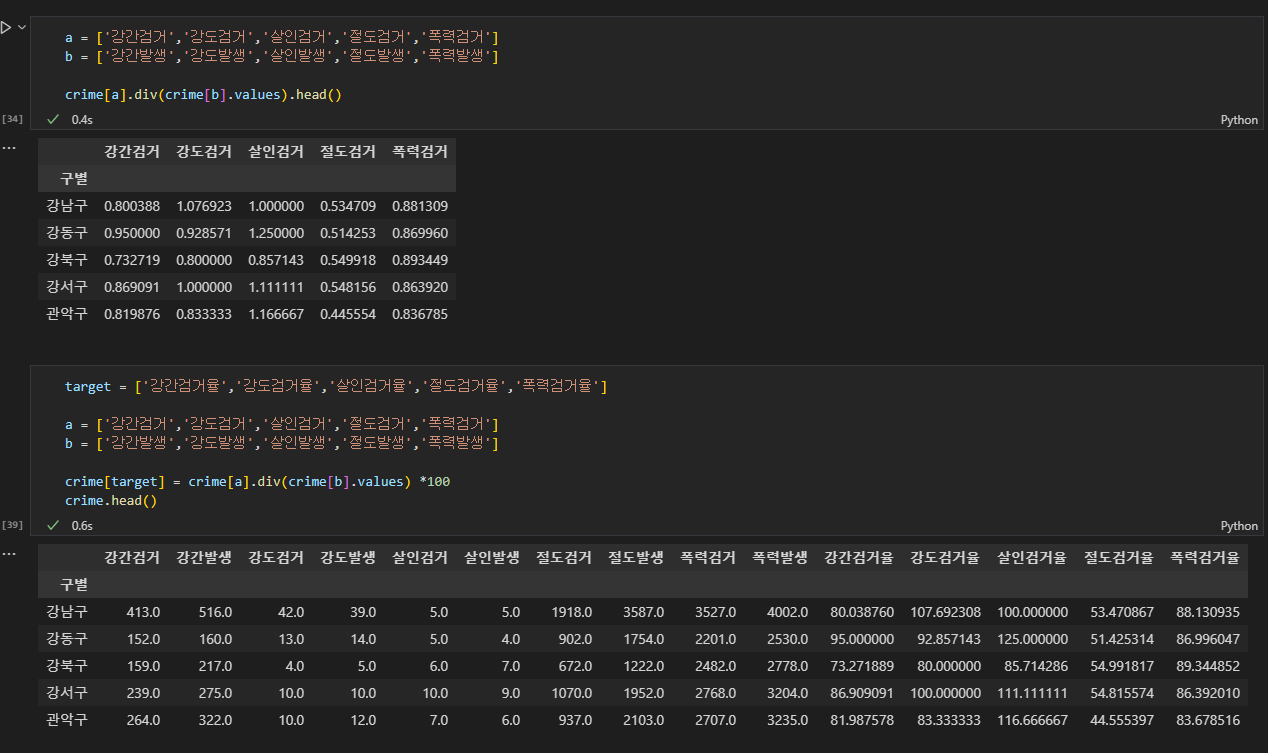
-
여러개의 컬럼을 한번에 여러개의 컬럼으로 나눌경우, df.div() 함수를 사용한다. 이때, 여러개의 컬럼을 [컬럼1,컬럼2,...] 리스트로 변수에 담아서 사용하면 df[변수명] 으로, 바로 여러개의 컬럼으로 하나의 변수로 접근할수있다.
-
이때 나누는 여러개의 컬럼은 .values를 하여 그 값으로 나누어주어야한다.
3. 필요없는 컬럼 및 데이터 값 정리
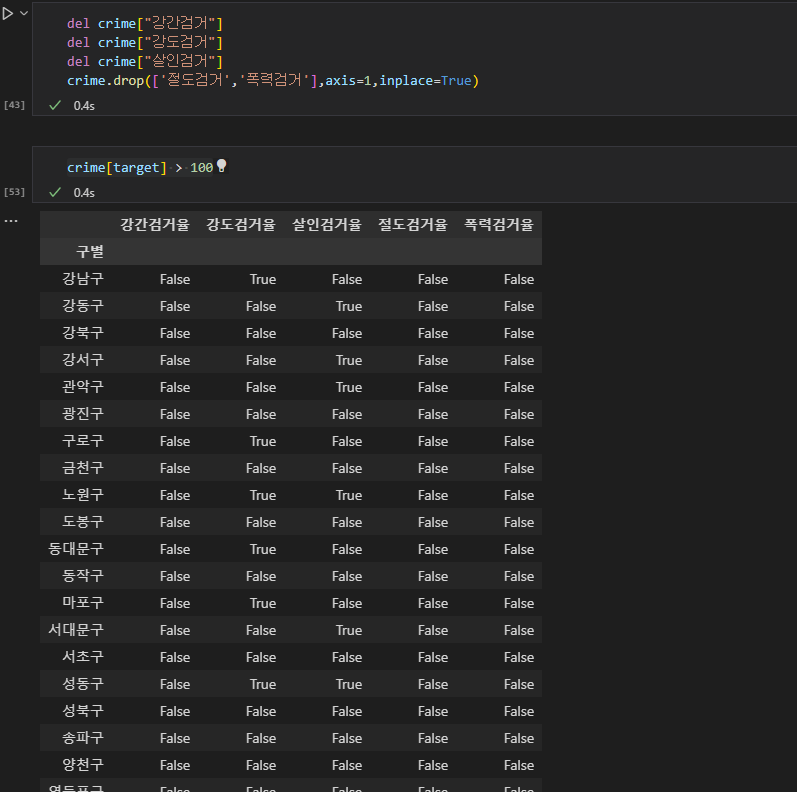
-
각 검거율을 구했으므로, 검거에 대한 데이터는 제거한다. target 변수, 즉 다섯개 죄목별 검거율의 값중에서, 100이 넘는 값들이 있다. 이것은 검거율 퍼센트가 100이 넘는다는건데, 그 말은 즉 모든 사건에서 전부 검거를 했다는 말과 같으므로 100 초과하는 값들은 100으로 변경해준다.
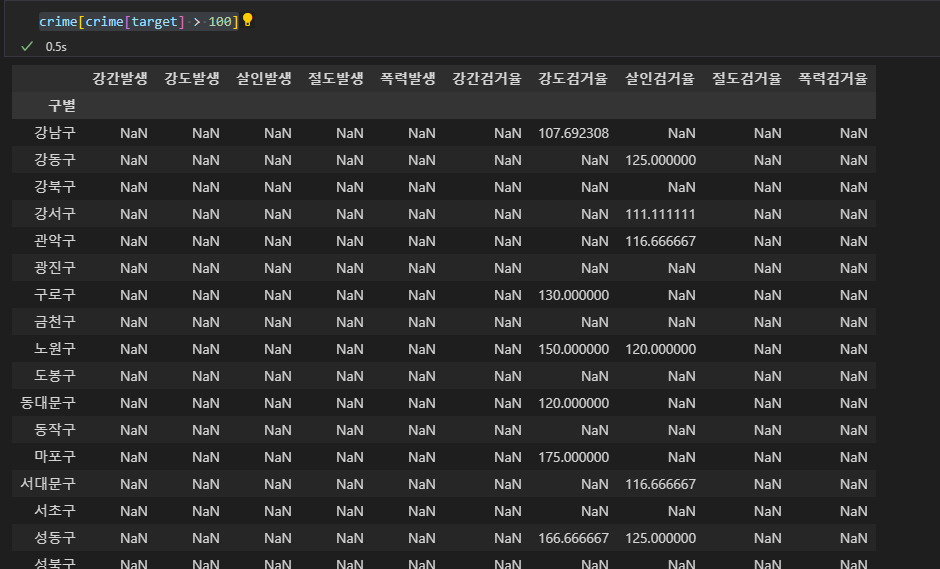
-
crime[target]>100 으로, target 변수에 해당하는 컬럼들에서 100이 넘는데이터를 boolean 값으로 볼 수 있고, crime[crime[target]]으로, 전체 crime 데이터프레임에서 100이 넘는 값을 출력한다. 해당사항이 없으면 nan으로 출력.
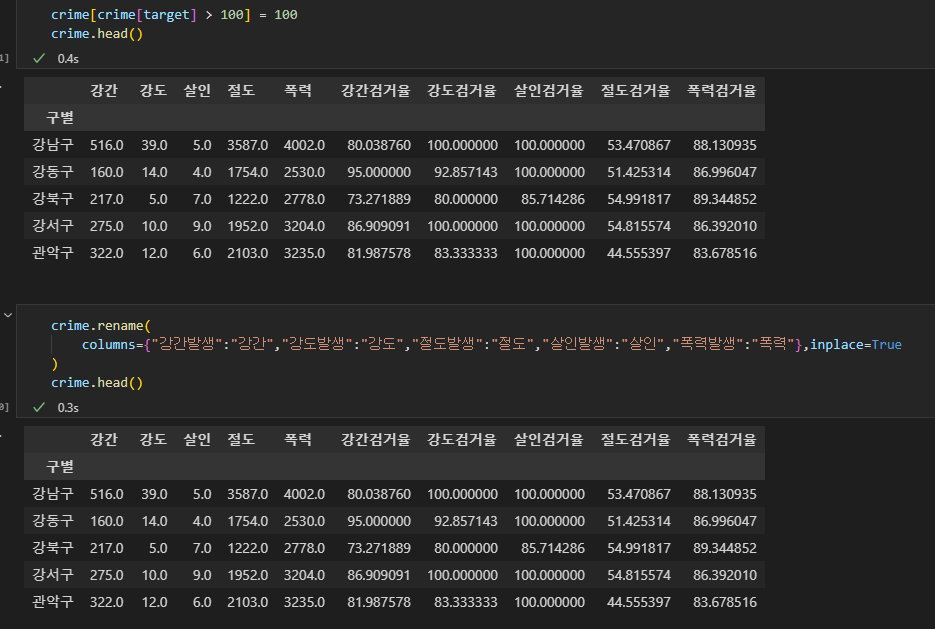
-
전체 발생수 대비 검거한 수로 검거율을 다 구했으므로 모든 죄목에 발생이란 단어를 빼고 컬럼명을 간단하게 줄인다.
