
📌 CV(Computer Vision)
📄 CNN Architecture For Image Classification
이전에 알아본 CNN 모델에 이어 추가적으로 SENet,EfficientNet에 대해 살펴보도록 한다.
✏️ SENet
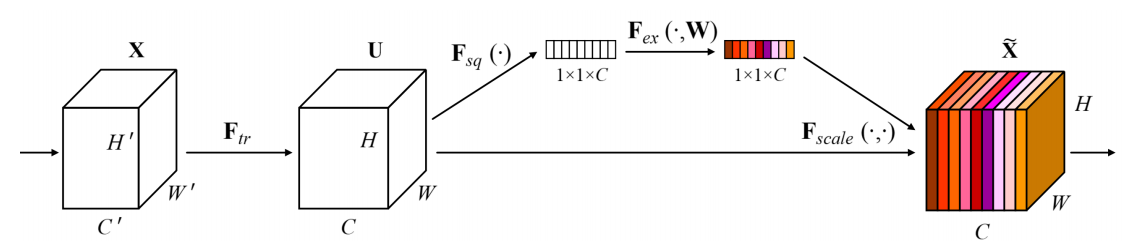
SENet 은 2017년 ILSVRC 에서 우승한 모델로 top-5 error 가 2.251% 를 기록하였다. 사람의 top-5 error 가 5% 인 것을 감안하면 매우 높은 수치임을 알 수 있다. 그렇다면 어떻게 이렇게 높은 수치를 도달할 수 있었을까?
✅ SE Block(Squeeze & Excitation Block)
크기의 feature map 는 convolution 연산 을 통해 크기의 feature map 를 얻는다. 그 다음 squeeze 연산 를 적용하는데, 이것은 global average pooling(GAP) 을 이용하여 크기의 vector를 얻는다. 이때 global average pooling 이란 각 채널의 2차원 feature map을 평균내어 하나의 값을 얻는것을 말하며, 다음과 같이 정의할 수 있다.
즉, 크기의 feature map 은 크기의 feature map 으로 squeeze 된다. 이후 excitation 작업을 통해 어느 곳에 attention 할지를 알아내기 위해 상대적 중요도를 찾으며 다음과 같이 정의할 수 있다.
위의 식을 보면 두번의 FC layer가 적용되는 것을 확인할 수 있는데, 그 과정을 천천히 살펴보면 squeez 연산의 결과 값 를 입력으로 받아 선형변환 후 activation function 으로 ReLu 함수 를 적용한다. 이후 그 결과값을 한 번 더 FC layer 에 적용하여 activation function 으로 sigmoid 함수 를 적용한다. 즉, 각 채널의 상대적 중요도를 0~1의 값으로 파악할수 있도록 연산이 이루어진다. 이때, 주목해야할 것은 FC layer 들이 bottle-neck 구조가 되도록 하는것인데, 일반화 및 hyperparameter 갯수를 많이 늘리지 않기 위함이다. 풀어서 설명하면, 입력층의 뉴런갯수 보단 은닉층의 뉴런 갯수를 더 작게 해주고 출력층의 뉴런의 갯수는 입력층과 동일하게 만든다. 이때 은닉층의 뉴런의 갯수는 reduction ratio ,r 에 의해 결정된다. 따라서 만약 채널 갯수가 에서 시작했다면, 은닉층의 채널은 로 감소하였다가 다시 로 증가한다.
마지막으로 상대적 중요도 정보가 포함된 를 기존의 feature map 와 각각 곱해줘서 재보정(Recallibration) 하여 feature map 를 얻는다. 이때 크기를 맞춰주기 위해서 scale 과정을 거친다.
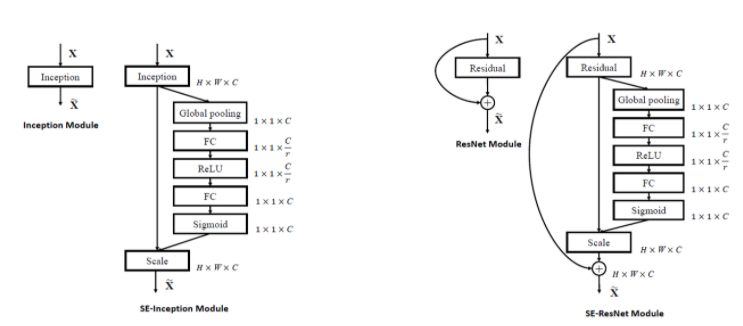
✅ 기존 CNN 모델과의 결합
✏️ EfficientNet
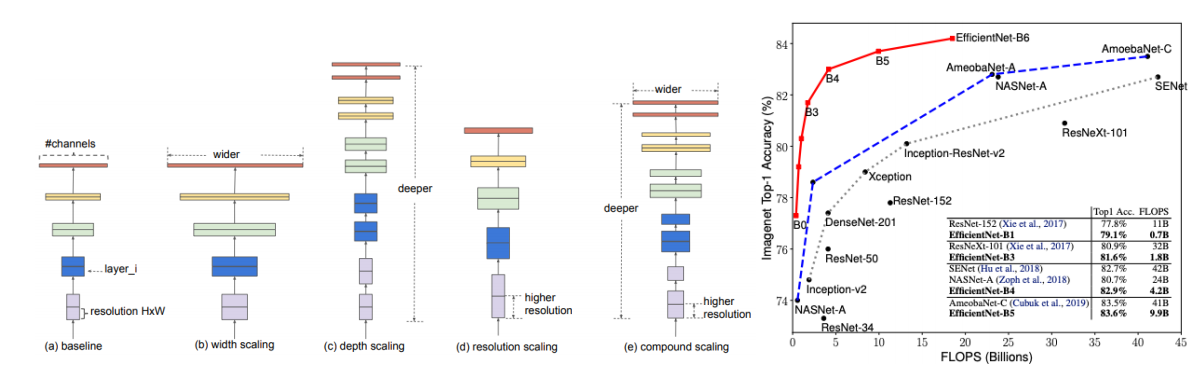
일반적으로 CNN의 성능향상 위해 좋은 모델을 찾는 경우도 있지만 기존 모델의 scaling 을 통해 성능향상을 도모 하기도 한다. EfficientNet 은 scaling에 집중하여 효과적인 성능 향상을 이끌었는데, 그 방법은 무엇인지에 대해 살펴보도록 한다.
✅ 문제인식
일반적으로 모델 scaling 방법에는 채널의 개수를 늘리는 width scaling / layer의 개수를 늘리는 depth scaling / 입력 이미지의 해상도를 높이는 resolution scaling 이 있다. 기존에는 위의 3가지 scaling 중 한가지 scaling을 이용해서 성능향상을 도모했다. 또한 3가지 방법 중 어떤 방법을 사용할지에 대한 가이드라인과 실제로 무작정 키운다고 해서 성능이 향상되는 것이 아닌 문제가 있었다. 그래서 본 논문에서는 나머지를 고정시키고 하나의 scaling factor 만 변화시키면서 변화를 측정하였다.
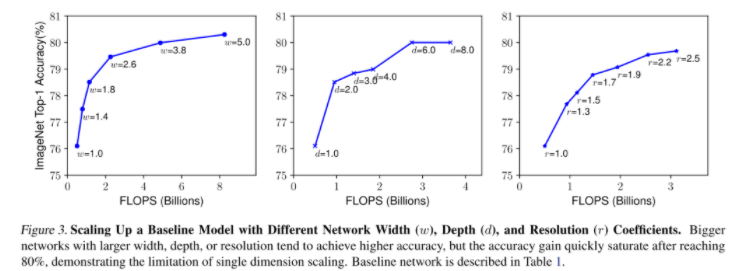
위의 결과를 보면 width scaling, depth scaling, resolution scaling 은 어느 시점 이후 saturation 되는 것을 확인할 수 있고, 분명 성능향상에 영향이 있지만 무한정 키우는 것이 좋은 답은 아니라는 것을 알 수 있다. 이번엔 depth 와 resolution 을 고정 시켜두고 width를 변화하면서 성능을 측정하였는데, 다음과 같았다.
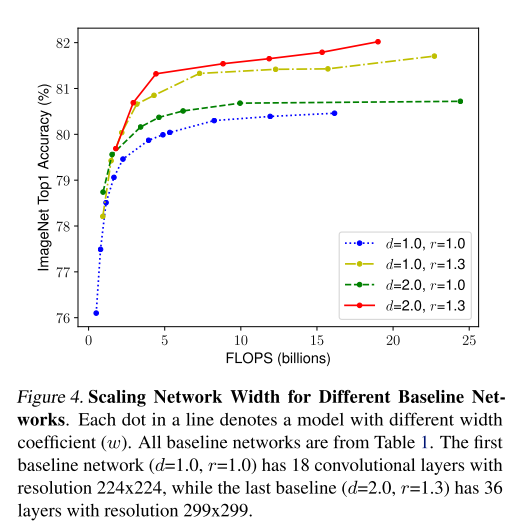
위의 결과가 주는 의미는 여러가지가 있지만, 가장 중요한 결과는 1가지 혹은 2가지 scaling factor만 고려하는 것이 아닌 3가지 scaling factor를 동시에 조절(Compound Scaling)하는 것이 가장 성능이 좋은 것을 확인할 수 있다. 그렇다면 어떻게 factor들을 결정해야할까?
✅ 해결방법
3가지 scaling을 동시에 조절하는 것이 가장 성능이 좋은 것을 실험적으로 확인하였고, 최적의 coefficient 를 찾아야만 했다. 우선 본 논문에서는 모델을 고정하고 3가지 scaling을 조절하는 방법을 제안하였는데, 이때, 고정하는 모델을 좋은 모델로 선정하는 것이 중요하다. 아무리 scaling factor를 조절해도 초기 모델자체의 성능이 낮다면 의미가 없기 때문이다. 본 논문에서는 최적의 baselien network 를 EfficientNet-B0 라고 명명하였다. 이후 scaling factor를 결정하는데, 기존에는 principled method 가 없었기 때문에 본 논문에서는 다음과 같이 제안한다.

위의 노란색 조건을 만족하는 를 찾기 위해 우선 를 1로 고정한 후 간단한 grid search 를 통해 좋은 성능을 보이는 값을 결정한다. 이후 결정된 를 기준으로 값을 변화시키면서 성능을 비교하게 된다.
✅ 결과
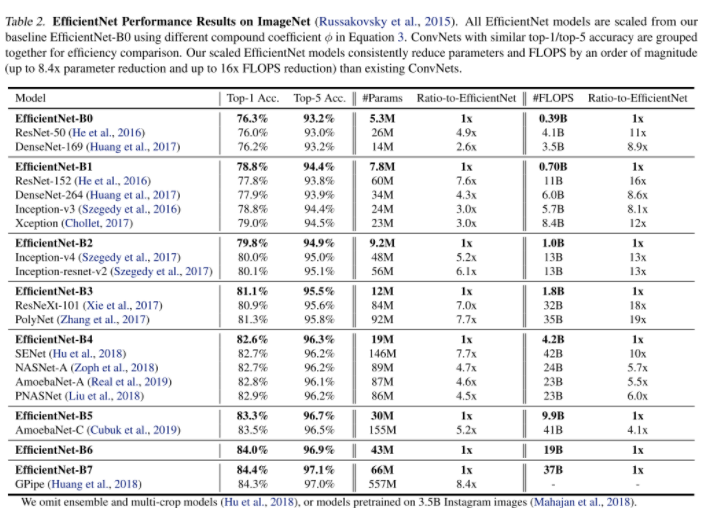
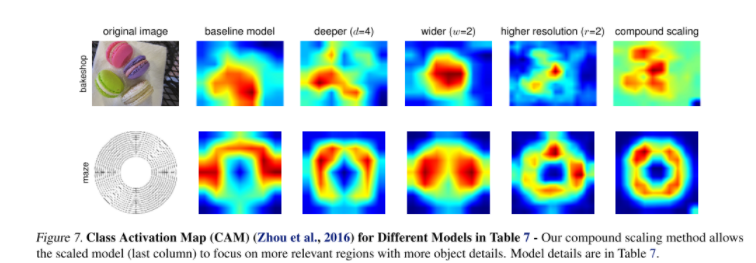
결과를 보면 다른 모델에 비해 좋은 성능뿐만 아니라 파라미터수,FLOPS 에 있어 더 효율적임을 알 수 있다. 또한 더 정교한 Class Activation Map(CAM) 을 뽑아 내는것을 확인할 수 있다.
📄 CNN Architecture For Semantic Segmentation
FCN 에 이어 추가적으로 U-Net,DeepLab 에 대해 살펴보도록 한다.
✏️ U-Net
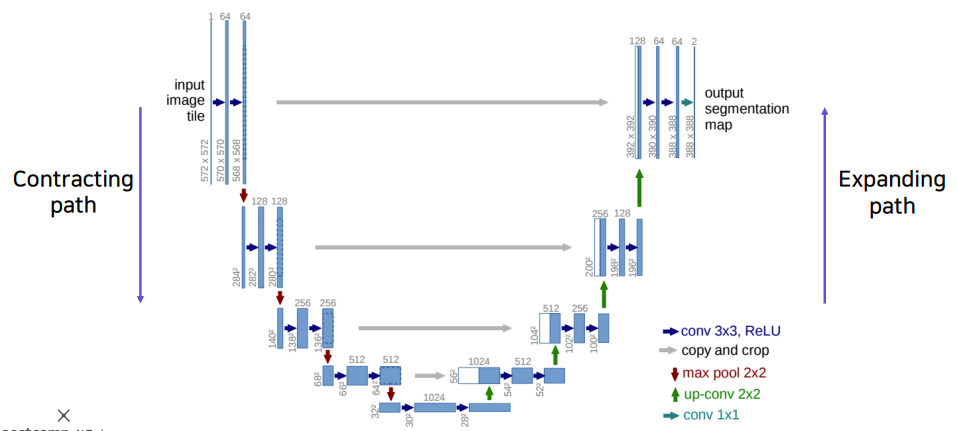
U-Net 은 Biomedical 분야에서 semantic segmentation 을 목적으로 제안된 end-to-end 방식의 FCN 기반 모델이다. 위의 그림과 같이 네트워크 구성의 형태("U")로 인해 U-Net이라는 이름이 붙여졌다. U-Net이 가지는 주요 특징은 다음과 같다.
✅ Contracting Path
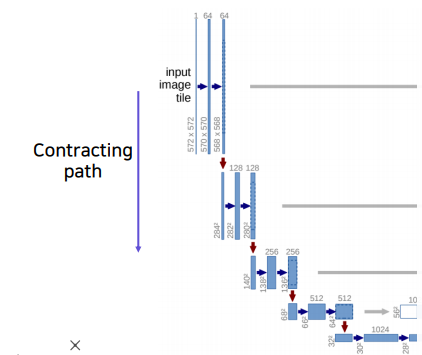
입력 이미지의 전반적인 context 정보를 얻기 위해 반복적인 conv 연산과 pooling 연산을 통해 resolution은 낮추고 channel은 늘려서 receptive field 의 크기를 키우는 과정이다. 구체적으로 살펴보면,
-
ReLU를 활성화 함수로 하여stride=1,padding=0,3x3conv 연산을 2차례 반복한다. -
이후
stride=2,padding=0,2x2max-pooling 연산을 한다. -
Down-sampling 마다 feature map의 크기는 배, channel의 수는 2배씩 늘어난다.
✅ Expanding Path
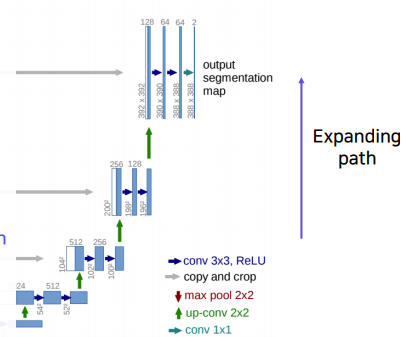
Contracting path로 인해 낮아진 resolution을 up-sampling 을 통해 높이고 channel 수는 줄임과 동시에 하위 층의 localized information(경계선,공간적으로 중요한 정보들) 를 갖는 feature map을 concatenation 하여 더 세밀한 localization을 구성하는 과정이다. 구체적으로 살펴보면,
-
stide=2, padding=0,2x2transposed conv(deconvolution) 연산을 통해 up-sampling 한다. 주목할것은stride=2를 통해 checkerboard artifact(추후 정리) 문제가 발생하지 않는다. 또한 up-sampling 된 feature map은 contracting path의 테두리가 cropped 된 feature map과 concatenation 한다.(위의 그림에서 흰색 박스가 concatenation을 의미한다.) crop을 하는 이유는 conv -
이후
ReLU를 활성화 함수로 하여stride=1,padding=0,3x3conv 연산을 2차례 반복한다. -
Up-sampling 마다 channel 의 수는 배 , feature map 의 크기는 2배가 된다.
-
마지막 layer에서는
1x1conv 연산을 통해 2개의 채널 최종 출력을 한다. 다시 한번 살펴보면 input channel은 1개인 반면 output channel은 2개인데, 그 이유는 한 픽셀당 가질 수 있는 경우의 수가 두 가지이기 때문이다. 또한 입력 이미지 보다 작은 출력 이미지을 뱉어낸다.
✅ Note
U-Net은 down-sampling 과 up-sampling 이 빈번하게 발생한다. 또한 하위층의 down-sampling 된 feature map과 상위층의 up-sampling 된 feature map을 concatenation 해야한다.그렇다면 만약 다음과 같이 홀수 크기 이미지이 주어진다면 어떻게 할까?
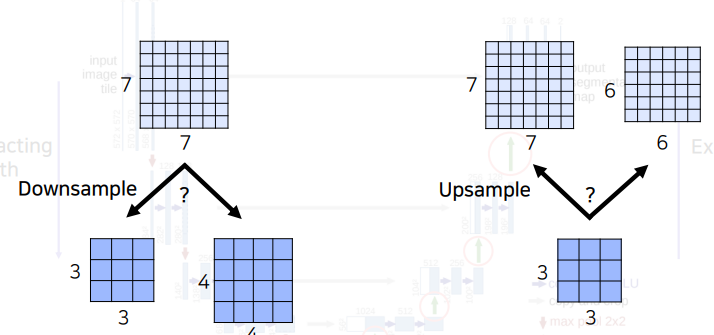
7x7 이미지를 down-sampling 한다면 3x3 ,4x4 크기의 두가지 선택 사항이 생길것이다. 만약 3x3의 크기로 down-sampling 한다고 가정한다면 up-sampling 시에는 6x6 이미지가 생기기 때문에 문제가 생기게 된다. 따라서 입력 이미지와 feature map의 크기는 짝수로 설정될 수 있도록 해야한다.
✅ Overlap-tile Strategy
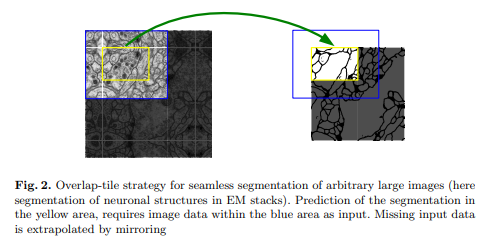
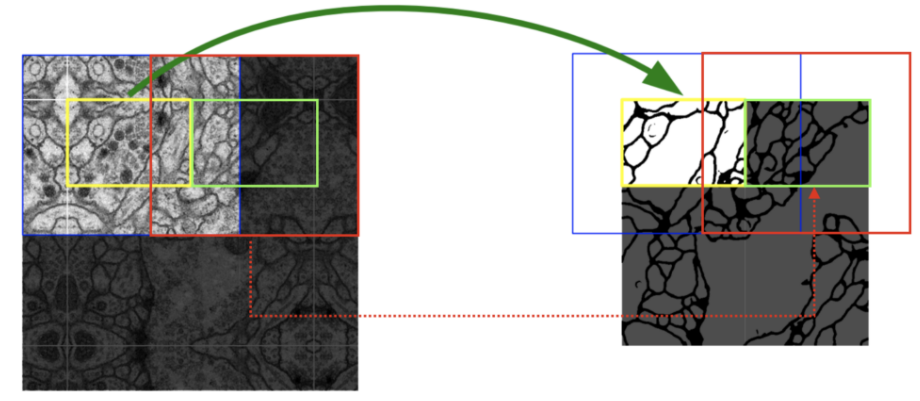
Overlap-tile Strategy 는 , U-Net 에서 다루는 전자 현미경 데이터의 특성상 이미지 사이즈의 크기가 상당히 크기 때문에 Patch 단위로 잘라서 Input 으로 넣고 있습니다. 이것이 가능한 이유는FCN을 기반으로 하여 입력이미지의 크기에 제약이 없기 때문이다.
위의 Fig.2 를 보면 노란색은 실제 segmentation될 영역, 파란색은 patch(tile) 이다. 이때 위와 같이 border 부분에 정보가 없는 부분을 패딩으로 채우는 것이 아닌 mirroring 방법으로 pixel의 값을 채워준다. 아래의 그림을 보면 mirroring을 통해 값을 채워주는것을 확인할 수 있다.
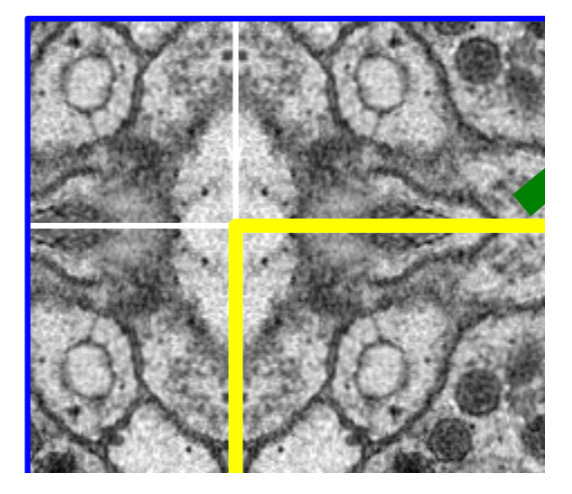
다음 tile에 대한 segmentation 을 얻기 위해서 위의 과정을 반복하면 다음 그림과 같이 이전 입력의 일부분이 포함되게 된다. 그래서 Overlap-tile Strategey 라 칭한다.
✏️ DeepLab

여기서는 여러가지 버전 중 가장 최신 버전인 DeepLab v3+을 살펴볼텐데, 그 전에 핵심 아이디어인 CRFs, Atrous Convolution(Dilated Convolution) ,Atrous Separable Convolution을 살펴보도록 한다.
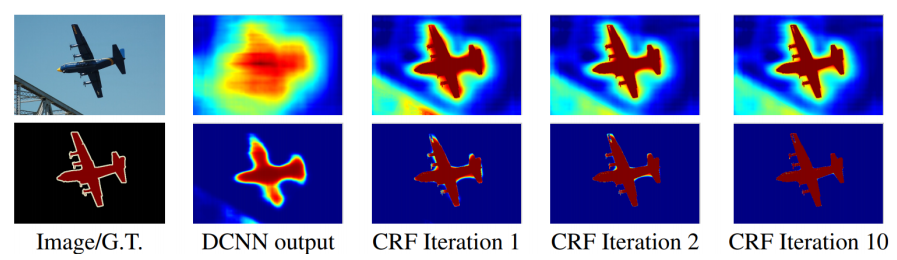
✅ Conditional Random Fields(CRFs)
✅ Atrous Convolution(Dilated Convolution)
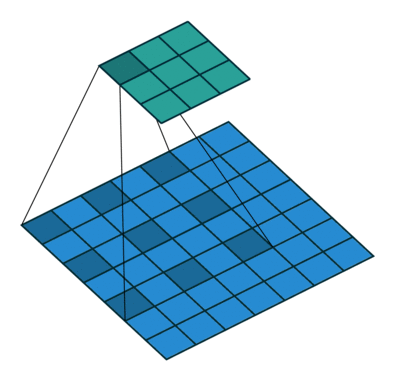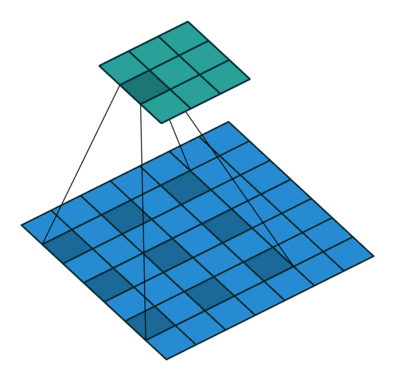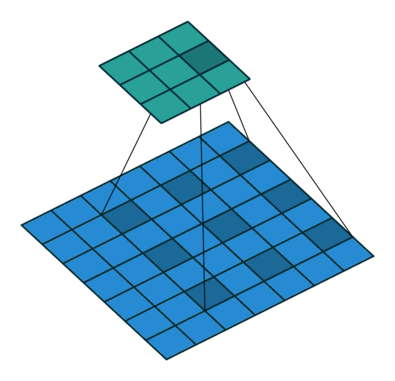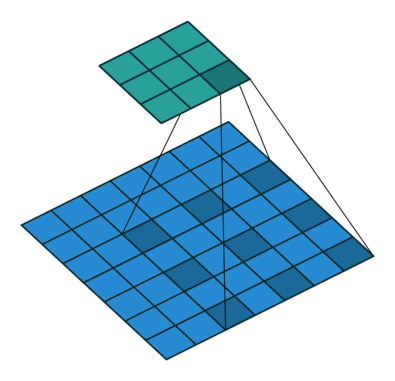
Dilated Convolution 은 convolutional layer에 "커널 사이의 간격" 을 의미하는 dilation rate를 도입한다. 가령, dilation rate=2 인 3x3 커널은 9개의 파라미터를 사용하면서 5x5 receptive field 를 가지게 된다. 즉 늘려진 커널 내부에 zero padding을 추가하여 receptive field를 늘린다. 주의할것은 파라미터의 수는 늘어나지 않고 3x3 커널 기준으로 9개의 파라미터로 동일하다는 것이다. 그렇다면 Dilated Convolution이 주는 이점은 무엇일까?
일반적인 CNN 구조에서 큰 receptive field를 취하기 위해서 layer를 깊게 쌓거나 / 커널의 크기를 키우거나/ pooling 연산 을 적용한다. 하지만 이것은 연산량이 늘어나고, 정보의 손실을 발생시킬수 있다. 그러나 Dilated Convolution을 사용하면 위의 예시와 같이 동일한 파라미터의 수를 유지함과 동시에 receptive field를 늘릴 수 있게 된다. 또한, pooling을 사용하지 않고도 receptive field를 크게 가져갈수 있기 때문에 spatial dimension의 손실이 적고, 대부분의 weight가 0이기 때문에 연산의 효율도 좋다. 이와 같이 spatial dimension을 잘 유지하는 특성 때문에 특히 segmantation task에 많이 사용된다.
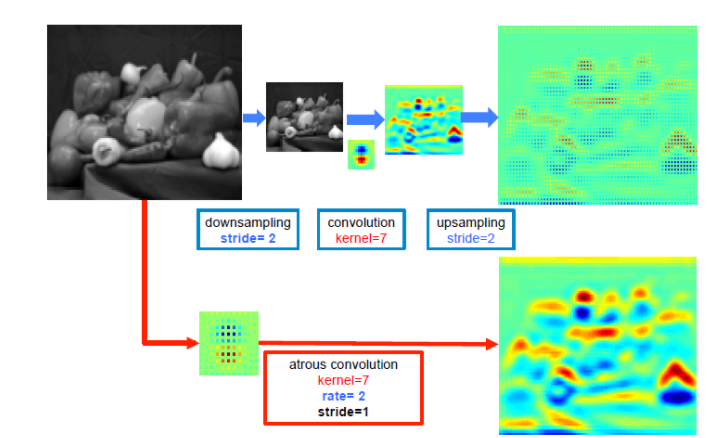
위의 그림을 보면 down-sampling(pooling-conv) 연산 후 up-sampling 하는것과 비교했을때, spatial 정보가 손실된 것을 up-sampling 할 경우 resolution이 떨어지지만, Dilated Convolution 의 경우 spatial 정보를 잘 가지고 있는것을 확인할 수 있다.
✅ Atrous Separable Convolution(Depthwise Separable Convolution)
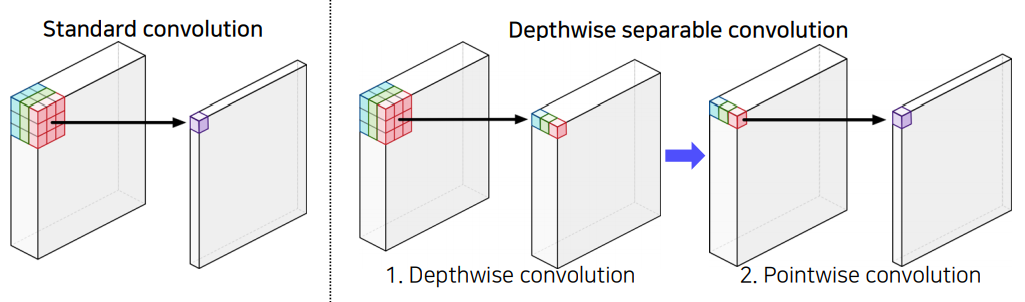
CNN 에서 가장 많은 연산량을 차지하는 부분은 convolution 연산이다. Depthwise Separable Convolution 은 이 연산량을 줄이는 것을 목표로 하는데, 우선 기본 convolution 연산량이 얼마가 되는지 간략하게 살펴보도록 한다.
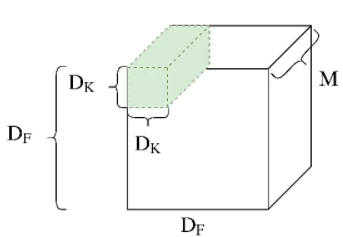
입력 에 대해 커널의 convolution 연산량은 이다. 이때 output channel 이 개 라면 이다.(편의상 출력 feature map 의 크기는 는 이라고 가정한다.)
Depthwise Separable Convolution 는 다음과 같이 두가지의 과정을 거친다.
- Depthwise Convolution
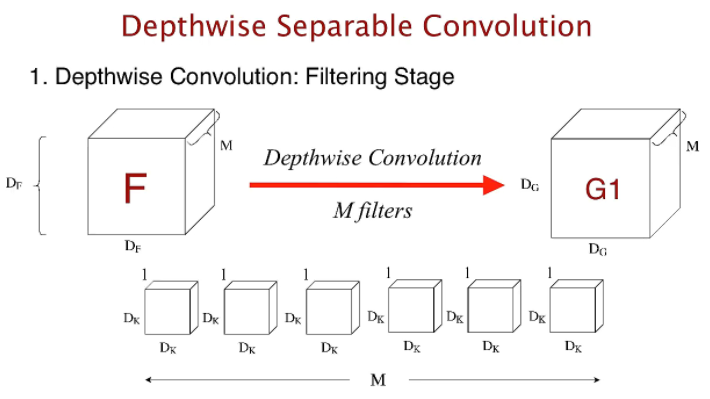
기존의 convolution 연산은 한개의 커널이 M채널 전체에 convolution 연산을 하는 반면 depthwise convolution 은 한 개의 커널이 한 개의 채널에만 연산을 한다. 이때, M개의 채널이 있으므로 총 연산량은 이다.(편의상 출력 feature map 의 크기는 는 이라고 가정한다.)
- Pointwise Convolution
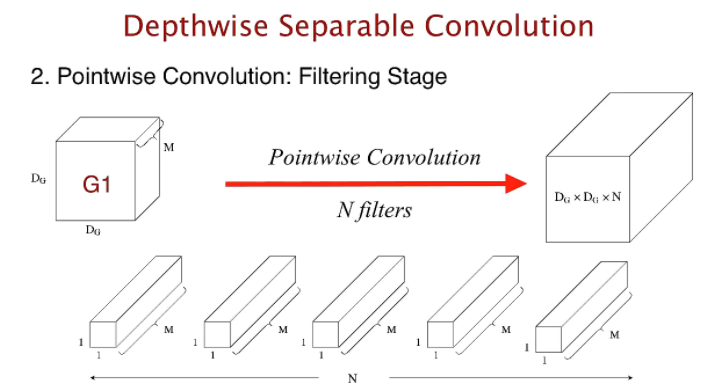
Depthwise convolution 의 출력에1x1convolution 연산을 적용하는것이 pointwise convolution 의 핵심인데, output channel 이 개 라면 개 의1x1convolution 연산 출력을 stack하여 만든다. 즉, 총 연산량은 이다.(편의상 출력 feature map 의 크기는 는 이라고 가정한다.)
따라서 Depthwise Separable Convolution 의 총 연산량은 이며 기존의 연산량에 비해 줄어든 것을 확인할 수 있다.
✅ DeepLab v3+
DeepLab v3+ 는 segmentation 모델 중에서 좋은 성능을 보이는 모델 중 하나로 DeepLab 시리즈 중 2019년도 기준으로 가장 최신 모델이다. 이름에서도 알 수 있듯이 DeepLab v3를 개선하였으며, 여기서 살펴봐야할 핵심 아이디어는 Encoder-Decoder ,Atrous Convolution ,ASPP(Astrous Spatial Pyramid Pooling),Atrous Separable Convolution(Depthwise Separable Convolution) 이다.
-
Encoder-Decoder 구조
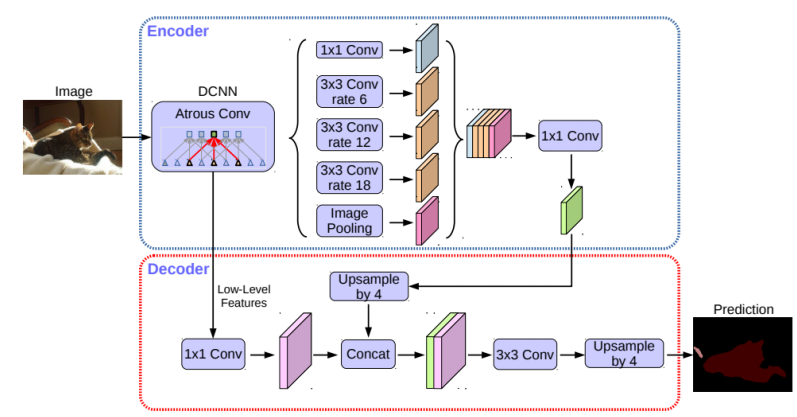
DeepLab v3에서는 단순히 bilinear up-sampling 하였으나,DeepLab v3+에서는 U-Net 과 같이Encoder-Decoder구조를 이용하여ASPP의 출력 결과를1x1convolution 을 통해 channel을 줄여서 bilinear up-sampling 후 low-level features 와 concatenation 하여 더 풍부한 semantic 정보를 담을수 있도록 한다.DeepLab v3+에서는 두 가지의 encoderDeepLab v3와변형된 Xception를 제시하고 있다. -
Atrous Convolution
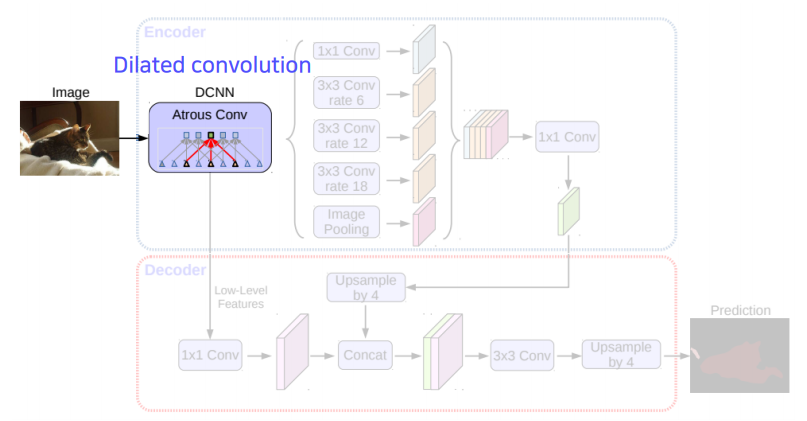
위에서 언급했듯이, 더 큰 receptive field를 수용 하기 위해 Dilated Convolution 을 활용한다. 이것은
DeepLab시리즈에서 동일하게 적용된다. -
ASPP(Astrous Spatial Pyramid Pooling)
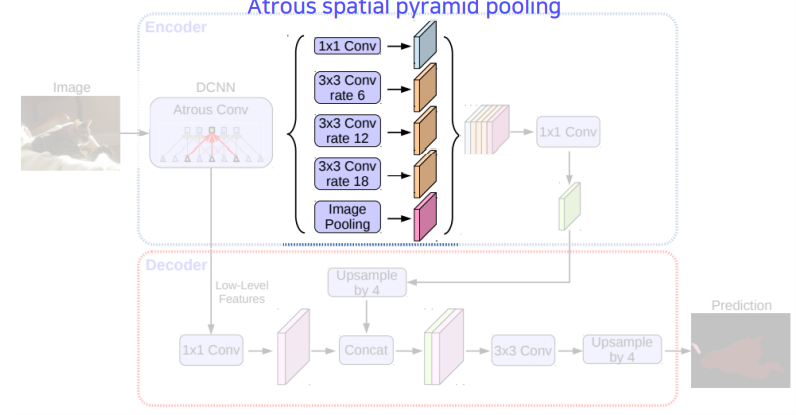
Atrous Convolution을 사용할때, 고정된 dilation rate 를 사용하게 되면 필터의 크기가 고정이 되고 다양한 feature 중에서 한정된 feature 밖에 찾지 못하는 문제를 가지게 된다. 따라서 다양한 크기의 dilation rate를 사용하여 다양한 receptive field에 대응되며 이것을ASPP(Astrous Spatial Pyramid Pooling)라 부른다. 이 방법은DeepLab v2에서 부터 적용된다. -
Atrous Separable Convolution(Depthwise Separable Convolution)
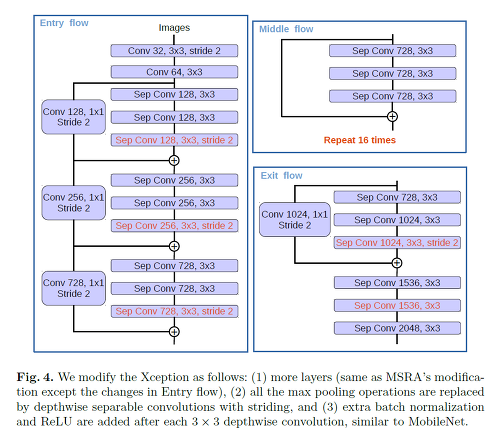
Depthwise separable convolution 을 활용한
Xception을 변형시킨 encoder를 제시했으며,ASPP와Decoder또한 depthwise separable convolution 을 적극활용 함으로써 파라미터 사용량 대비 성능 효율을 극대화 시키려 하였다.
📚 Reference
SENet
EfficientNet
U-Net1
U-Net2
Dilated Convolution
Depthwise Separable Convolution
DeepLab v3+
