
📌 DL Basics
📄 CNN(Convolutional Neural Network)
CNN 기본 개념 에 이어서 추가적인 개념들을 알아보도록 한다.
✏️ Receptive Field vs Feature Map
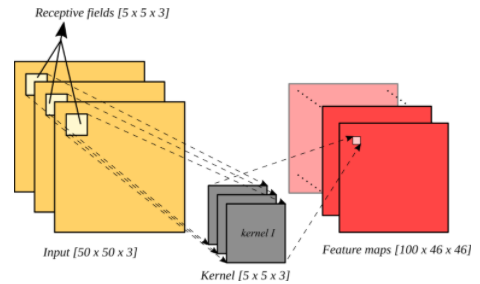
| Receptive Field | Feature Map |
|---|---|
| 커널이 적용되는 영역으로 feature map 의 한 노드 | 커널의 합성곱연산을 적용하여 얻어낸 결과 |
Feature Map 계산은 아래에서 살펴보도록 하고 여기선 Receptive Field 에 대해 알아보도록 한다. Receptive Field 의 크기는 "얼마나 많은 정보를 수용하냐" 와 관련이 있다. 예시로 살펴보면 5x5 입력 이미지에 stride=1(stride는 아래에서 설명한다.)로 3x3 kernel 연산과 pooling 을 적용한 feature map의 한 노드는 4x4 receptive field 를 가진다.
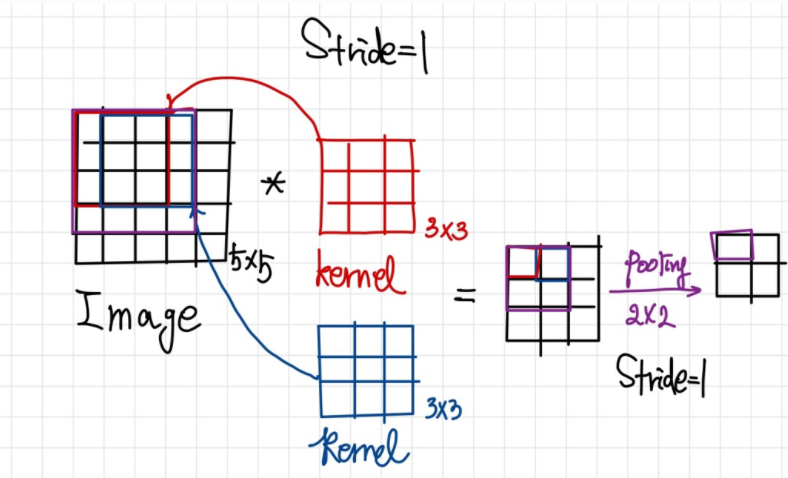
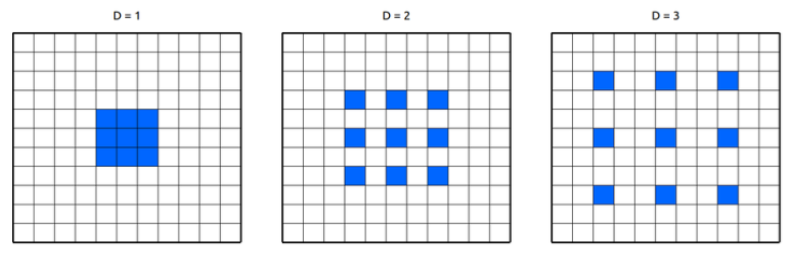
다른 예로 만약 dilated convolution( 만큼 팽창된 kernel의 convolution 연산) 을 생각한다면 다음과 같다.
<참고>
Receptive Field 의 크기를 쉽게 계산하고 싶다면 여기를 참고하도록 한다.
✏️ RGB Image Convolution
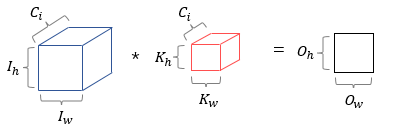
앞서 살펴본 합성곱에서는 흑백 이미지를 예시로 채널이 1 인 이미지를 살펴보았다. 그렇다면 RGB 이미지, 즉 채널이 3 인 이미지의 합성곱연산은 어떻게 진행될까? 나아가 다수의 채널을 가졌다면 어떻게 진행될까? 결론부터 말하면, 각 채널마다 커널의 합성곱연산 을 진행한다. 따라서, 입력데이터의 채널수 = 커널의 채널 수 이다.

위의 그림은 3개의 채널을 가진 입력데이터에 3개의 채널을 가진 커널의 합성곱 연산을 보여주는데, 커널의 각 채널 크기는 같아야한다. 주의할것은 위의 연산에서 적용되는 커널은 3개의 커널이 아닌 3개의 채널을 가진 1개의 커널이라는 것이다.
그렇다면, 다수의 채널에 커널의 합성곱 연산이 어떻게 적용되는지 이해했으니, 일반화하여 살펴 보도록 한다.
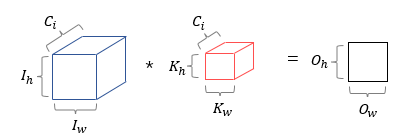
입력데이터 (,,) 가 들어온다면 같은 채널 사이즈 를 가진 임의의 커널 (,,)을 적용하면 (,) 인 하나의 feature map을 얻을 수 있다. 만약 하나의 feature map 이 아닌 다수의 feature map을 얻고 싶다면 다음과 같이 개의 커널을 이용하여 개의 feature map을 생성할 수 있다.

다음의 예시를 통해 정확한 이해를 했는지 확인해보록 한다.
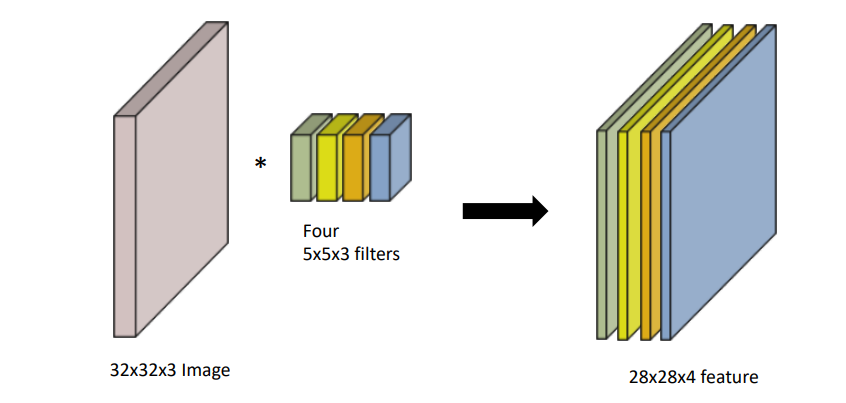
입력 데이터 (32,32,3) 에 (5,5,3) 인 커널 4개를 적용한다면 (28,28,1) 인 feature map 4개가 생성되므로 (28,28,4) 인 feature map을 얻을 수 있다.
✏️ Stride & Padding
Stride 는 커널의 합성곱연산을 적용할 때 움직이는 간격을 말한다.
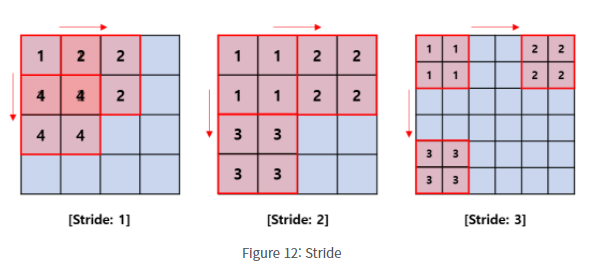
Padding 은 반복적으로 합성곱 연산을 적용했을때, feature map이 너무 작아지거나 이미지의 모서리 부분의 정보손실을 막기위해 입력데이터 주변을 0으로 채워넣는 방법 을 말한다.
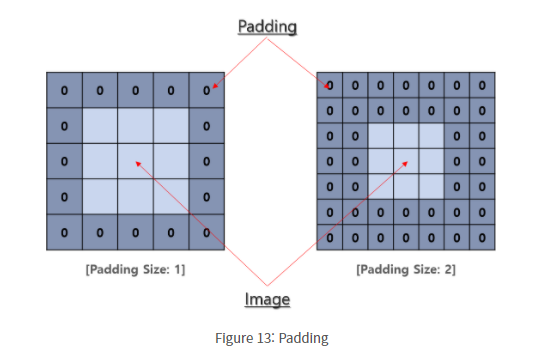
다음은 3x3 커널, stride=1,padding=1 인 합성곱연산의 예시이다.
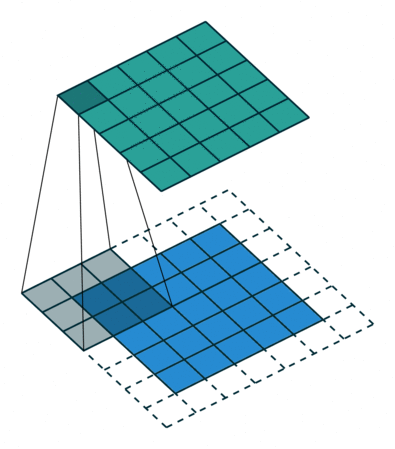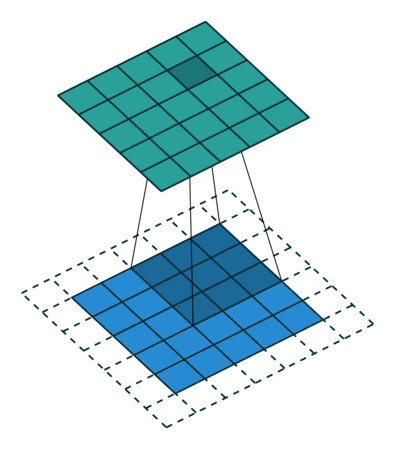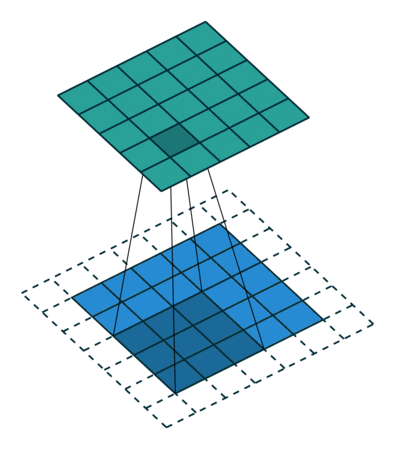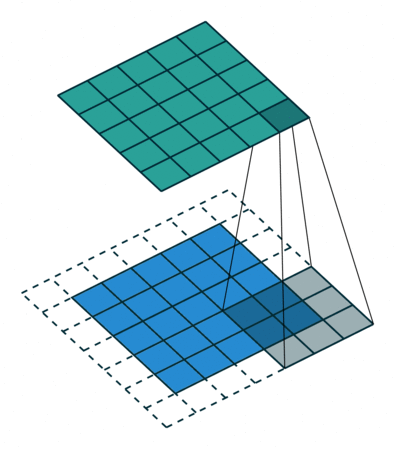
✏️ Pooling
일반적으로 convolutional layer 다음에는 pooling layer를 추가한다. pooling layer는 down sampling 을 통해 feature map 의 크기를 줄여주는 연산 으로 합성곱 연산과 같이 kernel 과 stride 개념을 가지고 있다. 보통 max pooling 과 average pooling 이 사용되는데, max pooling 은 커널의 receptive field 최댓값 / average pooing 은 커널의 receptive field 평균값을 추출하여 down sampling 한다. 다음은 2x2 커널, stride=2 인 max pooling의 예시이다.
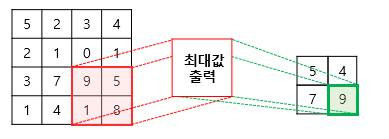
pooling 연산은 합성곱연산과 비슷하게 kernel 과 stride의 개념을 가진다는점에서 유사하지만, 차이점은 학습해야 할 가중치가 없으며 연산 후에는 feature map의 크기가 줄어들 뿐 채널의 수는 변하지 않는다는 점이다.
✏️ Feature Map 의 크기를 쉽게 계산할수 있을까?
Input size, kernel size, stride, padding 값을 알면 feature map 의 크기를 쉽게 계산할 수 있다. 계산하기 앞서 다음과 같이 notation을 정의한다.
- : 입력 데이터의 높이
- : 입력 데이터의 너비
- : 커널의 높이
- : 커널의 너비
- : stride
- : padding
- : feature map 의 높이
- : feature map 의 크기
이에 따라 feature map 의 크기는 다음과 같이 계산할 수 있다.
이제는 앞서 다뤘던 예시의 결과를 정확하게 이해할 수 있을것이다.
✏️ 파라미터의 수를 쉽게 계산할수 있을까?

앞서 다수의 채널 합성곱 연산을 이해했다면, 파라미터의 총 개수를 쉽게 구할 수 있다. 우선 파라미터는 커널의 원소들이므로 하나의 커널의 하나의 채널은 개의 파라미터를 가지고 있다. 그런데 합성곱 연산을 하려면 커널의 채널 수 = 입력데이터의 채널 수 이므로 하나의 커널은 개의 파라미터 를 가진다. 그런데 이러한 커널이 개 존재한다면 총 파라미터의 수는 이다.
정확하게 이해했는지 확인하기 위해 다음의 예시를 살펴 보도록 한다.

위의 그림은 의 입력데이터에 커널을 적용하여 64개의 feature map을 생성하고 있다. 따라서 총 파라미터의 수는 이다. 입력데이터의 크기 때문에 혼동될수 있겠지만, 파라미터와는 연관이 없다는 것을 기억하면 도움이 될것이다.
✏️ 그래서 CNN은 어떻게 구성되는데?
CNN은 크게 합성곱연산을 통해 feature를 추출하는 covolution layer, down sampling을 통해 feature를 추출하는 pooling layer , decision making을 위한 fully connected layer로 이루어져 있다.

📄 Modern CNN(Convolutional Neural Network)
ILSVRC(ImageNet Large-Scale Visual Recognition Challenge) 에서 수상을 했던 5개의 대표적인 CNN 모델 들의 구조와 주요 아이디어에 대해 살펴보도록 한다.
✏️ AlexNet

AlexNet 은 2012년 ILSVRC 에서 최초로 DL을 이용하여 수상한 모델이다. 전체적인 모델 구조를 살펴보면 입력데이터 (위의 이미지에선 으로 잘못 표현되었다)에 대해 11x11,5x5,3x3 커널을 사용하였으며 5개의 convolutional layer 와 3개의 dense layer 로 이루어져있다. 다음은 AlexNet 이 가지는 주요 특징들이다.
-
ReLU(Rectified Linear Unit) activation function
piecewise - linear 이지만 , 전체적으로 non-linear인ReLU함수를 통해 linear model의 좋은 특성은 유지한다. 또한 입력값을 그대로 전달하여 gradient descent 의 최적화를 쉽게 만들고sigmoid / tanh가 가지는 gradient vanishing 문제를 해결 했다.

-
GPU implementation (2 GPUs)
당시에는 이미지 사이즈에 비해 GPU VRAM이 부족했기 때문에 2개의 GPU를 이용하여 학습하여 합치는 방법을 사용하였다. GPU-1 에서는 주로 컬러와 상관없는 정보를 추출하기 위한 kernel이 학습되고, GPU-2에서는 주로 컬러와 관련된 정보를 추출하기 위한 kernel 학습된다. -
Local response normalization
같은 위치의 픽셀에 대해 다수의 feature map 간의 정규화를 적용한다. -
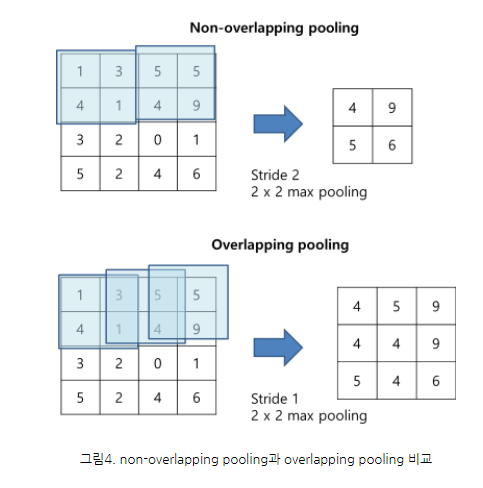
Overlapping pooling
일반적으로 각각 중복되지 않는 영역에서 pooling 을 하지만, AlexNet에선 Overlapping pooling을 이용했다.
-
Data augmentation
Over-fitting을 막기 위해 다음과 같이 data augmentation 한다.- 256x256 이미지에서 227x227 이미지를 random crop
- RGB 채널 값 변화
-
Dropout
over-fitting을 막기위해 랜덤하게 일부 뉴런을 생략하여 학습한다.
✏️ VGGNet
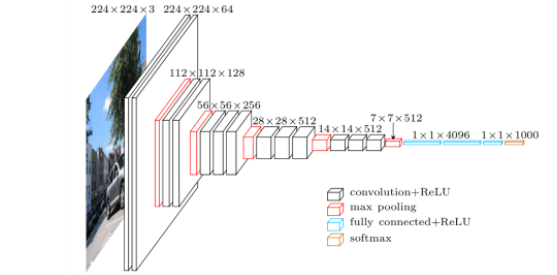
VGGNet 은 2014년 ILSVRC에서 GoogLeNet 과 함께 주목을 받았고 간소한 차이로 2위를 차지한 모델이다. VGGNet의 목적은 network의 depth가 어떤 영향을 주는지 연구 하기위함이었다. 그래서 convolution filter 를 하나의 크기로 고정하여 layer를 늘려나가는 방식으로 테스트를 진행한다. 다음은 VGGNet이 가지는 주요 특징들이다.
-
Increasing depth with only 3x3 convolution filters (with stride 1)
주목해야할 것은 "왜 3x3 convolution filter를 사용했는가 이다. 커널 사이즈가 커지면 receptive field 가 커지고, 그만큼 많은 영역의 정보를 파악할 수 있다. 반면 학습해야하는 parameter의 수가 커지는 문제점이 있다. 그렇다면 receptive field를 유지하면서 파라미터 수를 줄일 수 있는 방법은 무엇이 있을까?
5x5receptive field 는 두개의3x3커널을 이용하는 것 과 같으면서 parameter의 수는 줄어든것을 확인할 수 있다.
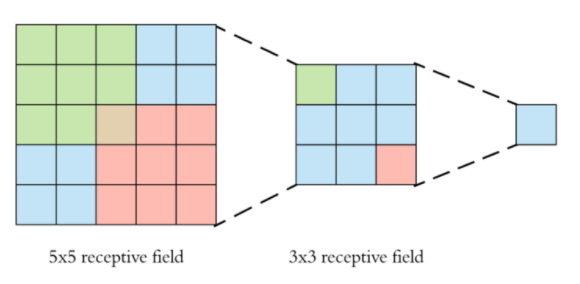
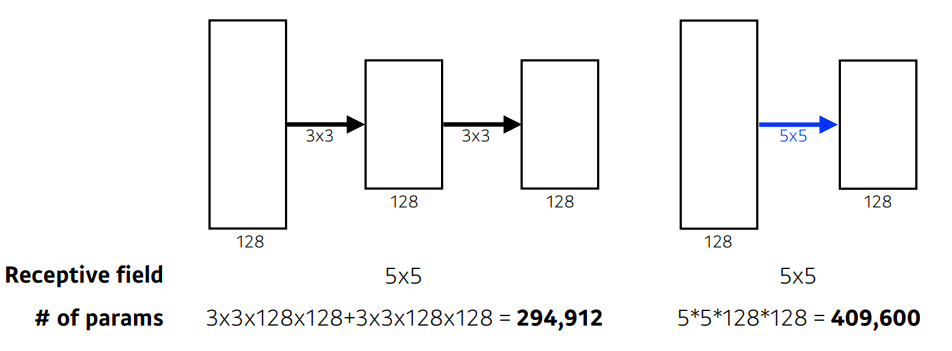
나아가,7x7receptive field 는 세개의3x3커널을 이용한것 과 같다는것을 알 수 있다. -
Dropout(p=0.5)
over-fitting을 막기위해 랜덤하게 일부 뉴런을 생략하여 학습한다. -
VGG16,VGG19
위에서 언급했듯이,VGGNet은 network의 depth가 어떤 영향을 주는지 연구하기 위함이었기 때문에,16-layer이외에도19-layer를 실험하였고,16-layer와 비교했을때 error 가 비슷하거나 더 안 좋은 결과를 보여준다.
✏️ GoogLeNet
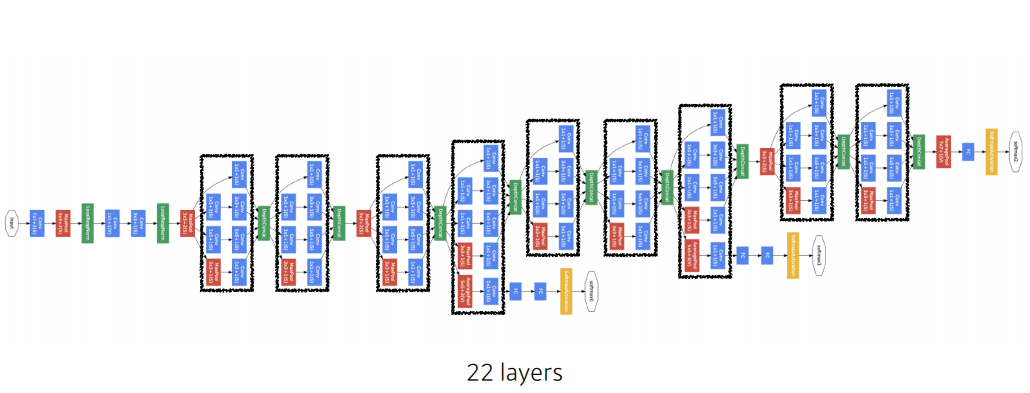
GoogLeNet 은 2014년 ILSVRC 에서 우승한 모델로, network-in-network(NIN) 개념을 차용하여 inception block 이라는 모듈의 적층 구조를 가지고 있다. 다음은 GoogLeNet 이 가지는 주요 특징들이다.
-
network-in-network(NIN)

GoogLeNet은NIN개념을 차용하여Mlpconv layer와 같은 하나의 모듈로 완성되는 구조를 만들고자 하였다.
-
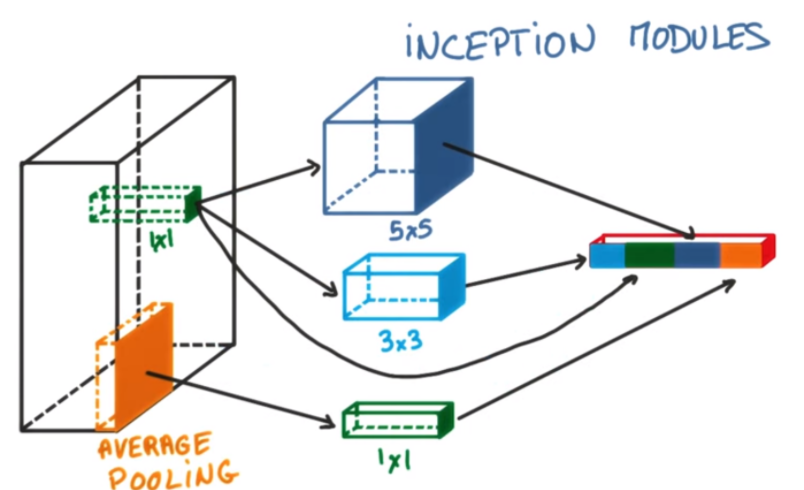
Inception blocks
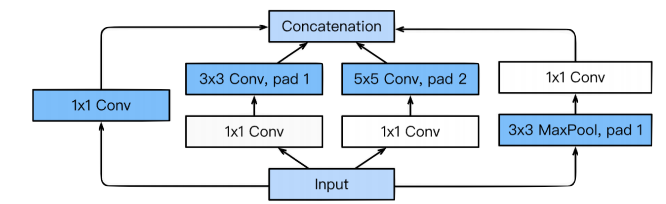
GoogLeNet은1x1,3x3,5x5의 필터를 사용하여,1x1은 입력데이터의 공간적 정보를 비교적 잘담게 만들고,3x3,5x5는 더 추상적이고 퍼져있는 정보를 잘 담게 하였다. 주목할것은1x1convolution이 각 필터에 적용되어 있다는 것이다. -
1x1 convolution

1x1 convolution 이 주는 가장 큰 이점은 차원감소의 효과이다. 즉,1x1 convolution 을 사용하여 파라미터 수를 줄여 깊은 망을 구성할수 있도록 하였다.

위의 그림을 보면 depth=128, 입력데이터 를 depth=128, 출력데이터를 만들기 위해 3x3 convolution을 적용하면 개의 파라미터 수를 가진다. 그러나 앞 단에 1x1 convolution을 통해 depth=32 로 줄인 후 다시 3x3 convolution으로 depth=128, 출력데이터 를 만든다고 한다면 개의 파라미터를 가져 연산량 조절을 할 수 있음을 확인할 수 있다.
- Auxiliary Classifiers
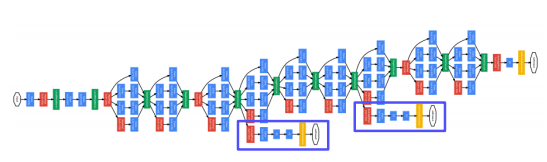
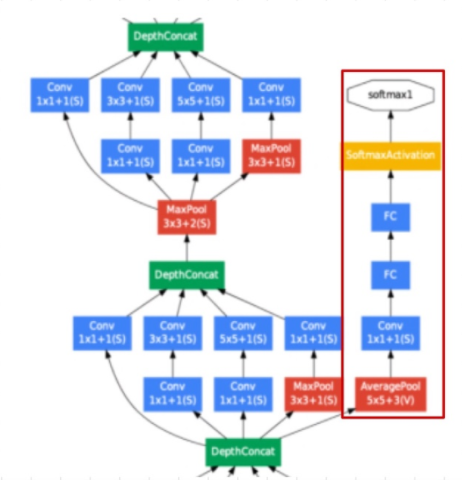
층이 깊어질수록 gradient vanishing 문제가 발생할 수 있는데, 이를 해결하기 위해 Auxiliary Classsifiers를 통해 중간 단계에서 gradient를 주입하여 하위 레이어에도 잘 전달될 수 있도록 한다. 주의할것은 학습시에만 사용되고 inference time 에서는 제거한다.
✏️ ResNet
ResNet 은 2015년 ILSVRC 에서 우승한 모델로, 2014년의 GoogLeNet 이 22-layer 로 구성된것에 비해 152-layer를 갖는다. ResNet 은 그동안 네트워크가 깊어지면서 성능이 올라갔고, 그렇다면 "깊이가 깊어지면 무조건 성능이 좋아질까?" 에 대한 의문에서 시작되었다.

그래서 20-layer 와 56-layer로 테스트 해본 결과 gradient vanishing/exploding 으로 인한 degradation 문제로 56-layer의 결과가 20-layer보다 더 나쁜 성능을 보였고, 이는 무조건 깊게 만드는것이 아닌 새로운 방법을 찾아야한다는 motivation을 얻게 되었다. 다음은 ResNet이 가지는 주요 특징들이다.

- Residual block
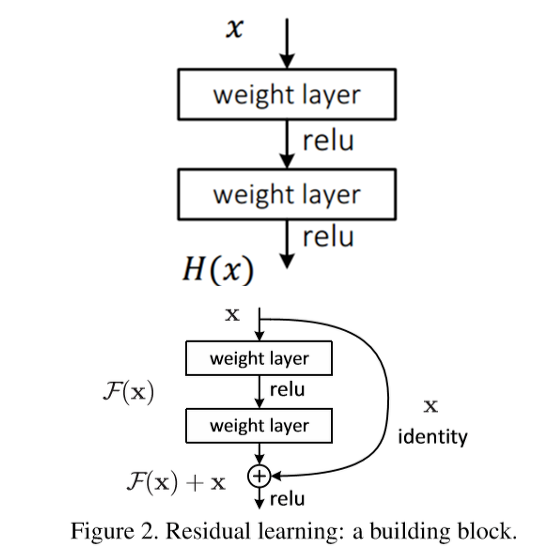
Residual unit 을 수식으로 살펴보기전 다음과 같이 notation을 정의한다.기존의 모델 경우feature이 입력되면 을 출력한다. 하지만ResNet에서 제안하는 residual learning 에서는 입력값을 그대로 전달하는 identity mapping 를 이용하여를 최소화 하는것을 목적으로 한다. 이때, 은 현시점에서 변할 수 없으므로 을 최소화하는 것을 의미하며, 이것은 이전 레이어들의 출력과 추가된 레이어의 출력의 차이값(residual)을 최소화하는것을 의미한다. 이 과정이 어떤 영향을 끼치는지에 대해 살펴보기전에, 계산을 쉽게하기 위해 activation function이 제외된 로 가정하도록 한다. 그러면 residual unit 은 다음과 같이 표현된다.이를 recursive 하게 계산하게 되면,가 된다. 그리고 이를 미분해보면 ,의 형태로 이루어진다. 두번째 term인 은 기존의 weight layer를 통과하면서 계산된 gradient 이며, 첫번째 term 은 상위 레이어의 어떤 gradient 라고 하더라도 그값이 변하지 않고 그대로 전파해준다. 따라서, 이러한 특성으로gradient vanishing문제를 해결한다.
- Simple Shortcut vs Projected Shortcut
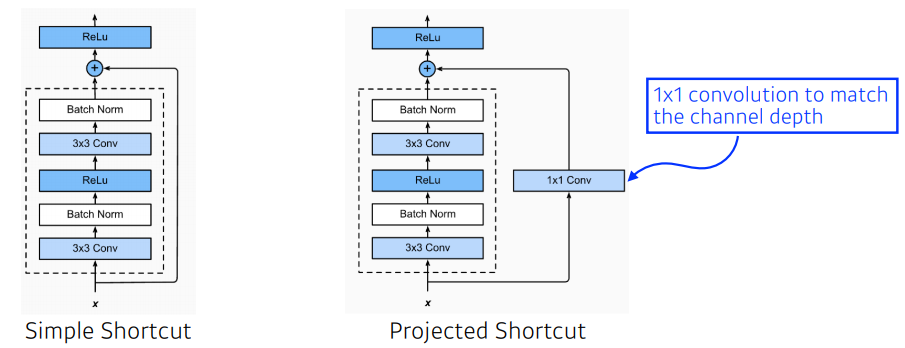
ResNet은VGG-19를 기반으로 한Plain-model에 shortcut을 추가하였는데, shortcut을 적용할때 에서 는 convolution filter를 통과하였기 때문에 filter 수가 증가하게 되면 차원수가 높아지기 때문에 의 차원을 높여줘야 한다. 따라서simple shortcut은 차원이 증가하지 않은 경우는 identity shortcut / 차원이 증가한 경우는 zero padding shortcut 하며,projected shortcut은1x1convolution 을 통해 증가시킨다.
- Batch normalization after convolutions
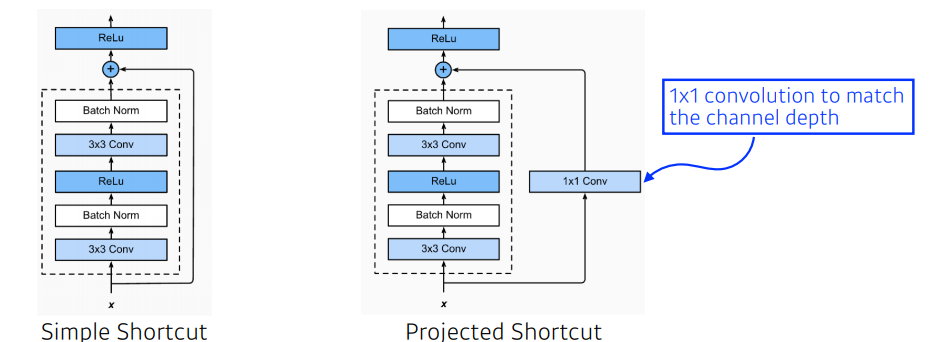
convolution 연산 후 batch normalization을 한다.
-
Bottle neck

학습시간을 줄이기 위해1x1convolution 을 이용한bottle neck design이 적용됐다. -
He initialization
ResNet의 경우 indentity mapping 으로 이전 입력값을 그대로 전달하기 때문에 가중치 초기값 설정이 학습과정에 큰 영향을 끼칠 수 있음을 알 수 있다. 그래서 이에 적합한 초기화 방법으로 He initialization 을 사용하였다.
아래의 실험결과는 Plain-model 에선 네트워크가 깊어져도 성능이 올라가지 않았지만 ResNet의 경우 더 깊은 네트워크의 성능이 올라간것을 확인할 수 있다.

✏️ DenseNet
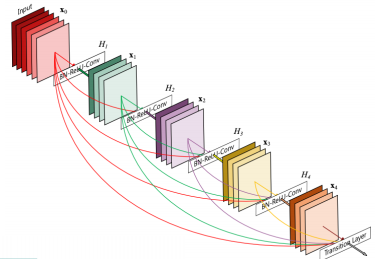

다음은 DenseNet 가지는 주요 특징들이다.
-
Dense block
ResNet 은 pairwise+한 반면DenseNet은 순차적으로 앞단의 모든 layer의 결과를 그 다음 layer에 dense 하게concatenate한다.
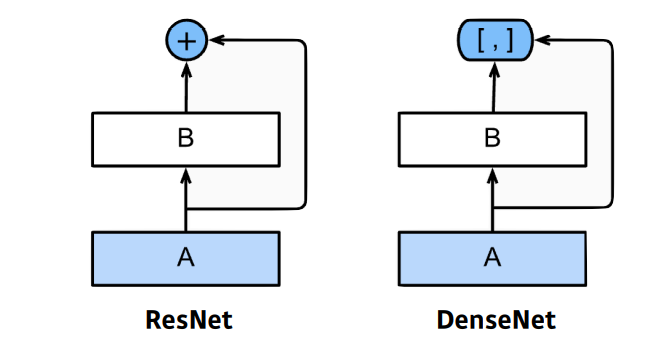
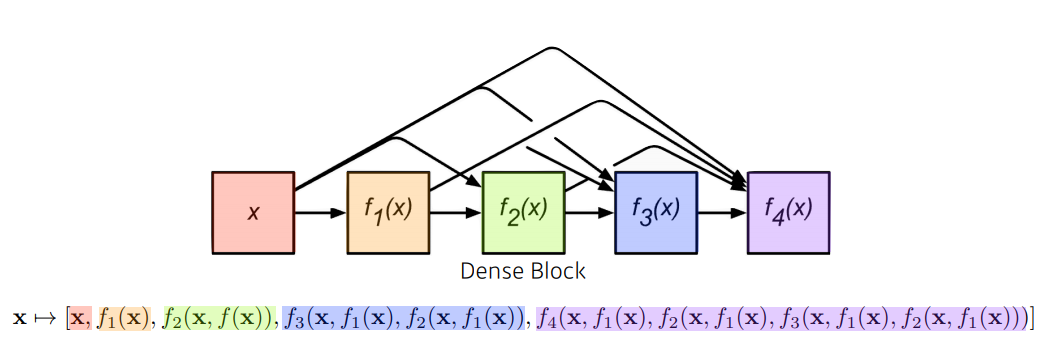
-
Transition block
Dense block 으로 인해 채널이 커지고 파라미터의 수가 급격하게 증가하기 때문에 transition blockBatch normalization -> 1x1 conv -> 2x2 AvgPooling을 통해 차원의 수를 줄인다.
📄 Semantic Segmentation
Semantic Segmentation 은 pixel-level classification 으로 이미지에 있는 모든 픽셀에 대한 예측을 하는것이기 때문에 Dense Prediction 이라고도 불린다.
Semantic Segmentation 을 위해 제안된 딥러닝 모델에는
- FCN
- DeepLab v1, v2
- U-Net
- ReSeg
- ...
등 많은 모델들이 있지만 최초의 pixelwise end to end 예측모델인 Fully Covolutional Networks For Semantic Segmentation(FCN) 에 대해 집중적으로 알아 보도록 한다.
✏️ Fully Convolutional Networks(FCN)
FCN 은 Semantic Segmentation 문제를 위해 기존에 이미지 분류에서 우수한 성능을 보인 CNN 기반모델(AlexNet,VGG-16,GoogLeNet)을 목적에 맞게 변형시킨것이다. 이름에서도 알수있듯이, convolutional layer 만을 사용하였으며,주목할것은 기존의 CNN 모델 뒤쪽에 있는 FC(Fully Connected) layer 를 1x1 convoluional layer 로 대체했다는 것이다.
Image classification 을 Sementic Segmentation 으로 바꾸기 위해 FCN 은 크게 다음 3가지로 구성된다.
- Convolutionalization
- Deconvolution(Upsampling)
- Skip Architecture
✅ Convolutionalization

위에서 언급했지만,FCN은 핵심 아이디어는 FC layer를 사용하지 않고 1x1 convolutional layer를 사용한것이다. 기존의 FC layer 의 경우 입력의 모든 차원을 출력의 모든 차원과 연결하도록 가중치를 훈련 시키므로 입력을 더 크게 만들면 더 많은 가중치가 필요하다. 즉, 고정된 입력 크기를 가질 수 밖에 없다. 또한, 이미지의 공간적 정보가 소실 된다. 이를 보완하기 위해 convolutional layer 는 각 이미지를 flattening 하는 것이 아닌 다음과 같이 각 channel 의 이미지 위치마다 flattening 하여 얻는 벡터들을 fully-connected 하는데, 이것은 1x1 convolution 연산과 동일하다.
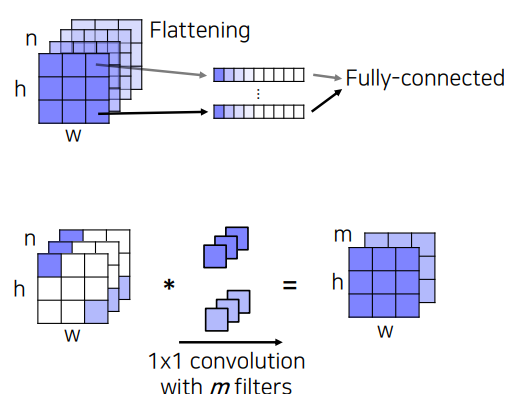
그래서 convolutional layer 는 입력사이즈에 independent 하기 때문에 입력사이즈의 제한을 받지 않고, 공간 정보를 보존할수 있게 되는 이점이 있다.

✅ Deconvolution(Upsampling)
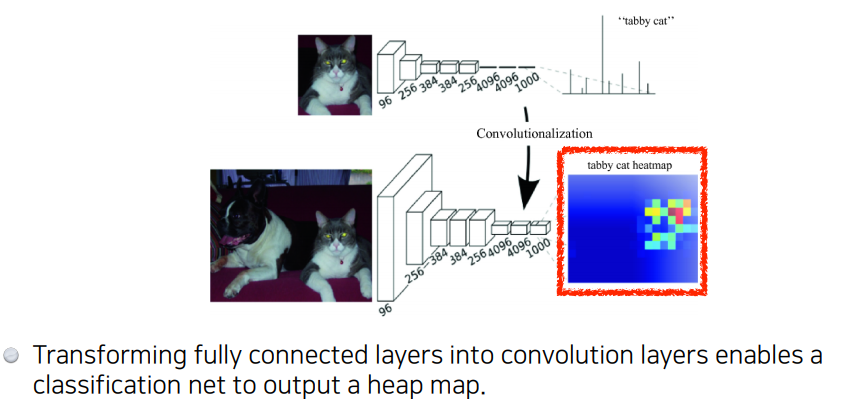
Convolutionalization 을 통해 얻은 heatmap은 하나의 class를 대표하는 대략적인(coarse) 정보이다. 하지만 우리의 목적은 dense prediction 이기 때문에 coarse map 을 dense map 으로 복원하는 deconvolution 이 필요하다.
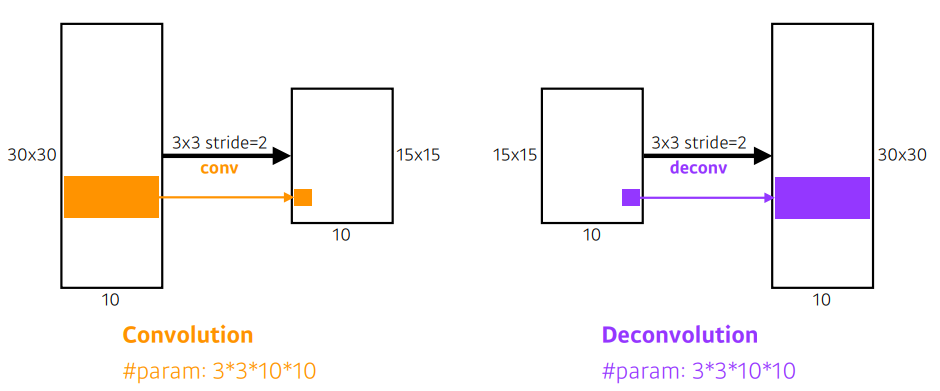
<참고>
Deconvolution 은 엄밀히 말하면 convolution 의 역연산은 아니지만 (convolution의 역연산이 존재할수가 없다. 예를들어 3x3 convolution 을 생각하면 3x3의 정보를 합쳐 하나의 정보로 만들기 때문에 역으로 각 3x3 의 각각의 값을 결정할 수 없기 때문이다.) 직관적인 이해를 위해 역연산으로 생각한다.
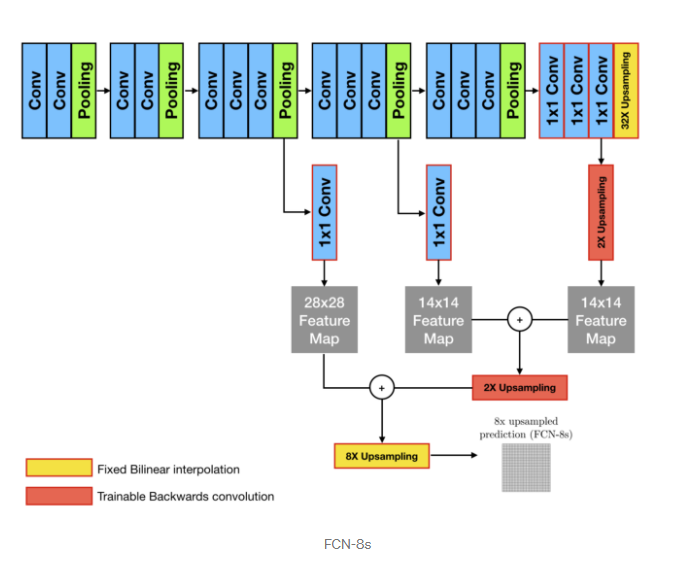
✅ Skip Connection
Deconvolution 을 통해 coare map을 dense map으로 복원하였지만, 근본적으로 feature map 크기가 작았기 때문에 여전히 coarse map 이다. 그렇다면 어떻게 더 정확한 segmentation을 얻을 수 있을까?
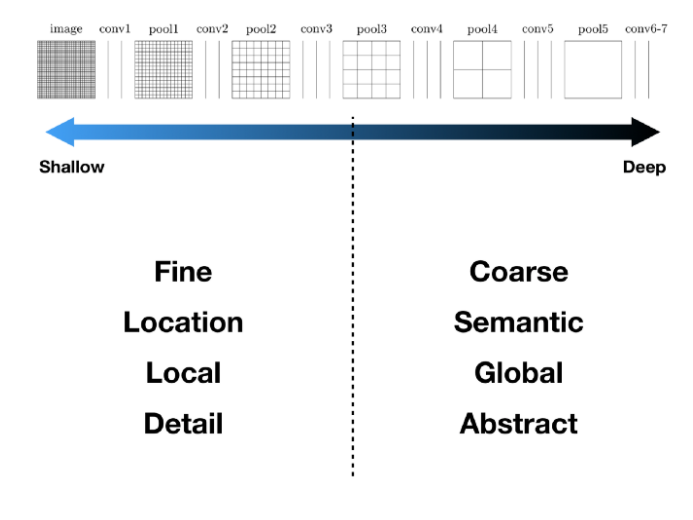
ZFNet의 시각화를 통해 이 문제에 대한 직관을 얻을 수 있는데, 얕은층에선 주로 직선,곡선,색상등 local feature를 깊은층에선 얕은층에 비해 개체의 일부분,위치나 자세 변화와 같은 global feature 를 추출해낸다는 것이다.

이 직관을 바탕으로 정확한 segmentation을 얻기 위해 Deep & Coarse 레이어의 global feature 와 Shallow & Fine 층의 local feature 를 결합한 skip connection 을 이용한다.

📄 Object Detection
classification 과 localization의 문제로, 어떤 이미지가 들어 오면 이미지 내 관심이 있는 객체의 위치(Region Of Interest,ROI)를 Bounding Box를 그려 localization 하고 , 다수의 Bounding Box를 다양한 object로 classification 한다. 2014년 기존의 CNN을 classfication 뿐만 아니라 object detection 에서의 적용을 이끌었던 R-CNN 부터 그 이후의 발전된 모델들의 주요 아이디어를 살펴보도록 한다.
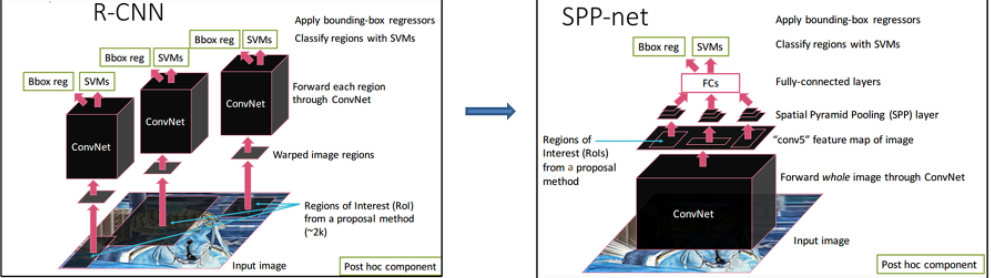
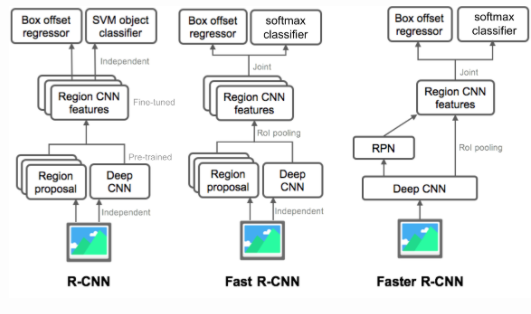
✏️ R-CNN

R-CNN은 Multi-stage Detector 로, object 위치를 찾는 Region Proposal 과 object를 분류하는 Region Classfication 두 단계를 가지는 모델이다. 다음은 R-CNN의 전체적인 구조이다.
-
Region Proposal
-
CNN
- SVM(Support Vector Machine) & Bounding Box Regression
✅ Region Proposal
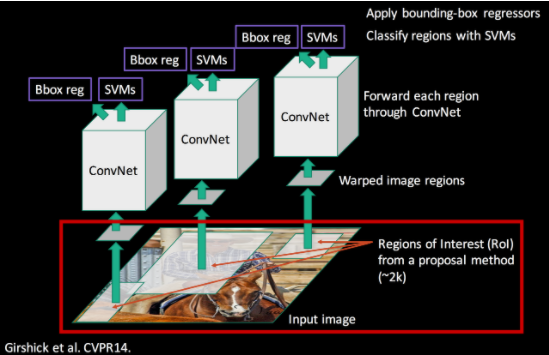
object의 위치를 찾는 단계로, Selective Search 를 이용하여 약 2000개의 후보 영역을 추출한다. 이 후 227x227 의 고정된 입력을 받는 CNN 모델에 넣기 위해 추출된 후보영역의 사이즈를 해당 사이즈의 이미지로 warping 한다. 간단하게 Selective Search 에 대해 설명하면 이미지의 구조적인 특징(색상,무늬,크기,모양등) 을 이용하여 물체의 위치를 파악할 수 있도록 하는 알고리즘으로,다음과 같은 구조를 가진다.
-
Efficient Graph-Based Image Segmentation, Felzenszwalb에서 제안된 segmantation 알고리즘을 활용하여 초기 후보영역을 다양한 크기와 비율로 생성한다. -
많은 초기 후보영역들을
유사도(Similarity)를 활용하여 greedy 하게 비슷한 영역들을 병합한다. -
최종적으로 하나의 영역이 만들어질 때까지, 2번의 과정을 반복한다.

✅ CNN
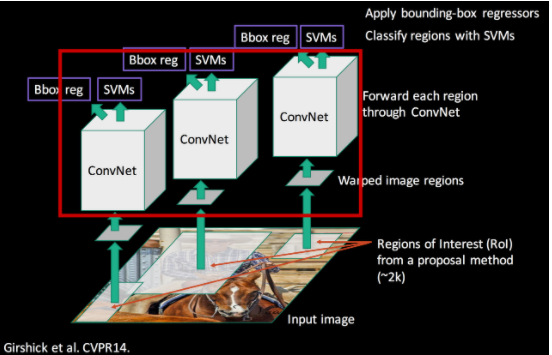
약 2000개의 warped image를 각각 CNN에 넣어 feature를 추출하는 단계로, 기존의 AlexNet 을 Fine-tunning 하여 사용했다. 각 CNN은 fixed-length feature vector(4096-dimensional feature vector) 를 추출한다.
✅ SVM & BBox Regressor
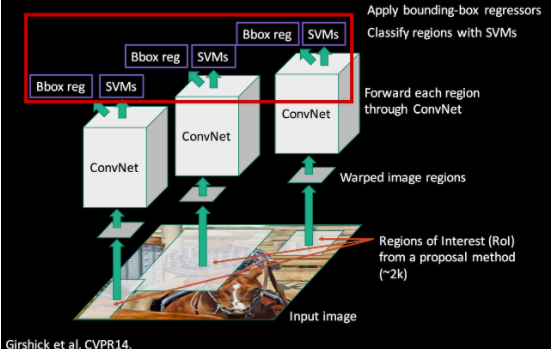
추출된 fixed-length feature vector를 활용하여 object를 분류하는 단계로, SVM 를 이용한다. (여기서 Softmax 가 아닌 SVM 을 사용한 이유는 CNN fine-tunning을 위한 학습데이터가 시기상 많지 않아서 Softmax을 적용하면 오히려 성능이 낮아지는 이슈로 SVM을 사용했다고 한다.) 또한,BBox Regressor를 통해 정확하지 않은 Bounding Box 의 위치를 조정해준다.
R-CNN 은 CNN을 object detection 문제에 최초로 적용하고 기존의 object detection 에 비해 굉장히 뛰어난 성능을 보인것은 맞지만, 명확한 단점들을 가지고 있다.
-
시간이 오래 걸린다.
앞서 살펴봤듯이, 약 2000개의 후보영역들을 각각 CNN 모델에 넣기 때문에 시간이 오래걸린다. -
복잡하다.
Multi-stage Training을 수행하며, CNN,SVM,BBox Regressor 까지 총 3가지의 모델을 필요로하여 복잡하다. -
End-to-End learning 이 불가능하다.
Multi-stage Training 으로 SVM,BBox Regressor 에서 학습한 결과가 CNN을 업데이트 시키지 못한다.
✏️ SPPNet(Spatial Pyramid Pooling Network)

R-CNN이 가지는 큰 문제점 2가지는
-
약 2000개의 후보영역을 각각 CNN에 넣기 때문에 2000번의 CNN 연산 이 소요된다.
-
CNN 입력 사이즈가
227x227로 고정되어 있기 때문에, warped image를 넣어야 했고 이 과정에서 image distortion이 발생할 수 있다.
SPPNet 은 이러한 문제를 해결하려 하였고, 다음과 같은 특징을 가진다.
-
Multi-stage Detector
-
Reduce CNN Operation
-
Spatial Pyramid Pooling
✅ Multi-stage Detector
구조는 R-CNN 과 다르지만 3가지의 pipeline(CNN,SVM,BBox Regressor) 으로 이루어진 Multi-stage Detector 라는 점은 같다.
✅ Reduce CNN Operation
앞서 설명했듯이,R-CNN은 region proposal 을 먼저 적용해 추출된 2000 개의 후보영역 ROI(Region Of Interest) 을 각 CNN 모델에 넣었기 때문에, 많은 CNN 연산을 수행햇다. 그러나 SPPNet은 입력 이미지에 대해 CNN 연산을 먼저 적용한 후 feature map에 기반한 region propoal 과정을 거치기 때문에, 1번의 CNN 연산 과정을 가진다.
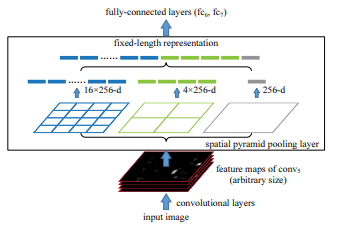
✅ Spatial Pyramid Pooling

추출된 ROI 에 대해 SPP가 어떻게 작동하는지 살펴보기위해 , 13x13 ROI feature에 대해 3x3 spatial bin 을 사용하여 pooling 한다고 가정한다. 3x3 spatial bin 을 사용한다는 것은 3x3 feature map 을 얻는 것을 의미하는데, 3x3 feature map을 얻기 위해서는 kernel size=5 ,stride=4 로 설정하여 얻을 수 있음을 알 수있다. 이때, receptive field 에 대해 max pooling 연산을 진행한다.
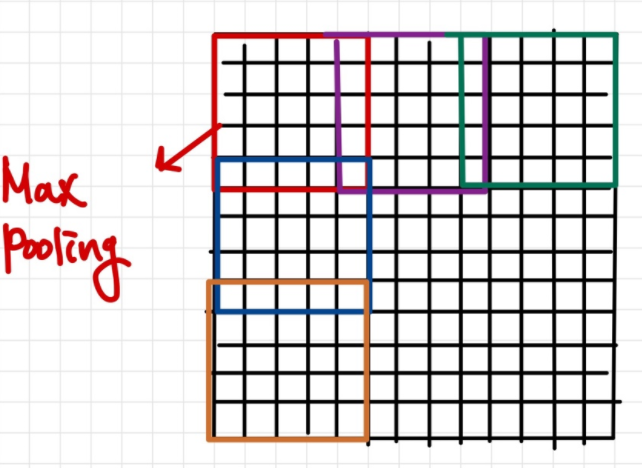
즉, ROI feature size 에 따라 kernel size 와 stride 만 설정하면 다양한 resolution을 설정할 수 있게 된다. 그래서 warping 작업이 필요가 없게 되고, 다양한 resolution 가지기 때문에 Spatial Pyramid Pooling 이라고 한다.
SPPNet 은 1x1,2x2,4x4 spatial bin을 사용하여 얻은 spatial bin들을 flattening 한fixed-length feature vector 를 FC layer에 넘겨준다.
SPPNet 은 R-CNN 의 소요시간과 비교하면 더 빨라졌지만, 그럼에도 불구하고 다음의 문제들을 해결하지 못했다.
-
복잡하다.
Multi-stage Training을 수행하며, CNN,SVM,BBox Regressor 까지 총 3가지의 모델을 필요로하여 복잡하다. -
End-to-End learning 이 불가능하다.
Multi-stage Training 으로 SVM,BBox Regressor 에서 학습한 결과가 CNN을 업데이트 시키지 못한다.
✏️ Fast R-CNN
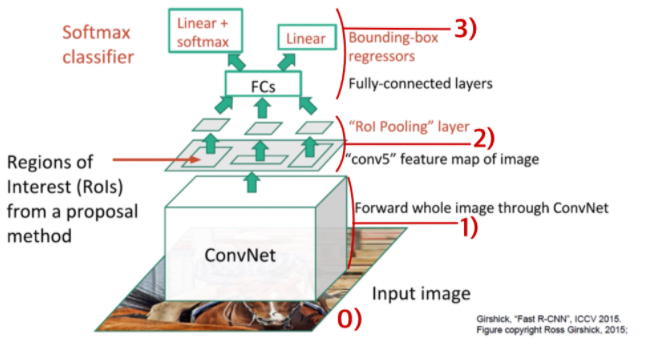
Fast R-CNN 은 SPPNet 과 비슷한 구조를 가지지만, 다음과 같은 차이점이 있다.
-
ROI Pooling Layer
-
Softmax Classifier
-
Multi-task loss
-
Truncated SVD
✅ ROI Pooling Layer
SPPNet 은 1x1,2x2,4x4 spatial bin 을 사용했다. 이것의 문제점은 3가지 resolution 으로 학습하기 때문에 하나의 object에 대해 지나치게 학습이 되어 over-fitting 문제가 발생할 수 있다. 그러나 Fast R-CNN에서는 7x7 single level spatial bin을 사용하여, over-fitting 문제를 피했으며 이를 ROI Pooling Layer 라고 한다.
✅ Softmax Classifier
SVM classifier 가 아닌 Softmax classifier 를 이용했다.
✅ Multi-task loss
R-CNN, SPPNet 에서는 BBox Regressor 와 SVM Classifier 가 따로 학습이 되었다. 하지만 Fast R-CNN 에서는 하나의 loss fucntion을 학습하여 End-to-End learning 을 가능하게 하였다.

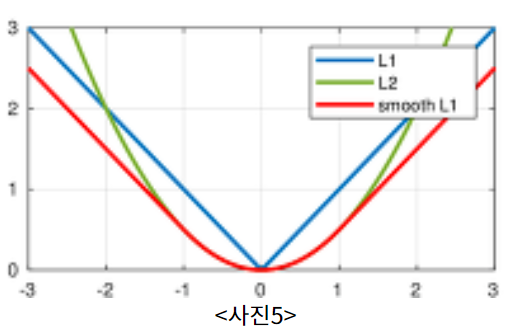
Classification loss / bounding box regression loss 를 사용하였다. bouding box regression loss 를 살펴보면 Iverson bracket 을 사용하여 표현하였는데, u=0 이면 값이 0 이되어 가 사라짐을 확인할 수 있다. 또한
을 이용하여 outlier의 영향력을 줄였으며(L2-loss 사용시, outlier에 의한 격차로 gradient exploding 문제가 있었다고 한다.), 를 통해 L1-loss 와 L2-loss간의 균형을 잡아준다.
✅ Truncated SVD
CNN 연산 후 region proposal 을 적용함으로서 R-CNN 에서 나타나는 문제를 해결하였지만, region proposal 후 생성된 약 2000개의 ROI를 FC layer 에 넣기 때문에 소요되는 시간이 많았다. 그래서 SVD(Single Value Decomposition) 을 통해 compression 하여 파라미터 수를 줄여, 소요시간을 줄였다.
✏️ Faster R-CNN
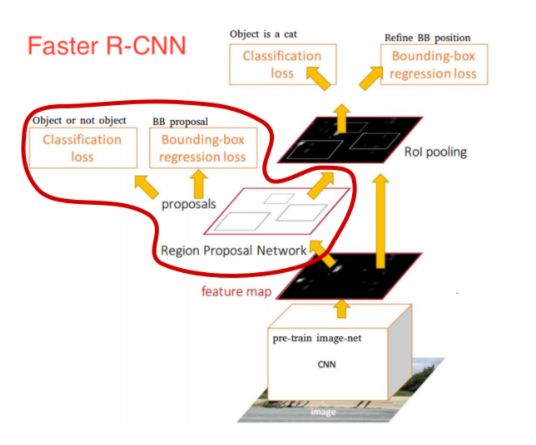
Faster R-CNN은 이름에서 알 수 있듯이,Fast R-CNN을 한층 발전시킨 모델이다. Fast R-CNN 은 R-CNN,SPPNet 보다 처리속도를 많이 감소시켰지만, 그럼에도 불구하고 CPU를 기반으로 처리되는 region proposal 과정이 약 2초가량 소요되어 느린 처리속도의 문제가 있었다. 그래서 Faster R-CNN 은 region proposal 과정 또한 학습을 시키는 RPN(Region PropoSal Network)을 제안하였다.
✅ RPN(Region Proposal Network)
Faster R-CNN 에서 CNN backbone 으로 ZFNet 과 VGG-16 을 이용하는데, 많은 Fatser-CNN 코드들이 VGG-16을 backbone으로 사용하기 때문에 이것을 기준으로 살펴보도록 한다.(아래의 그림은 ZFNet 기준의 그림이어서 256-d 으로 표현되었지만 VGG-16 의 경우 512-d 의 feature map을 출력한다.)
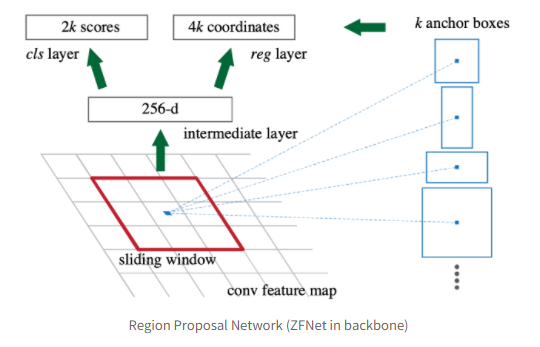
CNN 의 출력 feature map위에 NxN window 를 입력으로 받아 해당영역에 object 가 존재하는지/존재하지 않는지 2개의 class 를 분류하는 classification layer(cls layer) 와 BBox regression 을 진행하여 4개의 class(x,y,w,h)를 결정하는 regression layer(reg layer) 가 존재한다. 하지만 이렇게 단순하게 RPN을 설계할경우, 댜앙한 크기와 비율의 object를 수용하기에는 고정된 NxN window는 한계가 있다. 그래서 pre-defined scale/ratio 를 바탕으로 reference box k 개를 정해 놓고 각 sliding window의 위치마다 k개의 box를 출력하도록 설계하였고, 이것을 anchor 라고 명칭하였다. 여기에선 k=9 인 refernce boxes를 다음과 같이 정의했다.

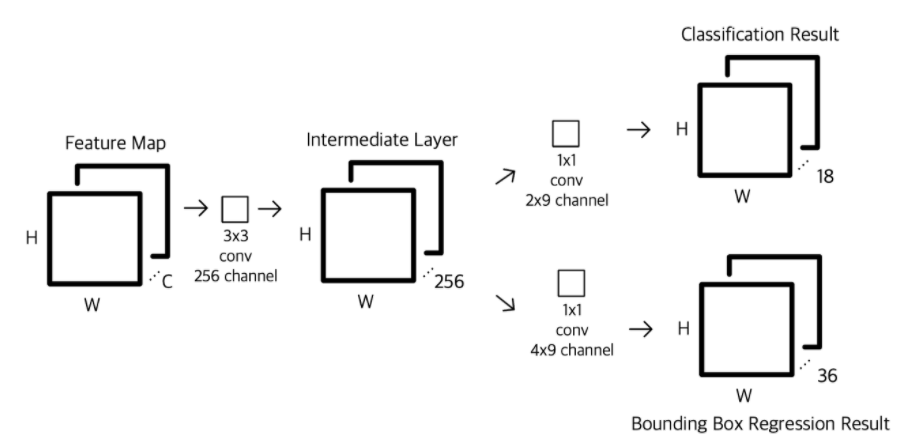
위의 그림은 ZFNet 을 기준으로 설명한 그림이지만, VGG-16을 기준으로 생각해본다면,224x224 이미지가 VGG-16 을 통과하여 나온 feature map 은 14x14x512 이다. 여기에 sliding window 과정을 가 보존되도록 padding=1 을 준3x3x512,stride=1,padding=1 convolution 연산으로 생각해볼수 있다. 그러면 14x14x512 의 결과가 나오게 되고 이것은 intermediate layer를 뜻한다. 이후 1x1 convolution 연산을 통해 각 anchor에서 k개의 anchor box를 생성하여 목적에 맞게 cls layer 와 reg layer를 생성해낸다. 즉 cls layer, reg layer 는 14x14x(9x2) ,14x14x(9x4)의 feature map을 얻게 된다.
✅ Training
위에서 RPN 에 대해 이해했으므로 전체적인 학습과정은 어떻게 진행되는지 확인해보면,
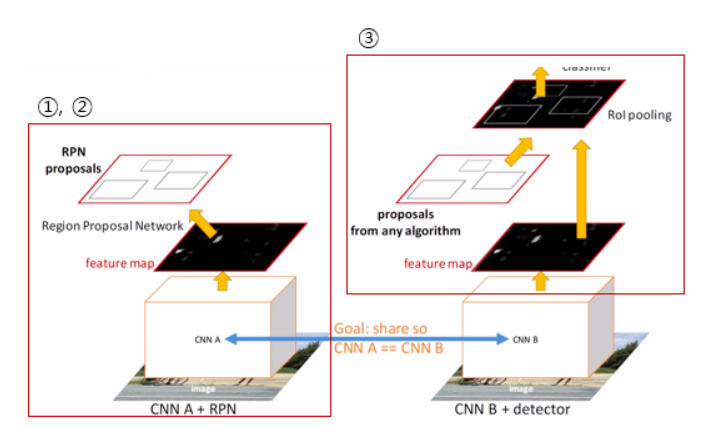
-
Pre-trained CNN Model (M0) 을 가져와서
RPN을 ImageNet 데이터로 학습을 시킨다. -
학습된
RPN(M1) 에서 ROI(P1) 을 추출한다. -
Pre-trained CNN Model (M0) 과 ROI(P1) 를 적용시켜
Fast R-CNN을 학습시킨다.
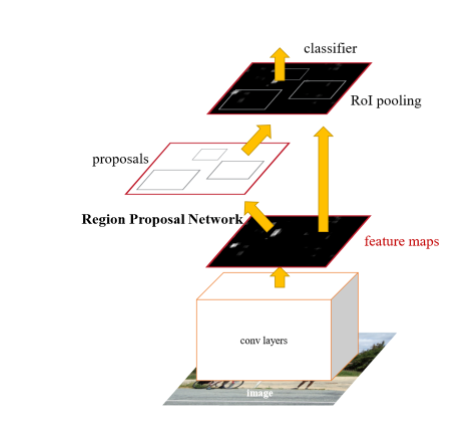
-
학습된
Fast R-CNN(M2) 를 이용해RPN을 재학습시킨다. (처음엔RPN과Fast R-CNN이 독립적으로 학습되나, 이때부터RPN의 feature 와Fast R-CNN의 feature를 sharing 한다.) -
재학습된
RPN(M3) 에서 ROI(P2) 를 추출한다. -
재학습된
RPN(M3) 과 추출된 ROI(P2) 를 적용시켜Fast R-CNN을 학습시킨다.
✏️ Summary of Models In The R-CNN Family
✏️ YOLO-v1

Faster R-CNN 에서 언급된 fps 성능은 5fps 이다. 물론 detection 성능인 mAP(Mean Average Precision)은 높은 수준을 유지하고 있지만 real-time(30fps) 수준에는 한참 못미치는 수준이었다. 그렇다면 "detection 성능은 조금 떨어뜨리더라도 높은 fps 성능을 갖는 모델을 구현할수 없을까?" 라는 motivation 으로 시작된 모델이 YOLO-v1 이다. 그래서 Faster R-CNN에서는 localization 과 claasification 이 따로 나뉜 구조인 반면에 YOLO-v1은 동시에 localization 과 classfication을 진행하게 된다.
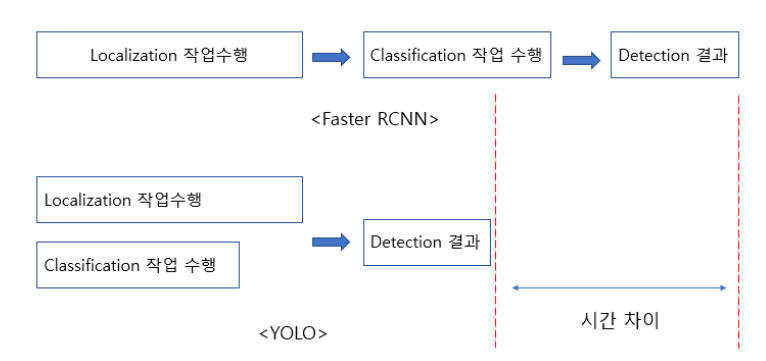

그렇다면 어떻게 localization 과 classification 정보를 구축하는 것일까?
YOLO-v1 은 다른 Object detection 모델처럼 CNN을 통해 feature map(SxS) 을 추출 하는데, 여기서는 7x7 feature map을 생성하였고, grid cell 이라고 표현하고 있다.

각각의 cell은 localization 을 위해 2개의 BBox(ROI)를 생성하고 BBOX의 위치정보(x,y,w,h) 와 confidence score 정보(BBox에 object가 포함되어 있을 신뢰도) 를 가지고 있다. 동시에 각각의 cell은 classification 을 위해 어떤 class 에 속할지에 대한 를 가지고 있다. 따라서 7x7 feature map 은 각각의 cell 이 2개의 BBox 를 생성하고 이에 대한 5개의 정보(x,y,w,h,confidence score) 를 가지고 있고, classfication을 위해 20개의 class(Pascal VOC Challenge 는 20개의 class에 대한 detection) 정보를 가지고 있어 7x7x(2x5+20)=7x7x30 인 output을 얻게 된다.

📚 Reference
Receptive Field vs Feature Map
Receptive Field
Convolutional Neural Network1
Convolutional Neural Network2
Stride & Padding
AlexNet1
AlexNet2
VGGNet1
VGGNet2
GoogLeNet
ResNet1
ResNet2
Fully Convolutional Network1
Fully Convolutional Network2
Fully Convolutional Network3
Selective Search
R-CNN1
R-CNN2
SPPNet
Fast R-CNN1
Fast R-CNN2
Fast R-CNN3
Faster R-CNN1
Faster R-CNN2
Faster R-CNN3
Faster R-CNN4
Summary of Models In The R-CNN Family
YOLO-v1
