
📌 CV(Computer Vision)
📄 Image Classification
이미지 분류(Image Classification) 은 CV에서 가장 기본적인 task 이다. 가령, 강아지와 고양이의 이미지가 주어졌을때, classifier 를 통해 주어진 이미지가 강아지인지 고양이 인지를 구분하는 것이다.
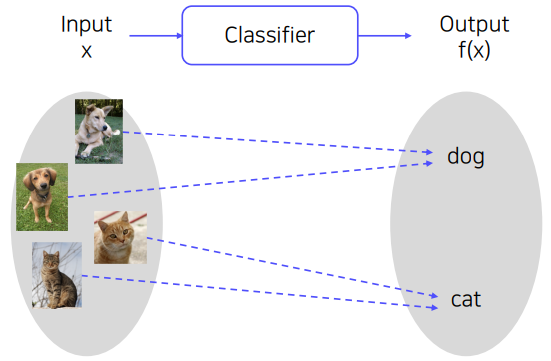
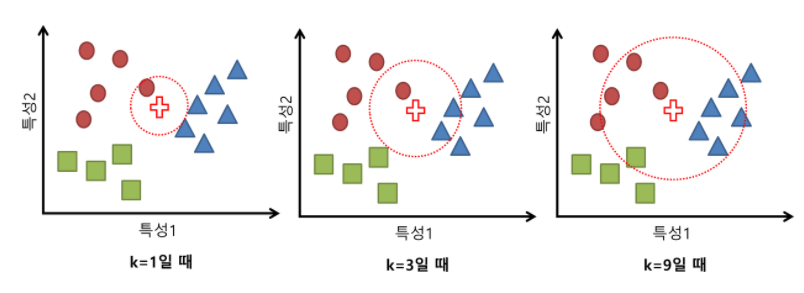
가장 이상적인 classifier는 세상에 존재하는 모든 이미지 데이터를 "유사한" 이미지끼리 모아서KNN(K-Nearest Neighbors) 을 적용하는 것이다. KNN에 대해 간단하게 설명하면, 주변 k개의 가장 가까운 이웃들을 살펴봐서 더 많이 속하는 class로 분류하는 알고리즘이다.
즉, KNN을 이용한다면 단순히 주변 이웃을 살펴 분류하므로 검색문제로 바뀌게되고 잘 해결할 수 있을 것이다. 하지만 다음과 같은 문제로 실제 문제에서는 적용이 어렵다.
-
세상에 있는 모든 이미지 데이터를 구할수 없다. 만약 구할수 있다고 하더라도 모든 이미지 데이터를 검색하는 시간을 단순히 linear search로 생각하더라도 무한히 많은 시간이 걸린다. 또한 모든 데이터를 저장할 공간 역시 무한히 커지게 된다.
-
이미지의 유사도를 정의하는 것이 쉽지 않다.
✏️ NN(Neural Networks) vs CNN(Convolutional Neural Networks)
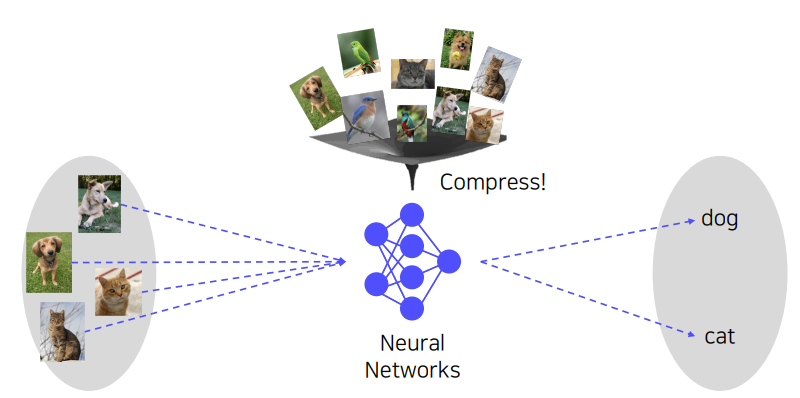
또 한가지 생각해 볼 수 있는 방법은 데이터의 패턴을 학습한 NN(Neural Networks) 를 이용하는 것이다.
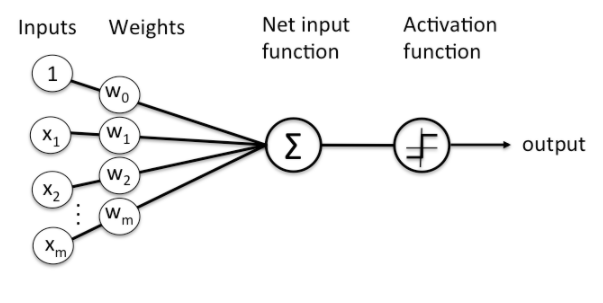
이해를 돕기 위해 , Single-layer Perceptron 으로 생각해본다면 이미지 데이터의 픽셀 값들을 입력으로 받아 FC(Fully-connected) layer 를 통과하여 activation function 을 통해 분류하는 것이다.
가령, 2x2 이미지 데이터가 있다면 같은 크기의 2x2 weight matrix(=FC layer) 를 학습하는 것으로 생각할 수 있다.
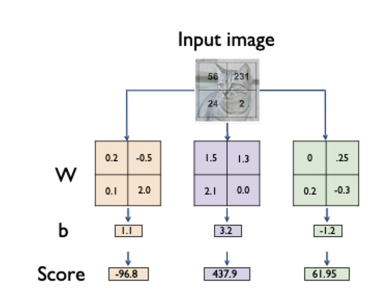
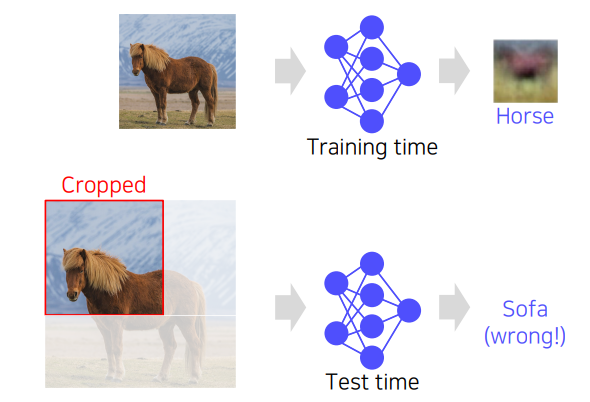
하지만 이것의 가장 큰 문제점은 이미지 전체의 패턴에 대해 학습했기 때문에, 가령 반쯤 잘리거나 학습된 이미지의 패턴과는 전혀 다른 이미지가 주어진다면 올바른 결과를 내지 못하는 것에 있다. 또한 이미지의 크기가 커진다면 학습해야할 파라미터의 수가 증가한다.
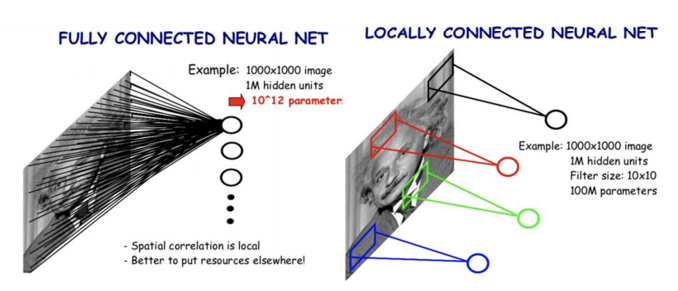
그래서 이 문제를 해결하기 위해 CNN(Convolutional Neural Networks) 은 Fully-connected layer 가 아닌 Locally-connected layer 를 통해 local feature들을 학습하게 하고, 파라미터를 공유(shared parameter) 함으로써 학습해야 할 파라미터의 수를 줄일수 있도록 디자인 하였다.
이를 바탕으로 CNN은 이미지 데이터를 효과적으로 다룰 수 있는 구조로 발전되었으며, 이미지 분류를 위한 대표적인 CNN 모델의 발전과정은 다음과 같다.
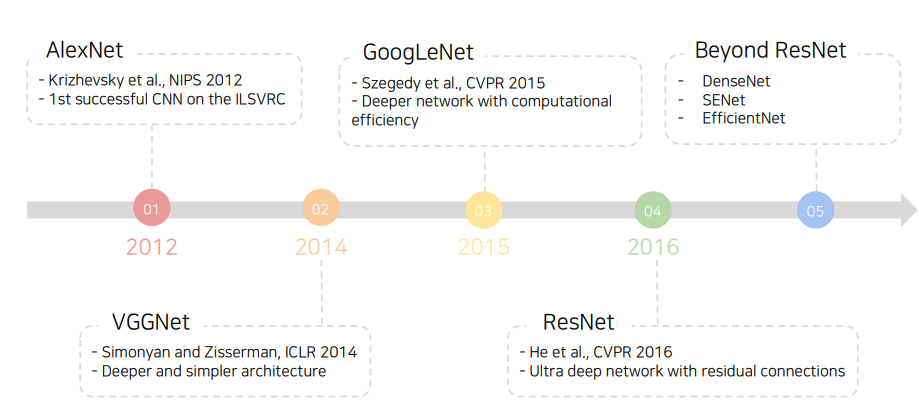
<참고>
대표적인 CNN 모델의 구조는 미리 살펴봤으므로 해당 글을 참고하도록 한다.
📄 Data Augmentation
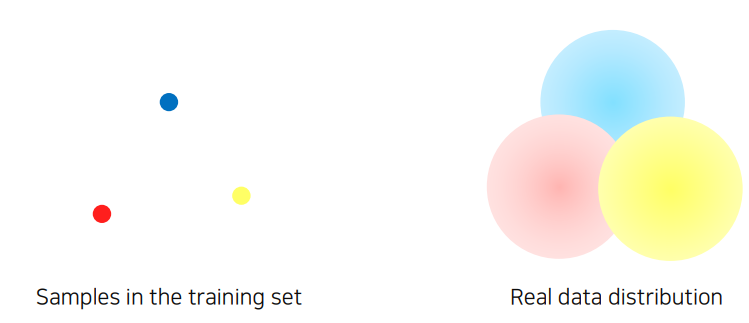
모델을 학습하는데 있어 가장 많은 부분을 차지 하고 있는 것은 데이터 이다. 하지만 현실에 있는 모든 데이터를 수집하는것은 어려움이 있으므로 적절히 샘플링된 데이터를 가지고 학습을 진행하게 되는데, 문제점은 샘플링된 데이터들이 대체적으로 편향된 데이터 라는 것이다. 이것은 편향된 데이터의 패턴을 학습하게 되고 일반적인 패턴을 못 찾아내므로, 새로운 데이터가 주어졌을때, 좋지 않은 결과를 도출한다. 이런 문제를 해결하기 위해 Data Augmentation 은 필수적이며 일반적인 기법에 대해 살펴보도록 한다.
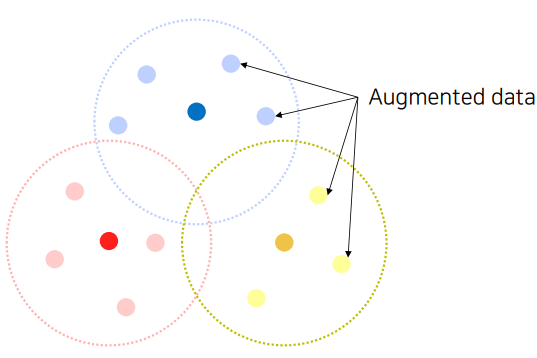
✏️ Modern Augmentation Techniques
✅ Brightness Adjustment
✅ Rotate & Flip

✅ Crop

✅ Affine Transformation
✅ CutMix
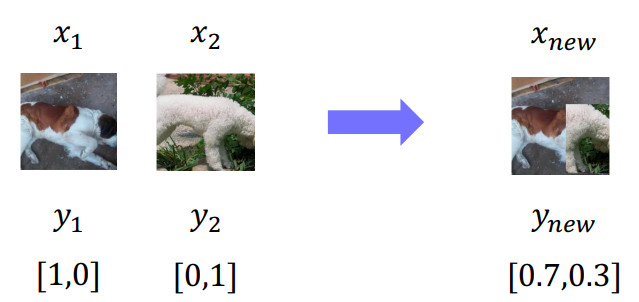
✅ RandAugment
많은 augmentation 기법이 존재하지만 최적의 기법을 찾는것은 어렵다. 또한 한번의 augmentation이 아닌 일련의 augmentation(Policy) 을 수행할 필요도 있다.

하지만 최적의 policy 을 찾는것이 어려운 문제인데, RandAugment 는 자동으로 최적의 policy를 찾아 어느정도의 강도로 적용할지 찾는 것을 목표로 한다.
📄 Leveraging Pre-trained Information
새로운 task에 대한 모델을 개발한다고 생각한다면 task에 맞는 새로운 데이터를 구성해야할 것이다. 하지만 이것은 쉬운일이 아닌데, 많은 양의 데이터를 구하는것이 어려울뿐만 아니라 구하더라도 labeling 하는 것은 쉬운일이 아니고 quality 또한 보장되지 않는다. 그래서 일반적으로 작은 데이터셋을 가지고 있을 경우 Transfer Learning 을 통해 이 문제를 해결한다.
✏️ Transfer Learning
Transfer learning 이란 한 데이터셋에서 배운 지식을 다른 데이터셋에서 활용하는 기술이다. Transfer Learning의 motivation은 "한 데이터셋에서 관찰되는 패턴들이 다른 데이터셋에서도 관찰될수 있는 공통적인 패턴들을 가지고 있지 않을까?" 라는 것이다. 다음은 Transfer Learning 의 방법을 보여준다.
✅ Transfer Knowledge from a pre-traind task to a new task
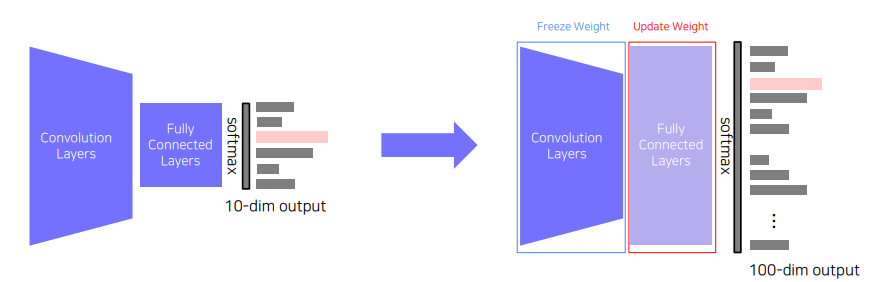
Pre-trained model에서 기존의 FC layer를 target task에 맞는 FC layer를 적용하여 pretrained model의 convolution layer 들의 가중치는 freeze 하고 FC layer의 가중치만 학습을 하는 방법이다. 따라서 학습데이터셋이 적더라도 적은 파라미터만 학습 시키기 때문에 효율적으로 학습시킬 수 있다.
✅ Fine-tuning
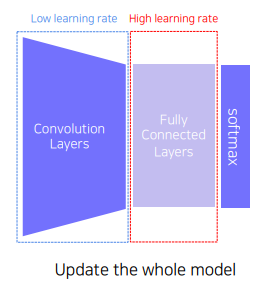
위의 방법과는 다르게 pretrained model 의 convolution layer도 같이 학습하게 하는데, convolution layer 의 learning rate 는 낮게 / target task를 위한 FC layer 는 높게 학습 하도록 하여 target task 에 빠르게 적응하도록 한다. 따라서 위의 방법보단 더 많은 파라미터를 학습시키기 때문에 조금 더 많은 데이터셋이 필요할 수 있다.
✏️ Knowledge Distillation
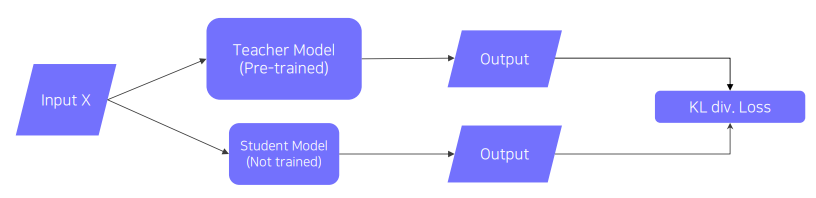
간단하지만 강력한 방법으로, pretrained model(Teacher Model) 의 학습된 지식을 더 작은 model(Student Model)로 지식을 전달하여 모델을 압축하는 방법이다. (혹자는 target task 와 전혀 다른 label을 가질수 있는데 무엇을 모방학습하는지 의문점을 가질 수 있는데, distillation 은 각 label 의 semanctic information 이 아닌 전체 분포가 추상적인 지식으로 표현되어 그 분포를 모방하도록 학습하는것이 목표이다.) 그 과정을 구체적으로 살펴보면, KL-divergence loss 를 통해 teacher model의 output distribution과 student model 의 output distribution 이 유사해지도록 학습을 한다. 이때, student model의 데이터셋이 없다면 unsupervised-learning 으로 진행되어 student model 만을 업데이트하게 된다. 만약 데이터셋이 존재한다면 다음과 같은 구조로 학습을 하게 된다.
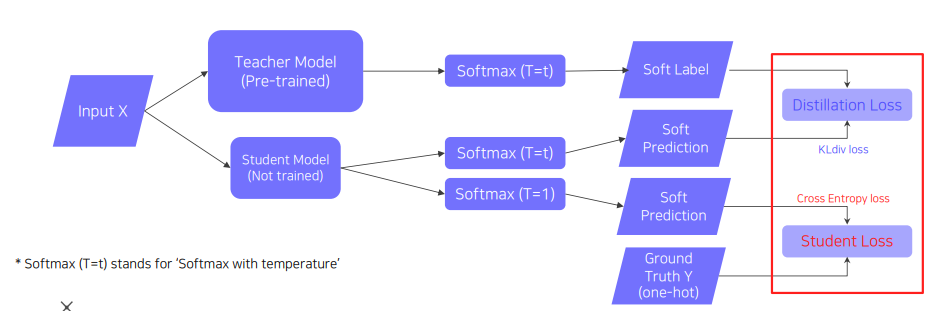
두가지의 학습 루틴을 확인할 수 있는데, distillation loss 는 teacher model 이 가지고 있는 지식을 모방 학습 / student loss 는 student model의 ground truth 를 학습한다. distillation loss 부분을 자세히 살펴보면 teacher model의 output을 hard level(one-hot vector) 이 아닌 soft label 로 표현하여 student model이 모방학습 하도록 하고있다.
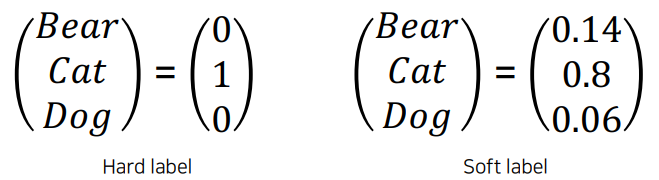
이것은 각 label의 전반적인 경향성이 knowledge를 나타낸다고 생각하여 soft label 과 soft prediction를 비교하여 학습한다.
또 한가지 주목해야 할것은 softmax(T=t) 부분인데, normal softmax(Hard Prediction)의 경우 출력의 값을 극단적으로 벌려주는 기능을 한다. 반면 softmax with temperature T(Soft Prediction)의 경우 출력의 값을 smooth 하게 만들어주는 기능 을 한다. 즉 , knowledge를 표현하는데 있어 극단적인 경향 보단 전체적으로 smooth 한 경향이 전반적인 분포를 더 파악하기 쉽게하고 더 유용한것으로 판단한다.

📄 Leveraging Unlabeled Dataset For Training
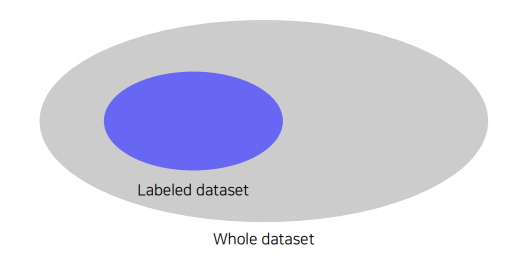
일반적으로 많은 데이터들은 unlabeled data 이며 labeled data 는 극히 일부분이다. 그렇다면 unlabeled data를 활용하여 학습할 수 있는 방법은 없을까?
✏️ Semi-supervised Learning
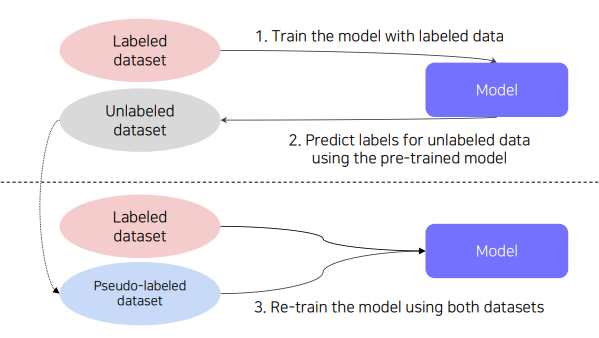
Semi-supervised Learning 이란 Unsupervised Learning + Supervised Learning 을 의미한다. 구체적으로 살펴보면, labeled data를 활용하여 학습된 pretrained model 로 unlabeled data를 예측하여 pseudo-labeled data를 생성하고 labeled data 와 pseudo-labeled data를 활용하여 pretrained model 또는 새로운 model을 재학습한다.
✏️ Self-training
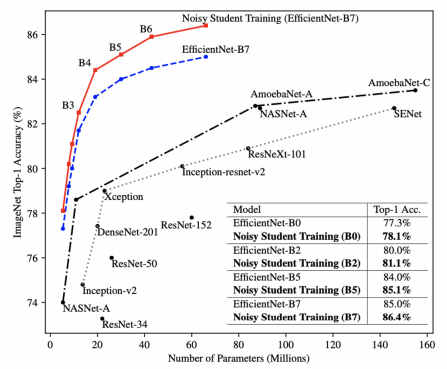
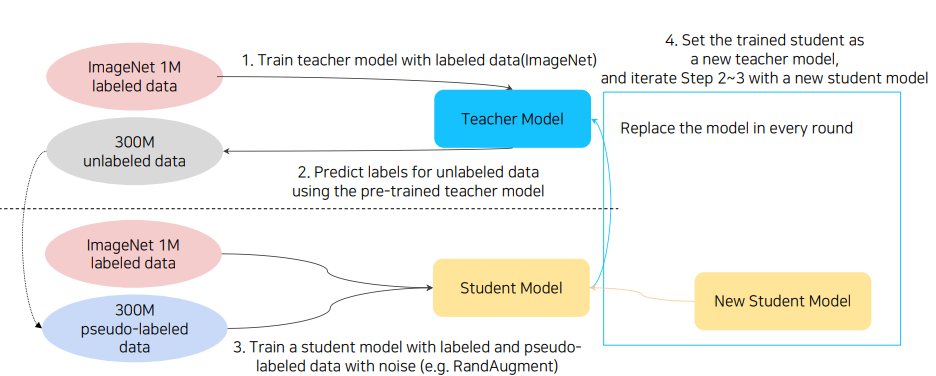
Self-training 은 Augmentation + Knowledge Distillation + Semi-supervised Learning 가 결합된 방법으로 압도적으로 성능향상을 이끌었다. 그 과정을 구체적으로 살펴보면 다음과 같다.
-
Labeled data로 teacher model 을 학습한다.
-
Teacher model로 unlabeled data를 예측하여 pseudo-labeled data를 생성한다.
-
Pseudo-labeled data 와
RandAugment를 통해 노이즈가 추가된 labeled data 를 활용하여 student model을 학습한다. 이때 모델이 학습하는 과정에선 Dropout 과 Deep Network with Stochastic Detph 방식으로 노이즈를 추가한다. -
Student model 학습이 끝난후 기존의 teacher model을 학습된 student model로 대체한후 더 큰 새로운 model를 student model로 셋팅한다.
-
위의 과정을 2~4번 반복한다.
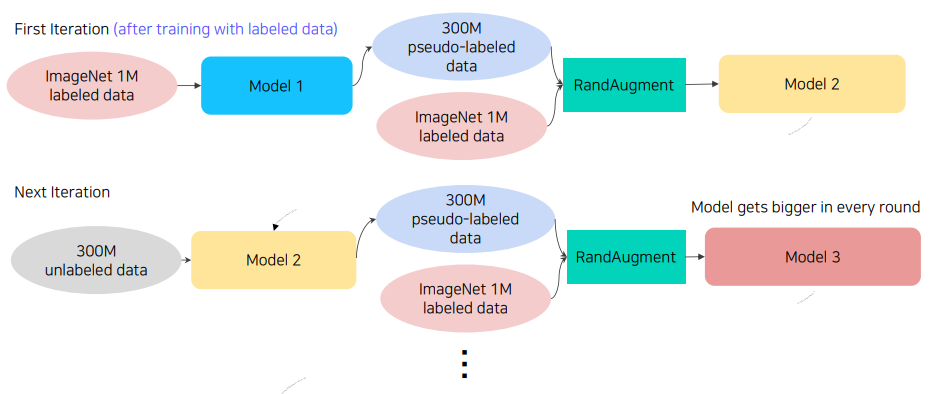
위의 싸이클을 펼쳐서 살펴보면 다음과 같다.
📚 Reference
