📌 ML With Graphs
📄 Node Embedding
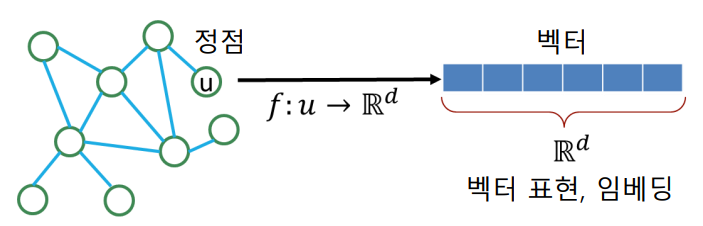
Node Embedding 이란 그래프의 정점을 벡터로 표현하는 방법 이다. Node Embedding 의 결과를 바탕으로 벡터 형태의 데이터를 위한 도구들을 그래프에도 적용할수 있게 된다. 또한 Node Classification , Community Detection 등에도 활용할수 있게 된다. 그렇다면 어떤 기준으로 정점을 벡터로 변환해야할까?
Node Embedding 의 목표는 그래프에서의 노드간 유사도를 임베딩 공간에서도 보존하도록 학습하는것이다. 따라서 어떻게 유사도를 정의할지에 대해 대표적인 접근법에 대해 살펴보도록 한다.
✏️ 인접성(Adjacency) 기반 접근법
두 정점이 인접할 때 유사하다고 간주하여 유사도를 계산한다. 즉 인접행렬(Adjacency Matrix) 의 각 원소들을 유사도로 가정한다.
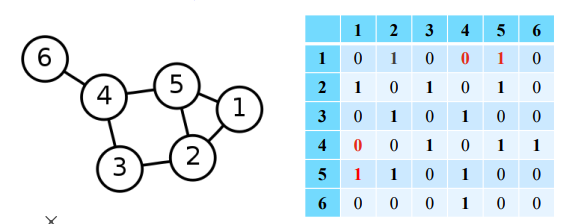
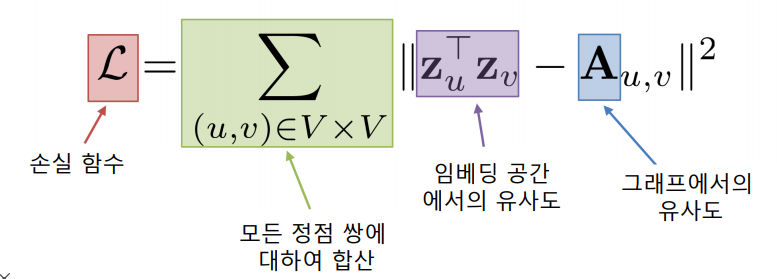
따라서, 정점 와 의 임베딩 벡터 와 에 대해 유사도 와 인접행렬의 원소 의 차이를 최소화 하는 것을 목표로 한다.
하지만 인접성만을 고려할 경우 다음과 같은 한계가 있는데,
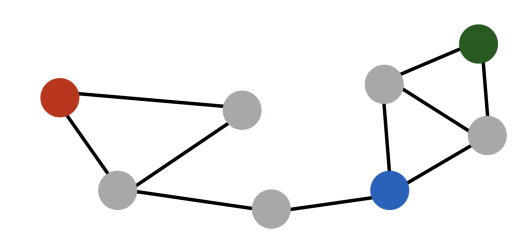
빨간색 노드와 파란색 노드는 거리가 3 인 반면 초록색 노드와 파란색 노드는 거리가 2 임에도 불구하고 두 경우의 유사도는 0 으로 같다. 또한 군집 관점에서 바라볼때 다른 군집에 속함에도 불구하고 유사도가 같다.
✏️ 거리 / 경로 / 중첩 기반 접근법
✅ 거리 기반 접근법
두 정점 사이의 거리가 충분히 가까운 경우 유사하다고 간주하여 유사도를 계산한다. 가령, "충분히" 의 기준을 2 라고 가정한다면 빨간색 노드는 초록색,파란색 노드들과 유사하며 유사도 1 을 가진다. 반면 보라색 노드와는 유사하지 않으며 유사도 0 을 가진다.
| - | 빨간색 | 초록색 | 파란색 | 보라색 |
|---|---|---|---|---|
| 빨간색 | 1 | 1 | 1 | 0 |
| 초록색 | 1 | 1 | 1 | 1 |
| 파란색 | 1 | 1 | 1 | 1 |
| 보라색 | 0 | 1 | 1 | 1 |
✅ 경로 기반 접근법
두 정점 사이의 경로(Path)가 많을수록 유사하다고 간주하여 유사도를 계산한다. 이때, 두 정점 와 사이의 경로 중 거리가 k인것의 수는 인접행렬 의 k 거듭제곱 로 생각할 수 있다.
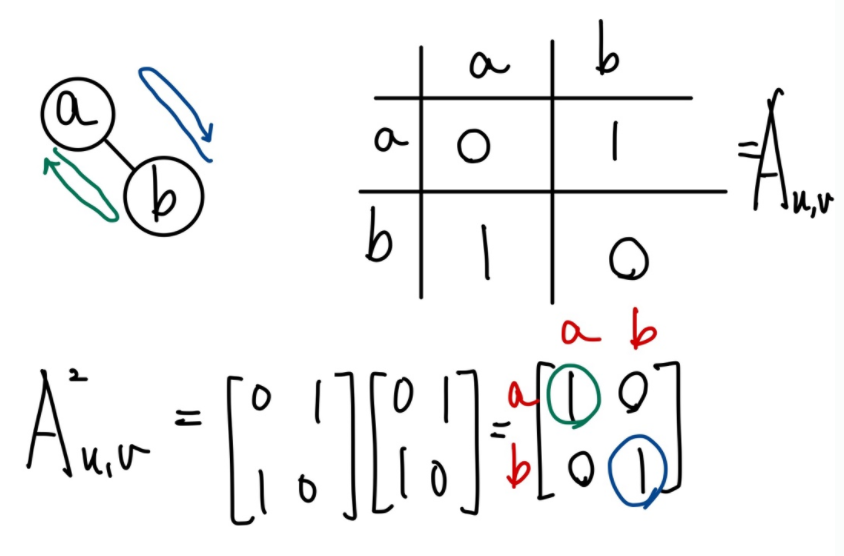
따라서 임베딩 벡터 유사도 와 경로 중 거리가 k 인 와의 차이를 최소화하는것을 목표로 한다
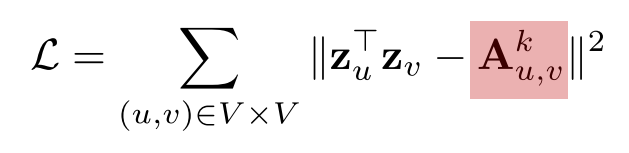
하지만 문제점은 위의 예시를 통해서도 알수 있듯이 경로 거리가 k 보다 짧은 경로가 반영이 되지 않는 것이다.
✅ 중첩 기반 접근법
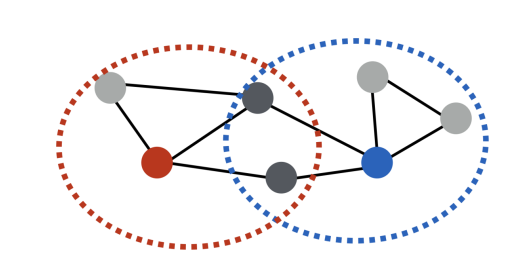
두 정점이 많은 이웃을 공유 할수록 유사하다고 간주하여 유사도를 계산한다.가령 위의 그림에서 빨간색 노드는 파란색 노드와 두명의 이웃을 공유하기 때문에 유사도는 2가 된다. 만약 정점 의 이웃집합 , 정점 의 이웃집합을 라고 정의한다면, 두 정점의 공통 이웃 수 는 다음과 같이 정의 될 수 있다.
따라서 임베딩 벡터 유사도 와 두 정점의 공통 이웃수 와의 차이를 최소화하는것을 목표로 한다
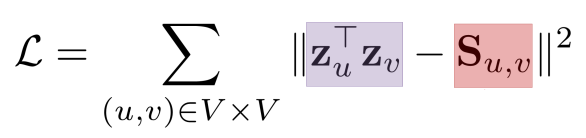
더 나아가 공통 이웃수 대신 자카드 유사도 또는 Adamic Adar 점수 를 사용할수도 있다.
-
자카드 유사도 : 공통 이웃수 대신 공통 이웃수의 비율을 계산한다.
-
Adamic Adar 점수 : 공통 이웃 각각에 가중치를 부여하여 가중합을 계산한다.
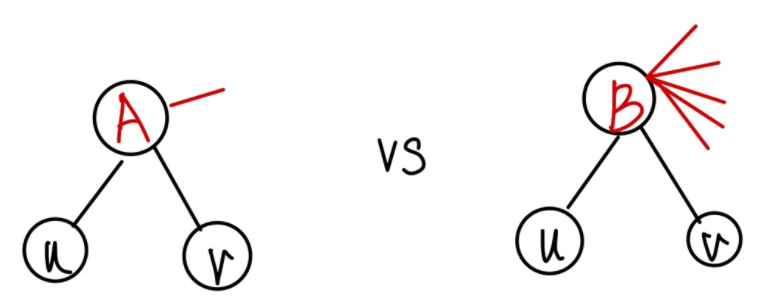
만약 와 가 공통이웃으로 를 가진다면, 는 degree가 높기때문에 즉 다른 노드와도 연결이 많이 되어 있으므로 특별히 , 와 가깝다고 말할수 없을 것이다. 하지만 만약 를 공통 이웃으로 연결되어있다면, 는 다른 노드와의 연결이 많지 않기때문에 가깝다고 말할 수 있을 것이다.
✏️ 임의보행(Random Walk) 기반 접근법
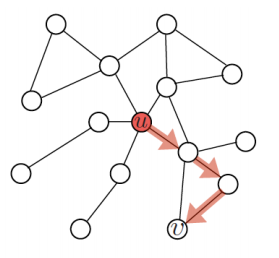
한 정점 에서 시작하여 임의보행을 통해 다른 정점 에 도착할 확률을 유사도로 계산한다. 임의보행의 경우 위에서 살펴본 접근법들과는 다르게 거리를 제한하지 않기 때문에 시작정점 주변의 지역적 정보 뿐만 아니라 그래프 전역정보 까지 모두 고려할 수 있는 장점이 있다. 임의보행 기반 접근법은 다음과 같이 세 단계를 거친다.
-
각 정점에서 시작하여 임의보행을 반복수행한다.
-
각 정점에서 시작한 임의보행 중 도달한 정점들의 리스트를 구성한다. 만약 정점 에서 시작한 임의보행 중 도달한 정점들의 리스트를 라고 한다면, 한 정점을 여러번 도달한 경우, 해당 정점은 에 여러번 포함될 수 있다.
-
손실함수를 최소화 하도록 학습한다.
✅ 손실함수
우리의 목적은 각각의 정점 를 시작정점으로 하여 random walk 로 생성된 를 관찰할 가능성이 가장 큰 임베딩 벡터 을 찾는 것이다.
따라서 likelihood를 최대화 하는것은 손실함수를 최소화하는 과정으로 생각할 수 있으며 다음과 같이 표현된다.
이때, 정점 에서 시작한 random walk 가 정점 에 도달할 확률 는 softmax 를 통해 다음과 같이 정의할 수 있다.
그러므로 손실함수는 다음과 같이 표현할 수 있다.
하지만 이것의 문제점은 손실함수 계산을 함에 있어 정점의 수의 제곱에 비례하는 시간이 소요된다는 것이다.
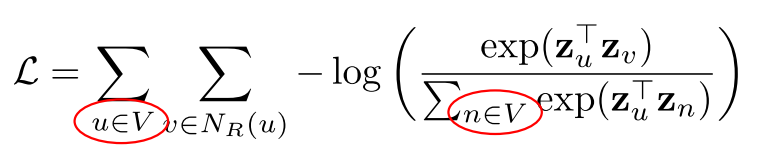
그래서 일반적으로 다음과 같이 negative sampling 을 통해 근사적으로 계산한다.
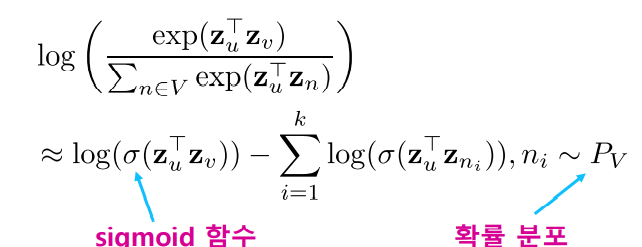
즉 softmax 에서 모든 정점에 대해 고려하는 것이 아닌 sampling 된 개의 정점을 비교하여 와 가 유사할 확률은 높으면서 negative sampling된 node들과 유사할 확률은 낮도록 학습한다.
✅ DeepWalk vs Node2Vec
임의 보행 기반 접근법 중 DeepWalk 와 Node2Vec 방식에 대해 살펴보면 공통적인 핵심 아이디어는 Word2Vec(Skip-gram)이다. Word2Vec(Skip-gram) 에서는 주어진 corpus 에서 중심단어를 기준으로 window size 만큼 주변 단어와 비슷한 유사도를 가지도록 임베딩한다. 그렇다면 node embedding 에서는 corpus가 없는데 어떻게 생성할까?
바로 random walk 기반 으로 생성된 path 가 Word2Vec(Skip-gram)의 corpus 역할을 한다. 즉 임의의 정점 에서 까지 random walk 로 도달한 path를 corpus로 생각하여 Skip-gram 방식으로 path 상에 가까이에 있는 노드들끼리 유사하도록 학습시킨다.
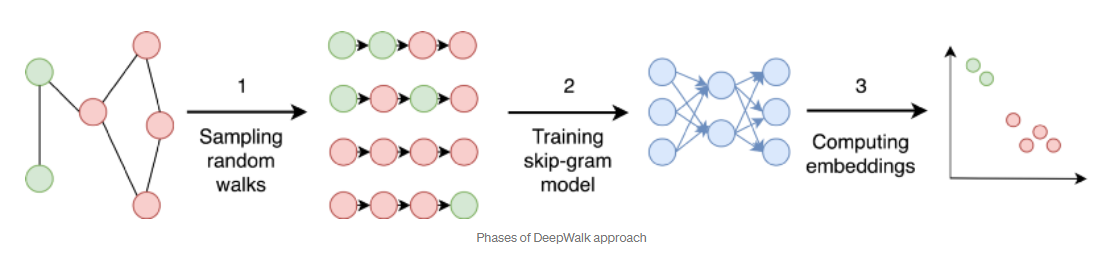
이때 random walk를 정의하는 방식의 차이는 다음과 같다.
-
DeepWalk : 기본적인 임의 보행 방법으로 현재 정점의 이웃 중 하나를 균일한 확률로 선택하여 이동한다. 하지만 random walk 를 임의로 만들기 때문에 각각의 random walk에서 앞뒤를 잘 파악했더라도 원래 그래프로 돌아왔을 때 노드의 주변 이웃을 잘 파악하지 못할 수 있다는 단점이 있다.
-
Node2Vec : Second-order Biased Random Walk 로 현재 정점과 직전에 머물렀던 정점을 모두 고려하여 다음 정점을 선택한다. 이때
DeepWalk의 단점을 보완하기 위해 직전 정점의 거리를 기준으로 경우를 구분하여 local structure / global structure 중에서 무엇을 더 중요하게 인식할지에 따라 차등적인 확률을 부여한다.
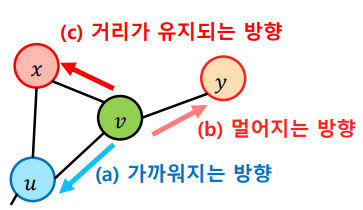
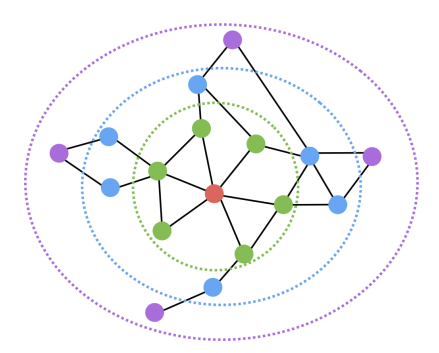
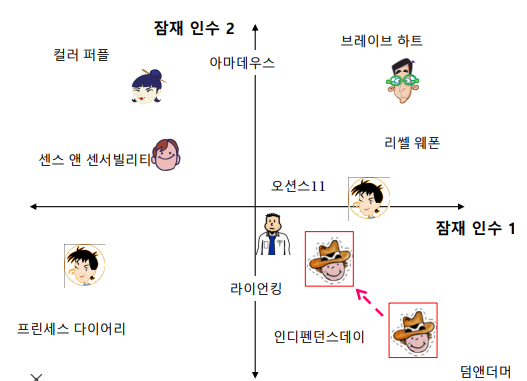
를 현재 정점, 를 직전에 머물렀던 정점이라고 가정한다면, 로 이동하는 경우 거리가 유지되는 방향 / 로 이동하는 경우 거리가 멀어지는 방향 / 로 이동하는 경우 가까워지는 방향임을 알 수 있다. 이렇게 직전 정점의 거리를 기준으로 차등적인 확률을 부여하는데 부여하는 확률에 따라 다른 종류의 임베딩을 얻을 수 있다.
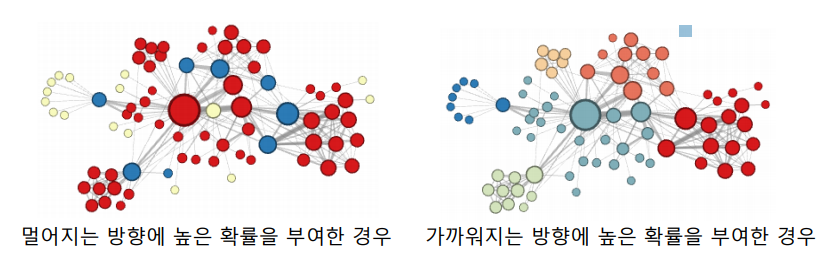
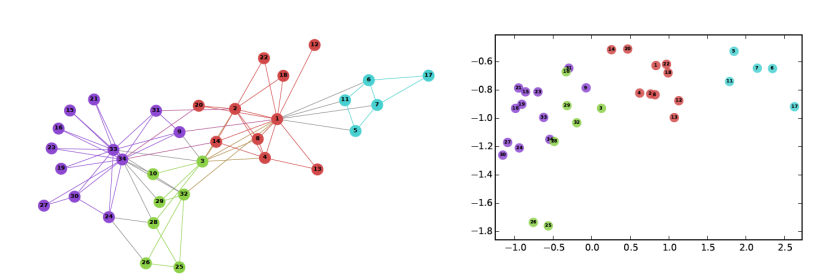
위의 그림은Node2Vec으로 임베딩을 수행한뒤K-means군집분석을 수행한 결과이다. 그림에서 알수 있듯이 만약 멀어지는 방향에 높을 확률을 부여한다면, 정점의 역할(다리역할,변두리 정점)이 같은 경우에 임베딩이 유사 한것을 확인할 수 있다. 반면 가까워지는 방향에 높은 확률을 부여한다면 같은 군집에 속한 경우 임베딩이 유사 한것을 확인할 수 있다.
✏️ Transductive Node Embedding
변환식(Transductive) 방법은 학습의 결과로 정점의 임베딩 자체 를 얻는 것을 의미한다. 이 전에 Word2Vec 을 살펴보았지만 이 역시 변환식 방법을 따르고 있음을 알 수 있다.
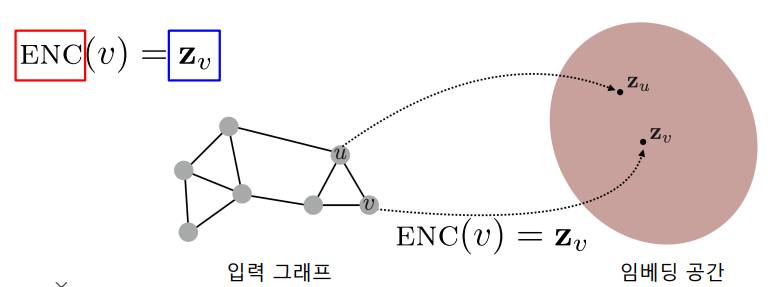
위의 그림을 바탕으로 살펴보면, 변환식 방법은 정점을 임베딩으로 변환시키는 ENC(Encoder)를 얻는것이 아닌 정점의 임베딩 자체 를 얻는다.(이때, 정점을 임베딩으로 변환 시키는 ENC(Encoder)를 얻는것을 귀납식(Inductive) 방법 이라 한다.) 따라서 다음과 같은 한계점을 가질수 밖에 없다.
-
학습이 진행된 이후에 추가된 정점에 대해서는 임베딩을 얻을 수 없다.
-
모든 정점에 대한 임베딩을 미리 계산하여 저장해두어야 한다.
-
정점이 속성(Attribute)(성별,지역등) 정보를 가진 경우에 이를 활용할 수 없다.
📄 Recommender System
✏️ Latent Factor Model
잠재 인수 모형(Latent Factor Model)(혹은 SVD, UV decomposition) 의 핵심은 고정된 인수가 아닌 잠재 인수들을 사용해 user 와 item 을 벡터로 표현하는 것에 있다.
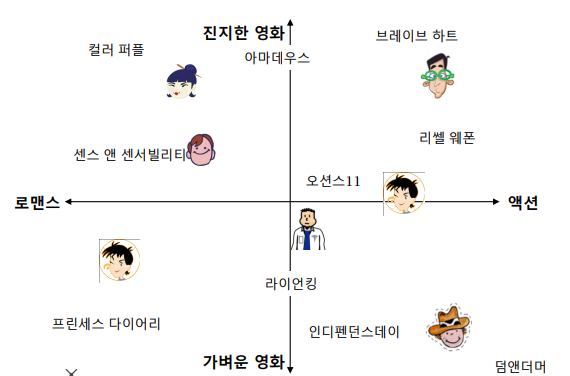
위의 예시를 보면 고정된 인수(액션,로맨스,진지한 영화,가벼운 영화 등)를 바탕으로 user 와 item을 임베딩하고 있다. 하지만 잠재 인수 모형 에서는 user 와 item을 잠재 인수들로 표현할 수 있다고 생각하여 잠재 인수들을 "효과적으로 학습"하여 임베딩 한다.

여기서 "효과적으로 학습" 하여 임베딩 한다는 것은 user와 item의 임베딩 내적이 평점과 최대한 유사하도록 하는것을 의미한다. 만약 user 의 임베딩을 , item 의 임베딩을 , user 의 item 에 대한 평점을 라고 한다면 와 를 유사하도록 하는것을 의미한다.
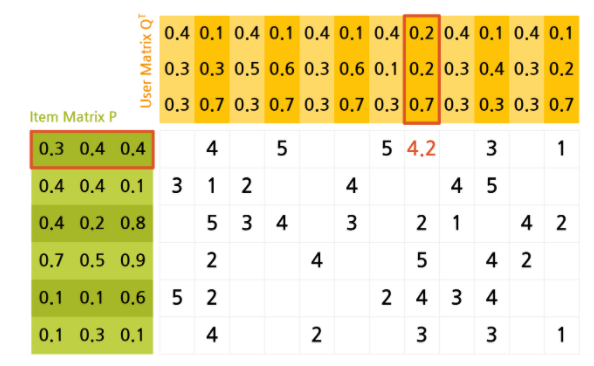
즉 잠재 인수 모형 은 다음 손실함수를 최소화 하는 와 를 찾는것을 목표로 한다.
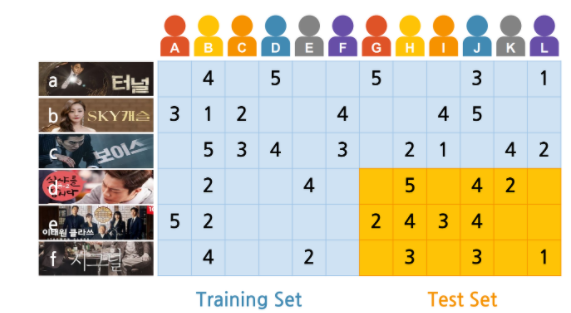
이때 rating matrix 은 훈련 데이터에 있는 평점에 대해서만 계산한다. 하지만 위 손실 함수를 사용할 경우 overfitting 이 발생할 수 있어 다음과 같이 손실함수를 디자인한다.
즉, 이 전에 살펴 본 regularization 방법들에서 L2-norm regularization 을 적용하여 outlier의 영향을 줄이고 generalization performance를 높이는 방향으로 학습한다.
✏️ 편향을 고려한 Latent Factor Model
단어의 의미에서 알 수 있듯이 편향 이란 한쪽으로 치우치는 정도를 의미한다. 가령 어떤 사용자는 깐깐하여 평점을 낮게 줄수도 있고, 혹은 평점을 후하게 줄 수도 있다. 또한 어떤 상품은 전체 상품 평점 평균에 비해 좋은 평가 를 받을수도 나쁜평가 를 받을수도 있다. 따라서 다음과 같은 편향을 고려하여 모델링하는 것이 성능 개선에 도움이 될 수도 있다.
-
사용자의 편향() : 해당 사용자가 매긴 평점들의 평균 과 전체 상품들의 평점평균의 차이
가령, 전체 평점 평균()이 이고 A가 매긴 평점의 평균이 , B가 매긴 평점의 평균이 라면 A의 사용자 편향은 / B의 사용자 편향은 이다. 즉 A는 후하게 /B는 깐깐하게 평점을 주는 것으로 생각할 수 있다. -
상품의 편향() : 해당 상품이 받은 평점들의 평균과 전체 상품들의 평점평균의 차이
가령, 전체 평점 평균()이 이고 item A에 대한 평점의 평균이 , item B에 대한 평점의 평균이 라면 item A의 상품 편향은 / item B의 상품 편향은 이다. 즉 item A는 전체상품 평점 평균에 비해 좋은 평가를 /B는 나쁜 평가 를 받는 것으로 생각 할 수 있다.
그렇다면 사용자 와 상품의 정보 뿐만 아니라 편향까지 고려한 손실함수를 다음과 같이 정의할 수 있을 것이다.
✏️ 시간적 편향을 고려한 Latent Factor Model
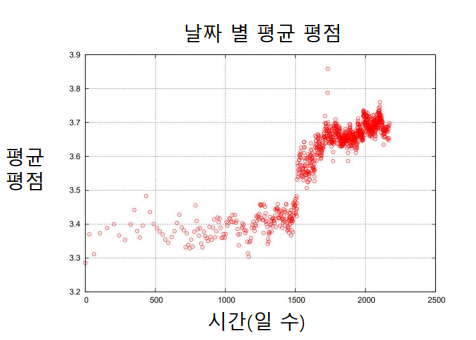
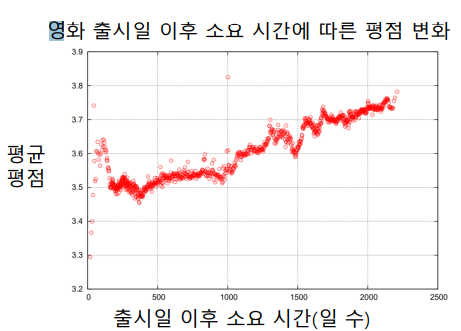
위와 같이 평점은 시간에 영향을 받을 수도 있다. 즉 사용자 편향과 상품 편향을 시간에 따른 함수로 가정하여 모델링 할 수 있다.
📚 Reference
