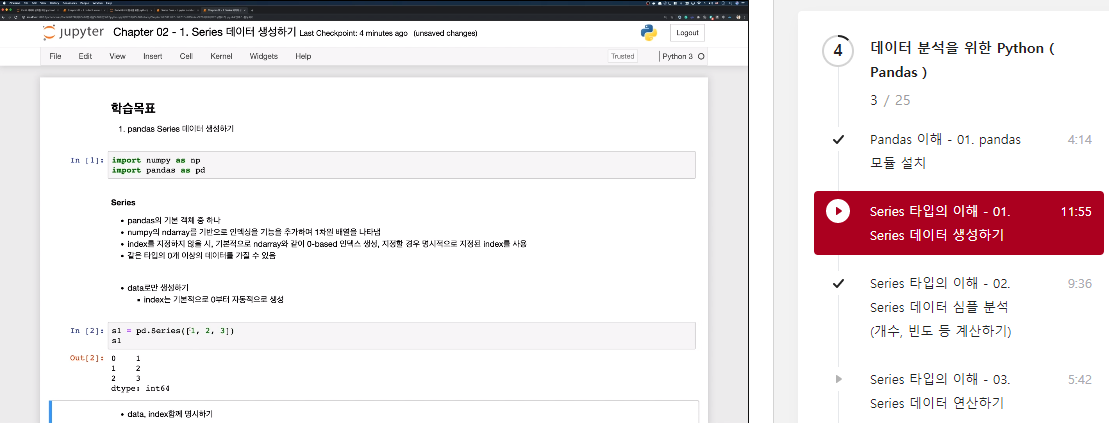
series 데이터 생성하기
series
- pandas의 기본 객체 중 하나
- numpy의 ndarray를 기반으로 인덱싱을 기능을 추가하여 1차원 배열을 나타냄
- index를 지정하지 않을 시, 기본적으로 ndarray와 같이 0-based 인덱스 생성, 지정할 경우 명시적으로 지정된 index를 사용
- 같은 타입의 0개 이상의 데이터를 가질 수 있음
data로만 생성하기
- index는 기본적으로 0부터 자동적으로 생성
import numpy as np
import pandas as pd
s1 = pd.Series([1, 2, 3])
s1
>>> 0 1
1 2
2 3
dtype: int64s2 = pd.Series(['a', 'b', 'c'])
s2
>>> 0 a
1 b
2 c
dtype: objects3 = pd.Series(np.arange(200))
s3
>>> 0 0
1 1
2 2
3 3
4 4
...
195 195
196 196
197 197
198 198
199 199
Length: 200, dtype: int32data, index함께 명시하기
s4 = pd.Series([1, 2, 3], [100, 200, 300])
s4
>>> 100 1
200 2
300 3
dtype: int64s5 = pd.Series([1, 2, 3], ['a', 'm', 'k'])
s5
>>> a 1
m 2
k 3
dtype: int64data, index, data type 함께 명시하기
s6 = pd.Series(np.arange(5), np.arange(100, 105), dtype=np.int16)
s6
>>> 100 0
101 1
102 2
103 3
104 4
dtype: int16인덱스 활용하기
s6.index
>>> Int64Index([100, 101, 102, 103, 104], dtype='int64')s6.values
>>> array([0, 1, 2, 3, 4], dtype=int16)- 인덱스를 통한 데이터 접근
s6[104]
>>> 4- 인덱스를 통한 데이터 업데이트
s6[104] = 70
s6
>>> 100 0
101 1
102 2
103 3
104 70
dtype: int16s6[105] = 90
s6[200] = 80
s6
>>> 100 0
101 1
102 2
103 3
104 70
105 90
200 80
dtype: int64- 인덱스 재사용하기
s7 = pd.Series(np.arange(7), s6.index)
s7
>>> 100 0
101 1
102 2
103 3
104 4
105 5
200 6
dtype: int32Series 데이터 심플 분석
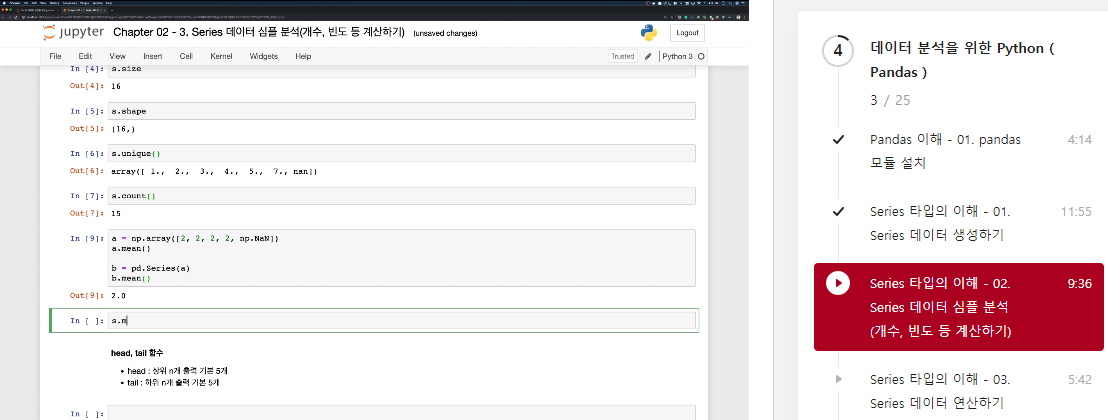
Series size, shape, unique, count, value_counts 함수
- size : 개수 반환
- shape : 튜플형태로 shape반환
- unique : 유일한 값만 ndarray로 반환
- count : NaN을 제외한 개수를 반환
- mean : NaN을 제외한 평균
- value_counts : NaN을 제외하고 각 값들의 빈도를 반환
s = pd.Series([1, 1, 2, 1, 2, 2, 2, 1, 1, 3, 3, 4, 5, 5, 7, np.NaN])
s
>>> 0 1.0
1 1.0
2 2.0
3 1.0
4 2.0
5 2.0
6 2.0
7 1.0
8 1.0
9 3.0
10 3.0
11 4.0
12 5.0
13 5.0
14 7.0
15 NaN
dtype: float64len(s)
>>> 16s.size
>>> 16s.shape
>>> (16,)s.unique()
>>> array([ 1., 2., 3., 4., 5., 7., nan])s.count()
>>> 15a = np.array([2, 2, 2, 2, np.NaN])
a.mean()
>>> nanb = pd.Series(a)
b.mean()
>>> 2.0s.mean()
>>> 2.6666666666666665s.value_counts()
>>> 1.0 5
2.0 4
5.0 2
3.0 2
7.0 1
4.0 1
dtype: int64index를 활용하여 멀티플한 값에 접근
s[[5, 7, 8, 10]].value_counts()
>>> 1.0 2
3.0 1
2.0 1
dtype: int64head, tail 함수
- head : 상위 n개 출력 기본 5개
- tail : 하위 n개 출력 기본 5개
s.head(n=7)
>>> 0 1.0
1 1.0
2 2.0
3 1.0
4 2.0
5 2.0
6 2.0
dtype: float64s.tail()
>>> 11 4.0
12 5.0
13 5.0
14 7.0
15 NaN
dtype: float64머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
