series 데이터 연산하기
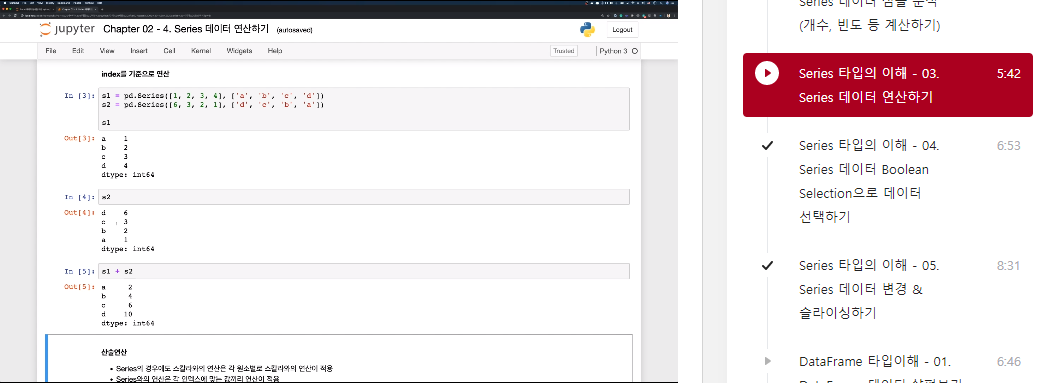
index를 기준으로 연산
import numpy as np
import pandas as pd
s1 = pd.Series([1, 2, 3, 4], ['a', 'b', 'c', 'd'])
s2 = pd.Series([6, 3, 2, 1], ['d', 'c', 'b', 'a'])s1
>>> a 1
b 2
c 3
d 4
dtype: int64s2
>>> d 6
c 3
b 2
a 1
dtype: int64s1 + s2
>>> a 2
b 4
c 6
d 10
dtype: int64산술연산
- Series의 경우에도 스칼라와의 연산은 각 원소별로 스칼라와의 연산이 적용
- Series와의 연산은 각 인덱스에 맞는 값끼리 연산이 적용
- 이때, 인덱스의 pair가 맞지 않으면, 결과는 NaN
s1 ** 2
>>> a 1
b 4
c 9
d 16
dtype: int64s1 ** s2
>>> a 1
b 4
c 27
d 4096
dtype: int64index pair가 맞지 않는 경우
- 해당 index에 대해선 NaN 값 생성
s1['k'] = 7
s2['e'] = 9s1
>>> a 1
b 2
c 3
d 4
k 7
dtype: int64s2
>>> d 6
c 3
b 2
a 1
e 9
dtype: int64s1 + s2
>>> a 2.0
b 4.0
c 6.0
d 10.0
e NaN
k NaN
dtype: float64Series 데이터 Boolean Selection으로 데이터 선택하기
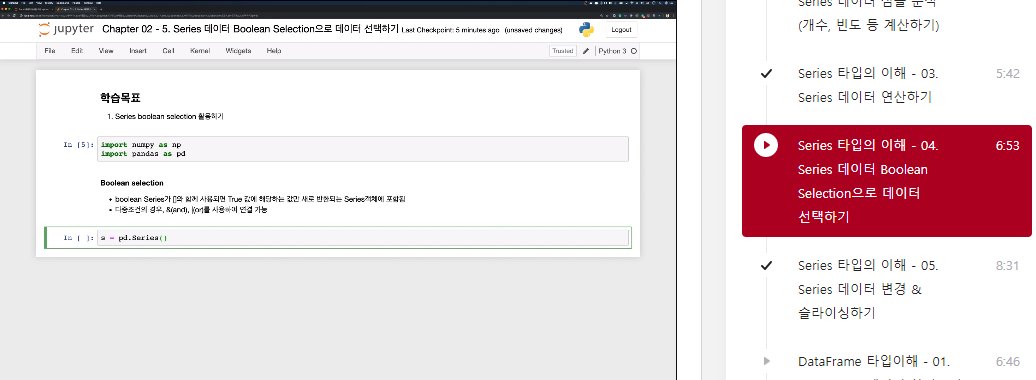
boolean selection
- boolean Series가 []와 함께 사용되면 True 값에 해당하는 값만 새로 반환되는 Series객체에 포함됨
- 다중조건의 경우, &(and), |(or)를 사용하여 연결 가능
s = pd.Series(np.arange(10), np.arange(10)+1)
s
>>> 1 0
2 1
3 2
4 3
5 4
6 5
7 6
8 7
9 8
10 9
dtype: int32s > 5
>>> 1 False
2 False
3 False
4 False
5 False
6 False
7 True
8 True
9 True
10 True
dtype: bools[s>5]
>>> 7 6
8 7
9 8
10 9
dtype: int32s[s % 2 == 0]
>>> 1 0
3 2
5 4
7 6
9 8
dtype: int32s.index > 5
>>> array([False, False, False, False, False, True, True, True, True,
True])s[s.index > 5]
>>> 6 5
7 6
8 7
9 8
10 9
dtype: int32s[(s > 5) & (s < 8)]
>>> 7 6
8 7
dtype: int32(s >= 7).sum()
>>> 3(s[s>=7]).sum()
>>> 24Series 데이터 변경, 슬라이싱하기
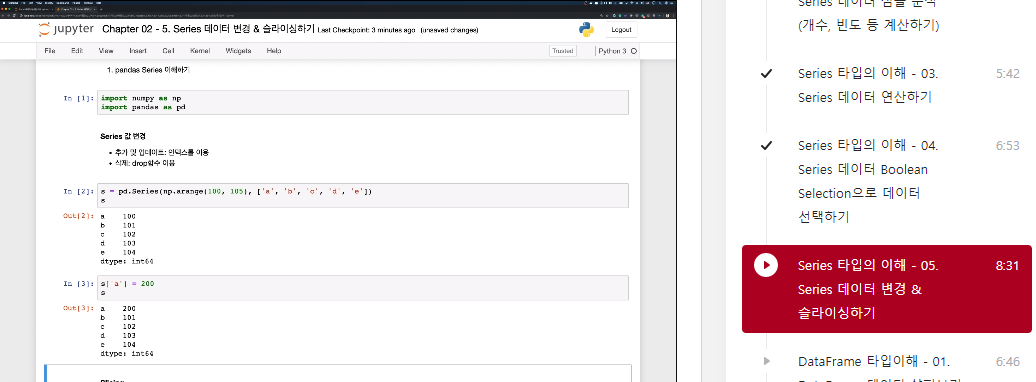
series 값 변경
- 추가 및 업데이트: 인덱스를 이용
- 삭제: drop함수 이용
s = pd.Series(np.arange(100, 105), ['a', 'b', 'c', 'd', 'e'])
s
>>> a 100
b 101
c 102
d 103
e 104
dtype: int32s['a'] = 200
s
>>> a 200
b 101
c 102
d 103
e 104
dtype: int32s['k'] = 300
s
>>> a 200
b 101
c 102
d 103
e 104
k 300
dtype: int64s.drop('k')
>>> a 200
b 101
c 102
d 103
e 104
dtype: int64s
>>> a 200
b 101
c 102
d 103
e 104
k 300
dtype: int64s.drop('k', inplace=True)
s
>>> a 200
b 101
c 102
d 103
e 104
dtype: int64s[['a', 'b']] = [300, 900]
s
>>> a 300
b 900
c 102
d 103
e 104
dtype: int64slicing
- 리스트, ndarray와 동일하게 적용리스트, ndarray와 동일하게 적용
s1 = pd.Series(np.arange(100, 105))
s1
>>> 0 100
1 101
2 102
3 103
4 104
dtype: int32s1[1:3]
>>> 1 101
2 102
dtype: int32s2 = pd.Series(np.arange(100, 105), ['a', 'c', 'b', 'd', 'e'])
s2
>>> a 100
c 101
b 102
d 103
e 104
dtype: int32s2[1:3]
>>> c 101
b 102
dtype: int32s2['c':'d']
>>> c 101
b 102
d 103
dtype: int32머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
