DataFrame 데이터 살펴보기
DataFrame
- Series가 1차원이라면 DataFrame은 2차원으로 확대된 버전
- 2차원이기 때문에 인덱스가 row, column으로 구성됨
- Data Analysis, Machine Learning에서 data 변형을 위해 가장 많이 사용
import pandas as pd
# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
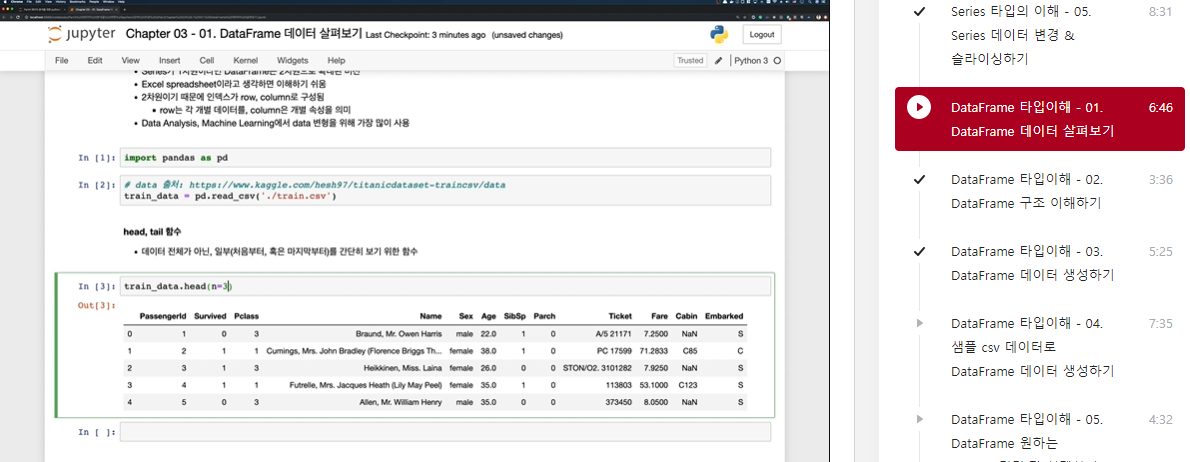
train_data = pd.read_csv('../train.csv')head, tail 함수
- 데이터 전체가 아닌, 일부(처음부터, 혹은 마지막부터)를 간단히 보기 위한 함수
train_data.head(n=3)
train_data.tail(n=3)
dataframe 데이터 파악하기
- shape 속성 (row, column)
- describe 함수 - 숫자형 데이터의 통계치 계산
- info 함수 - 데이터 타입, 각 아이템의 개수 등 출력
train_data.shape
>>> (891, 12)train_data.describe()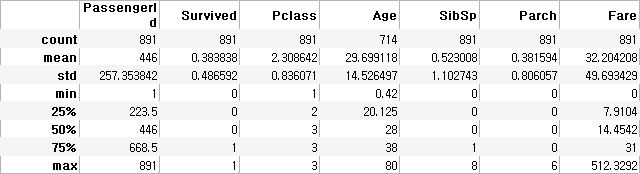
train_data.info()
>>> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KBDataFrame 구조 이해하기
import pandas as pd
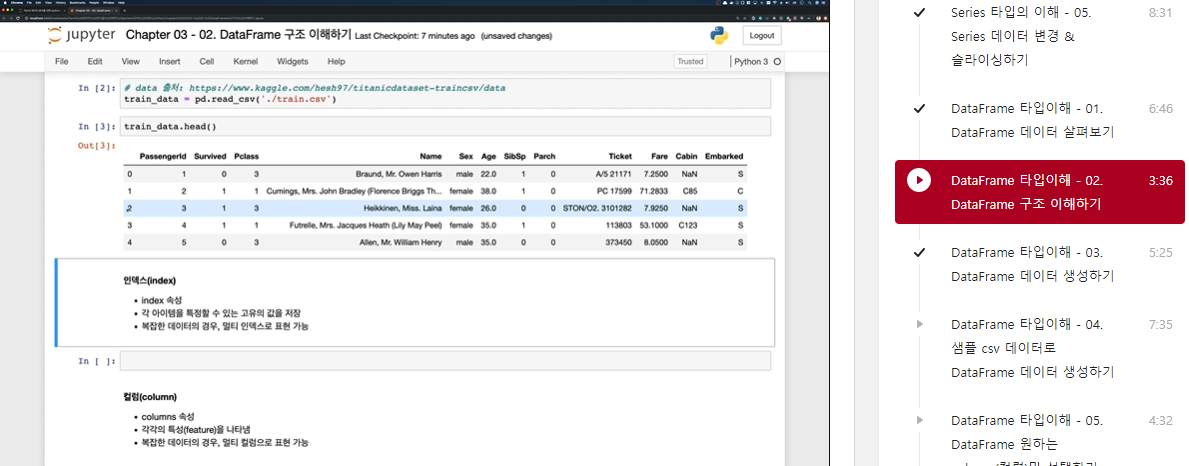
# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
train_data = pd.read_csv('../train.csv')인덱스(index)
- index 속성
- 각 아이템을 특정할 수 있는 고유의 값을 저장
- 복잡한 데이터의 경우, 멀티 인덱스로 표현 가능
train_data.index
>>> RangeIndex(start=0, stop=891, step=1)컬럼(column)
- columns 속성
- 각각의 특성(feature)을 나타냄
- 복잡한 데이터의 경우, 멀티 컬럼으로 표현 가능
train_data.colums
>>> Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')DataFrame 생성하기
- 일반적으로 분석을 위한 데이터는 다른 데이터 소스(database, 외부파일)을 통해 dataframe을 생성
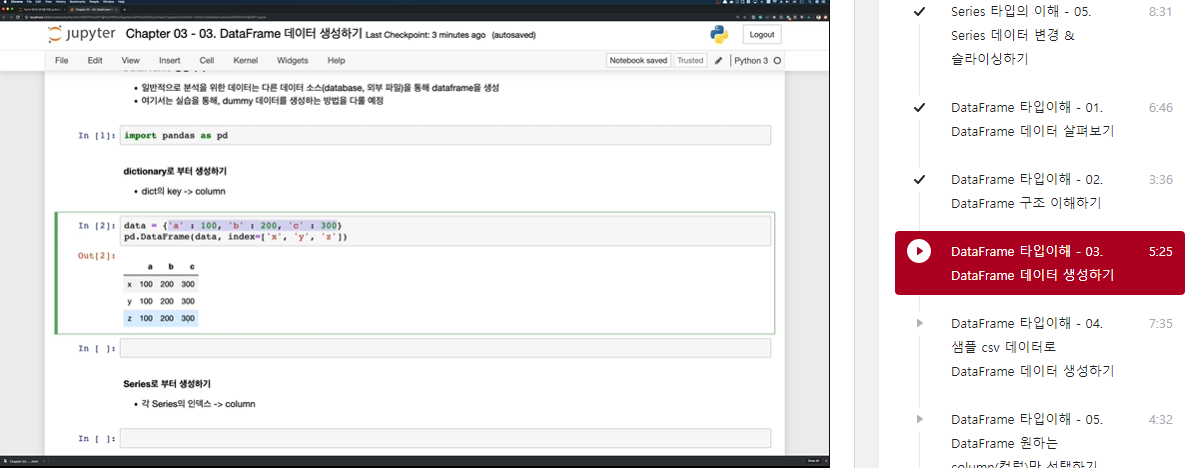
import pandas as pddictionary로 부터 생성하기
- dict의 key → column
data = {'a' : 100, 'b' : 200, 'c' : 300}
pd.DataFrame(data, index=['x', 'y', 'z']
data = {'a' : [1, 2, 3], 'b' : [4, 5, 6], 'c' : [10, 11, 12]}
pd.DataFrame(data, index=[0, 1, 2])
Series로 부터 생성하기
- 각 Series의 인덱스 → column
a = pd.Series([100, 200, 300], ['a', 'b', 'd'])
b = pd.Series([101, 201, 301], ['a', 'b', 'k'])
c = pd.Series([110, 210, 310], ['a', 'b', 'c'])
pd.DataFrame([a, b, c], index=[100, 101, 102])
머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
