csv 데이터로 DataFrame 데이터 생성하기
csv 데이터로 부터 DataFrame 생성
- 데이터 분석을 위해, dataframe을 생성하는 가장 일반적인 방법
- 데이터 소스로부터 추출된 csv(comma separated values) 파일로부터 생성
- pandas.read_csv 함수 사용
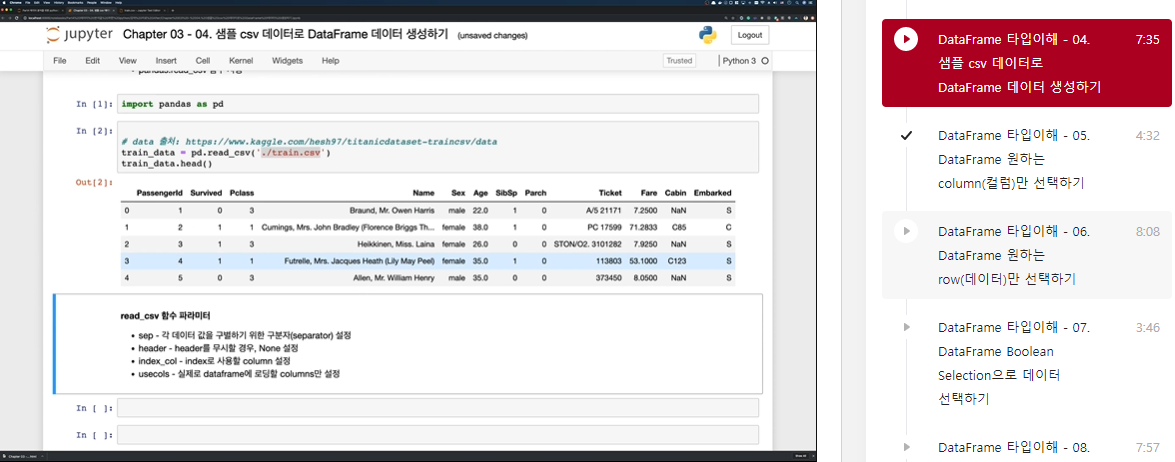
import pandas as pd
# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
train_data = pd.read_csv('../train.csv')
train_data.head()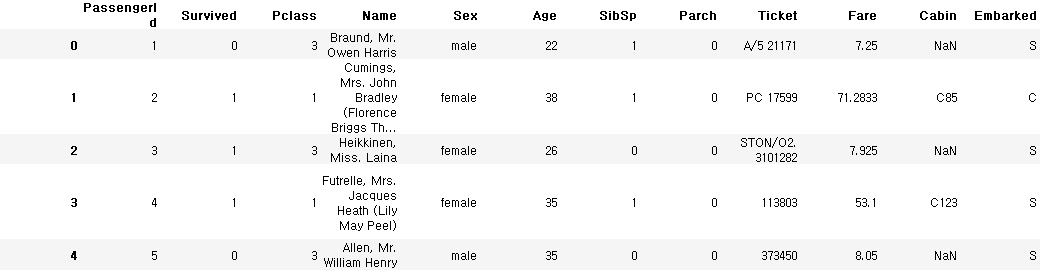
read_csv 함수 파라미터
- sep - 각 데이터 값을 구별하기 위한 구분자(separator) 설정
- header - header를 무시할 경우, None 설정
- index_col - index로 사용할 column 설정
- usecols - 실제로 dataframe에 로딩할 columns만 설정
train_data = pd.read_csv('../train.csv', index_col='PassengerId', usecols=['PassengerId', 'Survived', 'Pclass', 'Name'])
train_data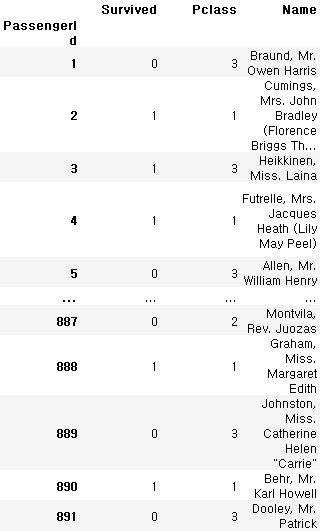
train_data.columns
>>> Index(['Survived', 'Pclass', 'Name'], dtype='object')DataFrame에서 원하는 column만 선택하기
column 선택하기
- 기본적으로 []는 column을 추출
- 컬럼 인덱스일 경우 인덱스의 리스트 사용 가능
- 리스트를 전달할 경우 결과는 Dataframe
- 하나의 컬럼명을 전달할 경우 결과는 Series
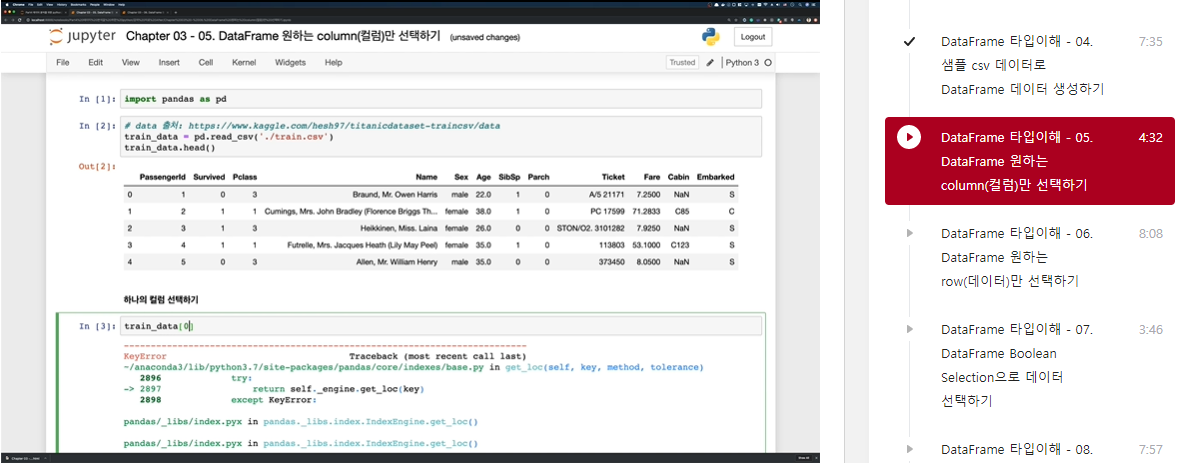
import pandas as pd
# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
train_data = pd.read_csv('../train.csv')
train_data.head()
하나의 컬럼 선택하기
train_data['Survived']
# datatype : Series
>>> 0 0
1 1
2 1
3 1
4 0
..
886 0
887 1
888 0
889 1
890 0
Name: Survived, Length: 891, dtype: int64복수의 컬럼 선택하기
train_data[['Survived', 'Name', 'Age', 'Embarked']]
# datatype : Dataframe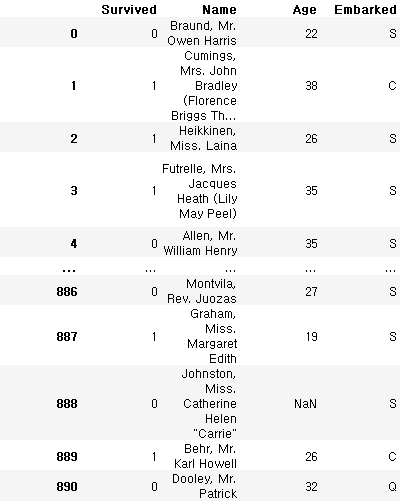
DataFrame에서 원하는 row만 선택하기
import numpy as np
import pandas as pd# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
train_data = pd.read_csv('../train.csv')
train_data.head()
dataframe slicing
- datafrmae의 경우 기본적으로 [] 연산자가 column 선택에 사용
- 하지만, slicing은 row 레벨로 지원
train_data[7:10]
row 선택하기
- Seires의 경우 []로 row 선택이 가능하나, DataFrame의 경우는 기본적으로 column을 선택하도록 설계
- .loc, .iloc로 row 선택가능
- loc - 인덱스 자체를 사용
- iloc - 0 based index로 사용
- 이 두 함수는 ,를 사용하여 column 선택도 가능
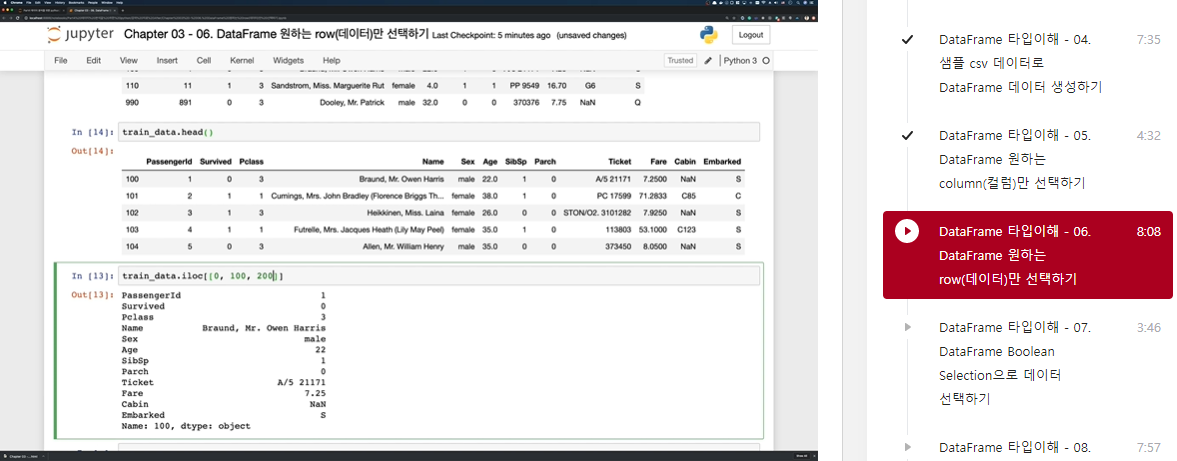
train_data.index = np.arange(100, 991)
train_data.tail()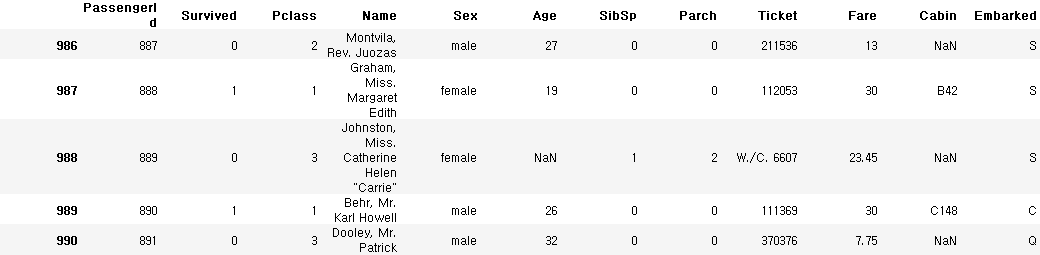
train_data.loc[986]
>>> PassengerId 887
Survived 0
Pclass 2
Name Montvila, Rev. Juozas
Sex male
Age 27.0
SibSp 0
Parch 0
Ticket 211536
Fare 13.0
Cabin NaN
Embarked S
Name: 986, dtype: objecttrain_data.loc[[986, 100, 110, 990]]
train_data.iloc[[0, 100, 200, 2]]
row, column 동시에 선택하기
- loc, iloc 속성을 이용할 때, 콤마를 이용하여 둘 다 명시 가능
train_data.loc[[986, 100, 110, 990], ['Survived', 'Name', 'Sex', 'Age']]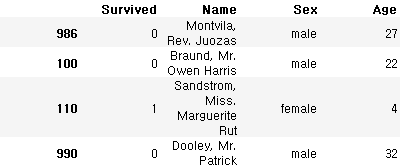
train_data.iloc[[101, 100, 200, 102], [1, 4, 5]]
머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
