DataFrame Boolean Selection으로 데이터 선택하기
import pandas as pd# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
train_data = pd.read_csv('../train.csv')train_data.head()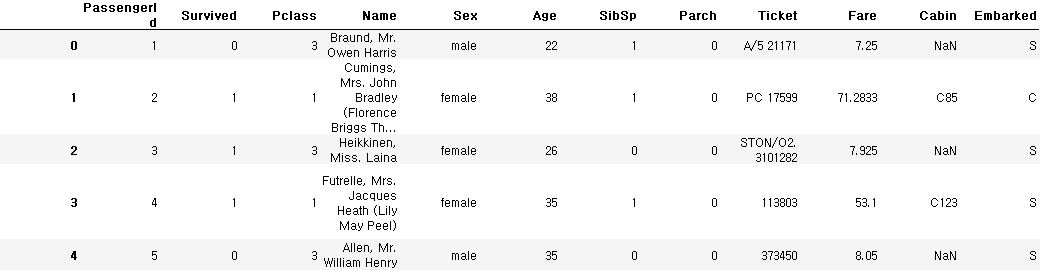
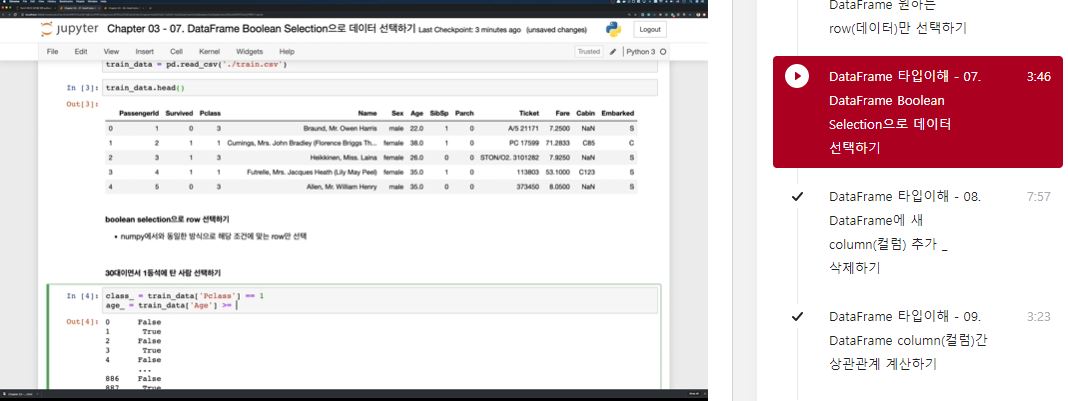
boolean selection으로 row 선택하기
- numpy에서와 동일한 방식으로 해당 조건에 맞는 row만 선택
30대이면서 1등석에 탄 사람 선택하기
class_ = train_data['Pclass'] == 1
age_ = (train_data['Age'] >= 30) & (train_data['Age'] < 40)
train_data[class_ & age_]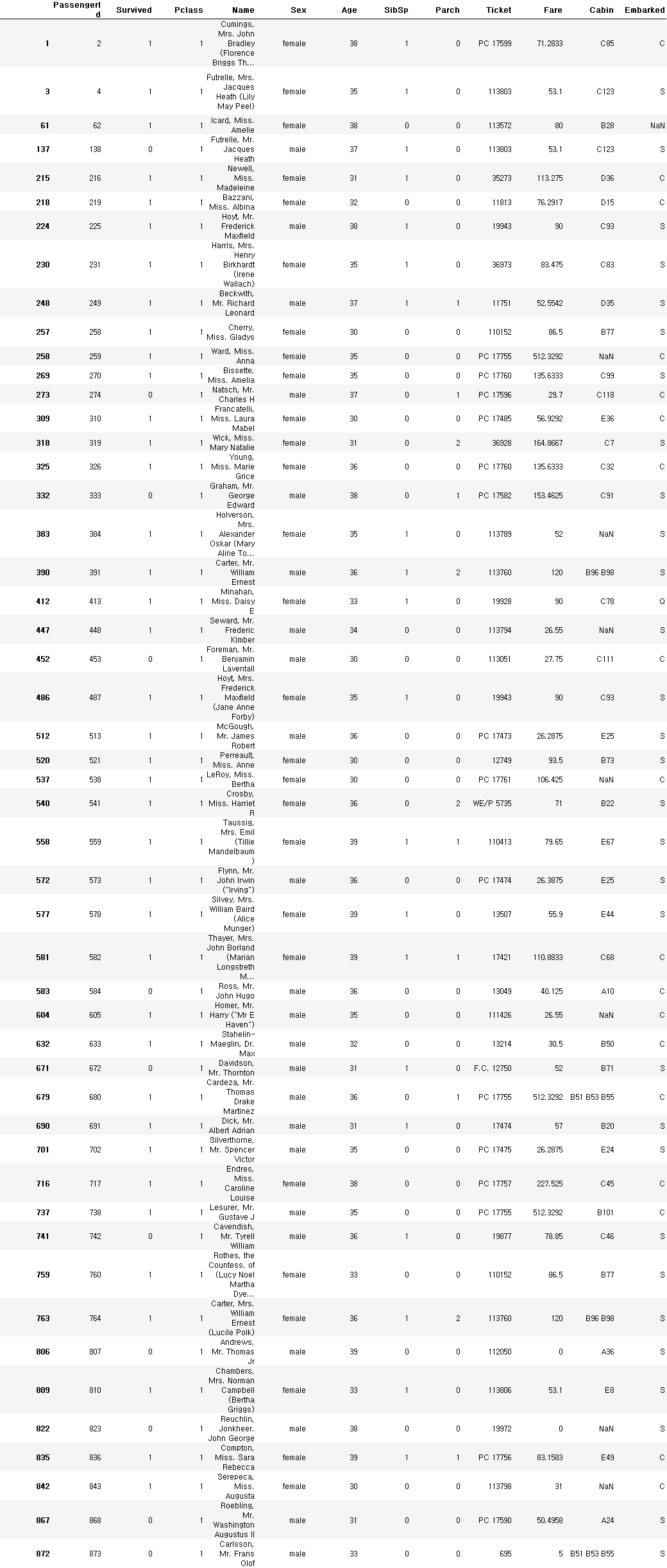
DataFrame에 column 추가, 삭제하기
새 column 추가하기
- [] 사용하여 추가하기
- insert 함수 사용하여 원하는 위치에 추가하기
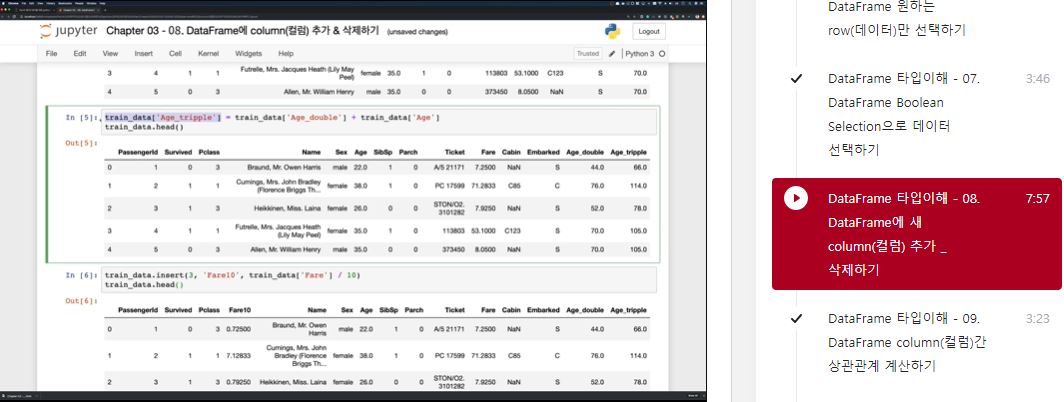
train_data['Age_double'] = train_data['Age'] * 2
train_data.head()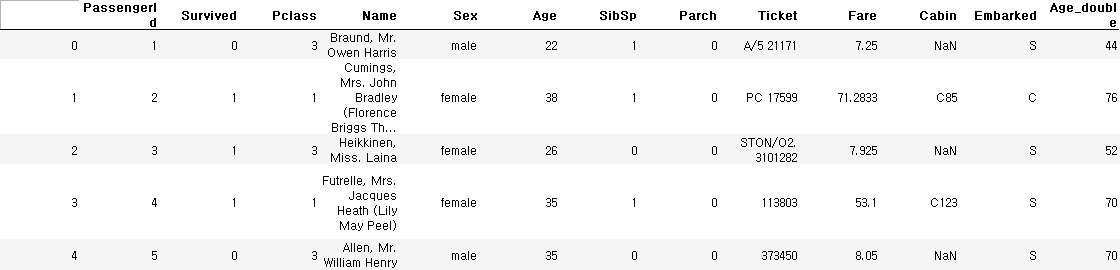
train_data['Age_tripple'] = train_data['Age_double'] + train_data['Age']
train_data.head()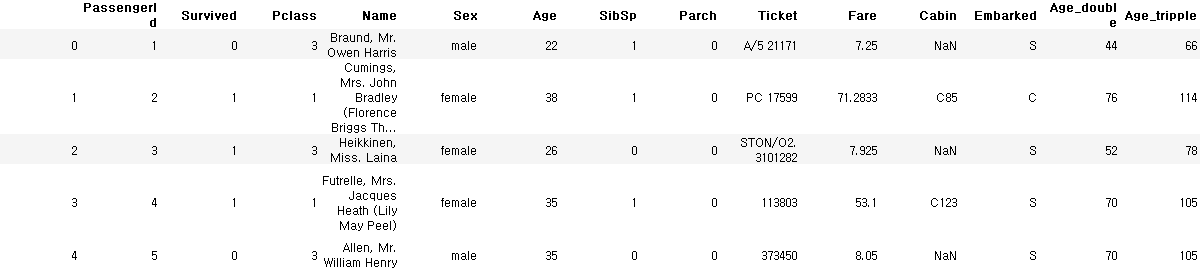
train_data.insert(3, 'Fare10', train_data['Fare'] / 10)
train_data.head()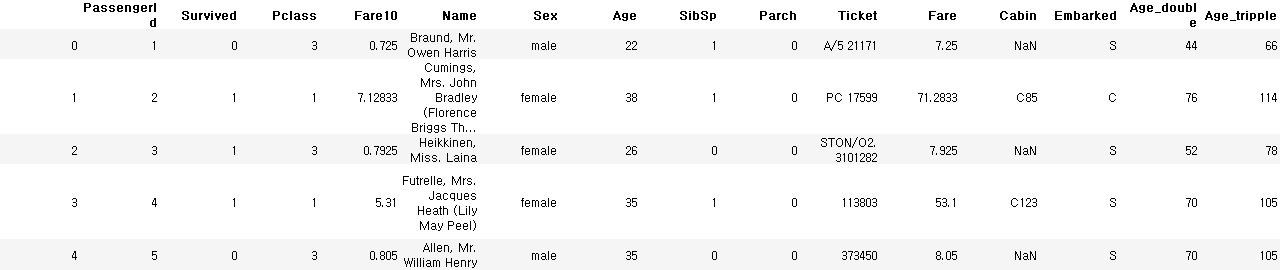
column 삭제하기
- drop 함수 사용하여 삭제
- 리스트를 사용하여 멀티플 삭제 가능
train_data.drop('Age_tripple', axis=1)
train_data.head()
train_data.drop('Age_double', axis=1)
train_data.head()
train_data.drop(['Age_double', 'Age_tripple'], axis=1, inplace=True)
DataFrame column간 상관관계 계산하기
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline # data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
train_data = pd.read_csv('./train.csv')
train_data.head()
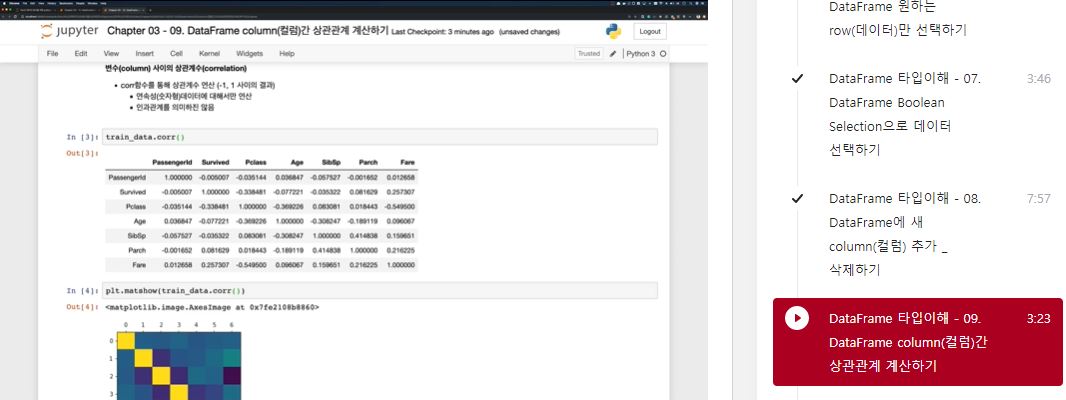
변수(column) 사이의 상관계수(correlation)
- corr함수를 통해 상관계수 연산 (-1,1 사이의 결과)
- 연속성(숫자형)데이터에 대해서만 연산
- 인과관계를 의미하진 않음
train_data.corr()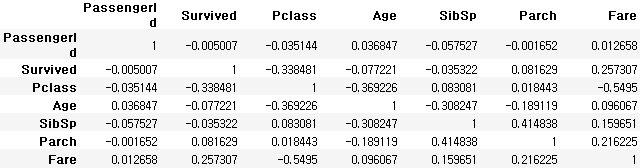
plt.matshow(train_data.corr())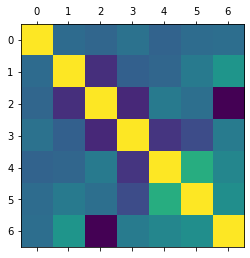
머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
