DataFrame NaN 데이터 처리
import pandas as pd# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
train_data = pd.read_csv('../train.csv')
train_data.head()
NaN 값 확인
- info함수를 통하여 개수 확인
- isna함수를 통해 boolean 타입으로 확인
train_data.info()
>>> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KBtrain_data.isna()train_data['Age'].isna()
train_data['Age'].isna()
>>> 0 False
1 False
2 False
3 False
4 False
...
886 False
887 False
888 True
889 False
890 False
Name: Age, Length: 891, dtype: boolNaN 처리 방법
-
데이터에서 삭제
- dropna 함수
-
다른 값으로 치환
- fillna 함수
-
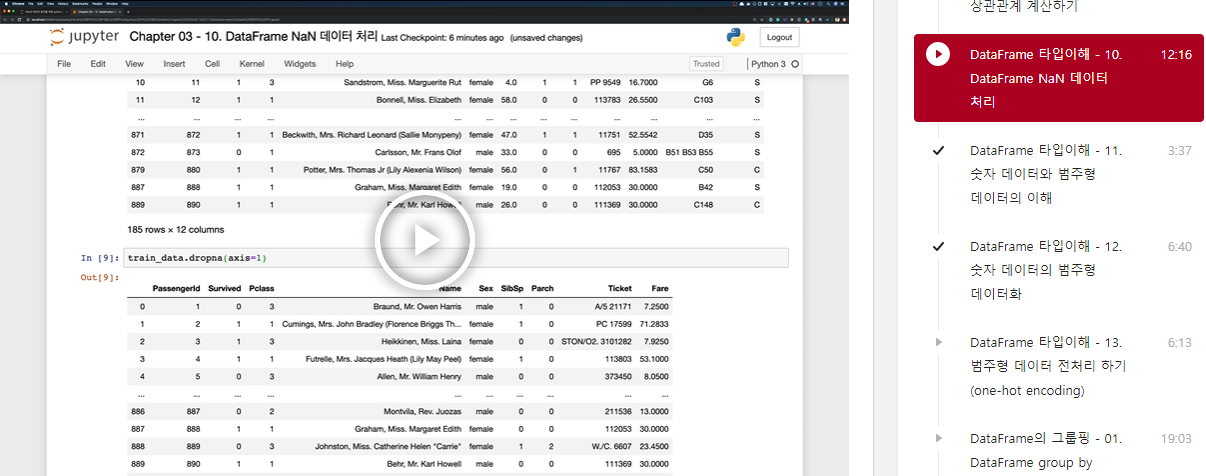
NaN 데이터 삭제하기
train_data.dropna()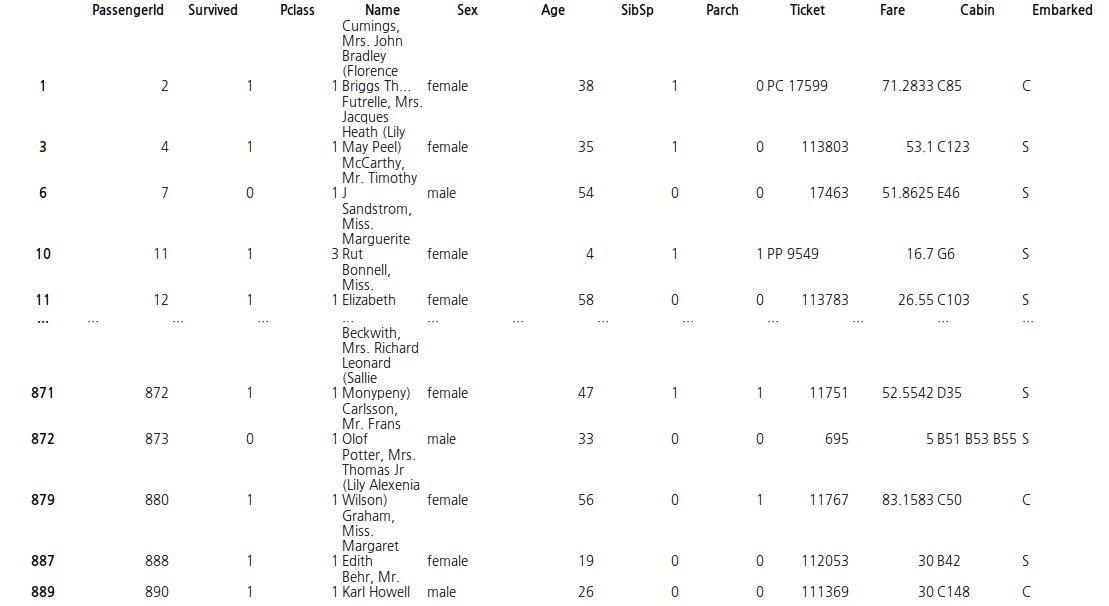
train_data.dropna(subset=['Age', 'Cabin'])
train_data.dropna(axis=1)
- NaN 값 대체하기
- 평균으로 대체하기
- 생존자/사망자 별 평균으로 대체하기
train_data['Age'].fillna(train_data['Age'].mean())
>>> 0 22.000000
1 38.000000
2 26.000000
3 35.000000
4 35.000000
...
886 27.000000
887 19.000000
888 29.699118
889 26.000000
890 32.000000
Name: Age, Length: 891, dtype: float64# 생존자 나이 평균
mean1 = train_data[train_data['Survived'] == 1]['Age'].mean()
# 사망자 나이 평균
mean0 = train_data[train_data['Survived'] == 0]['Age'].mean()
print(mean1, mean0)
>>> 28.343689655172415 30.62617924528302train_data[train_data['Survived'] == 1]['Age'].fillna(mean1)
train_data[train_data['Survived'] == 0]['Age'].fillna(mean0)
>>> 0 22.000000
4 35.000000
5 30.626179
6 54.000000
7 2.000000
...
884 25.000000
885 39.000000
886 27.000000
888 30.626179
890 32.000000
Name: Age, Length: 549, dtype: float64train_data.loc[train_data['Survived'] == 1, 'Age'] = train_data[train_data['Survived'] == 1]['Age'].fillna(mean1)
train_data.loc[train_data['Survived'] == 0, 'Age'] = train_data[train_data['Survived'] == 0]['Age'].fillna(mean0)숫자 데이터와 범주형 데이터의 이해
import pandas as pd# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
train_data = pd.read_csv('../train.csv')
train_data.head()
info함수로 각 변수의 데이터 타입 확인
- 타입 변경은 astype함수를 사용
train_data.info()
>>> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB숫자형(Numerical Type) 데이터
- 연속성을 띄는 숫자로 이루어진 데이터
- 예) Age, Fare 등
범주형(Categorical Type) 데이터
- 연속적이지 않은 값(대부분의 경우 숫자를 제외한 나머지 값)을 갖는 데이터를 의미
- 예) Name, Sex, Ticket, Cabin, Embarked
- 어떤 경우, 숫자형 타입이라 할지라도 개념적으로 범주형으로 처리해야할 경우가 있음
- 예) Pclass
숫자 데이터의 범주형 데이터화
import pandas as pd# data 출처: https://www.kaggle.com/hesh97/titanicdataset-traincsv/data
train_data = pd.read_csv('../train.csv')
train_data.head()
Pclass 변수 변환하기
- astype 사용하여 간단히 타입만 변환
train_data.info()
>>> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null object
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(4), object(6)
memory usage: 83.7+ KBtrain_data['Pclass'] = train_data['Pclass'].astype(str)Age 변수 변환하기
- 변환 로직을 함수로 만든 후, apply함수로 적용
import mathdef age_categorize(age):
if math.isnan(age):
return -1
return math.floor(age / 10) * 10train_data
train_data['Age'].apply(age_categorize)
>>> 0 20
1 30
2 20
3 30
4 30
..
886 20
887 10
888 -1
889 20
890 30
Name: Age, Length: 891, dtype: int64머신러닝과 데이터 분석 A-Z 올인원 패키지 Online. 👉 https://bit.ly/3cB3C8y
