유사 화장품 추천 프로젝트
01. 데이터 수집 👨🏽💻📑
📝 목차
- 대한화장품협회 - 성분사전
- INCI Decoder - Product List
- INCI Decoder - Product & Ingredients
1. 대한화장품 협회 - 성분사전
대한화장품 협회
https://kcia.or.kr/cid/search/ingd_list.php
- 약 20,000개의 성분코드, 성분명, 영문명, CAS No, 구명칭이 Table Class에 담겨있음.
- INCI Decoder에는 화장품 성분의 국문명이 없기 때문에 해당 사이트에서 화장품 성분의 국문, 영문명을 크롤링할 예정.
- 크롤링 한 성분 데이터들은 INCI Decoder 크롤링 때 활용할 예정
Module
import warnings
warnings.filterwarnings(action='ignore')
import pandas as pd
import numpy as np
from tqdm import tqdm_notebook
from bs4 import BeautifulSoup
from html_table_parser import parser_functions
import requestsCrwaling
# kcia의 성분사전 테이블 형태로 빈 데이터 프레임을 미리 하나 만든다
cols = ['성분코드', '성분명', '영문명', 'CAS No', '구명칭']
ing_df = pd.DataFrame(columns=cols)성분사전은 총 2038페이지이다.
url이 "https://kcia.or.kr/cid/search/ingd_list.php?**page=2**" 이런 형식으로 변환되는데, page={num}을 이용하여 루프를 돌면 될 것 같다.
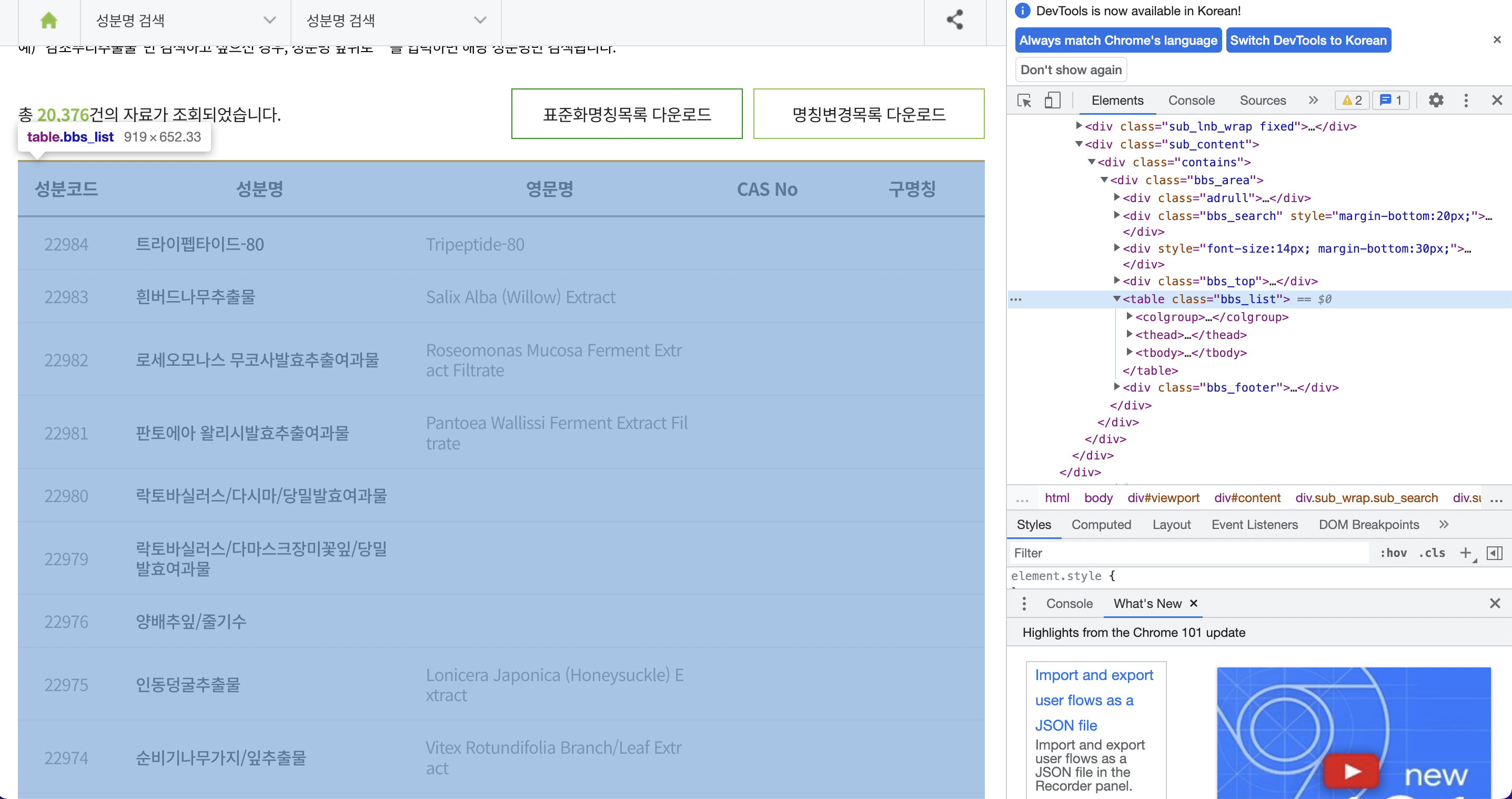
또한, 데이터들이 테이블 클래스에 담겨있다. parser_functions.make2d를 활용할 예정
for num in range(1, 2039): # 1~2038의 페이지로 구성되어있다
url = f"https://kcia.or.kr/cid/search/ingd_list.php?page={num}" # url이 뒤의 page num만 바뀜
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
data = soup.find('table',{"class" : "bbs_list"}) # class가 bbs_list인 테이블을 찾아와서
data = parser_functions.make2d(data)[1:] # parser_functions의 make2d로 받아온다
tmpdf = pd.DataFrame(data, columns=cols) # 임시 데이터 프레임을 만들어 각 페이지 별 테이블 정보를 담아서
ing_df = pd.concat([ing_df ,tmpdf]) # 위에 만들어 놓은 빈 데이터프레임이랑 concat 하는 식으로 누적시킨다
ing_df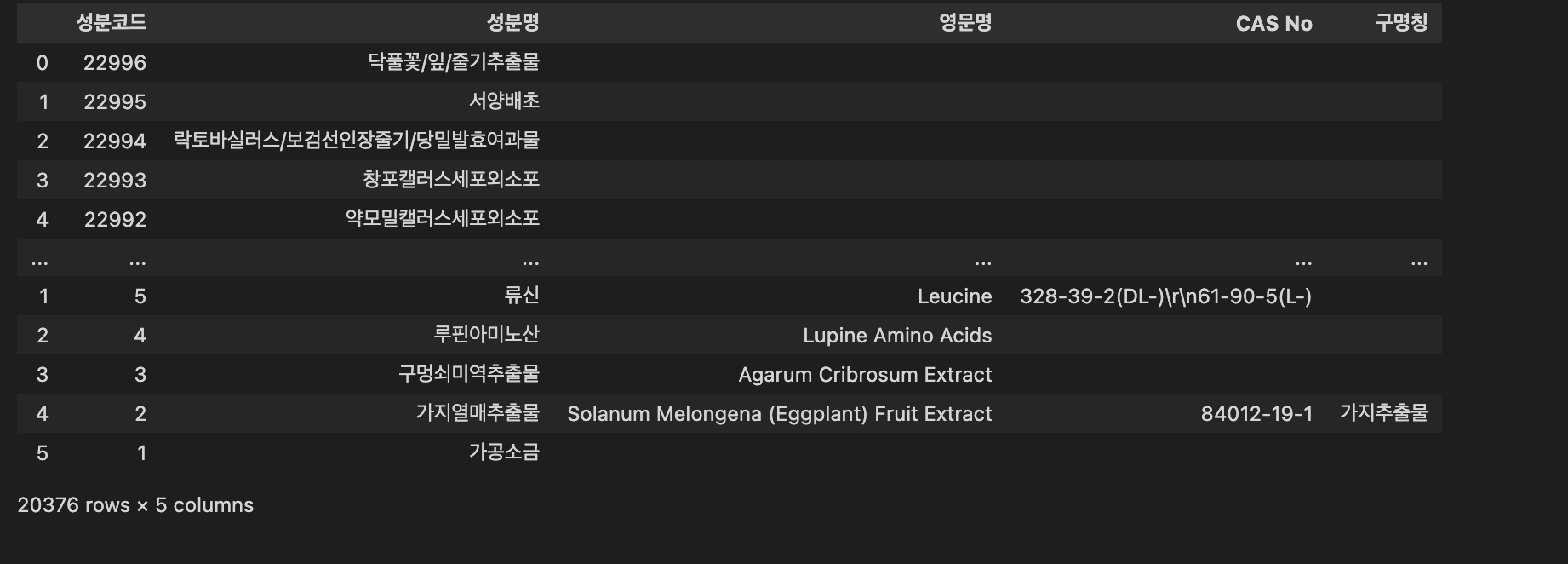
그런데, 성분코드는 22996이 마지막인데, 컬럼 개수는 20376개다
set 자료구조의 차집합을 통해 빠져있는 성분코드가 있는지 확인해보자.
set(list(range(1,22997))) - set(list(ing_df['성분코드'].astype('int')))
# 비교를 위해 str인 성분코드를 int로 바꿈{16499, 8640, 16862, 8847,
...
20133, 20136, 11944, 20134,
...}
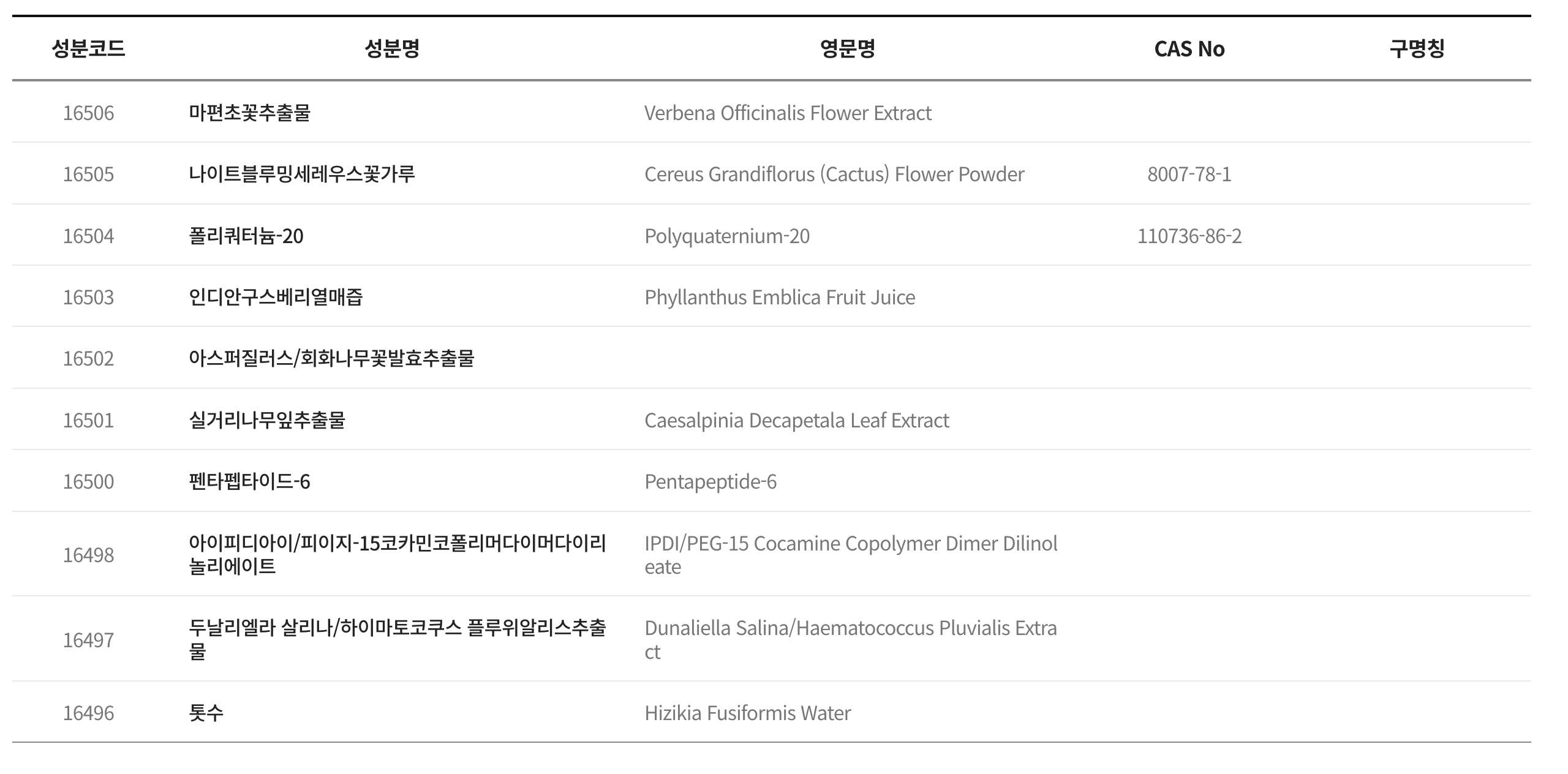
대표로 성분코드 16499의 성분만 확인해보았다.
사이트에서 원래 빠져있는 듯 하다. 즉, 수집은 문제없이 되었다.
데이터 프레임을 성분코드 기준으로 정렬하고 조금 정리하여 확인해보자.
ing_df = ing_df.astype({'성분코드':'int'})
ing_df = ing_df[['성분코드', '성분명', '영문명']].set_index('성분코드').sort_index()
ing_df.reset_index(inplace=True)
ing_df.head(10)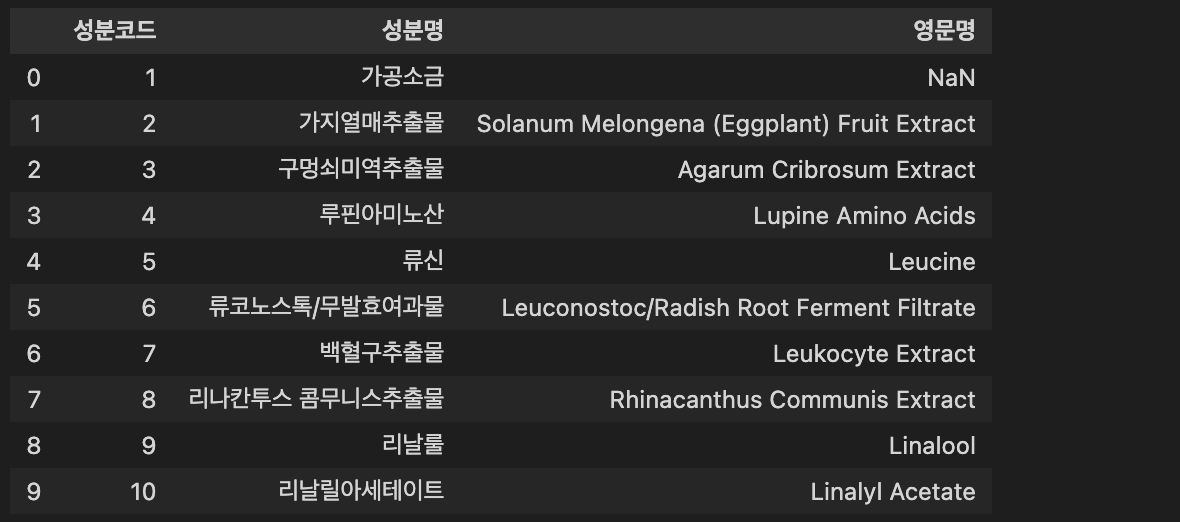
영문명이 없는 성분도 있는 듯 하다.
📍 그런데, 문제가 있다!
성분명을 수집하는 이유는 INCI Decoder 크롤링 때 활용하기 위함인데, url을 확인해보면, incidecoder.com/ingredients/propylene-glycol 이처럼 성분이 모두 소문자 처리되고, 공백 대신에 '-'가 들어있다.
다음 작업에서 쓰기 위한 formatted-named을 만들어주자.
# 정규표현식 re를 사용했다.
import re
pattern = r'\([^)]*\)'
for idx, row in ing_df.iterrows():
tmp = ing_df.iloc[idx]['영문명']
try:
if '(' in tmp:
txt = re.sub(pattern=pattern, repl='', string= tmp)
txt = ' '.join(txt.split())
ing_df.iloc[idx,2] = txt
except:
pass
ing_df['formatted_영문명'] = ing_df['영문명'].str.lower().str.replace(" ","-")
# inci-decoder에 검색가능한 format으로 변경하여 컬럼 추가
ing_df.head(10) # 확인 한 번 해주고
ing_df.to_csv('ing_name.csv') # 저장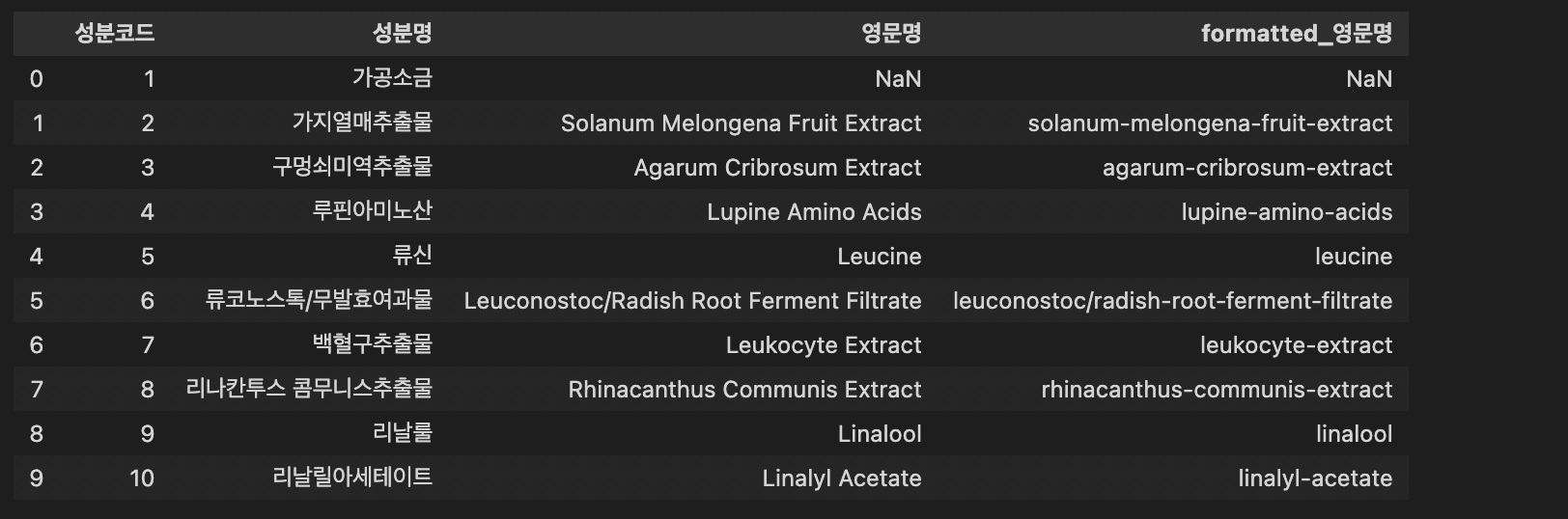
만족스러운 데이터프레임이 완성됐다. 저장해주고 마무리
2. INCI Decoder - Product List
INCI Decoder
- 화장품(제품), 성분, 성분의 효능 에 대한 데이터를 제공.
- 성분을 검색하면 해당 성분이 들어간 화장품 제품 리스트를 제공.
- 제품 페이지에는 제품에 들어간 성분들, 각 성분의 효능들이 테이블로 제공.
- 테이블에 나열된 제품들은 순서가 존재한다. 각 성분이 해당 제품에서 함량을 얼마나 차지하고 있는지에 따라 순차적으로 표기되어 있음.
- 성분사전에서 수집한 성분들을 이용하여 수집할 예정.
Module
from bs4 import BeautifulSoup
import pandas as pd
from tqdm import tqdm
from urllib.request import Request, urlopenCrawling
# 성분 파일(csv) 불러오기
ing_df = pd.read_csv('ing_name.csv',index_col=0)
ing_df['formatted_영문명'] = ing_df['formatted_영문명'].str.replace("/","-")# 성분 파일에서 'formatted_영문명' 컬럼만 웹페이지 접근용으로 사용
# 결측값 제거 후 리스트로 변환
ing_list = list(ing_df['formatted_영문명'].dropna())
product_name = set() # 제품명
product_label = set() # 제품명 (formatted - 웹페이지 접근용)
search_failed = [] # 'formatted_영문명' 값으로 웹페이지 접근이 불가했던 건들 확인용도INCI Decoder에 Ingredient를 검색하면
(예를 들어, Zinc Chloride라는 성분을 검색했다고 가정)
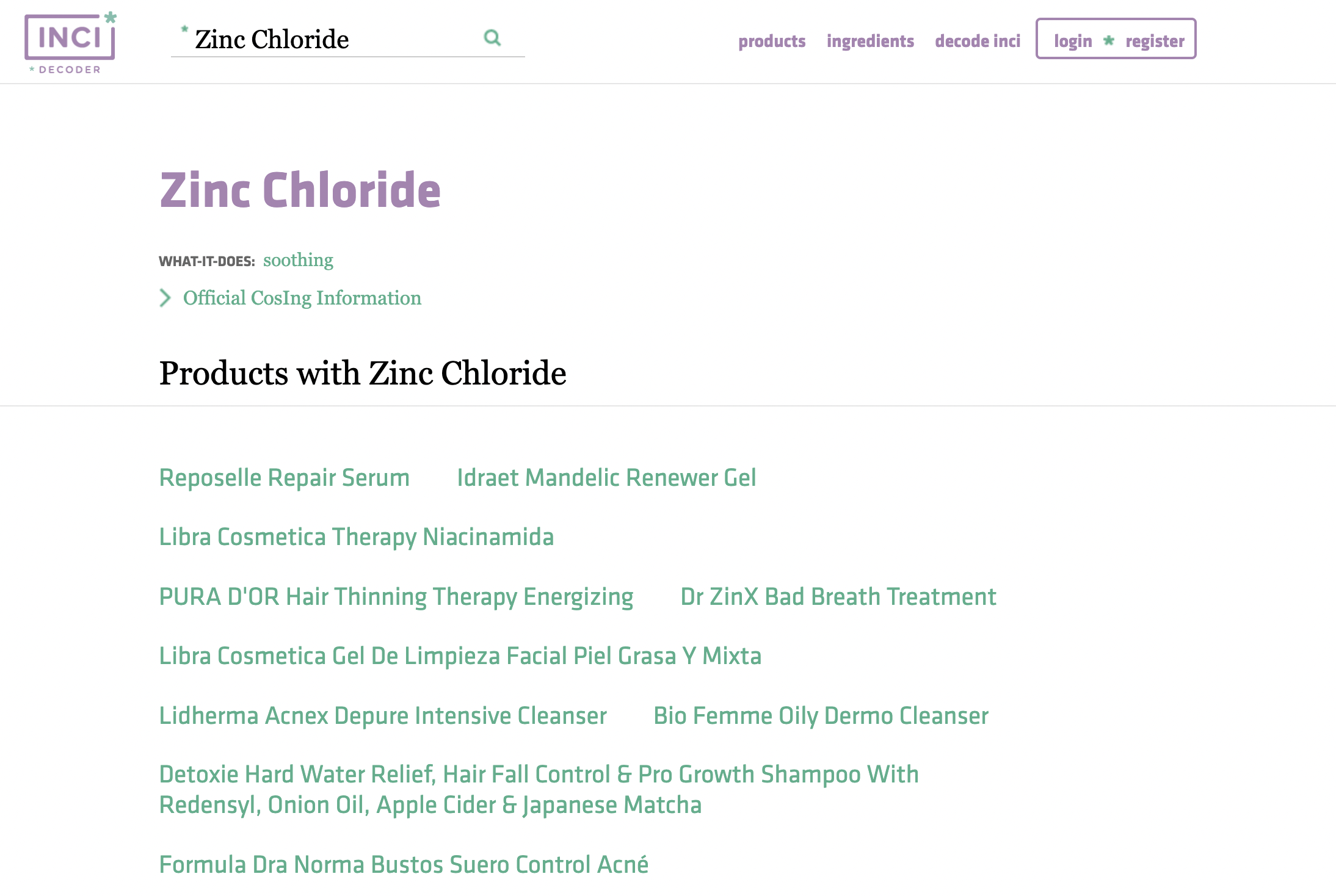
위와 같이 해당 성분이 포함된 제품들이 나열된다.
📍 제품들을 수집하기 위한 함수를 하나 만들자
# 성분으로 조회한 제품 리스트 만들기
def add_ing_products(tags): # html tag 를 받아와 조회하여
for tag in tags:
if tag.text not in product_name: # 중복된 데이터는 추가하지 않도록, tag의 제품명이 product_name 셋에 없는 경우에만 추가
product_name.add(tag.text)
product_label.add(tag.attrs['data-ga-eventlabel'][8:])이 제품들을 수집하여 제품 리스트를 만들고, 만들어진 제품 리스트로 다시 한 번 크롤링 할 예정.

또한 맨 아래를 보면 Next page라는 항목이 존재하는데, INCI Decoder는 성분사전처럼 페이지 숫자로 url을 바꿀 수 없다.
📍 끝 페이지에 도달했는지 확인하기 위한 함수도 만들자
# 성분으로 접근한 웹페이지의 제품 리스트에 '다음페이지'가 존재하는지 확인하기
def next_page_exists(soup):
if "Next" in soup.find(id="product").find_all("div")[-1].text: # Next라는 문자가 해당 태그안에 존재하는지 여부 확인
return True
else:
return False이제 준비가 끝났다. 데이터 수집 시작!
for ing in tqdm(ing_list): # 성분 리스트의 각 성분(formatted)마다
url = 'https://incidecoder.com/ingredients/'+ ing # url 주소를 생성
# if page exists (url로 접근 가능시)
try:
html = urlopen(url)
source = html.read()
soup = BeautifulSoup(source, "html.parser")
tags = soup.select("#product > div > a") # html의 태그 불러오기
add_ing_products(tags) # 태그에서 제품명 (일반+formatted) 리스트에 저장 - 중복건은 추가 x
if next_page_exists(soup): # 제품리스트가 1페이지 이상인지 확인
nextpage = True
while nextpage: # 다음페이지가 존재하는 경우 반복
nexturl = soup.find(id="product").find_all("a")[-1]['href'] # href태그로 다음페이지 url을 생성하여 해당 페이지 접근
url = 'https://incidecoder.com'+ nexturl
html = urlopen(url)
source = html.read()
soup = BeautifulSoup(source, "html.parser")
tags = soup.select("#product > div > a")
add_ing_products(tags) # 다음페이지에서도 동일하게 제품명 받아와서 저장
if not next_page_exists(soup): # 더이상 다음 페이지가 없는 경우 while문 빠져나옴
nextpage = False
# if page does NOT exist (url로 접근 불가시 추후 확인 용도로 search_failed 리스트에 추가)
except Exception:
search_failed.append(ing)
pass 데이터를 수집해왔다. 데이터 프레임을 만들어주고 csv로 저장한 후 확인해보자.
product_all = pd.DataFrame(columns=['product_label'])
product_all['product_label'] = list(product_label)
product_all.to_csv('product_df.csv',index=False)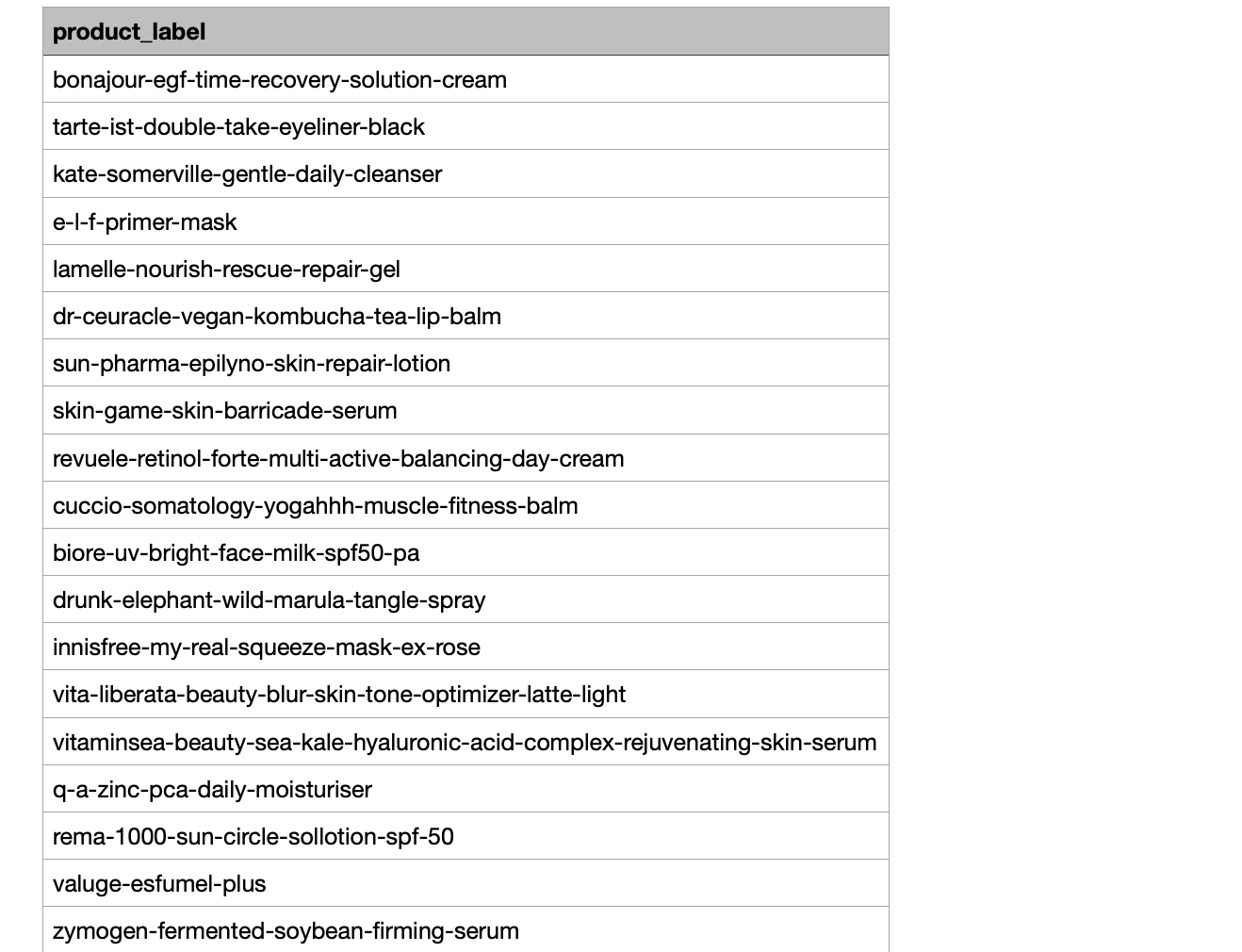
csv 파일의 일부를 발췌해봤다. 잘 모아졌다.
이제 이 제품 리스트를 기반으로 마지막 크롤링을 하면 된다!
3. INCI Decoder - Product & Ingredients
마지막 데이터 크롤링을 통해 두 가지 테이블을 생성할 예정.
1) Product - Product Name/ Ingredients_list
2) Ingredient - Ingredient Name/ What-it-does
Lip Oil : Cross My Heart 제품을 예시로 사이트를 확인해보자.

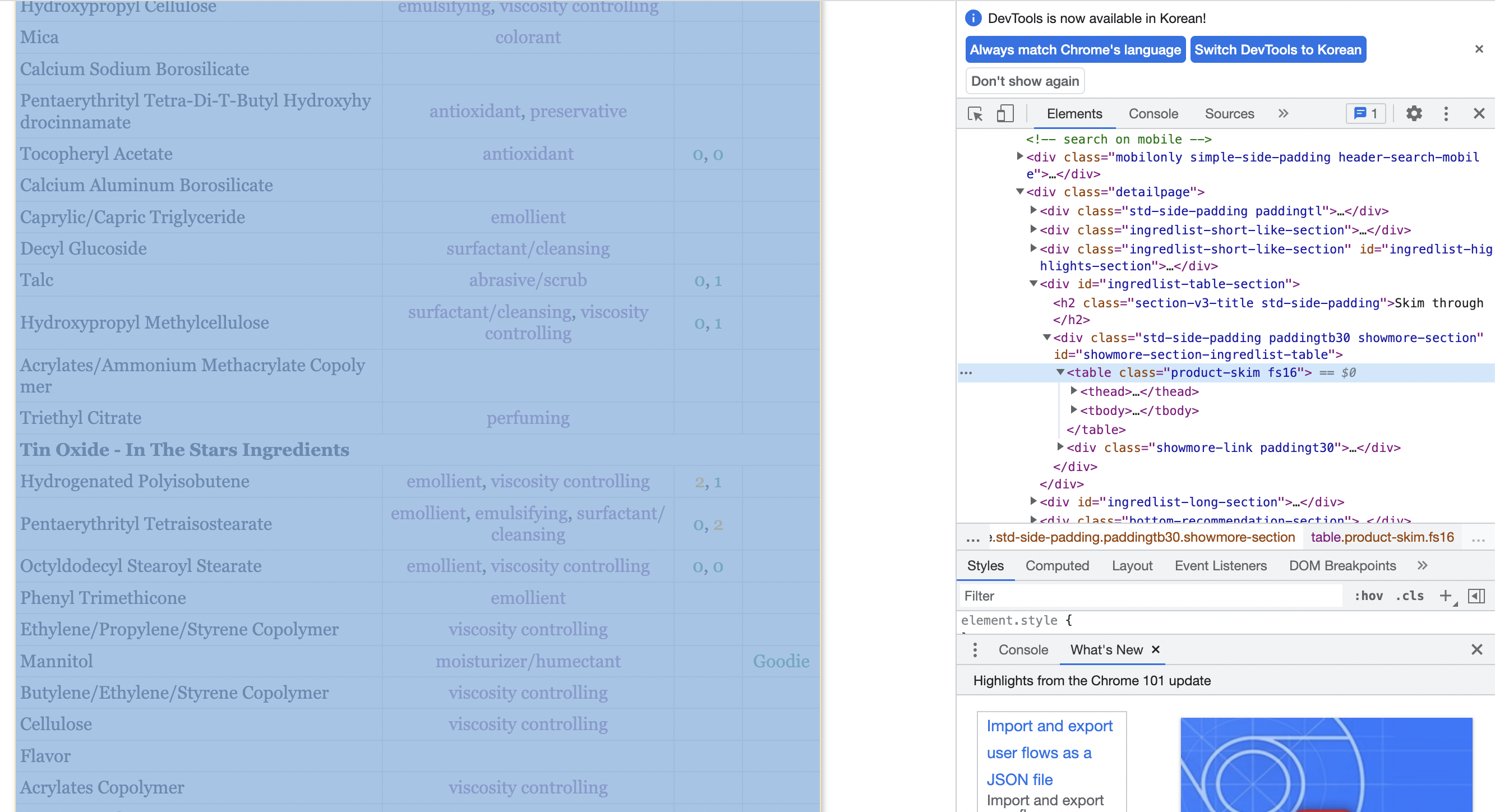
성분시장 크롤링 때와 마찬가지로 특정 클래스 이름을 지닌 테이블에 데이터들이 모여있다.
📍 이번 작업에서도 문제가 있었다.
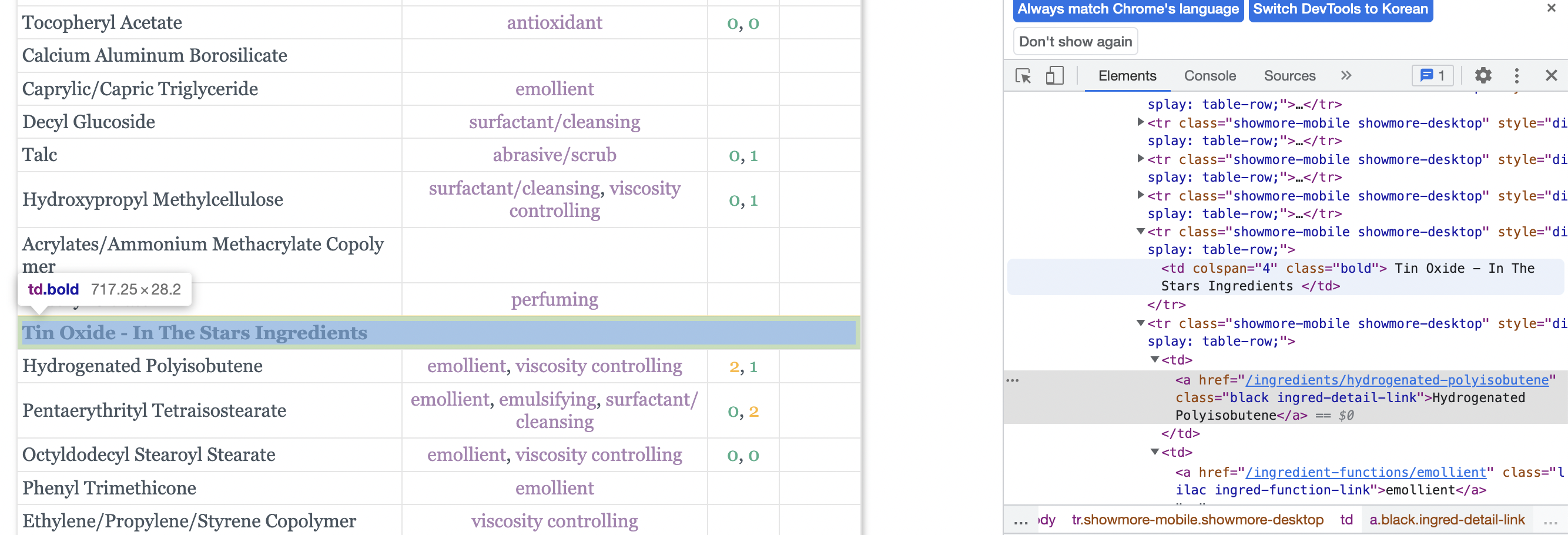
1) html 태그의 성분명이 여러 개의 Ingredient name을 지니고 있었다.
- 예를 들어 html 태그에서는 Water인 성분이 테이블의 Ingredeint name에서는 Aqua, Aqua/Water, Water(Aqua) 처럼 여러개의 성분명으로 나타났다.
- html 태그의 성분명을 formatted name으로 수집하여 추가해줘야 한다.
2) 테이블에는 기재되어 있지만, html 태그에서는 성분명이 없는 성분이 존재했다.
- (테이블의)Ingredient name의 row 개수와 (html태그의) Formatted name의 row 개수가 일치하지 않는 이슈 발생.
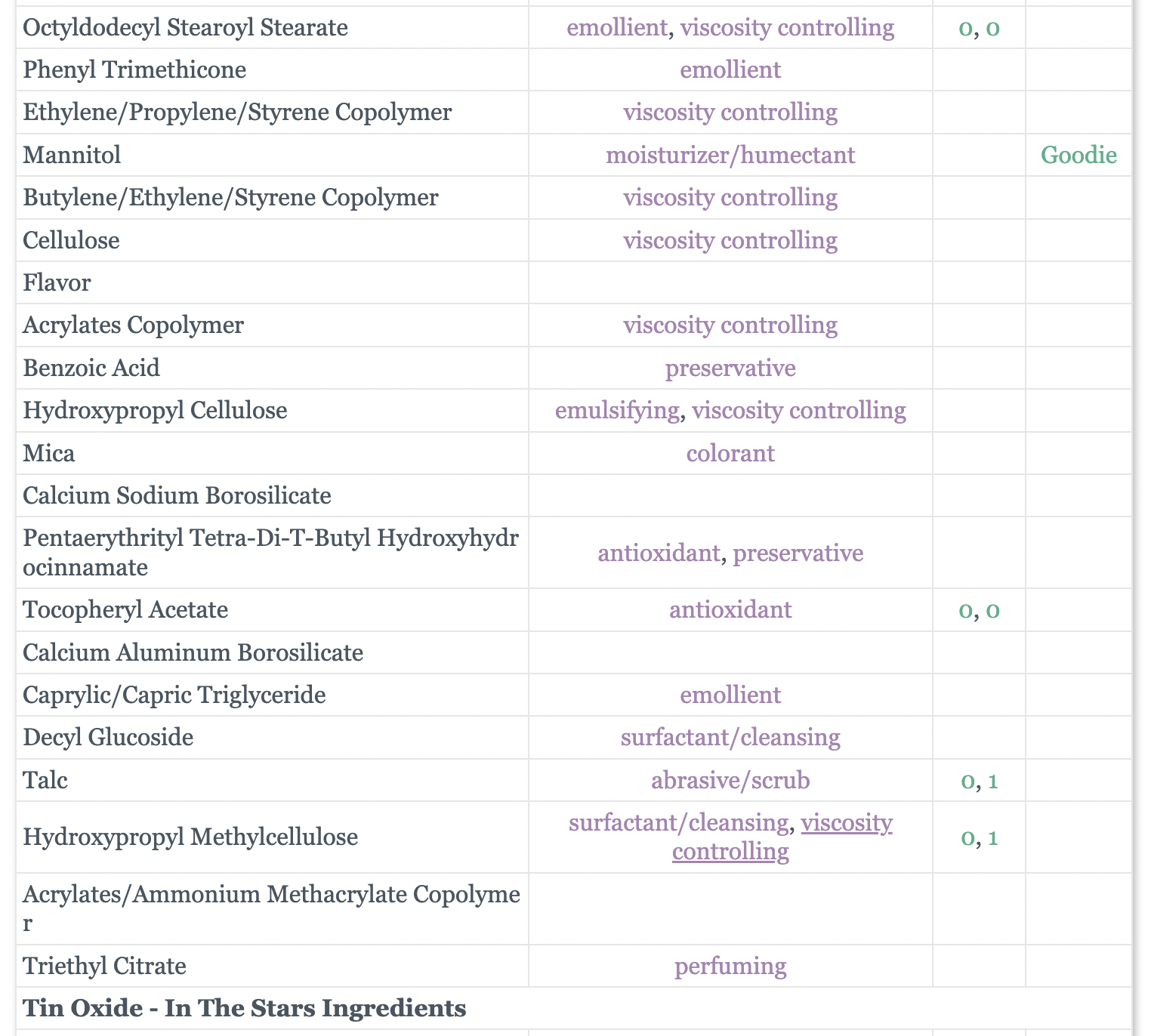
마지막에 Bold 처리된 성분은 사이트의 테이블에는 기재되어 있지만
이처럼 html 태그 안에 formatted name이 존재하지 않았다.
없는 것을 억지로 만들기 보다는 formatted name이 없는 Bold처리된 성분들을 없애기로 하였다. 이제 코드로 살펴보자.
Module
import warnings
warnings.filterwarnings(action='ignore')
import pandas as pd
import numpy as np
from tqdm import tqdm_notebook
from bs4 import BeautifulSoup
import requests
from html_table_parser import parser_functionsCrwaling
먼저, 데이터를 받을 빈 리스트들을 만들어준다.
product_name = [] # 화장품 이름
ingredient_lst = [] # 화장품에 들어있는 성분을 리스트로 받음
formatted_ingredient_lst = [] # formatted 성분 표기명을 리스트로 받음
what_lst = [] # 성분이 어떤 효능이 있는지 리스트로 받음
failed_lst = [] # 크롤링 중 실패한 로그를 추적하기 위해우선 제품 테이블을 위해 각 제품들에 들어간 성분들을 리스트 형태로 묶어서 받을 것이다.
for product in tqdm_notebook(product_lst):
url = f"https://incidecoder.com/products/{product}" # url에 product 명을 바꿔가며 루프를 돈다
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
data = soup.find('table',{"class" : "product-skim fs16"}) # class가 product-skim fs16인 테이블을 태그로 받음
df = parser_functions.make2d(data)[1:] # make2d를 활용해 테이블을 파이썬 자료구조로 받고
tmpdf = pd.DataFrame(df, columns=["Ingredient name", "what-it-does", "irr., com.", "ID-Rating"]) # 임시 데이터 프레임을 만든다
try: # 크롤링 시도
# 클래스 bold인 성분들은 html 태그에 formatted_name이 존재하지 않았다.
# 그래서 테이블에는 기록되어 있지만, 데이터를 모두 수집한 후 데이터 프레임으로 만드는 과정에서 개수가 맞지 않는 이슈가 있었다.(Ingredient_name != Formatted_name)
# 이를 방지하기 위해 bold처리된 성분들을 없앨 것.
Bold_lst = []
for ing in data.find_all('td', {'class': 'bold'}):
Bold_lst.append(ing.text.replace('\n','').strip()) # 전처리
indexes = []
for stop in Bold_lst: # 볼드 처리된 성분들을 없애기 위해 인덱스를 알아내는 작업
indexes.append(tmpdf[tmpdf['Ingredient name'] == stop].index[0])
tmpdf.drop(indexes, axis=0,inplace=True) # 알아온 인덱스들로 drop을 활용해 임시 데이터 프레임에서 삭제한다
ingtmp = []
for tag in data.find_all('a', {'class': "black ingred-detail-link"}):
ingtmp.append(tag.attrs['href'][13:]) # html 태그에 들어있는 formatted 성분명을 알아오는 작업. 마찬가지로 리스트 형태로 받아온다
formatted_ingredient_lst.append(ingtmp)
# 임시로 만든 tmpdf의 데이터들을 활용해 성분명_리스트, 효능_리스트를 얻고
ingredient_lst.append(list(tmpdf['Ingredient name']))
what_lst.append(list(tmpdf["what-it-does"]))
product_name.append(product) # 제품명 추가
except: # 실패시 failed_lst에 기록
failed_lst.append([product, data])이후, 성분 테이블을 위해 리스트로 묶여있는 원소들을 개별로 받아온다.
# 리스트로 묶여있는 원소들을 개별로 받아오는 작업
each_ingredient_lst = []
for lst in ingredient_lst:
for ing in lst:
each_ingredient_lst.append(ing)
each_formatted_ingredient_lst = []
for lst in formatted_ingredient_lst:
for ing in lst:
each_formatted_ingredient_lst.append(ing)
each_what_lst = []
for lst in what_lst:
for does in lst:
tmp = []
for does in does.replace('\n','').replace('\u200b','').split(','): # 전처리
tmp.append(does.strip())
each_what_lst.append(tmp)이제 제품 테이블을 생성하고
cols = ['product name', 'ingredients', 'formatted ingredients']
product_df = pd.DataFrame(columns=cols)
product_df['product name'] = product_name
product_df['ingredients'] = ingredient_lst
product_df['formatted ingredients'] = formatted_ingredient_lst성분 테이블도 생성해준다.
ingredient_df = pd.DataFrame(columns=['ingredients','formatted ingredients','what-it-does'])
ingredient_df['ingredients'] = each_ingredient_lst
ingredient_df['formatted ingredients'] = each_formatted_ingredient_lst
ingredient_df['what-it-does'] = each_what_lst참고로, 한 개의 노트북으로 진행할 시 16시간이 소요될 것으로 예상되었기 때문에 크롤링은 팀원들과 나누어서 진행하였다. 이후 팀원들이 모아온 데이터를 하나의 데이터 프레임으로 합쳤다. 아래는 최종 결과물이다.
📍이름 순으로 정렬된 성분 테이블
inci_ing_final = pd.concat([ing_a, ing_b, ing_c, ing_d, ing_e, ing_f, ing_g]).drop_duplicates().sort_values('ingredients').reset_index().iloc[:,1:]
inci_ing_final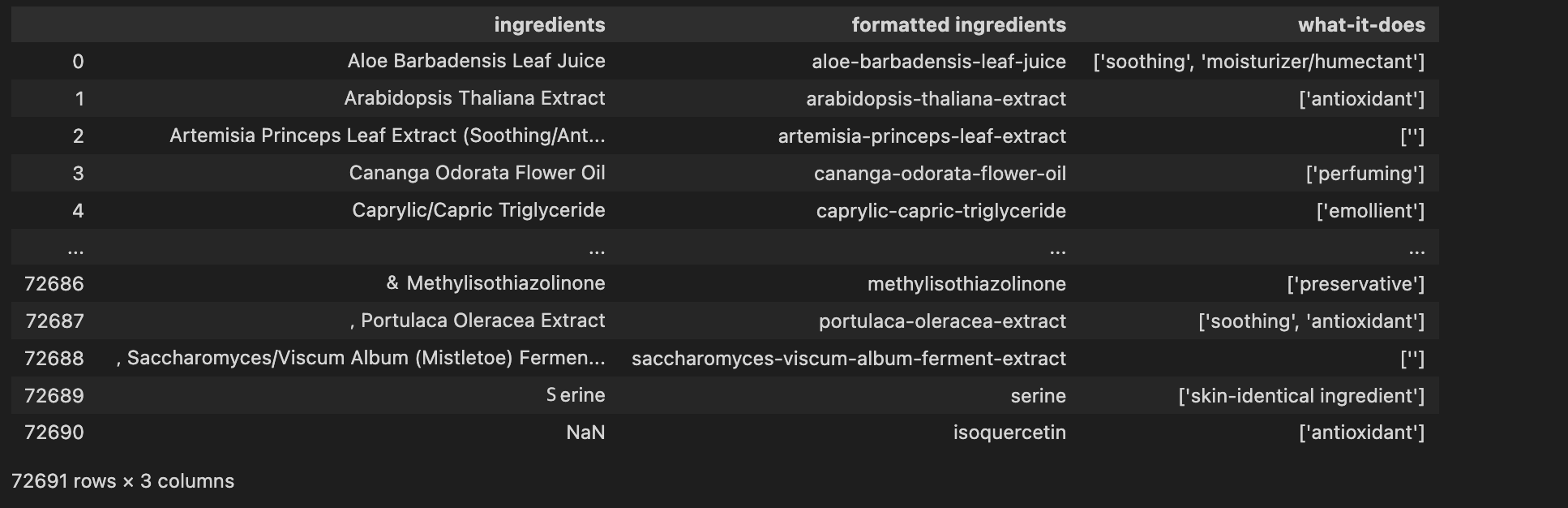
대략 70,000개. formatted ingredients를 기준으로 중복제거 하면 17,000개 정도가 남는다. 성분명/ 성분의 효능(리스트) 형태로 구성되어있다.
📍이름 순으로 정렬된 제품 테이블
inci_prod_final = pd.concat([prod_a, prod_b, prod_c, prod_d, prod_e, prod_f, prod_g]).drop_duplicates().sort_values('product name').reset_index().iloc[:,1:]
inci_prod_final
77,000개의 데이터가 들어있다. 제품명/ 제품에 들어간 성분(리스트) 형태로 구성되어 있으며, 성분 리스트는 제품에 들어간 함유량 순서대로 나열되어 있다. 이 순서를 기반으로 유사도 측정을 할 예정. 이제 데이터를 수집해왔으니 EDA 과정을 통해 열심히 뜯어볼 예정!
