유사 화장품 추천 프로젝트
02. EDA 🕹📭
📝 목차
- 모듈 준비 및 데이터 불러오기
- Domain Knowledge
- EDA
3-1. 이상치 및 결측치 확인
3-2. 성분 별 카운트
3-3. 제품 별 특징
3-4. 효과 별 성분 랭크- 결과 정리
1. 모듈 준비 및 데이터 불러오기
Module
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsData
prod_df = pd.read_csv('/Users/kanghyuntae/Documents/프로젝트/inci_prod_final.csv')
prod_df.head()
[ product_df 테이블 ]
- product name: 제품명
- ingredients: 제품에 포함된 성분이 리스트 형태로 들어있음
- formatted ingredients: ingredients를 통일하기 위하여 전처리
i.e) Water, Aqua, Water(Aqua) -> 모두 water로
ing_df = pd.read_csv('/Users/kanghyuntae/Documents/프로젝트/inci_ing_final.csv')
ing_df.head()
[ing_df 테이블]
- ingredients: product_df에 리스트로 묶여있던 성분들을 zip 해제
- formatted ingredients: 마찬가지로 통일하기 위하여 전처리
- what-it-does: 해당 성분이 가진 효과
2. Domain Knowledge
| 성분명(영) | 성분명(한) | 효과 |
|---|---|---|
| 'abrasive/scrub' | 연마제/스크럽 | 피부를 윤기나게 하거나 각질을 제거하는 데 도움이 되는 스크럽의 작은 "덩어리" 성분. 연마제는 또한 치아를 청소하기 위해 구강 관리 제품에 자주 사용됩니다. |
| 'anti-acne' | 항여드름 | 여드름 퇴치에 도움이 되는 좋은 성분. 그들은 또한 종종 항균제 및/또는 항염증제입니다. |
| 'antimicrobial/antibacterial' | 향균(미생물 포함) | 피부의 미생물 성장을 조절하는 성분. 항균제는 박테리아의 성장 또는 번식을 제어하는 반면 항균제는 더 넓은 범위에서 박테리아, 곰팡이 및 일부 바이러스의 확산을 방지합니다. |
| 'antioxidant' | 항산화제 | 피부가 콜라겐을 손상시키는 free radical* 을 퇴치하는 데 도움이 되는 좋은 성분. 이 기능이 포함된 성분은 중요한 노화 방지 성분 중 하나입니다. |
| 'buffering' | 완충제 | 화장품 포뮬러의 pH를 적정한 값으로 설정해주는 헬퍼 성분. |
| 'cell-communicating ingredient' | 세포-전달 성분 | 피부 세포에 "더 잘 행동"하도록 신호를 보내는 성분. 가장 유명한 예는 레티놀 또는 펩타이드입니다. |
| 'chelating' | 킬레이트제 | 금속 이온(보통 물에서 유래)과 반응하여 공식을 안정적으로 유지하는 데 도움이 되는 도우미 성분 |
| 'colorant' | 착색제 | 화장품에 좋은 색상을 부여하는 보조 성분입니다. |
| 'emollient' | 피부연화제 | 피부를 부드럽고 매끄럽고 사랑스럽게 만드는 좋은 성분. |
| 'emulsifying' | 유화제 | 일반적으로 서로 섞이는 것을 좋아하지 않는 성분(특히 물과 기름)들이 훌륭하고 균일한 혼합물을 형성하도록 돕는 성분. 그것들이 없으면 화장품이 물기 부분과 기름기 부분으로 분리됩니다. |
| 'exfoliant' | 각질제거제 | 각질 제거에 도움을 주는 좋은 성분들이 피부를 더욱 신선하고 매끄럽게 가꾸어 줍니다. 그것들 중 많은 성분들이 피부에 추가적인 이점을 가지고 있습니다. |
| 'moisturizer/humectant' | 보습제/습윤제 | 습윤제(Humectant)는 피부가 물에 잘 달라붙어 피부가 촉촉한 느낌이 들도록 도와주는 모이스처라이저 성분의 정식 명칭입니다. |
| 'perfuming' | 향수 | 좋은 냄새가 나도록 합니다. |
| 'preservative' | 방부제 | 화장품이 음식처럼 작동하지 않도록 도와주는 것: 냉장고에 넣어두어도 1~2주 안에 상하는 것처럼. 그들은 일반적으로 가장 피부 친화적인 성분은 아니지만 매우 중요하고 이것이 없으면 화장품 안전을 위협하고 완전히 안전한 수준으로 소량을 사용합니다. |
| 'skin brightening' | 피부 미백제 | 태양 손상 또는 PIH(염증 후 색소 침착)로 인한 갈색 반점(과색소 침착)을 완화시키는 데 도움이 되는 성분. |
| 'skin-identical ingredient' | 피부유사성분 | 피부에서 찾을 수 있거나 피부에서 자연적으로 찾을 수 있는 것을 모방하는 정말 좋은 성분. 그들은 두 개의 큰 그룹*이 있습니다. |
| 'solvent' | 용제 | 제품의 다른 성분을 녹이는 성분. 가장 큰 비중을 차지하는 물이 여기 해당됨. |
| 'soothing' | 진정제 | CosIng*의 공식 정의는 "피부의 불편함을 완화시키는 데 도움이 되는 성분". 염증을 줄이고 피부를 진정시키는 좋은 항염 및 항자극 성분이 이 범주에 속합니다. 그들은 일반적으로 피부의 노화 과정을 늦추는 데 도움이 되며 여드름, 주사비 또는 민감한 피부와 같은 몇 가지 일반적인 피부 질환에 매우 도움이 됩니다. |
| 'sunscreen' | 자외선 차단제 | 자외선으로부터 피부를 보호하는 데 도움이 되는 성분. |
| 'surfactant/cleansing' | 계면활성제/세정제 | 화장품의 표면장력을 낮추고 제품이 고르고 쉽게 퍼질 수 있도록 도와주는 성분. 그들은 일반적으로 물을 좋아하는 머리 부분과 기름을 좋아하는 꼬리 부분을 가지고 있으므로 클렌저 또는 거품을 만드는 모든 것의 중요한 성분이 되는 경향이 있습니다. 종종 계면활성제는 세정 및 유화 성분이기도 합니다. |
| 'viscosity controlling' | 점도 조절제 | 이것이 증점제의 공식 기능 이름입니다. 이들은 제품을 thicken-up 하여 질감이 좋은 젤, 세럼 또는 모이스처라이저를 형성하는 데 도움이 되는 성분입니다. |
free radical: 동식물의 체내 세포들의 대사과정에서 생성되는 산소화합물인 활성산소를 이르는 말이다. 활성산소는 체내 적당량이 있으면 세균이나 이물질로부터 방어하는 기능을 하지만, 과다 발생할 경우 정상세포까지 무차별 공격해 각종 질병과 노화의 주원인이 된다.
NMFs(Natural Moisturizing Factor): 각질형성세포(피부 세포) 내부에서 발견될 수 있고 우리 피부가 물을 붙잡아두는 데 도움이 되는 것들. 글리세린 또는 히알루론산은 유명한 NMF입니다. 그들은 피부의 수분을 잘 유지하는 데 매우 중요합니다.
SC(각질층 - 피부의 외부 층) 지질: 피부 세포 사이에는 세포외 기질이라고 하는 끈적끈적한 물질이 있습니다. 그것은 주로 지질로 구성되어 있으며 건강한 피부 장벽을 갖는 데 매우 중요합니다. 세라마이드, 콜레스테롤 및 지방산은 중요한 SC 지질입니다.
CosIng: EU의 화장품 원료 정보 데이터베이스
3. EDA
3-1. 이상치 및 결측치 확인
📌 info()로 1차 확인시 결측치가 없음.
→ 이는 성분정보가 없어도 텍스트 데이터('[]')로 존재하기 때문일 것임.
→ 각 주성분 리스트 (텍스트 데이터)를 실제 리스트 타입의 데이터로 변환하여 주성분 목록의 길이 확인 필요.
# 함수 설명: 주성분 목록의 길이가 x(length)개인 제품들의 수 계산
def find_inglst_length(length):
products = []
for i,data in enumerate(product_df['formatted ingredients']):
data = data.split("'")
tmp = []
for each in data:
if len(each) != 1:
if ',' not in each:
tmp.append(each)
if len(tmp) == length:
products.append(product_df['product name'][i])
return products# 주성분 목록의 길이가 0~3개인 제품의 갯수 확인
for i in range(4):
check = find_inglst_length(i)
print(f'Number of products with {i} ingredient:', len(check))
# 주성분이 1~3개인 제품들 직접 확인
for i in range(1,4):
print(f'주성분{i}개 제품 예시: {find_inglst_length(i)[0]}')
print('url: '+'https://incidecoder.com/products/'+str(find_inglst_length(i)[0]))
| 주성분 수(x) | 주성분 수 가 x개인 제품 수 | 제품 예시 | 제품 URL 링크 |
|---|---|---|---|
| 0개 | 없음 | - | - |
| 1개 | 181 | Almond Oil | https://incidecoder.com/products/action-almond-oil |
| 2개 | 145 | Original Oil | https://incidecoder.com/products/abyssian-original-oil |
| 3개 | 234 | Primer And Set Powder | https://incidecoder.com/products/14e-cosmetics-primer-and-set-powder |
제품 주성분이 존재하지 않는(주성분 수=0) 결측치 없음.
제품 주성분이 1~2개 인 제품 확인됨(예: Almond Oil, Original Oil=오일 2종 합성 제품)화장품으로 정의하기에 부적합하여 이상치로 구분할 수도 있음.
추후 EDA 과정 후반에서 필요시 처리하도록 하고 우선 데이터 유지 결정
3-2. 성분 별 카운트
from collections import defaultdict
ing_cnt = defaultdict(int)
for idx, row in prod_df.iterrows():
for ing in row['formatted ingredients'].split(','):
ing_cnt[(ing.replace('[','').replace(']','').replace("'",'').strip())] += 1
ing_cnt = sorted(ing_cnt.items(), key=lambda x:x[1], reverse=True)ing_cnt_df = pd.DataFrame(ing_cnt, columns=['ing','cnt'])
ing_cnt_df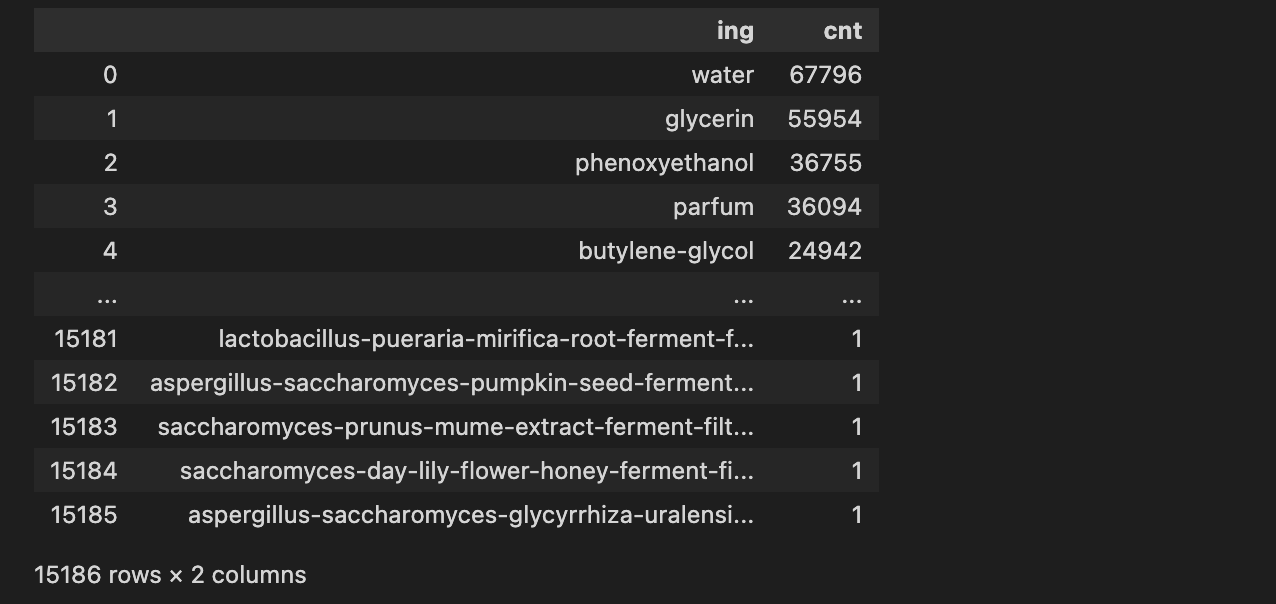
ing_top10 = [ing for ing, cnt in ing_cnt[:10]]
ing_top10
['water',
'glycerin',
'phenoxyethanol',
'parfum',
'butylene-glycol',
'ethylhexylglycerin',
'disodium-edta',
'citric-acid',
'xanthan-gum',
'tocopherol']단순히 많이 쓰인 성분들을 확인하는 단계였기에 큰 인사이트는 찾지 못했다.
이후 제품 유형 별 많이 쓰인 성분을 확인해볼 예정이다.
이 때 top 10 성분이 얼마나 많은 비중을 차지하는지 확인해보고 싶어 top10 성분만 따로 추출해놨다.
3-3. 제품 별 특징
화장품 법령 분류 체계를 참고하여 제품을 분류했다.
제품명에 essence, serum 등 유형이 확실히 표기 된 제품들을 이용하여 특징을 파악해봤다.
크게 5가지 [기초화장품/ 자외선차단제/ 세정용제품/ 두발용제품/ 색조화장품] 유형을 탐색했다.
함수를 먼저 만들어주자.
# 특정 단어가 들어간 제품을 찾아내기 의한 함수
# i.e) prod_char('sunblok') -> sunblock이 제품명에 들어간 제품을 찾아냄
def prod_char(product):
sH = defaultdict(int) # 빈 딕셔너리 만들고
for idx, row in prod_df.iterrows(): # prod_df 테이블을 순회하면서
if product in row['product name']: # 입력값으로 받은 product가 제품명에 들어가 있으면
for ing in row['formatted ingredients'].split(','): # formatted ingredients를 전처리해서
ing = ing.replace('[','').replace("'",'').strip()
sH[ing] += 1 # 전처리한 formatted ingredients를 key로 하여 숫자를 카운트해준다(value)
sH = sorted(sH.items(), key=lambda x:x[1], reverse=True) # 카운트된 숫자(value) 기준 내림차순 정렬
return sH# 사용빈도 top10 ingredients를 제외한 성분들을 보고싶어서 만들었던 함수
# 크게 쓸모는 없었다.
def except_top10(prod_char, n): # 사용빈도 top10을 제외한 성분들로 몇 순위까지 보고 싶은지 n으로 설정
sort_prod = []
most_lst = []
for idx, val in enumerate(prod_char):
if val[0] in ing_top10: # top10 성분들 줍줍
most_lst.append((idx+1, (val[0], val[1])))
else: # top10 제외한 놈들 줍줍
sort_prod.append((idx+1, (val[0], val[1])))
if len(sort_prod) == n: # top N이 완성되면 return
return (sort_prod, most_lst)[📌 먼저 Top10 성분이 얼마나 자주 쓰이는지 확인 ]
기초 화장품
# 위에서 만든 prod_char 함수 이용 ~
serum_ing = prod_char('serum')
essence_ing = prod_char('essence')
mist_ing = prod_char('mist')
emulsion_ing = prod_char('emulsion')
cream_ing = prod_char('cream')
lotion_ing = prod_char('lotion')
toner_ing = prod_char('toner')# 하나만 예시로 뽑아보면 __ing 자체는 리스트!
serum_ing[:5] # 리스트 안에 (ing, cnt) 형태의 튜플이 있음
[('water', 6844),
('glycerin', 5886),
('phenoxyethanol', 3622),
('sodium-hyaluronate', 3336),
('xanthan-gum', 3001)]compare = pd.DataFrame(columns=['serum','essence', 'mist', 'emulsion','cream','lotion','toner'], index=[i for i in range(1,11)]) # 컬럼, 인덱스 지정해주고
for idx, row in compare.iterrows(): # top10만 뽑아주려고 ___ing[:10] 슬라이싱
# index를 1부터로 설정해서 -1씩 해준거~
compare.iloc[idx-1, 0] = (serum_ing[:10][idx-1][0]) # 세럼 top10에서 각 인덱스별 튜플 뽑아서 ~ 튜플(ing,cnt) 였으니까 0번째는 ing!
compare.iloc[idx-1, 1] = (essence_ing[:10][idx-1][0])
compare.iloc[idx-1, 2] = (mist_ing[:10][idx-1][0])
compare.iloc[idx-1, 3] = (emulsion_ing[:10][idx-1][0])
compare.iloc[idx-1, 4] = (cream_ing[:10][idx-1][0])
compare.iloc[idx-1, 5] = (lotion_ing[:10][idx-1][0])
compare.iloc[idx-1, 6] = (toner_ing[:10][idx-1][0])
compare| serum | essence | mist | emulsion | cream | lotion | toner |
|---|---|---|---|---|---|---|
| water | water | water | water | water | water | water |
| glycerin | glycerin | glycerin | glycerin | glycerin | glycerin | glycerin |
| phenoxyethanol | butylene-glycol | phenoxyethanol | butylene-glycol | phenoxyethanol | phenoxyethanol | butylene-glycol |
| sodium-hyaluronate | phenoxyethanol | butylene-glycol | disodium-edta | cetearyl-alcohol | parfum | 1-2-hexanediol |
| xanthan-gum | sodium-hyaluronate | parfum | dimethicone | glyceryl-stearate | cetearyl-alcohol | ethylhexylglycerin |
| butylene-glycol | disodium-edta | ethylhexylglycerin | carbomer | dimethicone | xanthan-gum | phenoxyethanol |
| ethylhexylglycerin | ethylhexylglycerin | citric-acid | parfum | butylene-glycol | dimethicone | sodium-hyaluronate |
| niacinamide | 1-2-hexanediol | sodium-hyaluronate | glyceryl-stearate | parfum | glyceryl-stearate | disodium-edta |
| tocopherol | parfum | disodium-edta | ethylhexylglycerin | caprylic-capric-triglyceride | disodium-edta | panthenol |
| disodium-edta | xanthan-gum | propanediol | phenoxyethanol | xanthan-gum | tocopheryl-acetate | allantoin |
[ 📌 이번에는 각 유형별, 해당 유형의 효과를 내는 성분을 색깔 처리해보자 ]
자외선 차단제
sunblock_ing = prod_char('sunblock')
sunscreen_ing = prod_char('sunscreen')
suncream_ing = prod_char('sun-cream')
sunstick_ing = prod_char('sun-stick')
compare = pd.DataFrame(columns=['sunblock','sunscreen','sun-cream','sun-stick'], index=[i for i in range(1,11)])
for idx, row in compare.iterrows():
compare.iloc[idx-1, 0] = (sunblock_ing[:10][idx-1][0])
compare.iloc[idx-1, 1] = (sunscreen_ing[:10][idx-1][0])
compare.iloc[idx-1, 2] = (suncream_ing[:10][idx-1][0])
compare.iloc[idx-1, 3] = (sunstick_ing[:10][idx-1][0])
compare| sunblock | sunscreen | sun-cream | sun-stick |
|---|---|---|---|
| water | water | water | bis-ethylhexyloxyphenol-methoxyphenyl-triazine |
| ethylhexyl-methoxycinnamate | glycerin | glycerin | water |
| glycerin | zinc-oxide | butylene-glycol | diethylamino-hydroxybenzoyl-hexyl-benzoate |
| zinc-oxide | phenoxyethanol | titanium-dioxide | ethylhexyl-salicylate |
| butylene-glycol | titanium-dioxide | 1-2-hexanediol | ethylhexyl-methoxycinnamate |
| titanium-dioxide | dimethicone | ethylhexylglycerin | butylene-glycol |
| dimethicone | butyl-methoxydibenzoylmethane | stearic-acid | vinyl-dimethicone-methicone-silsesquioxane-cro... |
| disodium-edta | tocopheryl-acetate | ethylhexyl-salicylate | polyethylene |
| cyclopentasiloxane | ethylhexyl-methoxycinnamate | tocopherol | 1-2-hexanediol |
| glyceryl-stearate | octocrylene | xanthan-gum | silica |
세정용 제품
cleanser_ing = prod_char('cleanser')
cleansingfoam_ing = prod_char('cleansing-foam')
cleansingbalm_ing = prod_char('cleansing-balm')
cleansingoil_ing = prod_char('cleansing-oil')
compare = pd.DataFrame(columns=['cleanser','cleansing-foam','cleansing-balm','cleansing-oil'], index=[i for i in range(1,11)])
for idx, row in compare.iterrows():
compare.iloc[idx-1, 0] = (cleanser_ing[:10][idx-1][0])
compare.iloc[idx-1, 1] = (cleansingfoam_ing[:10][idx-1][0])
compare.iloc[idx-1, 2] = (cleansingbalm_ing[:10][idx-1][0])
compare.iloc[idx-1, 3] = (cleansingoil_ing[:10][idx-1][0])
compare| cleanser | cleansing-foam | cleansing-balm | cleansing-oil |
|---|---|---|---|
| water | water | caprylic-capric-triglyceride | caprylic-capric-triglyceride |
| glycerin | glycerin | water | water |
| phenoxyethanol | butylene-glycol | tocopherol | helianthus-annuus-seed-oil |
| citric-acid | disodium-edta | glycerin | tocopherol |
| cocamidopropyl-betaine | myristic-acid | helianthus-annuus-seed-oil | simmondsia-chinensis-seed-oil |
| parfum | stearic-acid | butyrospermum-parkii-butter | olea-europaea-fruit-oil |
| disodium-edta | potassium-hydroxide | ethylhexyl-palmitate | parfum |
| sodium-chloride | lauric-acid | phenoxyethanol | glycerin |
| butylene-glycol | cocamidopropyl-betaine | parfum | peg-20-glyceryl-triisostearate |
| ethylhexylglycerin | sodium-chloride | peg-20-glyceryl-triisostearate | tocopheryl-acetate |
두발용 제품
두발용 제품은 샴푸 혹은 컨디셔너로만 구분이 되어서 간략하게 표시
shampoo_ing = prod_char('shampoo')
conditioner_ing = prod_char('conditioner')
compare = pd.DataFrame(columns=['shampoo','conditioner'], index=[i for i in range(1,11)])
for idx, row in compare.iterrows():
compare.iloc[idx-1, 0] = (shampoo_ing[:10][idx-1][0])
compare.iloc[idx-1, 1] = (conditioner_ing[:10][idx-1][0])
compare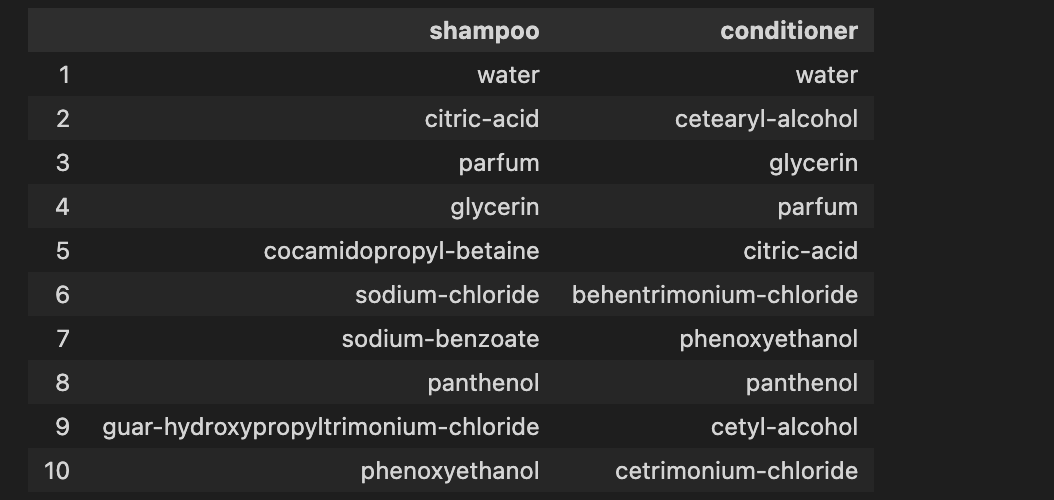
색조 화장품
색조 화장품은 ci-xxxx 성분들이 확연하게 눈에 띈다.
해당 성분들은 colorant effect가 있다.
foundation_ing = prod_char('foundation')
powder_ing = prod_char('powder')
lipstick_ing = prod_char('lipstick')
lipgloss_ing = prod_char('lip-gloss')
lipbalm_ing = prod_char('lip-balm')
compare = pd.DataFrame(columns=['foundation','powder','lipstick','lip-gloss','lip-balm'], index=[i for i in range(1,11)])
for idx, row in compare.iterrows():
compare.iloc[idx-1, 0] = (foundation_ing[:10][idx-1][0])
compare.iloc[idx-1, 1] = (powder_ing[:10][idx-1][0])
compare.iloc[idx-1, 2] = (lipstick_ing[:10][idx-1][0])
compare.iloc[idx-1, 3] = (lipgloss_ing[:10][idx-1][0])
compare.iloc[idx-1, 4] = (lipbalm_ing[:10][idx-1][0])
compare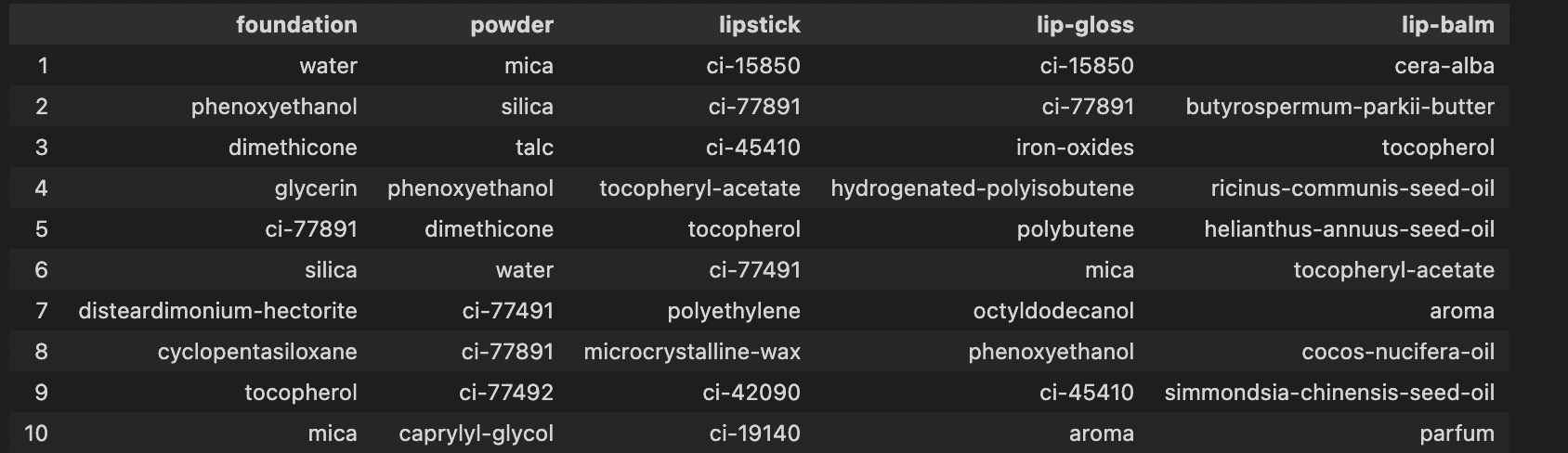
💡 화장품 유형 별 성분 테이블을 만들면서 해당 테이블을 모델 측정 지표로 쓸 수 있지 않을까 생각해봤다! 💡
에센스만 5개 정도 뽑아서 sequence를 확인해볼까?
stop = 0
for idx, row in prod_df.iterrows():
if 'essence' in row['product name']:
print('<',row['product name'],'>')
print(row['formatted ingredients'].split(',')[:10])
print()
stop += 1
if stop == 5:
break
< 001-skincare-rosa-damascena-essence-mist >
['rosa-damascena-flower-water', 'polysorbate-20', 'benzyl-alcohol', 'dehydroacetic-acid', 'rosa-damascena-flower-oil', 'water', 'tocopherol', 'citronellol', 'geraniol', 'methyl-eugenol']
< 1004-laboratory-atvt-bifida-77-hexa-layer-fermentation-essence >
['bifida-ferment-lysate','hydrogenated-polyisobutene', 'glycerin', 'coco-caprylate-caprate', 'niacinamide', 'polyglyceryl-2-stearate', 'glyceryl-stearate', 'sodium-hyaluronate', 'nelumbo-nucifera-flower-water', 'silica']
< 111skin-antioxidant-energising-essence >
['water','glycerin','sorbitol', 'polysorbate-20', 'benzyl-alcohol', 'macrocystis-pyrifera-extract', 'tartaric-acid', 'aloe-barbadensis-leaf-extract', 'tetrahexyldecyl-ascorbate', 'xanthan-gum']
< 23-5degn-rice-soothing-active-essence >
['rice-ferment-filtrate', 'oryza-sativa-extract', 'sodium-hyaluronate', 'carbomer', 'glycerin', 'phenoxyethanol', 'chlorphenesin']
< 2ndesign-first-toner-essence >
['water', 'butylene-glycol', 'glycerin', '1-2-hexanediol', 'betaine', 'glycereth-25-pca-isostearate', 'arginine', 'acrylates-c10-30-alkyl-acrylate-crosspolymer', 'panthenol', 'caprylic-capric-triglyceride']
에센스 top10 성분과 sequence가 매우 상이한 것을 확인됐다. water나 glycerin 정도를 제외하고는 제품마다 본연의 성분 sequence들이 확연했음. 제품 별 성분 카운트 top10 테이블을 정확도 측정 매트리스로 사용하기에는 어려울 수도 있겠다는 생각이 든다~
3-4. 효과 별 성분 랭크
일단, ing_df에서 결측치 처리해주고
ing_df_notnull = ing_df[ing_df['what-it-does'] != "['']"]
ing_df_notnull.reset_index(inplace=True)
ing_df_notnull = ing_df_notnull.iloc[:,1:]
ing_df_notnull성분 테이블 컬럼에 효과가 추가된 새로운 테이블 effect를 만들고~
effect = pd.merge(ing_cnt_df, ing_df_notnull, how='left', left_on='ing' ,right_on='formatted ingredients').drop(['ingredients'], axis=1).drop_duplicates().reset_index().iloc[:,1:]
effect = effect[['formatted ingredients', 'what-it-does', 'cnt']]
effect.dropna(inplace=True)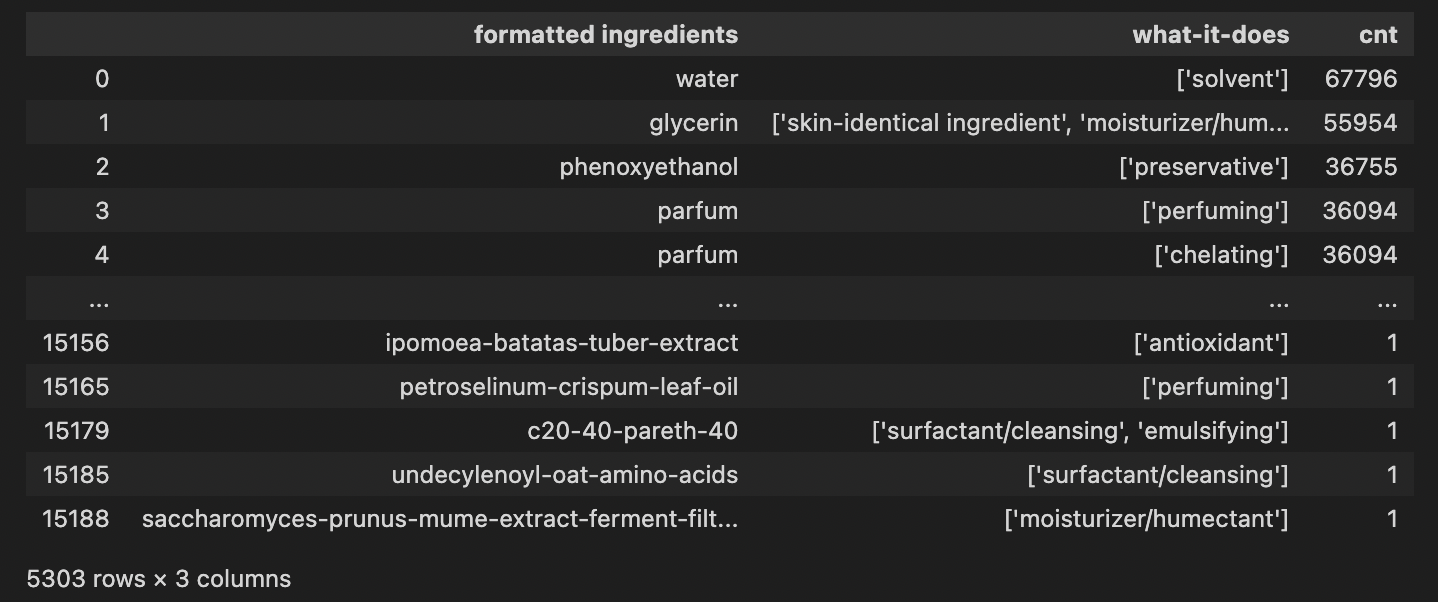
이제 각 효과 별 성분을 매칭시켜주고
예를 들어 solvent = [water, water1, ... ]
effect_rank = defaultdict(int)
for row in effect['what-it-does']:
try:
for ing in row.split(','):
ing_ = ing.replace('[','').replace(']','').replace("'",'').strip()
effect_rank[ing_] = defaultdict(int)
except:
print(row)
for idx, row in effect.iterrows():
for key in [key for key in effect_rank.keys()]:
if key in row['what-it-does']:
effect_rank[key][row['formatted ingredients']] = row['cnt']그 중에 top20만 내림차순 정렬!
effect_rank_top20 = defaultdict(int)
for key in effect_rank.keys():
effect_rank_top20[key] = (sorted(effect_rank[key].items(), key=lambda x:x[1], reverse=True)[:20])결과를 출력해보자
for k, v in effect_rank_top20.items():
print('[',k,']')
for ing, cnt in v[:5]:
print(ing, cnt)
print()
[ solvent ]
water 67796
butylene-glycol 24942
1-2-hexanediol 13093
propylene-glycol 12806
limonene 12711
[ skin-identical ingredient ]
glycerin 55954
sodium-hyaluronate 19878
squalane 7051
arginine 5091
sodium-pca 4300
[ moisturizer/humectant ]
glycerin 55954
butylene-glycol 24942
sodium-hyaluronate 19878
caprylyl-glycol 16992
panthenol 15715
[ preservative ]
phenoxyethanol 36755
ethylhexylglycerin 23514
sodium-benzoate 14899
...
[ *Fragrance ]
bha 412원하는 결과가 나오긴 했는데 ,, 여기서도 딱히 인사이트는 못찾겠다.
4. 결과 정리
📌 어떤 성분들이 화장품 제조에 많이 쓰이는지 확인 완료.
📌 화장품 유형 별로 어떤 성분들이 많이 쓰이는지 확인 완료. i.e) 자외선 차단제에서는 sunscreen effect를 가진 성분들, 색조 화장품에서는 colorant effect를 가진 성분들 , ..
📌 effect 별로 어떤 성분들이 많이 쓰이는지 확인 완료.💡 이제 성분들을 어떻게 벡터라이징 하여 모델에 돌려볼지 고민해보자! 이후 다시 EDA 작업으로 돌아오자 ~ 💡
