유사 화장품 추천 프로젝트
03. 유사도 측정 ver.1 📊📄
📝 목차
- 카운트 기반의 단어 표현
- DTM
- 유사도 측정
3-1. Shuffle & Sampling
3-2. Euc Distance
3-3. Cos Similarity
3-4. Accuracy- Next
1. 카운트 기반의 단어 표현
📌 문장 간의 유사도 측정
- 수치화
텍스트를 수치화 하고나면, 통계적인 접근 방법을 통해 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내거나, 문서의 핵심어 추출, 검색 엔진에서 검색 결과의 순위 결정, 문서들 간의 유사도를 구하는 등의 용도로 사용할 수 있다.
유원준, 딥러닝을 이용한 자연어 처리 입문, (위키독스, 2022)
본 프로젝트에서는 화장품 전성분 리스트를 카운트 기반으로 수치화하여 유사도를 측정할 예정
1) 전성분 리스트가 하나의 문장이 되는 것이고
2) 각 전성분들이 하나의 토큰화된 단어 역할
2. DTM
📌 문서 단어 행렬(Document-Term Matrix, DTM)
- 문서 단어 행렬(Document-Term Matrix, DTM)이란 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것을 말한다. 쉽게 생각하면 각 문서에 대한 BoW를 하나의 행렬로 만든 것으로 생각할 수 있으며, BoW와 다른 표현 방법이 아니라 BoW 표현을 다수의 문서에 대해서 행렬로 표현하고 부르는 용어다.
유원준, 딥러닝을 이용한 자연어 처리 입문, (위키독스, 2022)
각 문서에서 등장한 단어의 빈도를 행렬의 값으로 표기한다.
-> 각 화장품의 전성분 리스트를 개별 조회하여 전성분 빈도를 행렬 값으로 표기
문서 단어 행렬은 문서들을 서로 비교할 수 있도록 수치화할 수 있다.
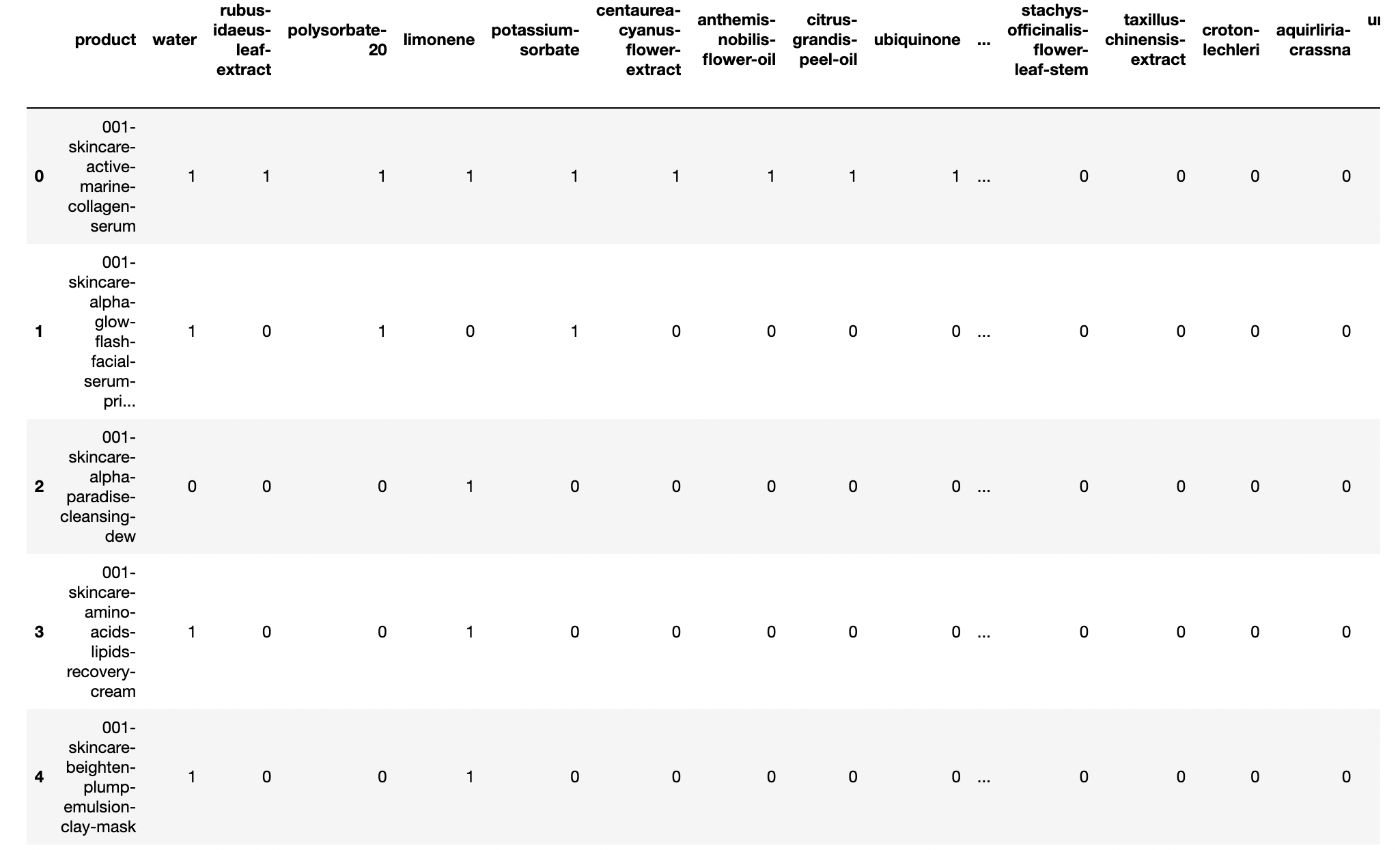
Cols: 15,187 (개별 Ingredient)
Rows: 77,000 (개별 Product)
한 화장품에 동일 성분이 중복되어 사용되는 경우는 없다.
따라서 성분이 화장품에 들어갔냐(1), 안들어갔냐(0)으로만 구분되어 행렬이 완성됐다.
각 Row들은 해당 화장품의 전성분 리스트를 벡터화한 수치가 됐다.
예시로 5개 정도의 화장품만 출력해보자.
매트릭스에서 화장품 이름과 벡터 값을 추출하는 함수를 get_Vector로 만들었다.
def get_vector(idx):
return pd.Series(test.iloc[idx].to_numpy())[0], pd.Series((test.iloc[idx].to_numpy())[1:])
for i in range(5):
product_name, vec = get_Vector(matrix, i)
print(product_name)
print(vec[:10]) # 15,187개를 모두 나열할 수 없으니 10개만
print()
output:
loreal-elvive-volume-filler
[1, 0, 0, 1, 0, 0, 0, 0, 0, 0]
loreal-even-complexion
[1, 0, 0, 1, 0, 0, 0, 0, 0, 1]
loreal-ever-pure-moisture-shampoo
[1, 0, 0, 1, 0, 0, 0, 0, 0, 0]
loreal-ever-pure-scalp-scrub
[1, 0, 0, 1, 1, 0, 0, 0, 0, 0]
loreal-ever-strong-sulfate-free-thickening-shampoo
[1, 0, 0, 1, 0, 0, 0, 0, 0, 0]3. 유사도 측정
문장이나 문서의 유사도를 구하는 작업은 자연어 처리의 주요 주제 중 하나이다. 사람들이 인식하는 문서의 유사도는 주로 문서들 간에 동일한 단어 또는 비슷한 단어가 얼마나 공통적으로 많이 사용되었는지에 의존한다. 기계도 마찬가지다.
기계가 계산하는 문서의 유사도의 성능은 각 문서의 단어들을 어떤 방법으로 수치화하여 표현했는지(DTM, Word2Vec 등), 문서 간의 단어들의 차이를 어떤 방법(유클리드 거리, 코사인 유사도 등)으로 계산했는지에 달려있다.
유원준, 딥러닝을 이용한 자연어 처리 입문, (위키독스, 2022)
3-1. Shuffle & Sampling
위에서 만든 DTM은 대략 2gb의 매우 무거운 데이터 프레임이다.
만약 77,000개의 화장품을 모두 유사도 측정에 사용하게 된다면?
- 현재 우리 팀이 작성한 코드는 시간복잡도가 을 따른다.
- 77,000개의 화장품을 모두 사용하게 될 시 너무 많은 시간이 소요됨을 확인했다. (속도 관련 이슈는 향후 개선해야 할 허들 .. 😭)
- 따라서 데이터 프레임을 Random_Seed를 지정한 후 Shuffle 하기로 했다.
- Shuffle된 데이터 프레임에서 샘플로 10% 가량을 떼어낸 후
- 해당 샘플을 테스트에 사용하기로 하였다.
다행히 pandas에서는 sample이라는 함수를 제공한다.
이를 통해 손쉽게 셔플할 수 있다.
Pandas 공식 홈페이지

shuffled_matrix = matrix.sample(n=7000, random_state=56)
shuffled_matrix.to_csv('shuffled_matrix.csv')매개변수 n에는 7,000(77,000의 대략 10%), random_state에는 56을 두어 셔플 완료했다. 이후 저장!
test = pd.read_csv('/Users/kanghyuntae/Documents/프로젝트/유사도 테스트/shuffled_matrix.csv', index_col=0)
test.rename(columns={'Unnamed: 0':'product'}, inplace=True)
test.head(3)
잘 된 것 같다. 이제 유사도를 측정해보자.
3-2. Euclidean Distance

여러 문서에 대해서 유사도를 구하고자 유클리드 거리 공식을 사용한다는 것은, 앞서 본 2차원을 단어의 총 개수만큼의 차원으로 확장하는 것과 같다.
유원준, 딥러닝을 이용한 자연어 처리 입문, (위키독스, 2022)
- 다차원 공간에서 두 점 p와 q사이의 거리를 구하는 것
- 두 점 사이의 거리는 피타고라스 공식을 통해서 쉽게 구할 수 있다.
DTM 등의 행렬을 통해서 문서의 유사도를 구하는 경우에는 해당 행렬이 각각의 특징 벡터 A, B가 된다.
우리는 77,000개의 화장품에 대해서 유사도를 구할 예정이다.
전성분의 개수인 15,187개만큼 차원을 확장한다.
따라서 A라는 화장품과 가장 유사한 화장품을 예측하고자 한다면?
- A 화장품을 15,187 차원 공간에서 77,000개의 화장품들과 비교하며 유클리디안 거리를 구한다.
- 유클리드 거리의 값이 가장 작다는 것은 화장품 간 거리가 가장 가깝다는 것을 의미한다.
- 즉 가장 값이 작은 화장품이 A 화장품과 가장 유사한 화장품 예측값이 된다.
📌 실제로 구현해보자!
화장품의 벡터값과 유클리디안 거리를 구하는 함수를 만들어주자.
def get_vector(idx):
return pd.Series(test.iloc[idx].to_numpy())[0], pd.Series((test.iloc[idx].to_numpy())[1:])
def euc_dist(x,y):
return round(np.sqrt(np.sum((x-y)**2)),3)처음에는 유사도를 구할 때 마다 get_vecotr 함수를 써왔다.
그런데 속도에 큰 문제가 있는 것으로 판단, 미리 모든 화장품 이름과 벡터값을 구해놓기로 했다.
from collections import defaultdict
name_vec_dic = defaultdict(int)
for i in tqdm_notebook(range(7000)):
pname, vec = get_vector(i)
name_vec_dic[pname] = vec본격적으로 유클리디안 거리를 기반으로 유사한 화장품 예측 시작!
그런데 7,000개의 화장품을 모두 확인하려니 예상 시간이 대략 130시간을 상회했다.
시간 상의 문제로 중간에 루프를 강제로 멈춘 후 결과를 확인해보았다.
key_lst = list(name_vec_dic.keys())
sim_dic = defaultdict(int)
n = len(key_lst)
for i in tqdm_notebook(range(n)):
min_euc = 1e9
for j in tqdm_notebook(range(n)):
if i != j:
pname_i = key_lst[i]
pname_j = key_lst[j]
euc = euc_dist(name_vec_dic[pname_i], name_vec_dic[pname_j])
if euc < min_euc:
min_euc = euc
sim_dic[pname_i] = (pname_j, euc)소량의 결과만으로 유클리디안 거리 접근으로는 문제가 있다는 것을 확인했다.
예를 들어 아래 코드 output의 Case A를 보자.
skin-mask와 powder가 가장 유사하다는 결과를 도출했다.
또 Case C의 경우는 cleansing-oil과 loccitane의 skin용 cosmetic이 유사하다는 결과를 도출했다.
몰론 7,000개가 아닌 77,000개 전체와 비교했을 때 보다 정확한 화장품이 존재할 수도 있다.
하지만 샘플링을 하기 전 셔플을 실행했기에 표본이 대표성을 띄고 있다고 판단했다.
더 중요한 것은 전체 컬럼 개수(즉, 성분 개수)는 15,000개를 넘는다.
하지만 가장 많은 성분을 지닌 화장품이라 해봐야 그 전성분 리스트의 길이가 50을 넘지 못한다.
15,000개 중 20개의 성분을 지닌 화장품, 30개의 성분을 지닌 화장품 , ... 등등을 비교해도 큰 의미가 없다는 판단을 하게 되었다.
sim_dic
output:
# A
'joah-skin-polish-gold-peel-off-mask':
('w7-tokyo-rice-powder', 5.0)
# B
'uriage-thermal-micellar-water-for-normal-to-dry-skin':
('vcbella-tonico-facial', 2.828)
# C
'shu-uemura-skin-purifier-ultime8-sublime-beauty-cleansing-oil':
('loccitane-shea-butter-organic-certified', 5.0),
# D
'qms-medicosmetics-qms-tinted-day-cream':
('calvin-klein-euphoria', 6.403),
# E
'planet-revolution-grapefruit-brightening-cleansing-water':
('math-scientific-b5-recovery', 3.317),
# F
'erno-laszlo-phormula-3-9-repair-serum':
('sinoz-24k-altin-yuz-bakim-serumu', 5.568),
# G
'ulta-healthy-hydration-lip-sleeping-mask':
('malin-goetz-resurfacing-glycolic-acid-pads', 4.899)3-3. Cosine Similarity
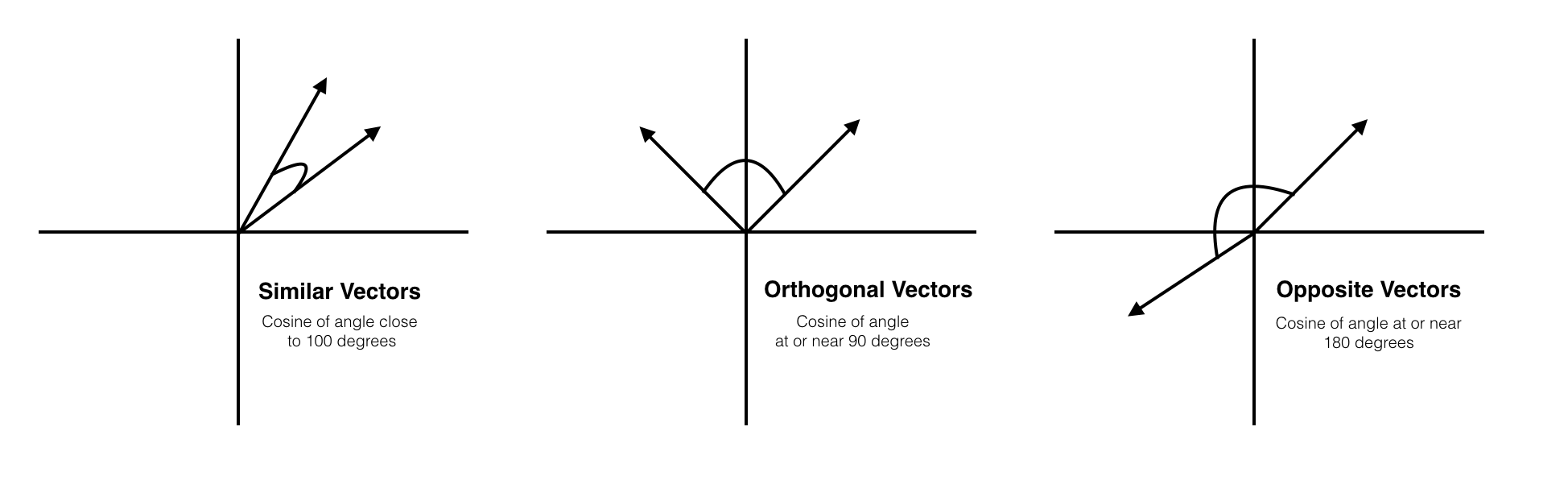
코사인 유사도는 두 벡터 간의 코사인 각도를 이용하여 구할 수 있는 두 벡터의 유사도를 의미한다. 두 벡터의 방향이 완전히 동일한 경우에는 1의 값을 가지며, 90°의 각을 이루면 0, 180°로 반대의 방향을 가지면 -1의 값을 갖게 된다.
즉, 결국 코사인 유사도는 -1 이상 1 이하의 값을 가지며 값이 1에 가까울수록 유사도가 높다고 판단할 수 있다. 이를 직관적으로 이해하면 두 벡터가 가리키는 방향이 얼마나 유사한가를 의미한다.
유원준, 딥러닝을 이용한 자연어 처리 입문, (위키독스, 2022)
유클리디안 거리를 구할 때와 동일한 프로세스를 거친다.
미리 구해놓은 Product_name, Vector 사전을 이용하여 매 루프마다 가장 유사한 화장품을 예측한다.
key_lst = list(name_vec_dic.keys())
sim_dic = defaultdict(int)
n = len(key_lst)
for i in tqdm_notebook(range(n)):
max_cos = 0
for j in tqdm_notebook(range(n)):
if i != j:
pname_i = key_lst[i]
pname_j = key_lst[j]
cos = cos_sim(name_vec_dic[pname_i], name_vec_dic[pname_j])
if cos > max_cos:
max_cos = cos
sim_dic[pname_i] = (pname_j, cos)이번에는 꽤 그럴싸한 예측들이 나왔다. 대표적인 예시만 몇개 확인해 본다면
먼저, serum-serum/ cream-balm
처럼 비슷한 제형/ 유형의 화장품들끼리 Pair됨을 확인했다.
sim_dic
output:
# A
'biodermal-pure-balance-skin-boosting-serum':
('aco-25-protect-restore-serum', 0.951)
# B
'symbiosis-london-glycolic-lactic-acids-ultimate-resurfacing-12-hour-duo-moisturiser':
('avant-skincare-intensive-redensifying-glycolic-acid-day-moisturizer', 0.946)
# C
'la-roche-posay-cicaplast-baume-b5-soothing-therapeutic-multi-purpose-cream':
('mixa-cica-repair-balm', 0.951)몰론 Cosine-Similarity 접근에서도 유사도 0.2~3 수준으로 Pair된 경우도 많았다.
유클리디안 거리 때와 마찬가지로 나머지 70,000개 속에 반례가 있을 수 도 있고, 아니면 예측 자체가 틀렸을 수도 있다.
다만 위 사례같이 신빙성 있는 예측값들이 나오는걸 통해, 전성분 나열표를 통한 유사 제품 추출 접근이 시도해볼만한 가치가 있음을 확인했다.
그런데 ,, 신빙성
신빙성을 어떻게 확인하지?
3-4. Accuracy
Input으로 화장품과 해당 화장품의 전성분 나열표를 넣는다.
Output으로 Input 화장품과 가장 유사한 화장품이 예측된다.
그런데, 그 예측값이 정말 유사한 화장품인지 어떻게 확인할 수 있을까?
📌 Quantitative analysis
전성분 나열표를 직접 확인해보자.
정말로 두 화장품의 성분이 비슷하게 구성되었는지 확인해보는 것이다.
화장품과 그 전성분이 담긴 데이터를 불러온다.
이후 제품별 전성분을 비교해주는 함수를 만들어줬다.
prd_ing = pd.read_csv('./data/inci_prod_final.csv',index_col=False)
def get_inglst(name):
df = prd_ing[prd_ing['product name']==name]
inglst = []
tmp = list(df['formatted ingredients'])
for txt in tmp[0].split("'"):
if "," not in txt and "[" not in txt and "]" not in txt:
inglst.append(txt)
return inglst
def compare_prods(pname1,pname2):
prd1,prd2 = get_inglst(pname1),get_inglst(pname2)
union = list(set(prd1) | set(prd2))
interx = list(set(prd1) & set(prd2))
uq1 = list(set(prd1) - set(prd2))
uq2 = list(set(prd2) - set(prd1))
return union, interx, uq1, uq2전성분 리스트간 합집합, 여집합 비교를 통해 전성분간 유사도를 확인했다.
union, interx, unique1, unique2 = compare_prods('제품1','제품2')
print()
print('Total # of Ingredients:',len(union))
print('Total # of Common Ingredients:',len(interx))
print('Product A # of Unique:', len(unique1))
print('Product B # of Unique:', len(unique2))위에서 확인했던 Cos_Similarity의 Case A,B,C를 비교해봤다.
실제로 거의 똑같거나, 약간의 차이만 있을 뿐 전성분들이 비슷했다.
Product A: biodermal-pure-balance-skin-boosting-serum
Product B: aco-25-protect-restore-serum
Total Num of Ingredients: 22
Total Num of Common Ingredients: 22
Product A Num of Unique: 0
Product B Num of Unique: 0
Product A: symbiosis-london-glycolic-lactic-acids-ultimate-resurfacing-12-hour-duo-moisturiser
Product B: avant-skincare-intensive-redensifying-glycolic-acid-day-moisturizer
Total Num of Ingredients: 64
Total Num of Common Ingredients: 58
Product A Num of Unique: 3
Product B Num of Unique: 3
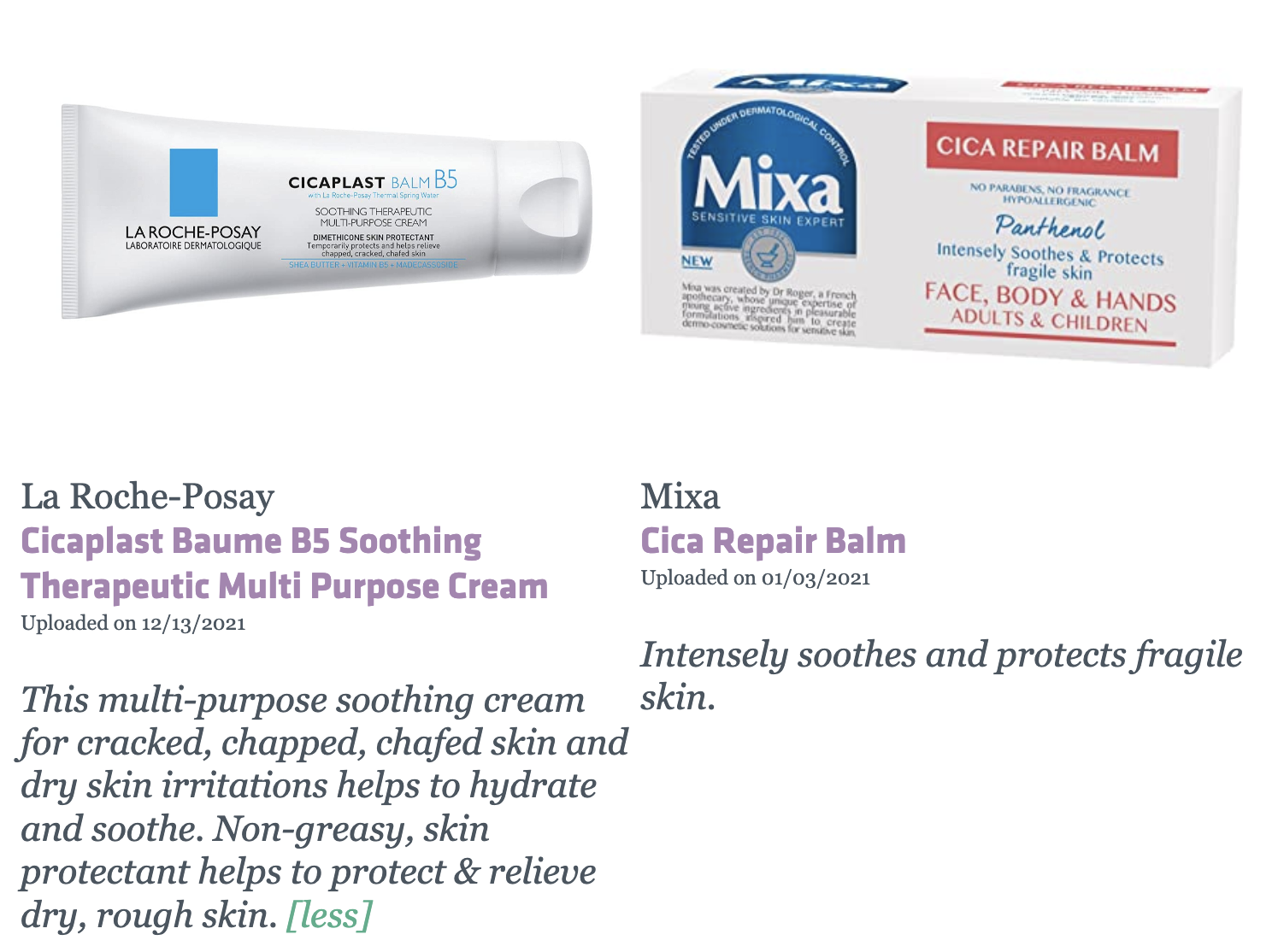
Product A: la-roche-posay-cicaplast-baume-b5-soothing-therapeutic-multi-purpose-cream
Product B: mixa-cica-repair-balm
Total Num of Ingredients: 29
Total Num of Common Ingredients: 26
Product A Num of Unique: 2
Product B Num of Unique: 1📌 Qualitative analysis
이번에는 유사한 두 화장품을 직접 Description을 보며 비교해봤다.
- Case A

- Case B

- Case C
4. Next
지금까지 텍스트를 어떻게 비교할 수 있는지 알아보았다.
가장 기초적으로 수치화를 통한 기하학적 접근을 시도했다.
만족스러운 결과는
- 단순 Count 기반임에도 의미있는 결과들이 나온 점
아쉬운 결과는
- 그럼에도 역시 부족함을 드러내는 반례들이 있었다는 점
- 시간복잡도 개선 실패로 Task를 수행하는데 너무 많은 시간이 소요된 점
그러나, 가장 중요한 것은 순서/위치(Position)에 있다.
화장품 전성분 리스트는 그냥 무작위로 나열된 것이 아니라, 그 함량에 따라 나타난다.
즉 가장 높은 함유량을 보이는 순으로 전성분이 나열된 것이다.
따라서 그 순서/위치(Position)가 중요한데, 이번 케이스에서는 단순히 빈도만 체크했다.
다음 Task는?
📌 순서/위치(Position)를 고려한 벡터화
📌 새로운 백터를 통한 유사도 측정
