유사 화장품 추천 프로젝트
프로젝트 중간 발표 🧑🏻💻📋
📝 목차
- 중간 결과 보고
- 데이터 소개
- 데이터 수집
- EDA
- 유사도 측정
5-1. 행렬 변환 및 모델 실행 준비
5-2. 측정 결과 정확도 확인- 한계 및 다음 단계
1. 중간 결과 보고
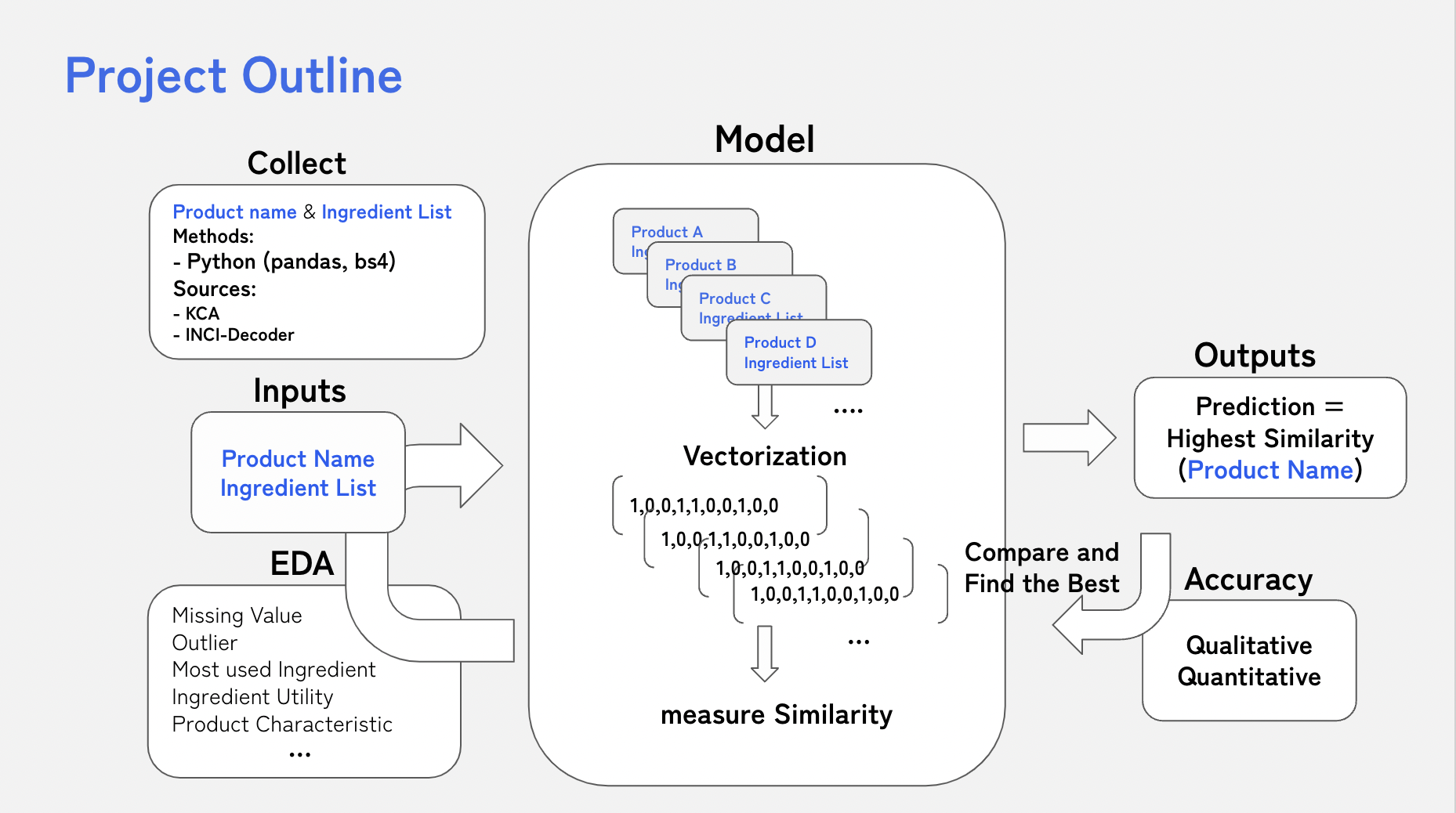
📌 프로젝트의 전체적인 흐름
먼저, Input Data로 화장품과 해당 화장품의 전성분표가 필요
파이썬을 활용하여 KCA, INCI-Decoder라는 웹사이트에서 데이터를 수집
모델에 Input하기 전, 간단한 EDA 과정을 거쳤고
결측치, 이상치, 가장 많이 쓰인 성분, 성분 효능, 화장품별 특성등을 확인
이후 Input Data를 모델에 넣게 되면 수치화, 즉 벡터화
수치화를 통해 숫자 값이 되면 비교 가능
이를 통해 유사도를 측정하여 가장 높은 유사도를 보인 제품을 Output으로 추출
마지막으로 Output 값을 질적, 양적 분석을 통해 정확도 판단.
그리고 수치화, 유사도 측정의 방법을 여러가지로 시도 해보며 최적의 방법을 선정하여 실제 유사한 화장품을 추천하는 것이 목표이다.
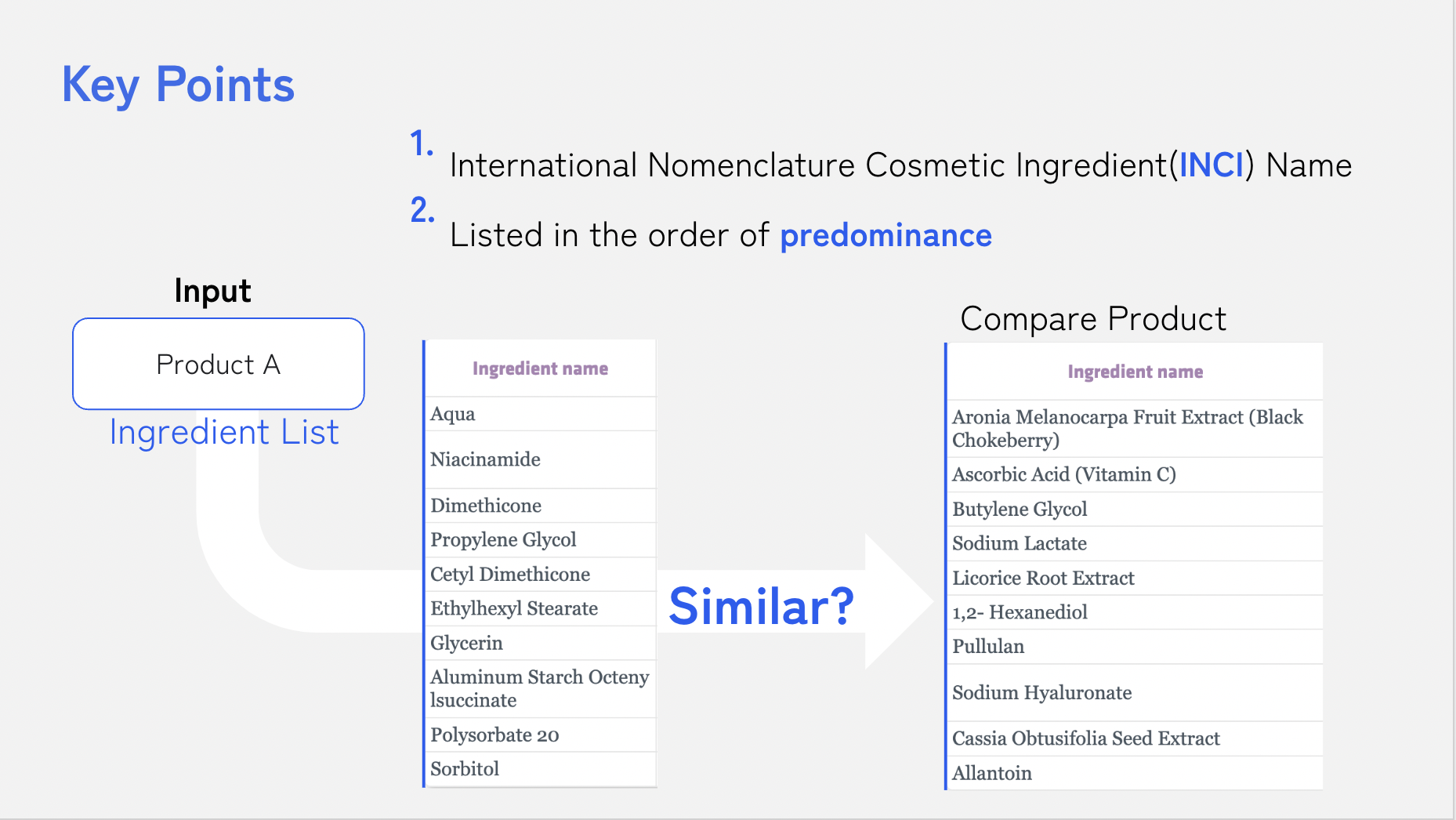
📌 전성분표의 필요성
각 화장품은 함유하고 있는 성분을 모두 나열하게 되어 있다.
이 성분명은 INCI-Name이라는 국제 표기명으로 통일
또한 함유량이 높은 순서대로 내림차순 정렬
따라서 규격이 통일된 성분 리스트들을 비교하여 유사도를 예측할 수 있다고 판단했다.

📌 수치화(벡터화) 작업
성분 리스트 같은 텍스트를 비교하기 위해서는 수치화 작업이 필요.
수치화를 하게되면 N차원 평면 위에 좌표로 표시하는게 가능하고, 비교가 가능
이번 단계에서는 간단하게 빈도수(카운트) 기반으로 매트릭스를 구성했다.
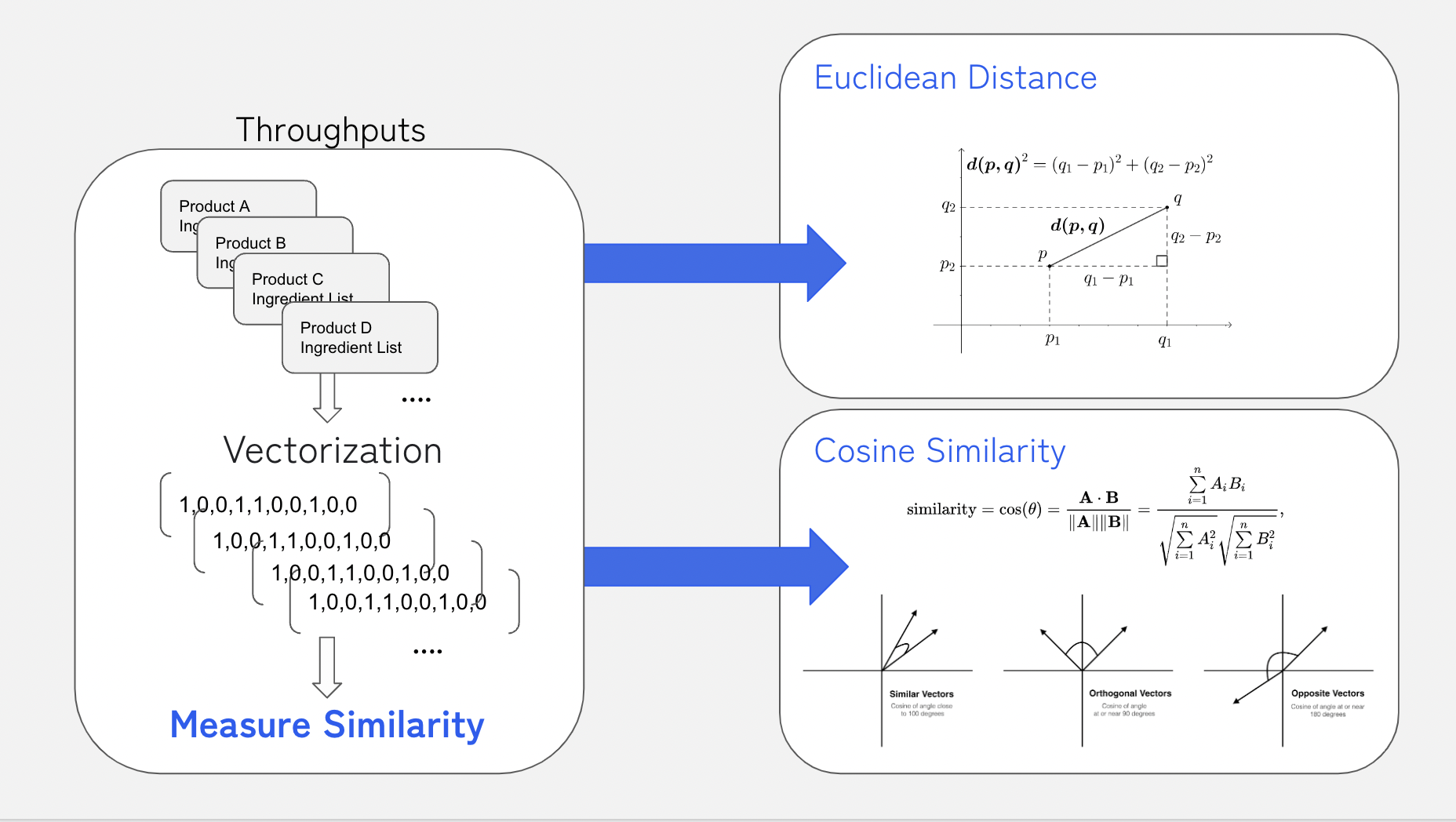
📌 유사도 측정
전성분 벡터들을 비교하기 위해 유클리디안 거리와 코사인 유사도를 선택
유클리디안 거리는 단순히 좌표 평면상의 거리
코사인 유사도는 각도의 유사함을 측정하는 방법

📌 케이스 스터디
동일한 제품에 대해 유클리디안, 코사인 결과 값이 상이하게 도출됨
마스크 제품에 대해 유클리디안에서는 파우더를, 코사인에서는 동일하게 마스크 유형 제품을 추출
따라서 코사인 유사도가 보다 의미있는 성과를 보인다고 판단하였다.
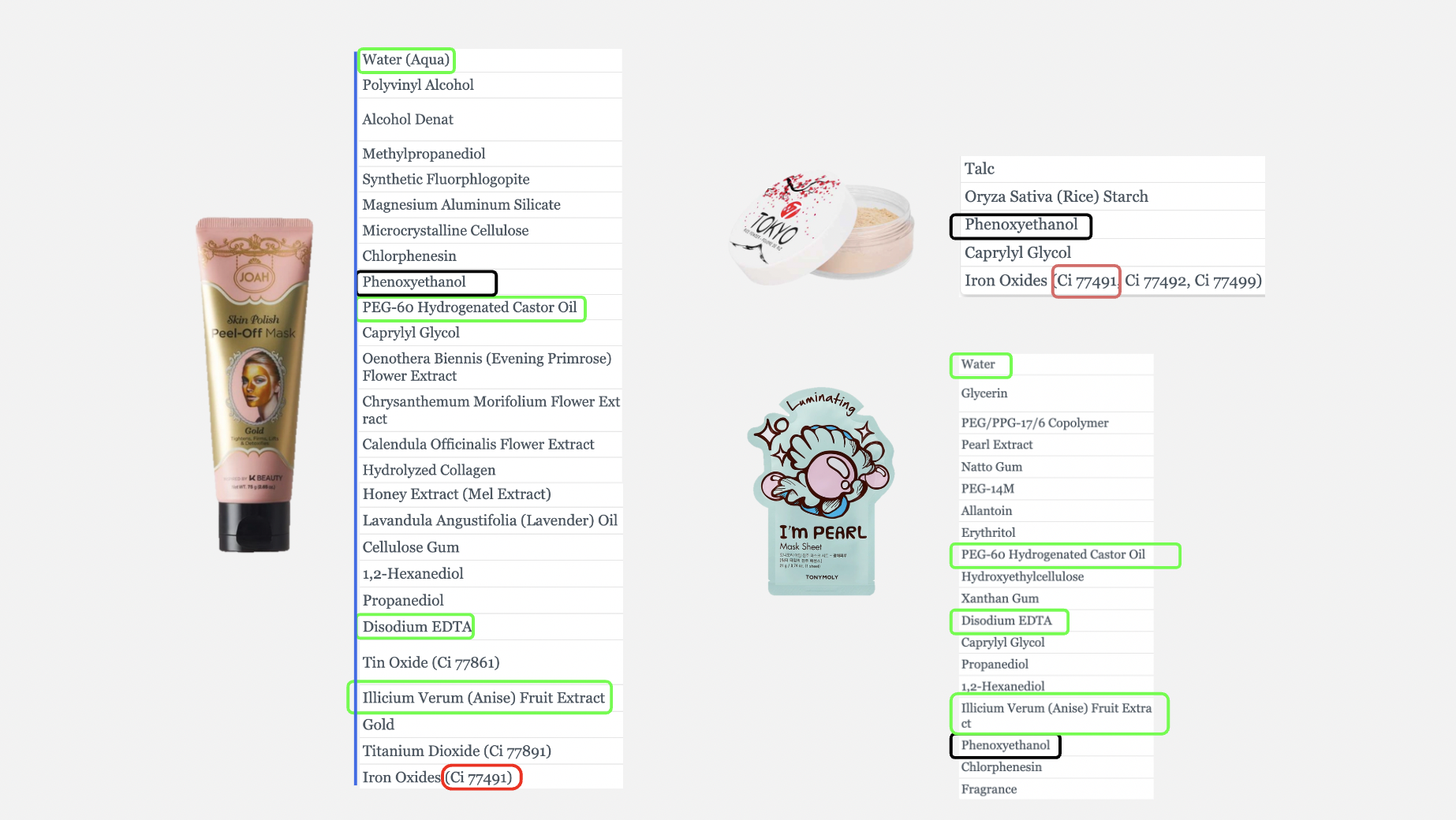
검정 박스는 세 제품, 빨간 박스는 마스크&파우더, 초록 박스는 마스크&마스크에 공통으로 함유된 성분
실제로 각 제품들의 성분표를 직접 비교해보았음.
- 페녹시 에탄올은 세 제품에서 모두 동일하게 함유
- 유클리디안의 결과값인 파우더는 제품 유형도 다를 뿐 더러 공통으로 함유하고 있는 성분 역시 색조 효과를 내는 성분 하나 뿐
- 반면, 코사인 유사도에서는 동일한 마스크류 제품이었고 겹치는 성분 또한 다수 존재했다.
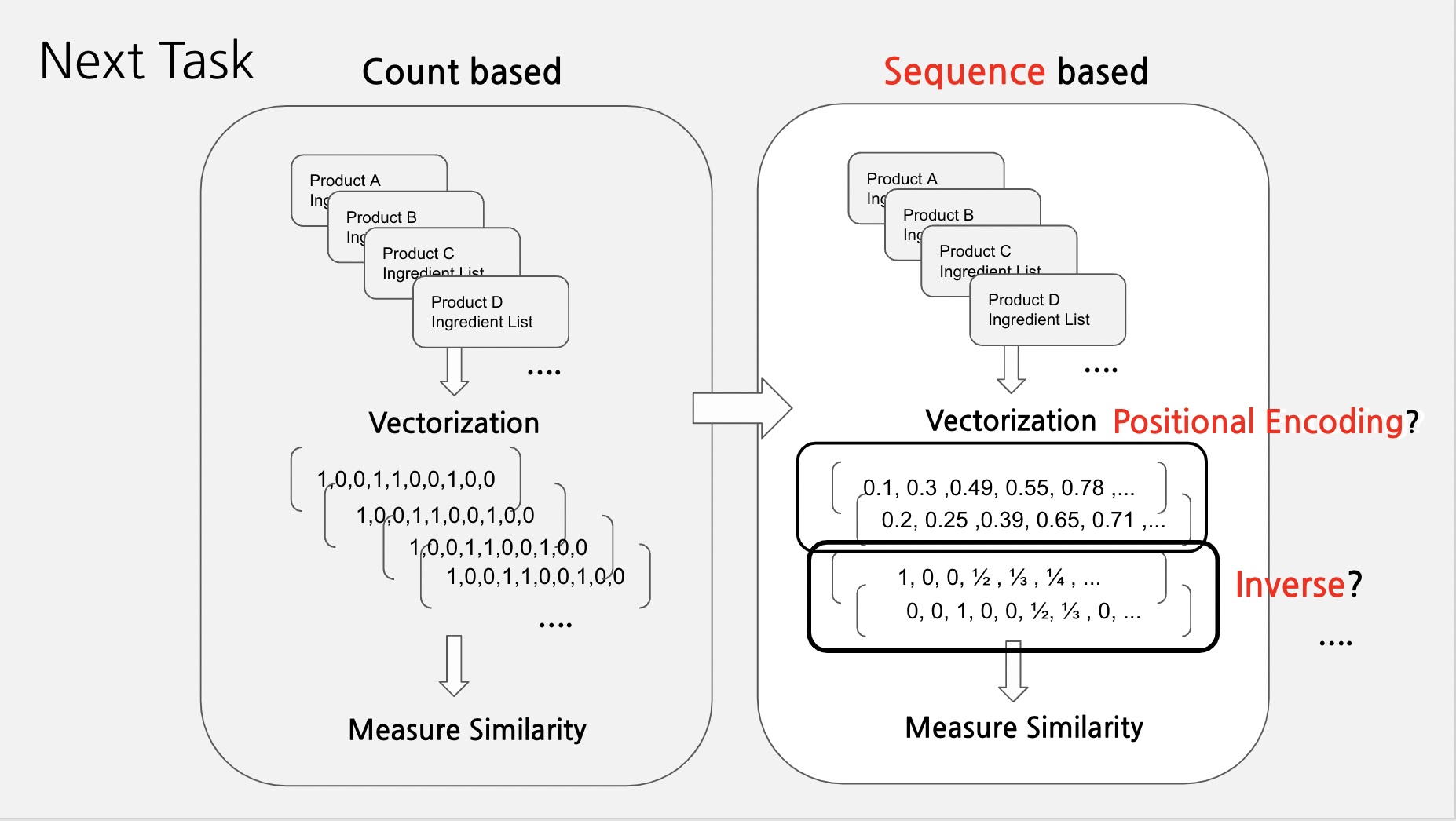
📌 다음 Task?
앞서 말했듯이 화장품 전성분표의 순서는 의미를 내포함(함유량 높은 순)
이번 단계에서는 단순 카운트 기반이었기 때문에 다음 task로는 순서를 고려한, 조금 더 develop된 방법으로 벡터라이즈를 진행할 예정
2. 데이터 소개

📌 Product Table
총 77,000개의 데이터.
컬럼은 총 3개로 화장품이름, 해당 화장품의 성분 리스트, 수정한 표기명
데이터를 수집해온 INCI-Decoder에서 aqua, water와 같은 동일한 성분을 다른 표기명으로 표기한 경우가 있었음, 따라서 이러한 성분들의 표기를 통일한 데이터를 만들었다.
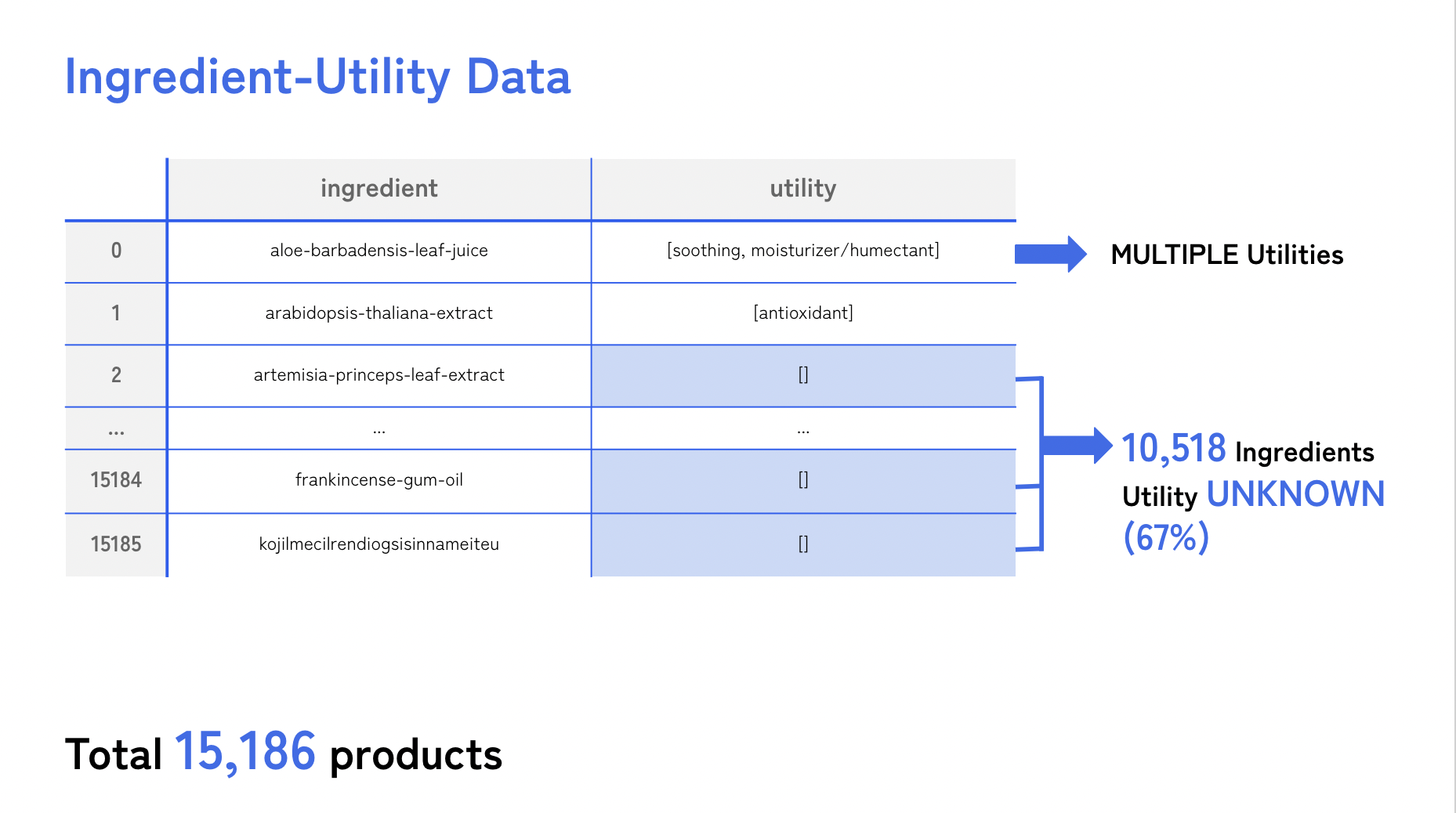
📌 Ingredient Table
총 15,186개의 데이터.
컬럼은 총 2개의 컬럼으로 성분명, 해당 성분의 효능
그 중 전체에서 67%를 차지하는 10,518개의 데이터가 효능이 표기되어 있지 않음
또한 한 가지의 효능만 가지고 있지 않고 여러 효능을 보유한 성분들도 존재했다.
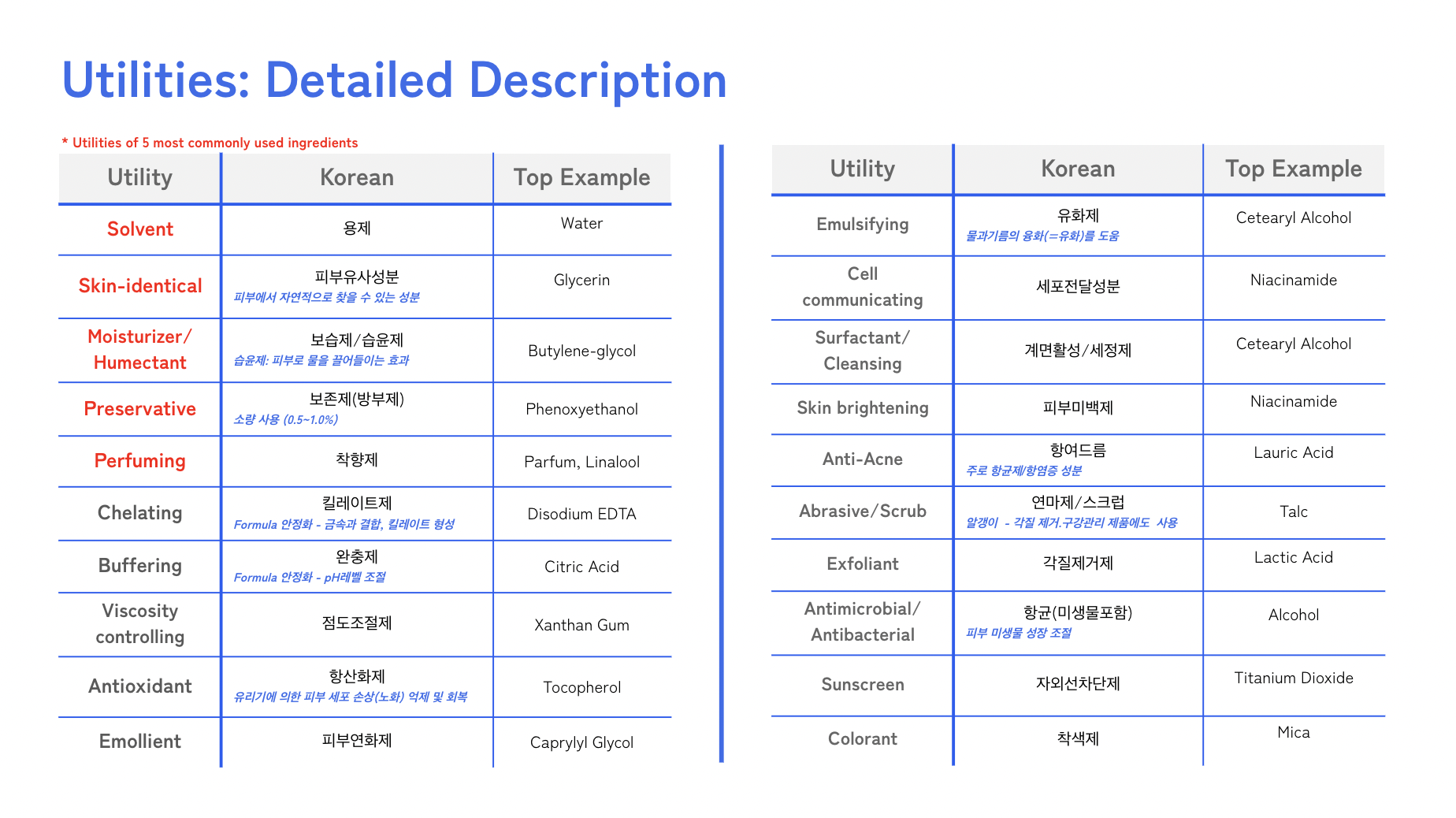
📌 Effect Description
화장품 성분들이 지니는 효과를 기록한 표.
각 효과의 한글 이름과 대표적으로 쓰이는 성분이 기재되어 있음.
3. 데이터 수집
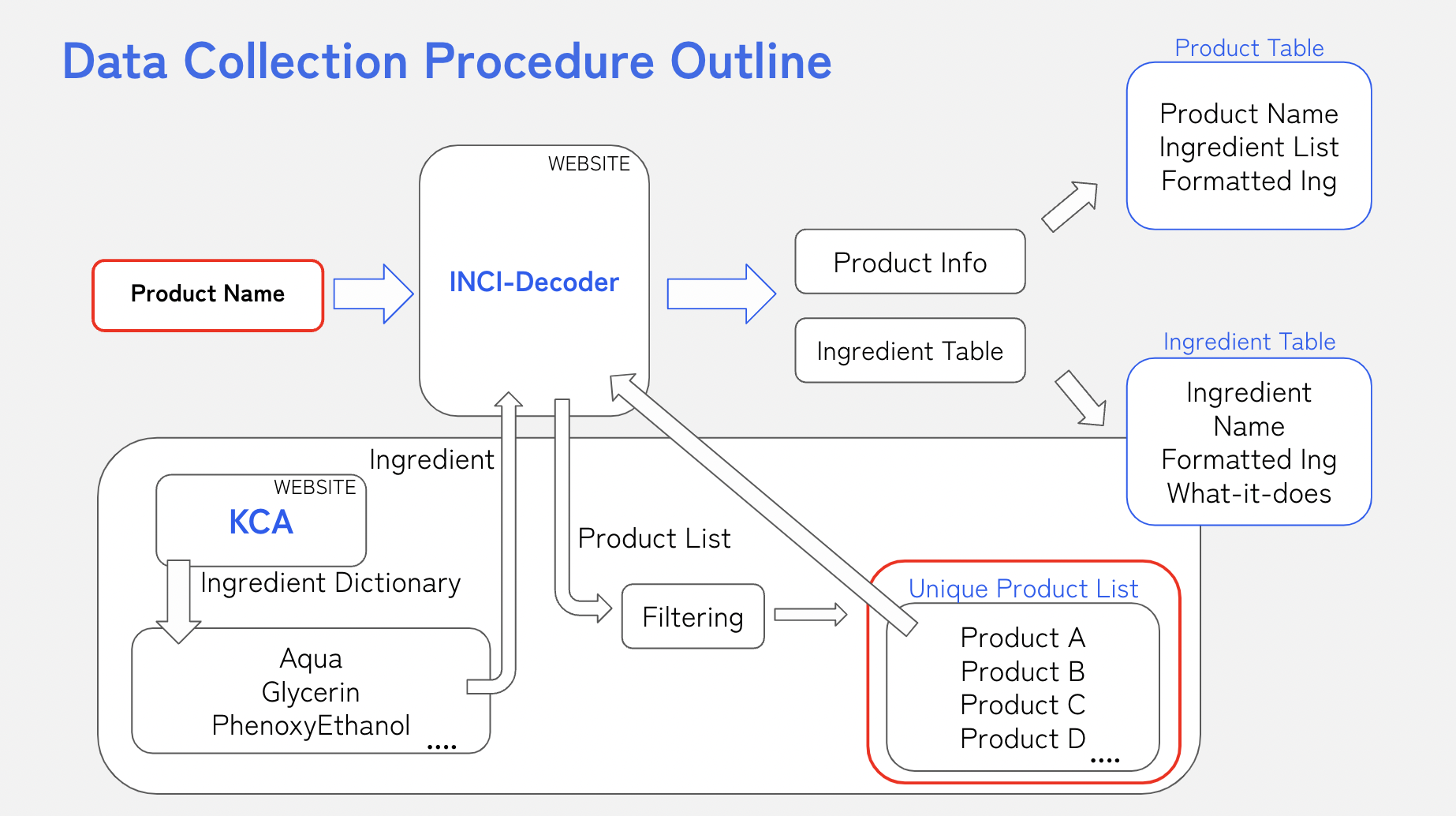
최종 목표는 화장품 제품명과 제품별 전성분 리스트의 수집.
이를 위해서
- 1차적으로 KCA, 즉 대한화장품협회에서 제공하는 성분사전에서 화장품 성분의 영문이름 목록을 수집
- 수집한 화장품 성분 영문명을 인시디코더에서 검색, 각 성분을 함유한 제품 목록을 수집
- 마지막으로, 제품 목록에서 중복데이터를 제거 한 후 각 제품명을 인시디코더에서 검색하여 제품별 전성분 리스트 데이터를 완성
자세한 과정은 [ 유사 화장품 추천 프로젝트 ] 01. 데이터 수집에 기록되어 있음.
4. EDA

📌 결측치와 이상치
-
Product Table
전성분이 누락된 제품은 없었지만, 전성분이 1개 또는 2개인 제품들이 약 300개
해당 제품들을 이상치로 판단하고 처리할지 고민해 보았지만, 전성분 길이가 유사도 측정에 미치는 영향을 아직 가늠할 수 없기 때문에 우선 별다른 처리 없이 유지 -
Ingredient Table
약 15000개 중 33%만 성분에 대한 효능이 명시되어있음.
성분별 효능보다는 각 제품별 전성분 데이터를 활용하고자 했음.
따라서 효능데이터 결측치는 이번 프로젝트에 크게 영향을 미치지 않는다고 판단
이상치의 경우, 과반수 이상의 제품에 공통적으로 포함된 성분은 물과 글리세린 두가지. 그 반대로 단 한가지 제품에만 사용된 성분들이 약 30%에 달했다.

📌 Common Ingredients TOP5
Top5 성분들의 통계적 수치, 효능 등이 기재되어 있음.
눈여겨 볼 것은 Phenoxyethanol의 Max concentration은 1%.
즉, 전성분표에서 Phenoxyethanol 뒤에 나열된 성분들은 함량이 모두 1% 미만인 것.
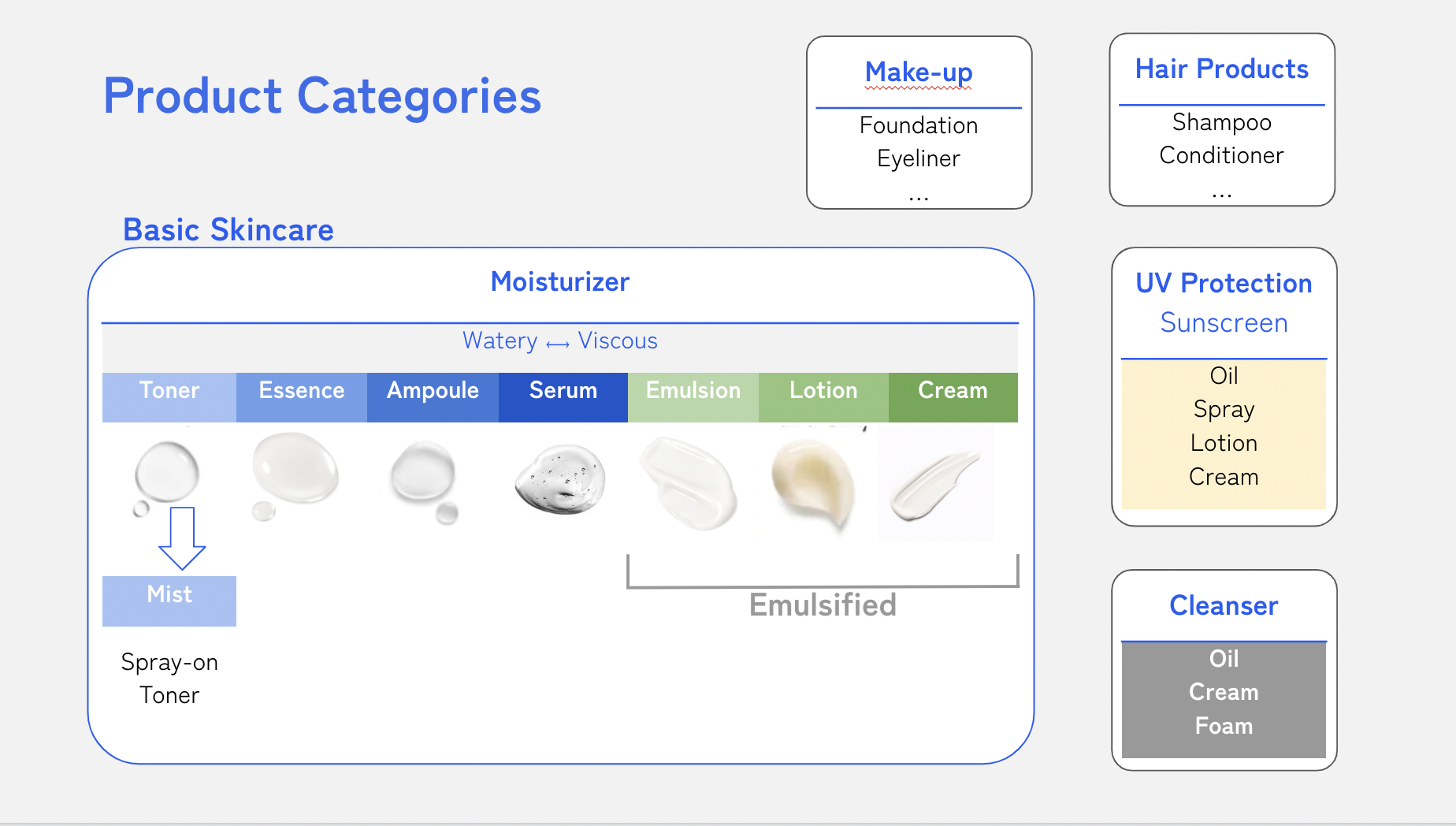
📌 제품 유형별 확인
피부보습, 자외선차단, 세정, 화장, 두발용 제품 등으로 나눔.
프로젝트를 진행하며 알게된 사실은
- 흔히 기초화장품으로 알고있는 제품들은 사실 모두 보습에 중점을 둔 모이스쳐라이저 제품이다.
- 토너, 에센스, 앰플, 세럼, 에멀젼, 로션, 크림 모두 모이쳐라이저 제품으로 구분된다. 단지 각각의 제형과 효능성분의 함량의 차이로 구분한다고 볼 수 있다.😱
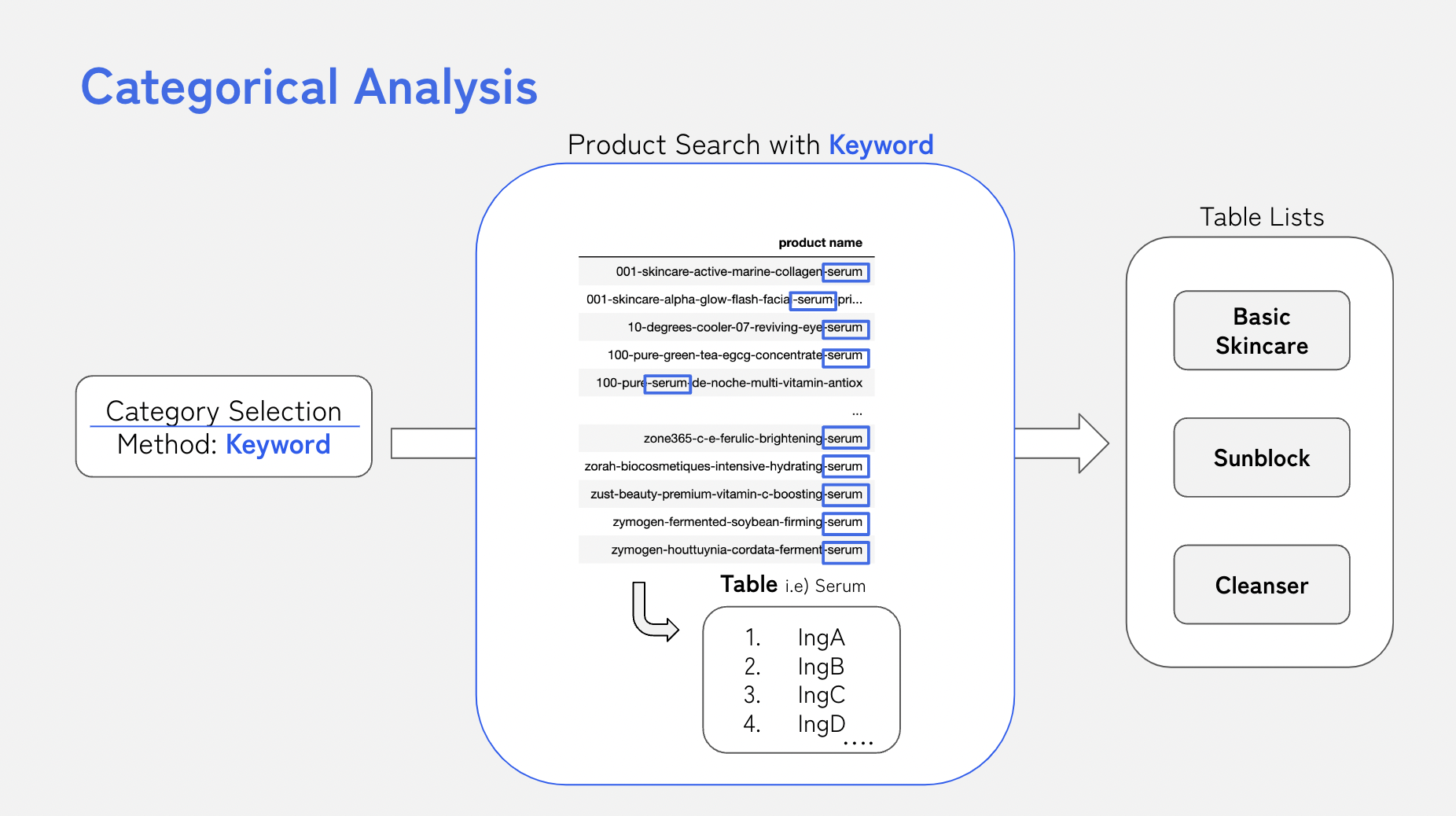
📌 유형을 나눈 방법
제품군 별로 분석시에는 키워드 검색을 사용.
예를 들어 세럼 제품들에 빈번하게 사용된 성분들 확인하는 과정에서는,
제품명에 ‘serum' 이라는 단어를 포함한 데이터만 필터링 하여 확인.
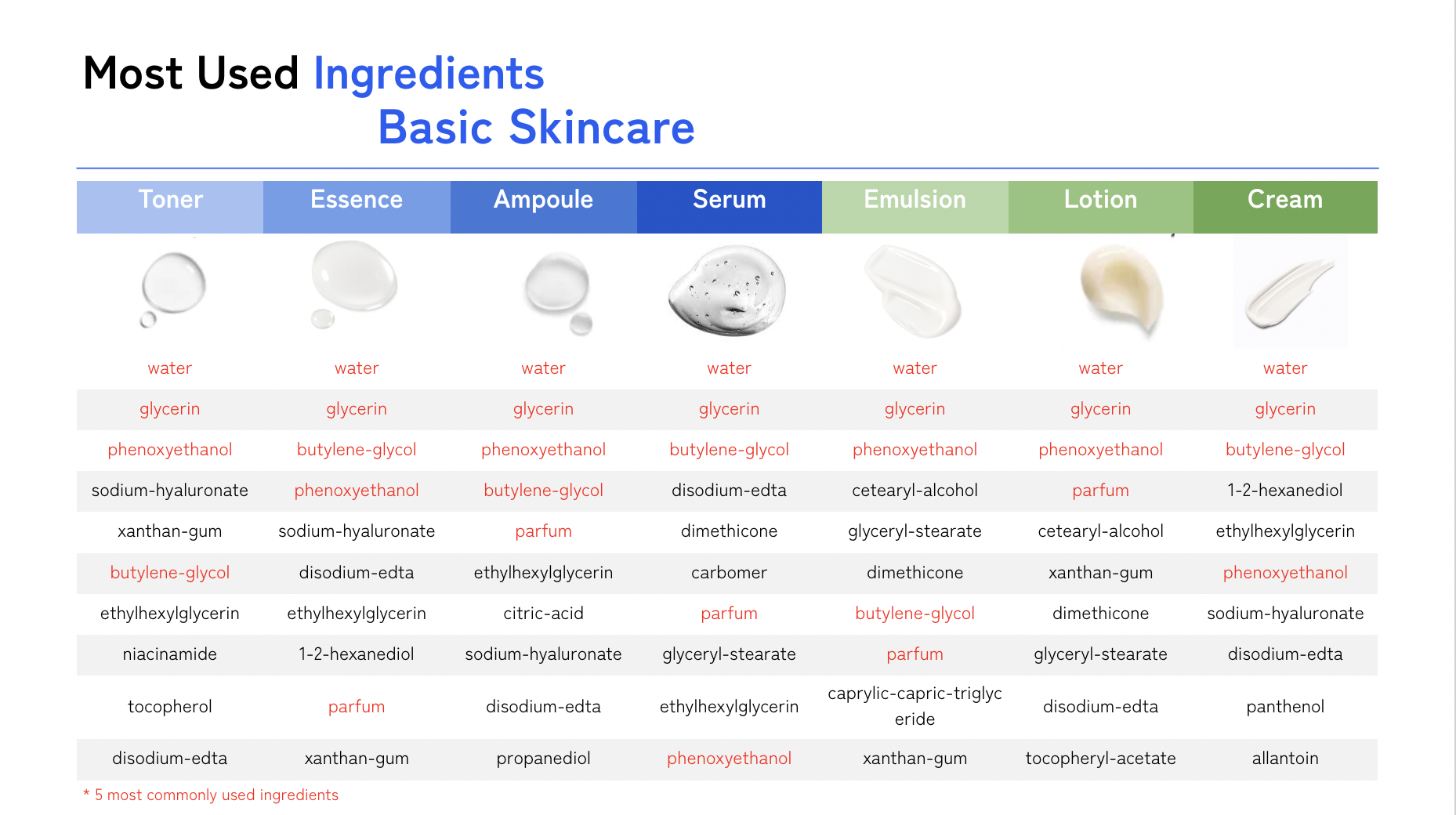
📌 기초화장품 분석
기초화장품 종류 별 가장 많이 활용된 성분을 나열한 테이블
- 종류에 관계없이 물과 글리세린이 가장 많이 쓰였다.
- 보존제인 페녹시에탄올과 보습 성분을 지닌 부텔린글라이콜도 많이 쓰였음.
그 이외의 성분들은 종류별로 활용도에 편차가 있는것으로 확인됐다.
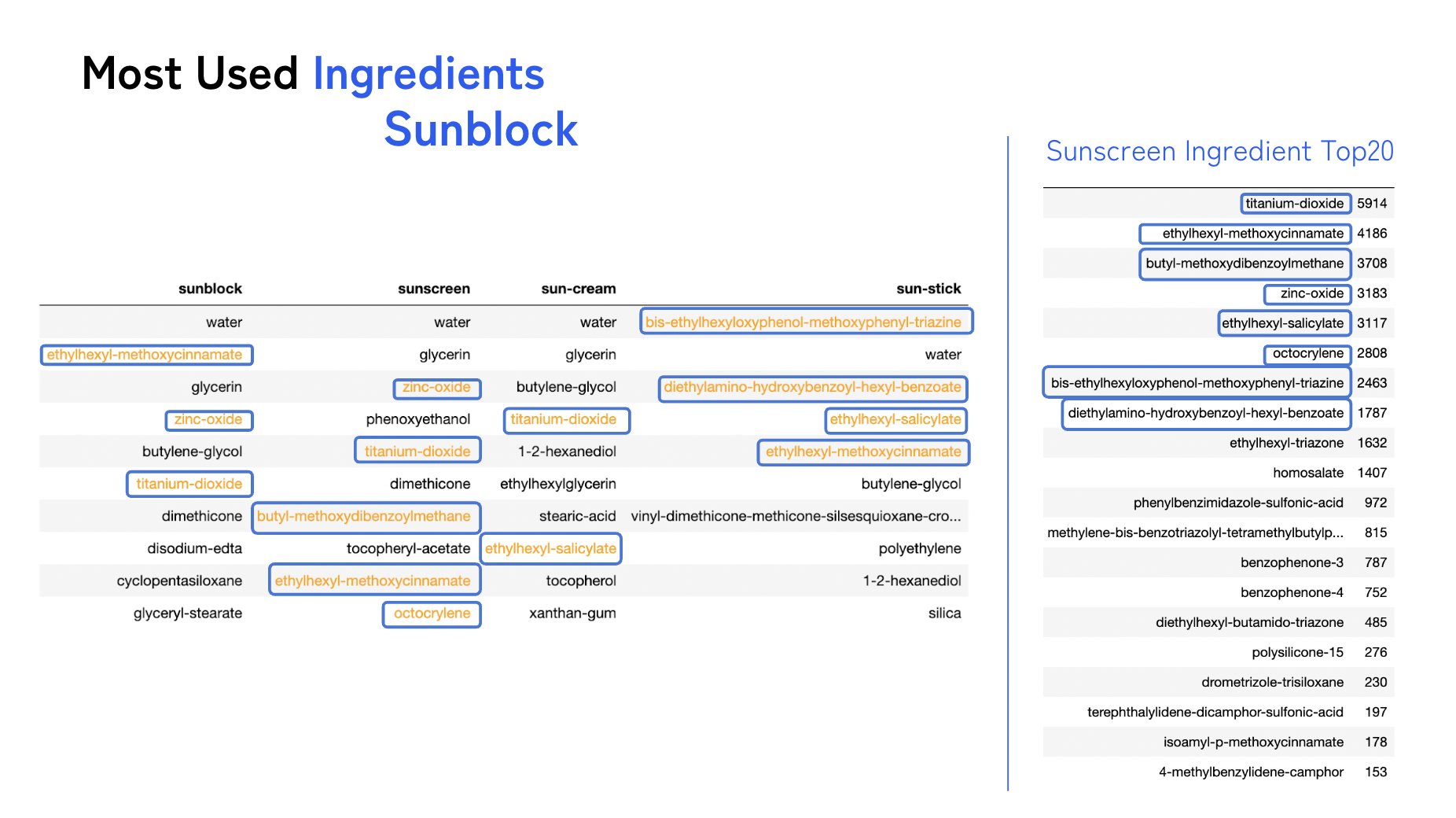
📌 선블락 제품 분석
왼쪽 테이블에 강조된 부분은, 자외선 차단 효과을 가진 성분들
- 선블록, 선크림, 선스크린등 여러가지 이름으로 불리기도 하고
- 스틱형, 크림형 등으로 제형도 다양하다.
모두 자외선 차단 효과를 가진 성분들이 공통적으로 사용됐음이 확인됐다.

📌 세정 제품 분석
왼쪽 테이블에 강조된 부분은, 계면활성과 세정 효과를 가진 성분들
- 마찬가지로 계면활성, 세정효과를 내는 성분들이 분포된 것을 확인
💡💡 제품 유형별 분석을 통해 제품타입, 목적별로 특정 효과를 내는 성분들이 분포되는것이 확인됐다.
따라서 전성분을 활용해서 유사한 화장품을 찾고자하는 시도가 유의미하다고 판단했다. 💡💡
자세한 과정은 [ 유사 화장품 추천 프로젝트 ] 02. EDA에 기록되어 있음.
5. 유사도 측정
5-1. 행렬 변환 및 모델 실행 준비
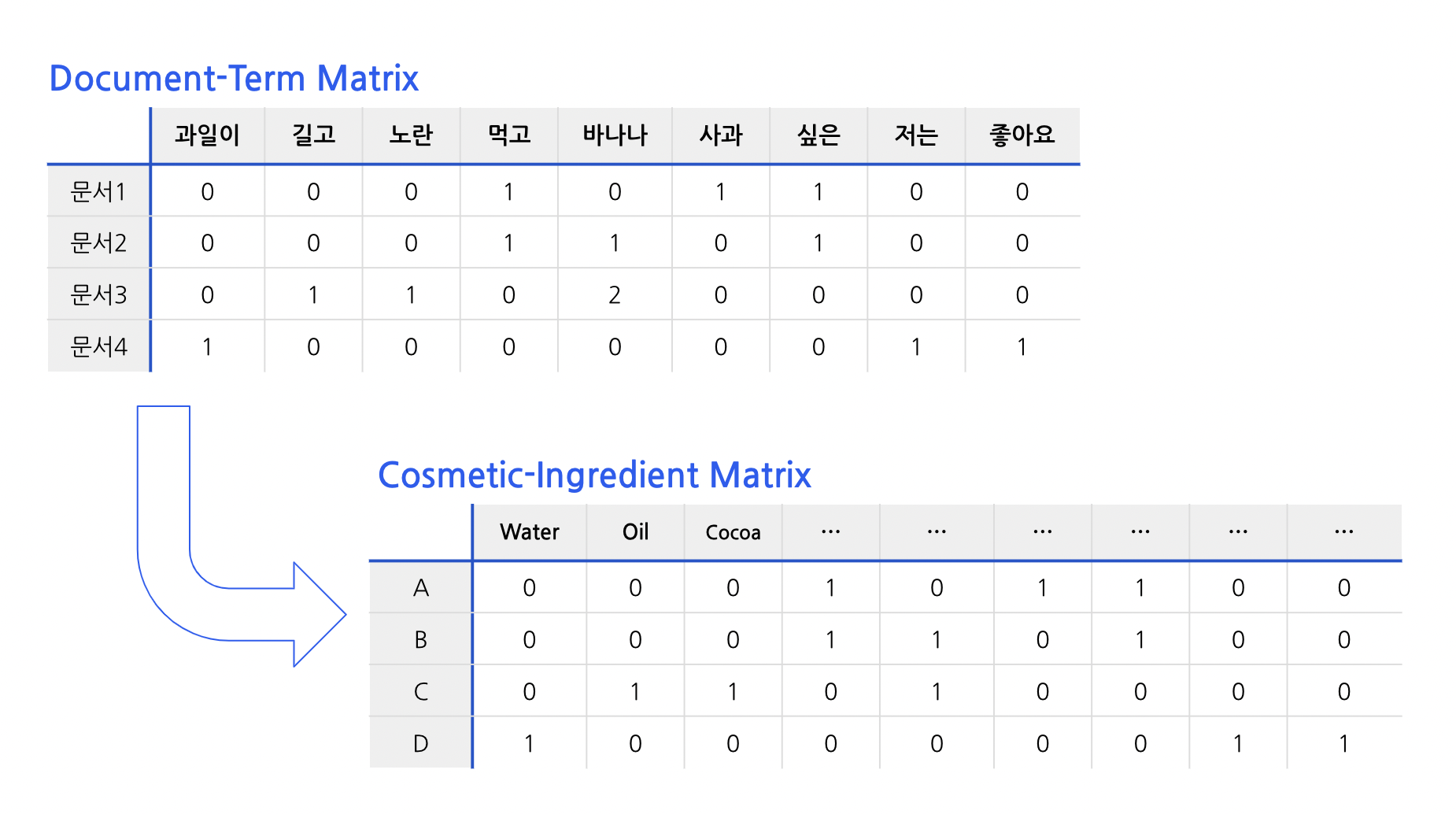
📌 DTM 말고 CIM😁
제품들 간의 유사도를 파악하기 위해서 Product, Ingredeint Table을 유사도 계산에 적합한 형태로 변환.
자연어 처리에서 텍스트를 표현하는 방법 중 정보 검색과 텍스트 마이닝 분야에서 주로 사용되는 카운트 기반의 텍스트 표현 방법을 활용했다.
- 각 product에 대한 bag of ingredients를 행렬화
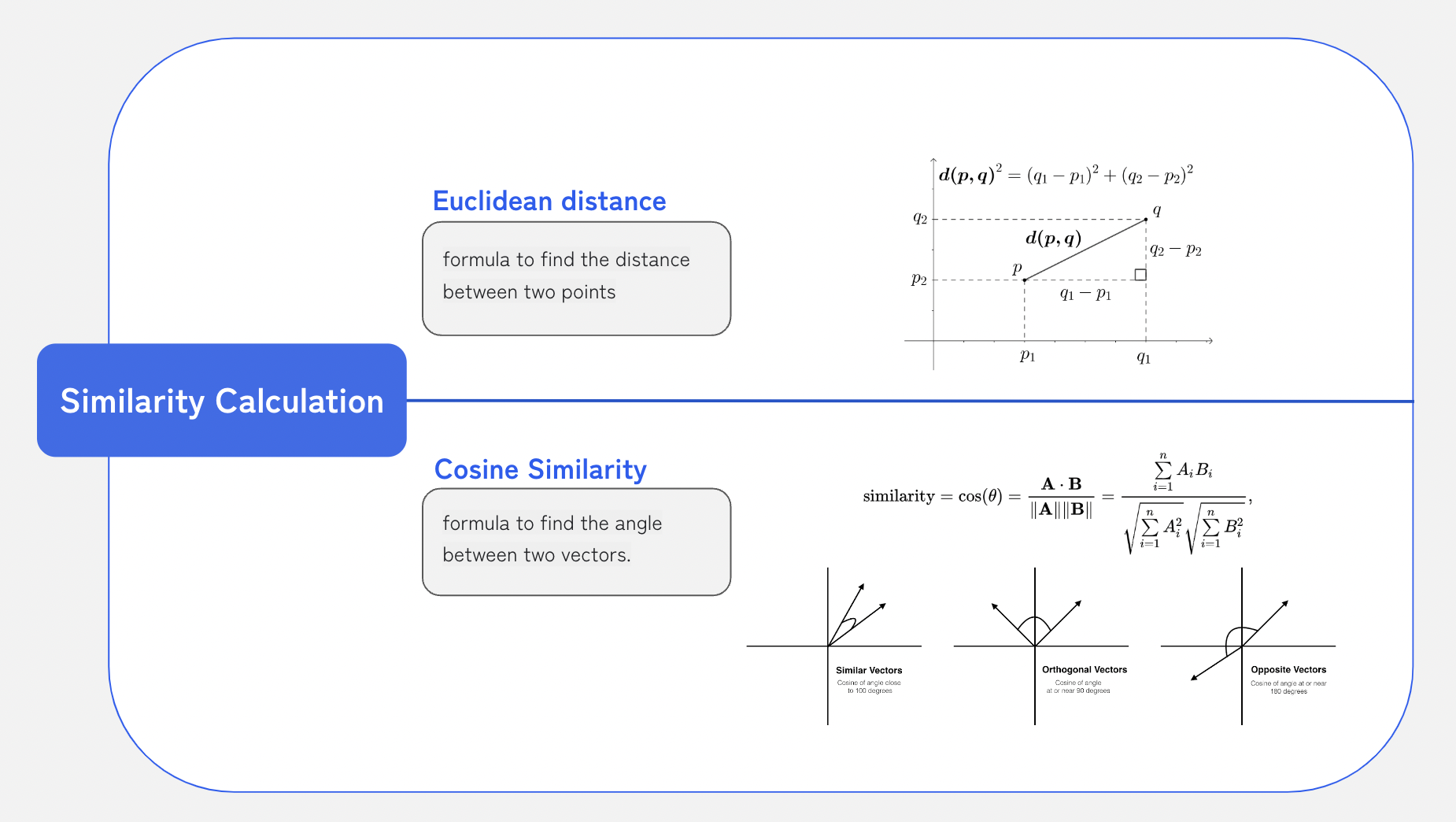
📌 Euc vs Cos
벡터 사이 거리를 구하는 기하학적 접근 중 대표적인
- Euclidean Distance
- Cosine Similarity
를 활용하여 유사도를 측정함.
두 가지 방법 중 더 나은 결과를 보이는 방법을 선택하기로 했다.
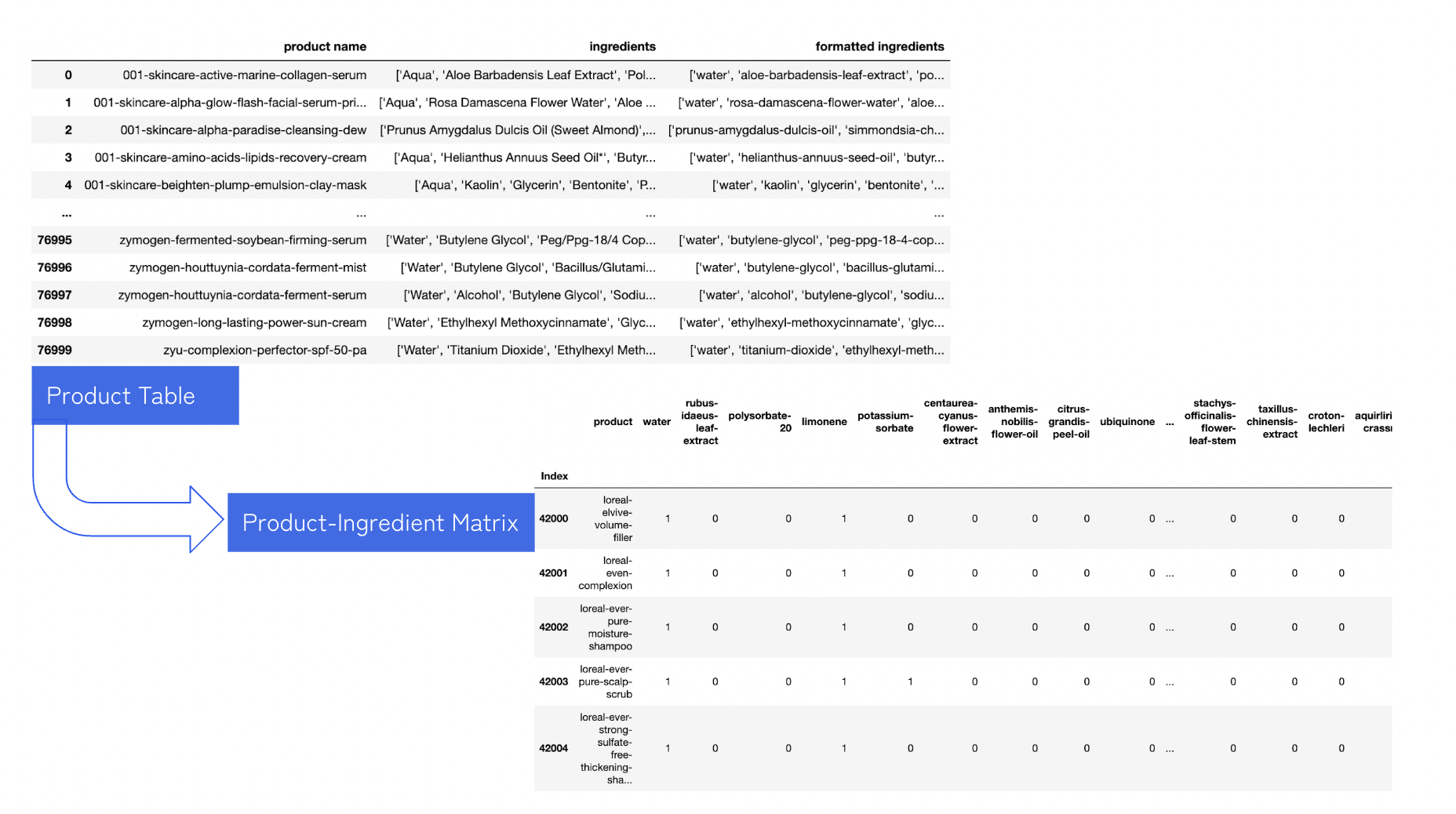

📌 실제로 행렬화하여 만든 화장품-성분 행렬표
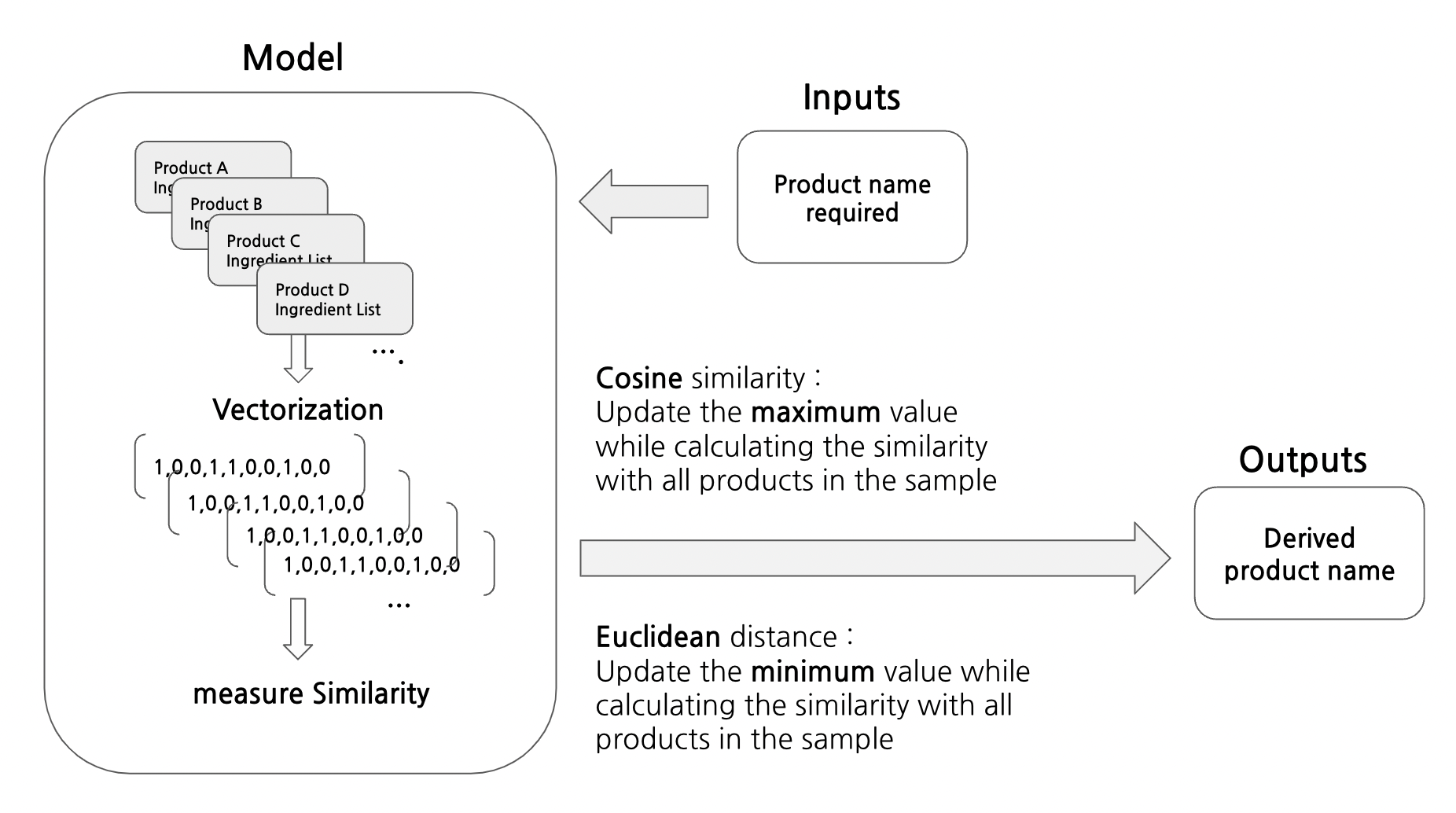
📌 결과값 도출 프로세스
Euclidean은 값이 작을 수록, Cosine은 값이 클수록 대상과 유사하다고 판단함. 따라서
- Euclidean: 루프를 돌며 Minimum 값을 갱신
- Cosine: 루프를 돌며 Maximum 값을 갱신

📌 Shuffle & Sampling
모델을 돌릴 때, 데이터 프레임이 워낙 방대하여 시간 issue를 겪게 됨.
따라서 계산 시간의 문제를 해결을 위해 계산 대상의 표본을 줄이기로 결정.
그 과정을 검토하면서, 특정 브랜드의 데이터가 순서대로 모여있는 것을 확인.
같은 브랜드 내 제품이 검색되는 것을 미연에 방지하기 위해서 셔플을 진행한 후 무작위로 7000개의 표본 추출을 진행했다.
5-2. 측정 결과 정확도 확인
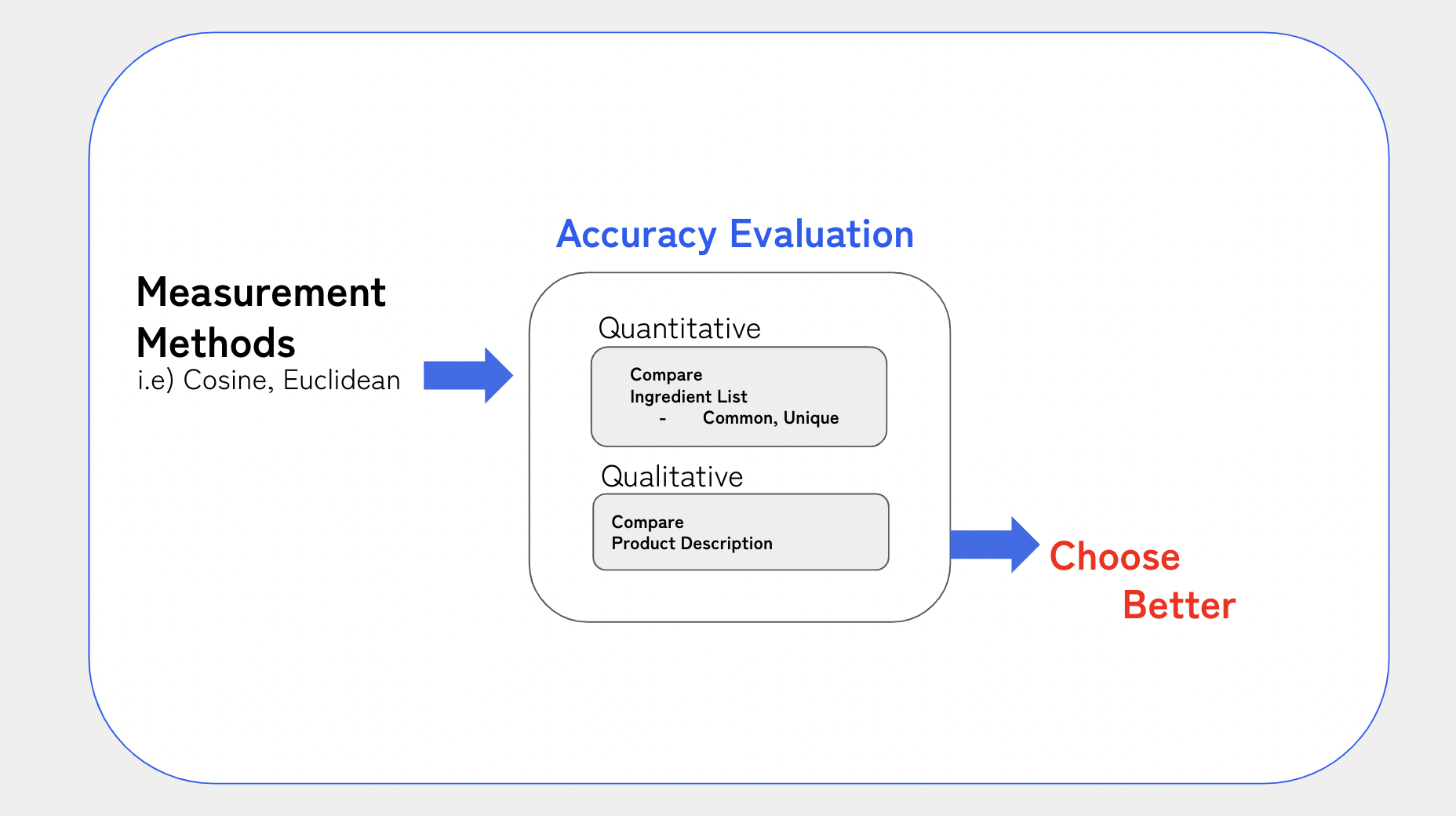
📌 정확도 확인 방법
한 개 제품에 대한 두 가지 유사도 측정 방식 결과의 정확도 확인을 위해
- 양적 분석
‣ Input, Output 두 제품의 전성분표 직접 비교
‣ 공통된 성분의 갯수, 차이를 보이는 성분의 수 등을 파악 - 질적 분석
‣ 제품 description 혹은 사용 후기의 용도, 질감, 기능 등의 구체적인 차이를 정성적으로 파악

📌 Euclidean Result
joah사의 스킨 폴리시 골드 필오프 마스크의 유클리디안 거리 측정 결과
- 5.0의 값을 보인 w7 사의 도쿄 라이스 파우더가 도출

📌 Euc - 양적 분석
필오프 마스크의 경우 26개의 성분이 포함되어 있고,
라이스 파우더의 경우 5개의 성분이 포함되어 있는데 공통적으로 포함된 성분은 3가지.
성분의 수의 차이가 큼에도 유사한 제품이라고 도출하였음.

📌 Euc - 질적 분석
두 제품을 구체적으로 파악해 보았음에도 뚜렷한 공통점이 보이지 않았음.
핵심적인 차이는 두 제품의 제형, 용도가 완전히 달랐음.
세안 이후 피부 관리에 활용되는 필오프 마스크와 달리, 라이스 파우더는 메이크업의 과정에서 사용하는 제품이다.

📌 Cosine Result
joah사의 스킨 폴리시 골드 필오프 마스크의 코사인 유사도 측정 결과
- 0.405의 값을 보인 tonymoly 사의 아이엠 펄 시트 마스크가 도출

📌 Cos - 양적 분석
유클리디언 거리 측정 방식으로 도출된 제품과는 다르게,
시트 마스크의 성분의 개수는 19개 정도로, 두 성분의 수의 차이는 7개 정도로 기존보다 적었음.
또한, 공통된 성분이 9개 정도이며,
- 필오프 마스크의 약 35%
- 시트 마스크의 약 47%
를 차지하였음. 두 제품 전성분표의 상당 부분을 차지하는 것을 알 수 있었습니다.

📌 Cos - 질적 분석
두 제품의 유사성은 정성적인 분석 결과로도 확인할 수 있었음.
- 두 제품 모두 세안 이후의 스킨케어에 사용됨
- 핵심 기능이 동일
- 차이를 보이는 많은 성분들의 역할이 비슷함
약간의 차이는 필오프 마스크에 알코올 성분이 들어가 있다는 것과
구체적인 사용 방식 및 질감 차이 등이 존재했다.
지금까지의 분석 결과를 바탕으로 코사인 유사도 측정 방식이 유클리디언 거리 측정 방식보다 더 나은 결과를 도출했다고 판단했음.
6. 한계 및 다음 단계

📌 Computing Resource & Time
특정 제품들은 가장 유사한 제품을 구할 때 다른 제품들에 비해서 낮은 코사인 유사도를 보였음.
그 이유를 다음과 같이 예측 해보았음
- 모든 제품에 대한 계산 결과가 반영되지 않았다.
- 기초적인 방식으로만 유사도를 도출하려는 시도를 했다.

📌 Action Plans
이러한 분석 결과를 기반으로, 이후의 Action Plans를 산정
-
기존에 부족했던 계산 속도를 확보하기 위해 다양한 Try 예정
‣ 멀티 스레드 기술을 코드로 구현하여 계산 속도를 확보?- 같은 행렬 즉, 같은 메모리 영역을 공유하고 같은 계산 과정을 거치기 때문에 가능할 것이라 판단.
-
대안적인 유사도 측정 방식 활용 예정
‣ 자카드 계수?- 기존의 추천 모델에서도 자주 사용되어 왔음.
- 0을 계산 과정에서 제외하기 때문에 더 나은 속도
그 이외에도 부차적인 조사 과정을 거쳐서 다양한 유사도 측정 방식을 적용할 예정임.

- 성분 위치 정보를 고려한 벡터라이즈
- 벡터 내 성분의 순서에 따라서 순위를 부여하고, 그것의 역수를 취하기?
전성분표는 함유량이 높은 순으로 내림차순 정렬되어 있음.
위 방법을 통해
- 앞 순서의 성분의 중요도는 계산 과정에서 가중치가 더 높고
- 뒷 순서의 성분 중요도는 가중치가 낮게 조정될 것으로 예상
그 이외에도 계산 과정에서의 속도를 조정하기 위해서 밀집 벡터를 활용하는 등, 다양한 벡터라이즈 방안 모색 예정!
